手撕快排
快速排序使用分治法策略来把一个序列分为较小和较大的 2 个子序列,然后递回地排序两个子序列。具体算法描述如下:
- 先把数组中的一个数当做基准数(pivot),一般会把数组中最左边的数当做基准数。
- 然后从两边进行检索。
- 先从右边检索比基准数小的
- 再从左边检索比基准数大的
- 如果检索到了,就停下,然后交换这两个元素。然后再继续检索
- 直到两边指针重合时,把基准值和重合位置值交换
- 排序好后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 然后递归地(recursive)把小于基准值的子数组和大于基准值元素的子数组再排序。
时间复杂度:O(nlogn)、空间复杂度:O(logn)、不稳定
private void sort(int[] nums, int left, int right) {
if (left >= right) {
return;
}
int p = partition(nums, left, right);
sort(nums, left, p - 1);
sort(nums, p + 1, right);
}
Random random = new Random();
public int partition(int[] arr, int left, int right) {
int r = random.nextInt(right - left + 1) + left;
swap(nums, left, r);
int pivot = arr[left];//定义基准值为数组第一个数
int i = left;
int j = right;
while (i != j) {
//case1:从右往左找比基准值小的数,找到就停止,没找到就继续左移
while (pivot <= arr[j] && i < j) j--;
//case2:从左往右找比基准值大的数,找到就停止,没找到就继续右移
while (pivot >= arr[i] && i < j) i++;
//将找到的两数交换位置
if (i < j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
// swap(arr, left, i)
arr[left] = arr[i];
arr[i] = pivot;//把基准值放到合适的位置
return i;
}
手撕归并
归并排序使用分治法策略来把一个序列分为 2 个子序列,分别对这两个子序列进行归并排序,使两个字序列分别有序,将已有序的子序列合并,得到完全有序的序列。具体算法描述如下:
- 申请空间,该空间用来存放合并后的序列;
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置;
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
- 重复步骤 3 直到某一指针达到序列尾;
- 将序列剩下的所有元素直接复制到合并序列尾。
时间复杂度:O(nlogn)、空间复杂度:O(n)、稳定
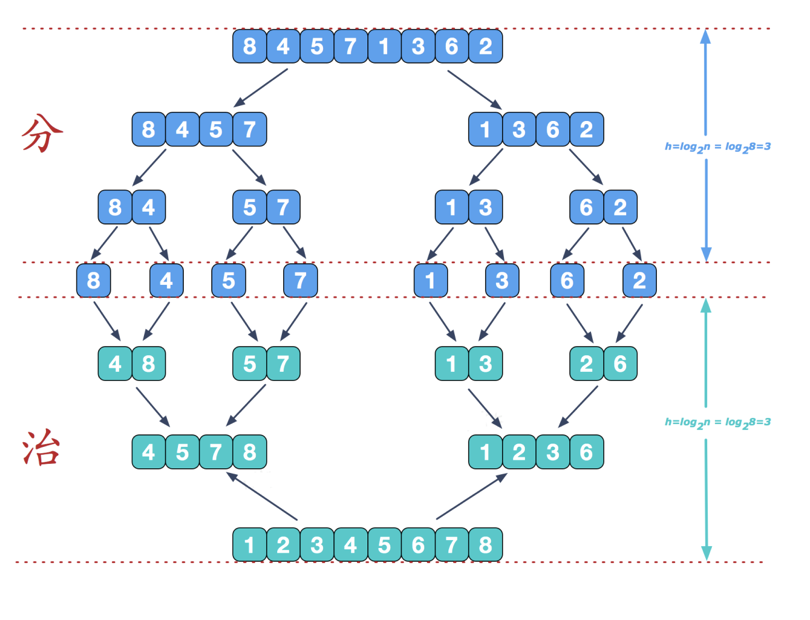
//分+治
public static void mergeSort(int[] arr, int left, int right, int[] tmp) {
if(left >= right){
return ;
}
int mid = (left + right) / 2; //中间索引
//向左递归进行分解
mergeSort(arr, left, mid, tmp);
//向右递归进行分解
mergeSort(arr, mid + 1, right, tmp);
//合并(治理)
merge(arr, left, right, tmp);
}
//治理阶段(合并)
public static void merge(int[] arr, int left, int right, int[] tmp) {
int mid = (left + right) / 2;
int i = left; // 初始化i, 左边有序序列的初始索引
int j = mid + 1; //初始化j, 右边有序序列的初始索引
int t = 0; // 指向temp数组的当前索引
//(一)
//先把左右两边(有序)的数据按照规则填充到temp数组
//直到左右两边的有序序列,有一边处理完毕为止
while (i <= mid && j <= right) {
if (arr[i] <= arr[j]) {
tmp[t++] = arr[i++];
} else {
tmp[t++] = arr[j++];
}
}
//(二)
//把有剩余数据的一边的数据依次全部填充到temp
while (i <= mid) {//左边的有序序列还有剩余的元素,就全部填充到temp
tmp[t++] = arr[i++];
}
while (j <= right) {
tmp[t++] = arr[j++];
}
//(三)
//将temp数组的元素拷贝到arr
t = 0;
while (left <= right) {
arr[left++] = tmp[t++];
}
}
手撕堆排
根据父子节点之间的关系,堆又可大致分为两类(如下图所示):
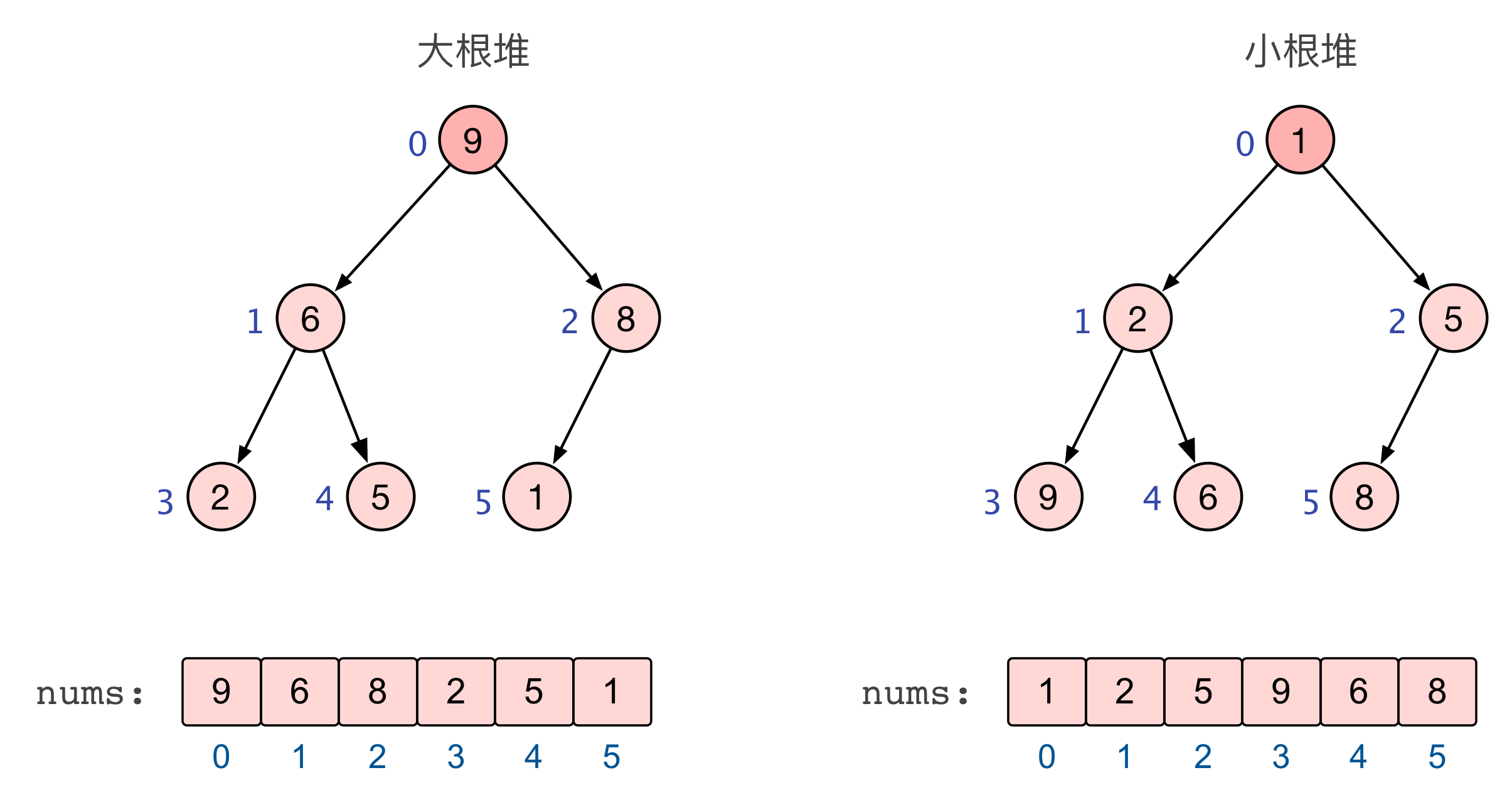
大根堆/大顶堆:每个节点的值均大于等于其左右孩子节点的值;
小根堆/小顶堆:每个节点的值均小于等于其左右孩子节点的值。
堆排序整体思路是:
对于一个待排序的包含 n 个元素的数组 nums,堆排序 通常包含以下几个基本步骤:
- 建堆:将待排序的数组初始化为大根堆(小根堆)。此时,堆顶的元素(即根节点)即为整个数组中的最大值(最小值)。
- 交换和调整:将堆顶元素与末尾元素进行交换,此时末尾即为最大值(最小值)。除去末尾元素后,将其他 n−1 个元素重新构造成一个大根堆(小根堆),如此便可得到原数组 n 个元素中的次大值(次小值)。
- 重复步骤二,直至堆中仅剩一个元素,如此便可得到一个有序序列了。
对于「升序排列」数组,需用到大根堆; 对于「降序排列」数组,则需用到小根堆。
时间复杂度:O(nlogn)、空间复杂度:O(1)、不稳定
如果一个节点索引为 i,则
- 左孩子索引:
2 * i + 1 - 右孩子索引:
2 * i + 2 - 父节点索引:
(i - 1) / 2
如果有n个元素,则最后一个非叶子节点索引为 n / 2 - 1
简单的来说,堆排序就是将持续的将一个顺序存储的二叉树变成大顶堆或者小顶堆。
代码步骤如下:
- 从最后一个非叶子节点(
n / 2 - 1)开始向前遍历 - 每一个非叶子节点,都将和自己的左节点、右节点进行判断
- 根据大顶堆的需要(父节点最大),来进行替换
- 直到成为一个大顶堆
成为了大顶堆之后,我们将得到了一个最大数,也就是大顶堆根节点的数
- 将这个根节点与最后的叶子节点进行替换,也就是将最大的数放到了最后,找到了一个数还不够,我们将重复上面的步骤
- 重复第一步,但不要影响上一步中放到最后的数 (它已经有序)
- 得到大小顶堆的根节点后,进行替换,不是和最后的数进行替换了,而是依次往前替换(倒数第2,3,….)。
- 直到排序完成
建堆:
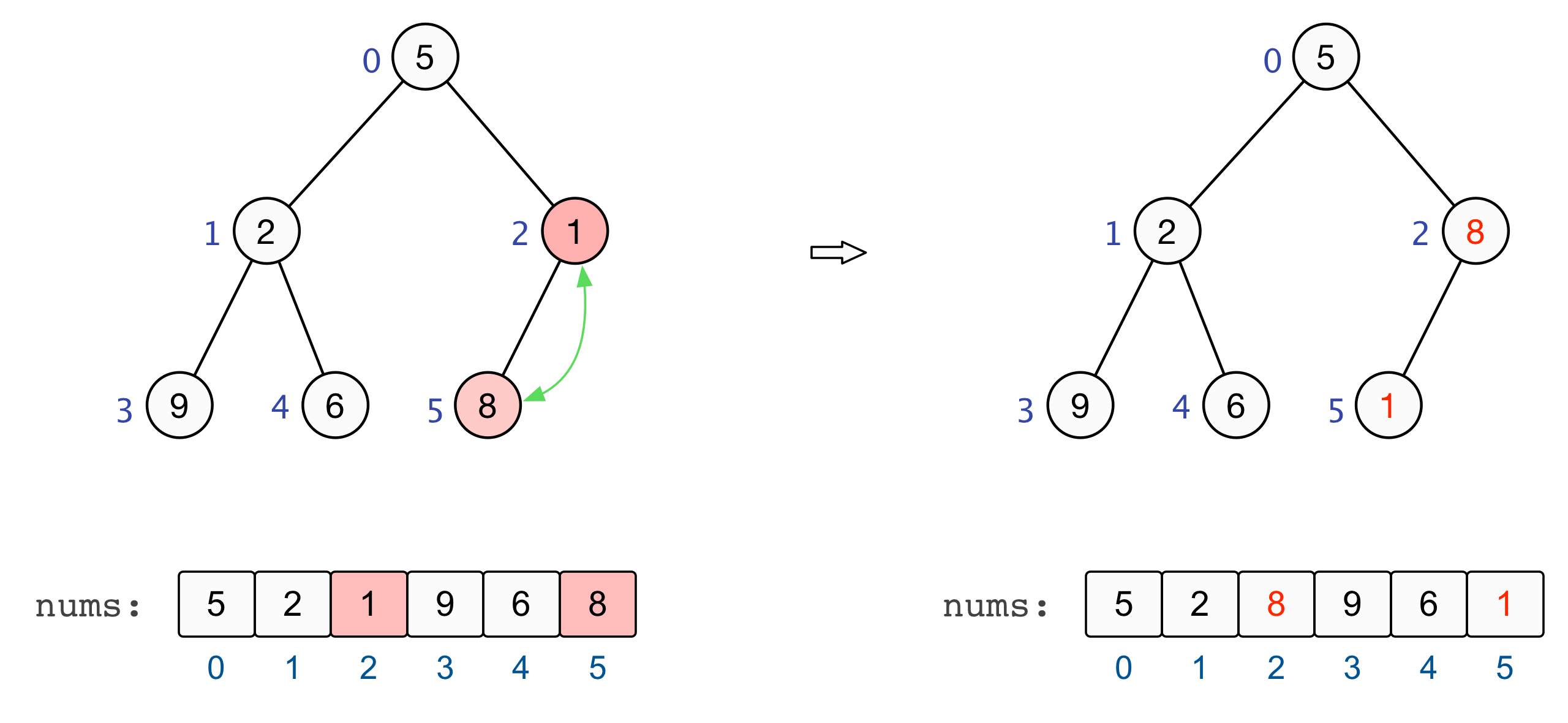
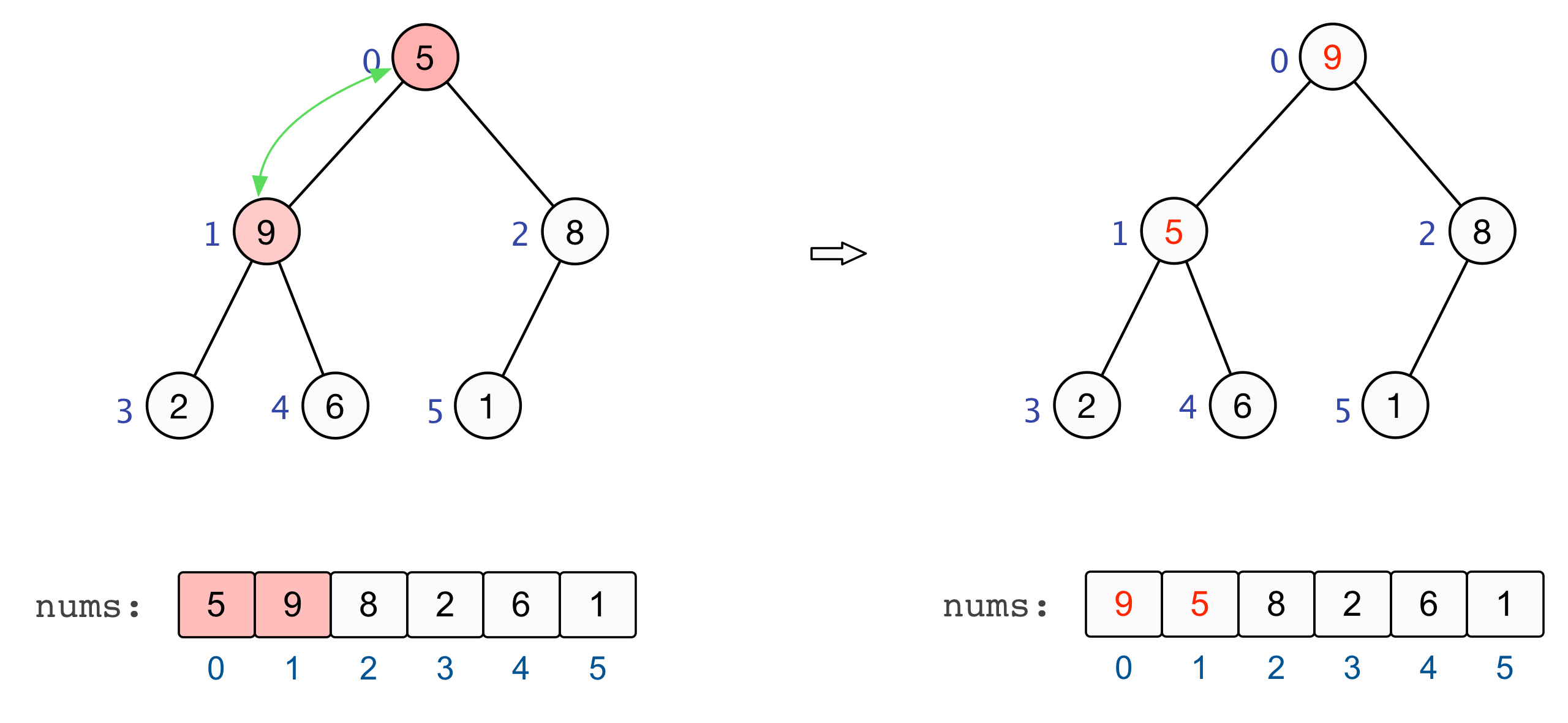
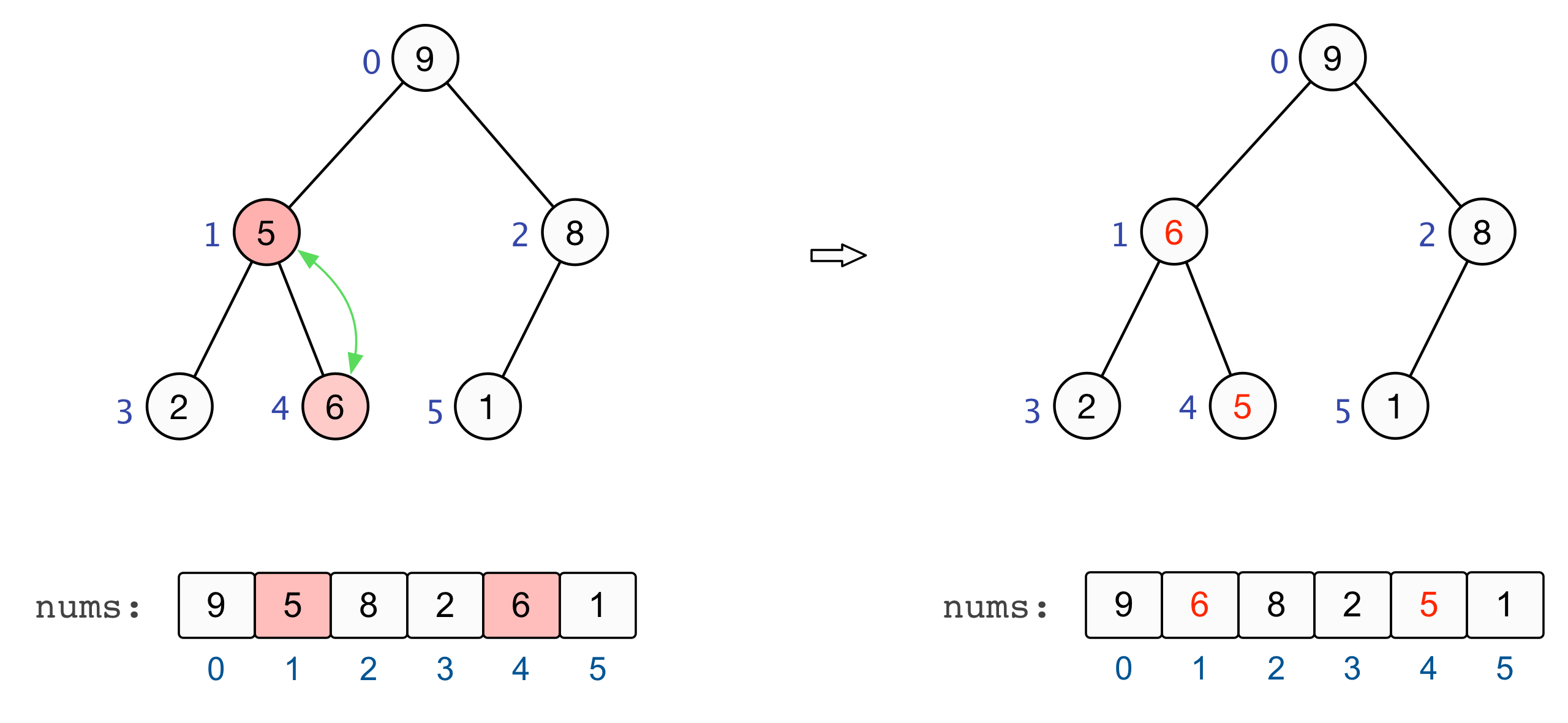
对于以某个非叶子节点的子树而言,其基本的调整操作包括:
- 如果该节点大于等于其左右两个子节点,则无需再对该节点进行调整,因为它的子树已经是堆有序的;
- 如果该节点小于其左右两个子节点中的较大者,则将该节点与子节点中的较大者进行交换,并从刚刚较大者的位置出发继续进行调整操作,直至堆有序。
 |
 |
|---|---|
 |
 |
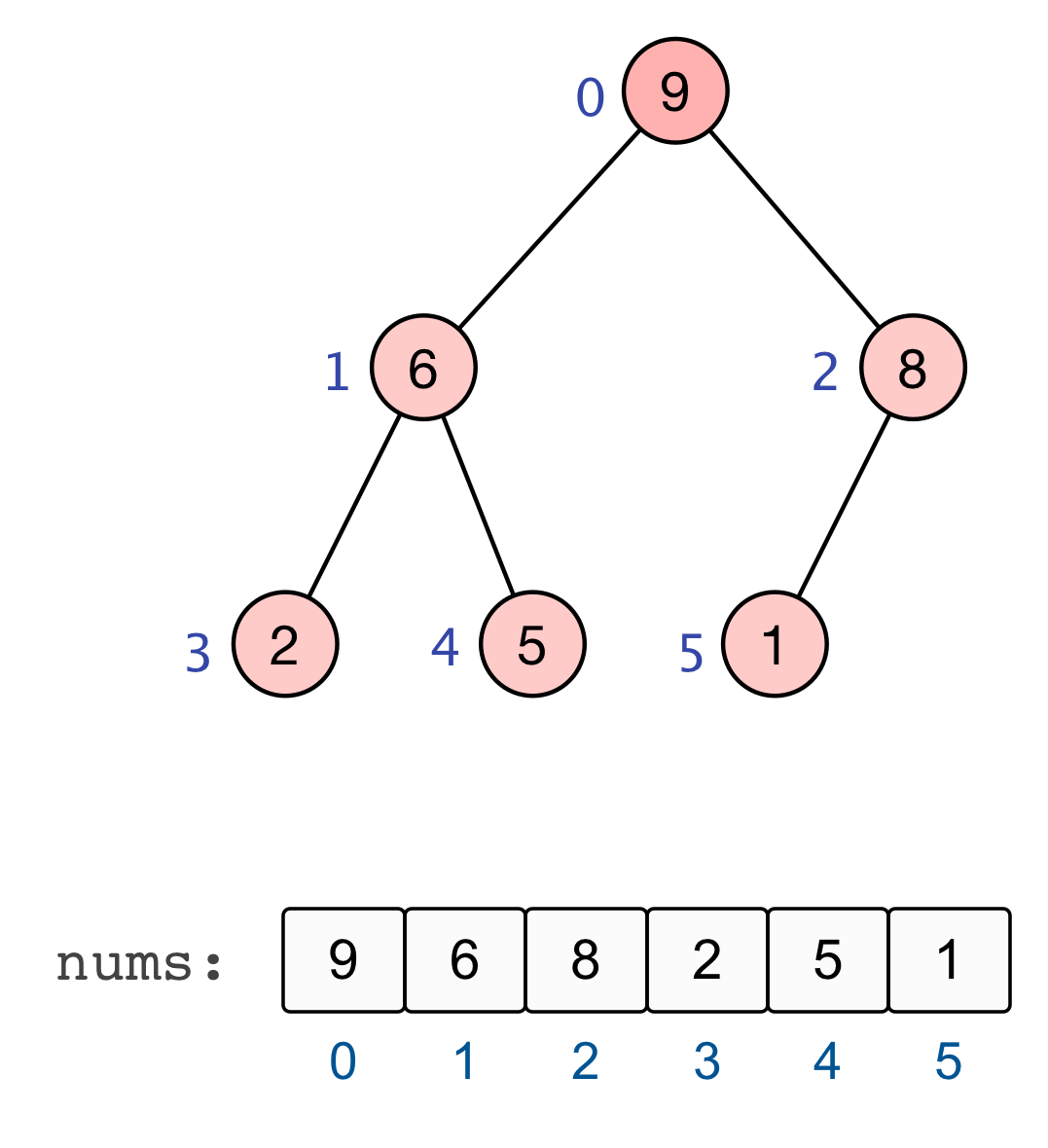 |
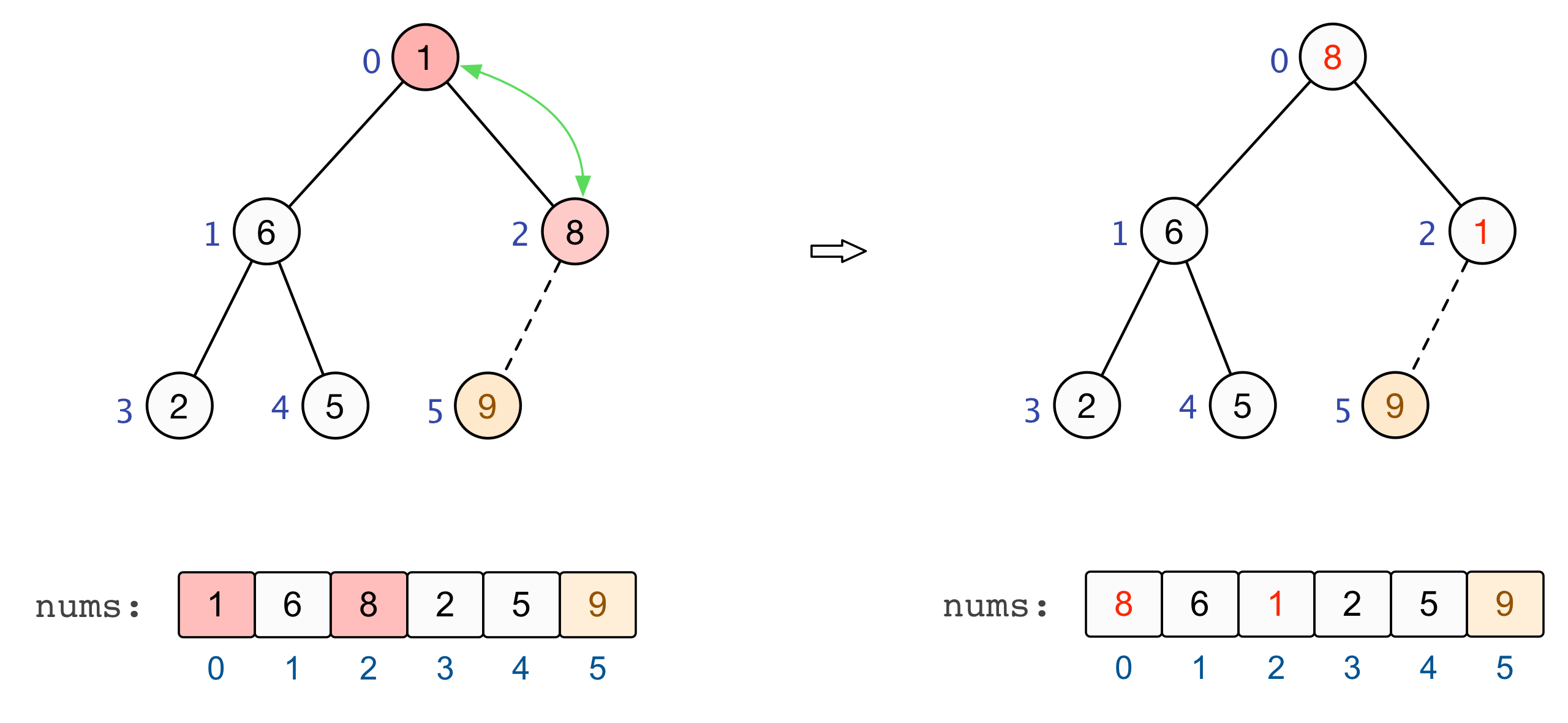
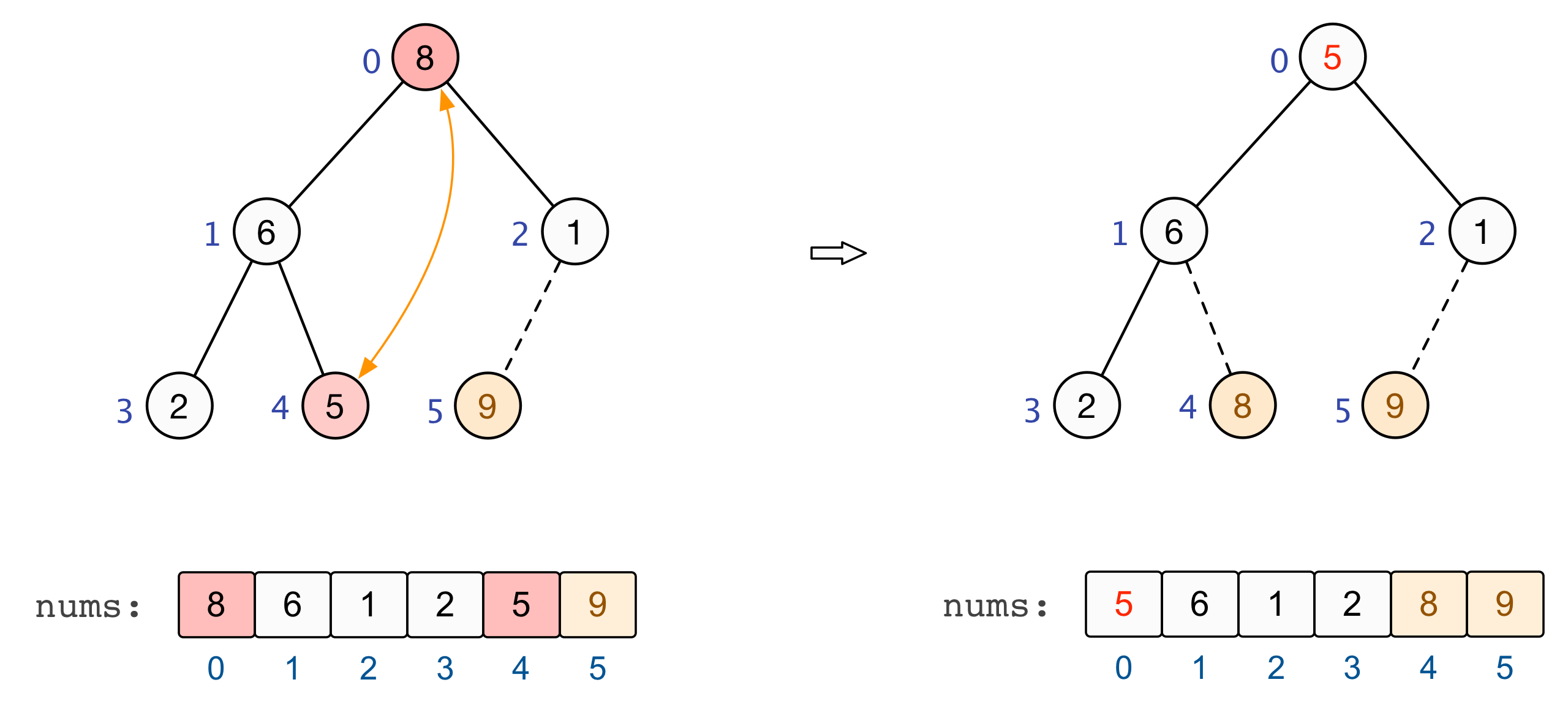
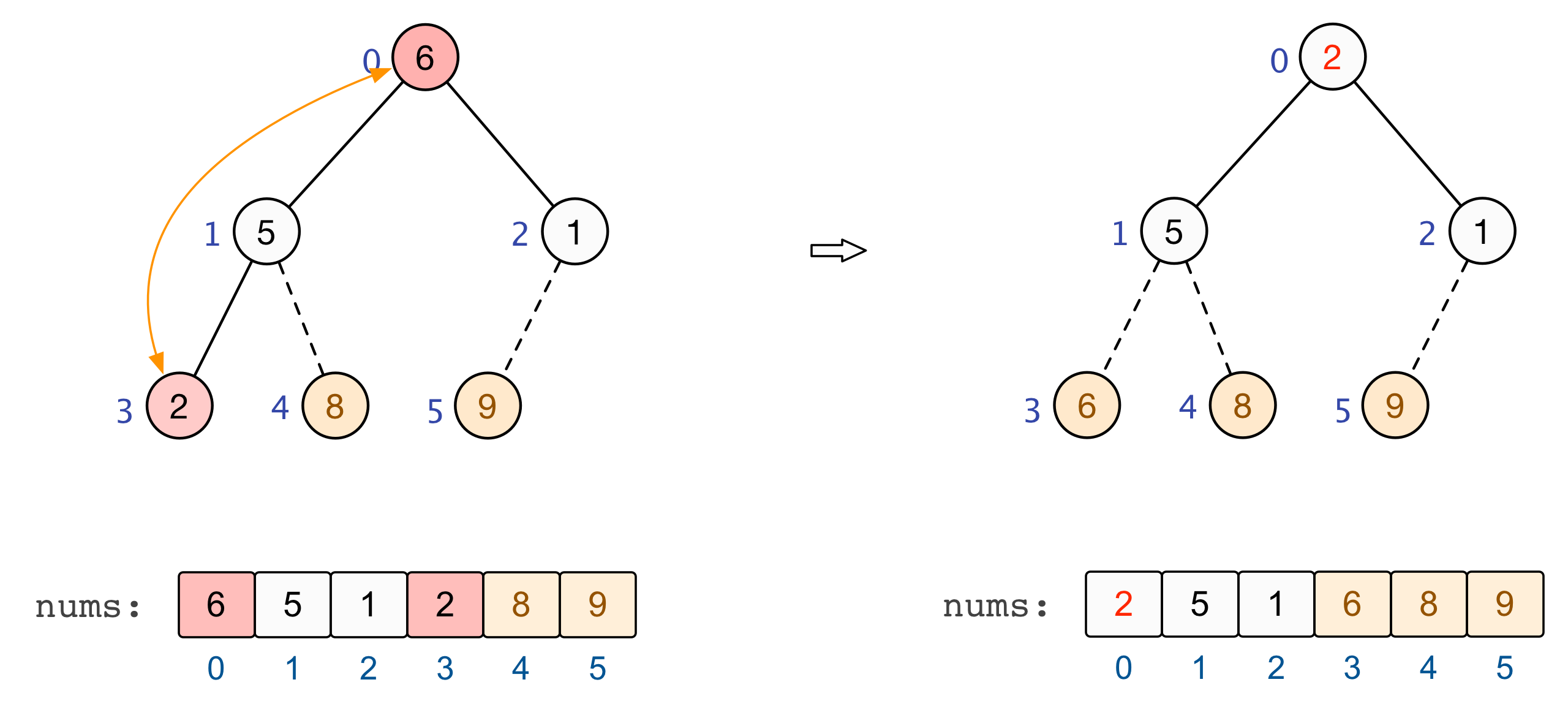
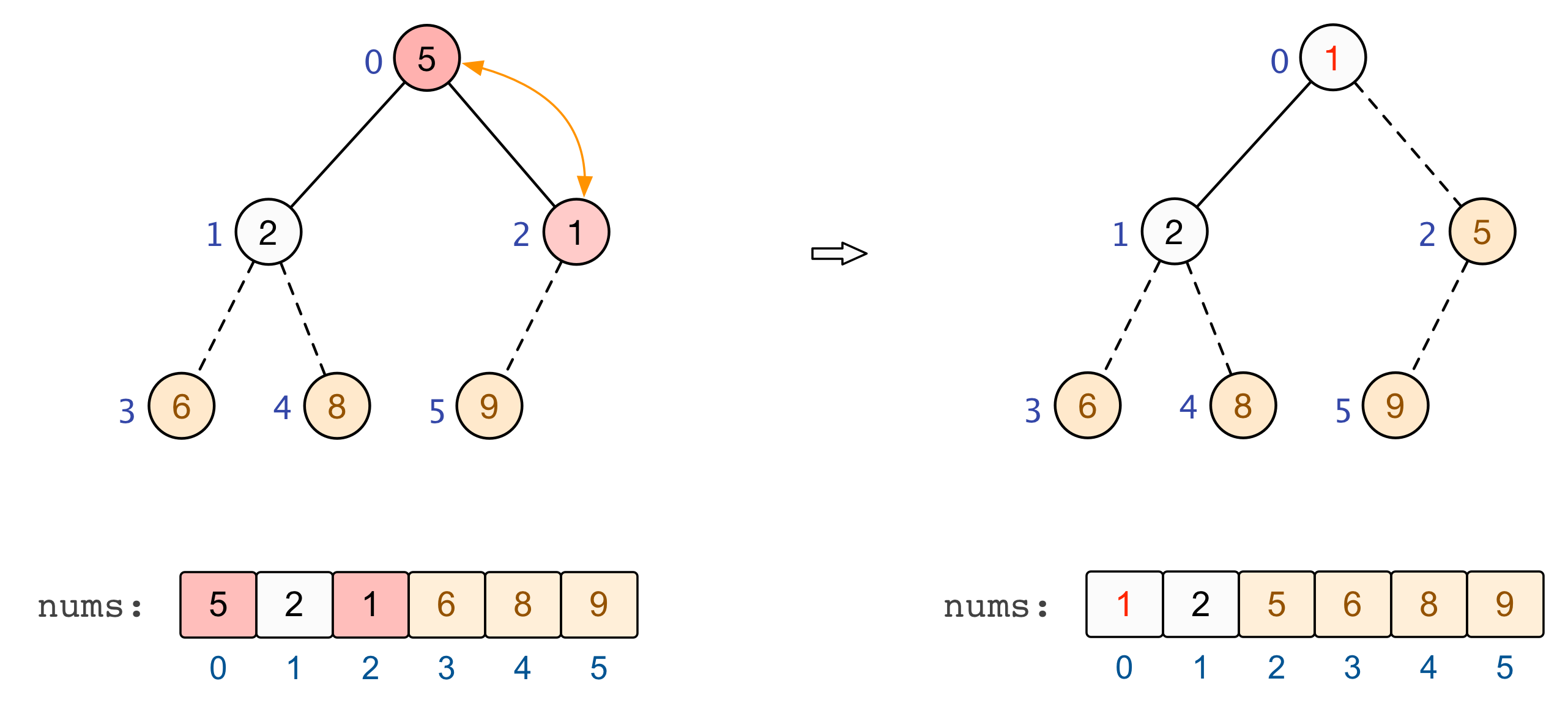
至此,全部的调整完毕,我们也就建立起了一个大根堆 :nums=[9,6,8,2,5,1] |
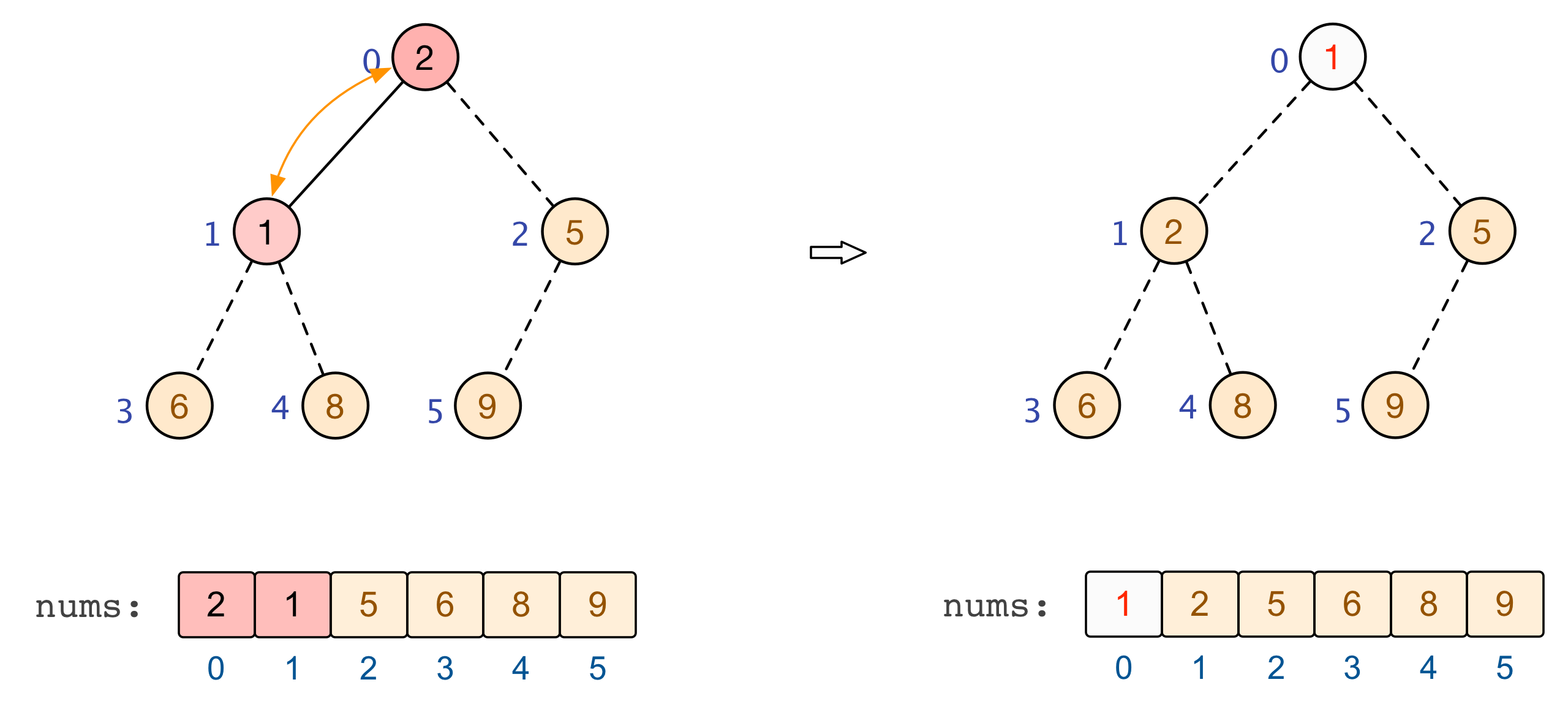
交换和调整
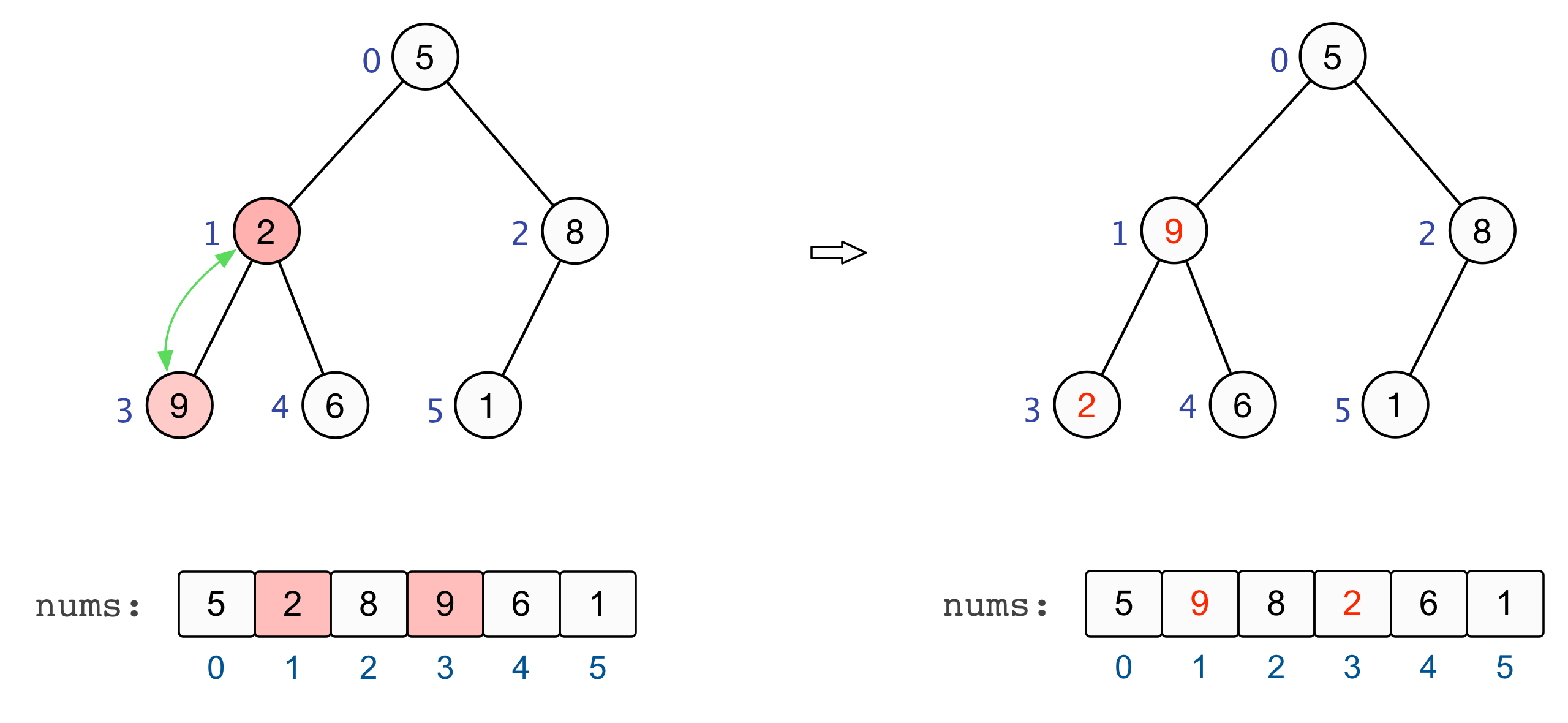
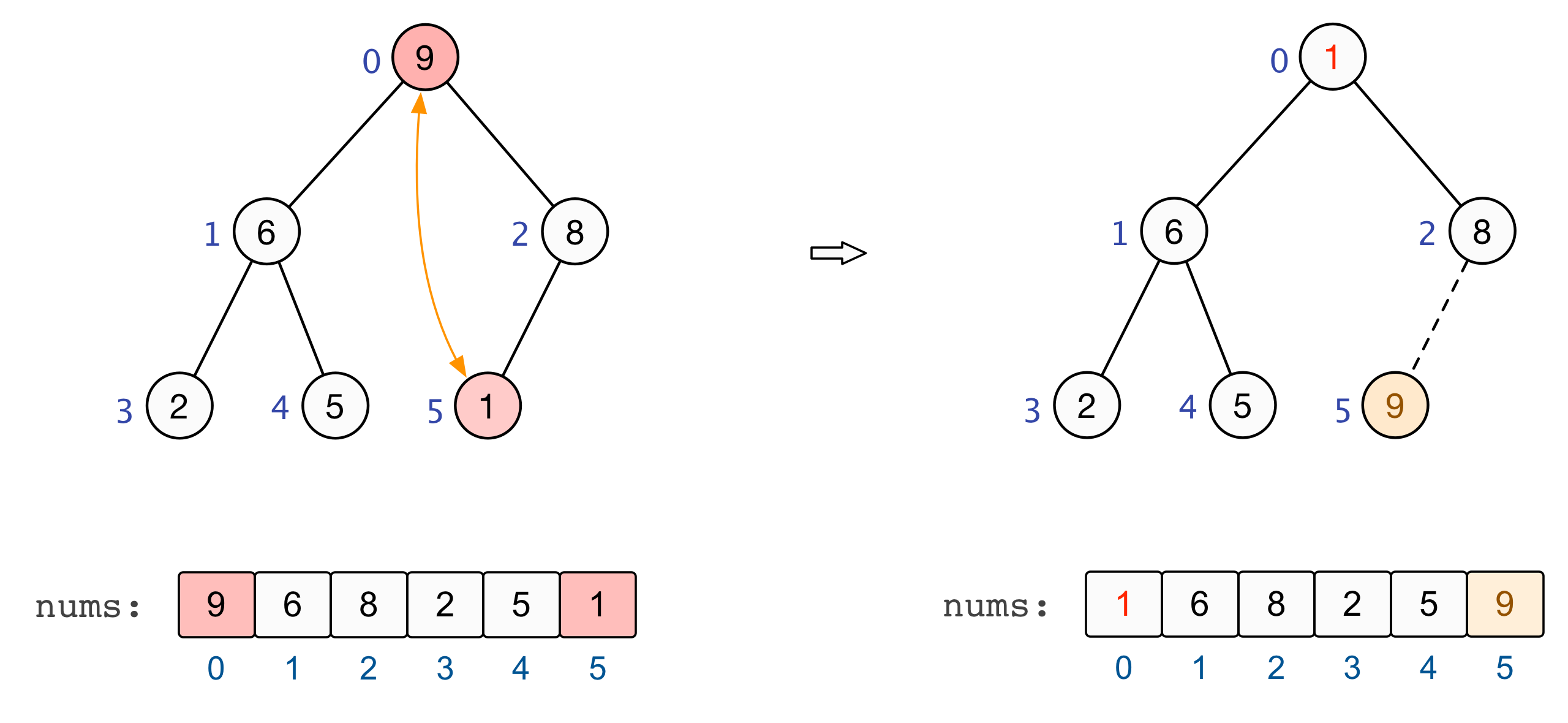
建立起一个大根堆后,便可以对数组中的元素进行排序了。总结来看,将堆顶元素与末尾元素进行交换,此时末尾即为最大值。除去末尾元素后,将其他 n−1 个元素重新构造成一个大根堆,继续将堆顶元素与末尾元素进行交换,如此便可得到原数组 n 个元素中的次大值。如此反复进行交换、重建、交换、重建,便可得到一个「升序排列」的数组。
 |
 |
|---|---|
 |
 |
 |
 |
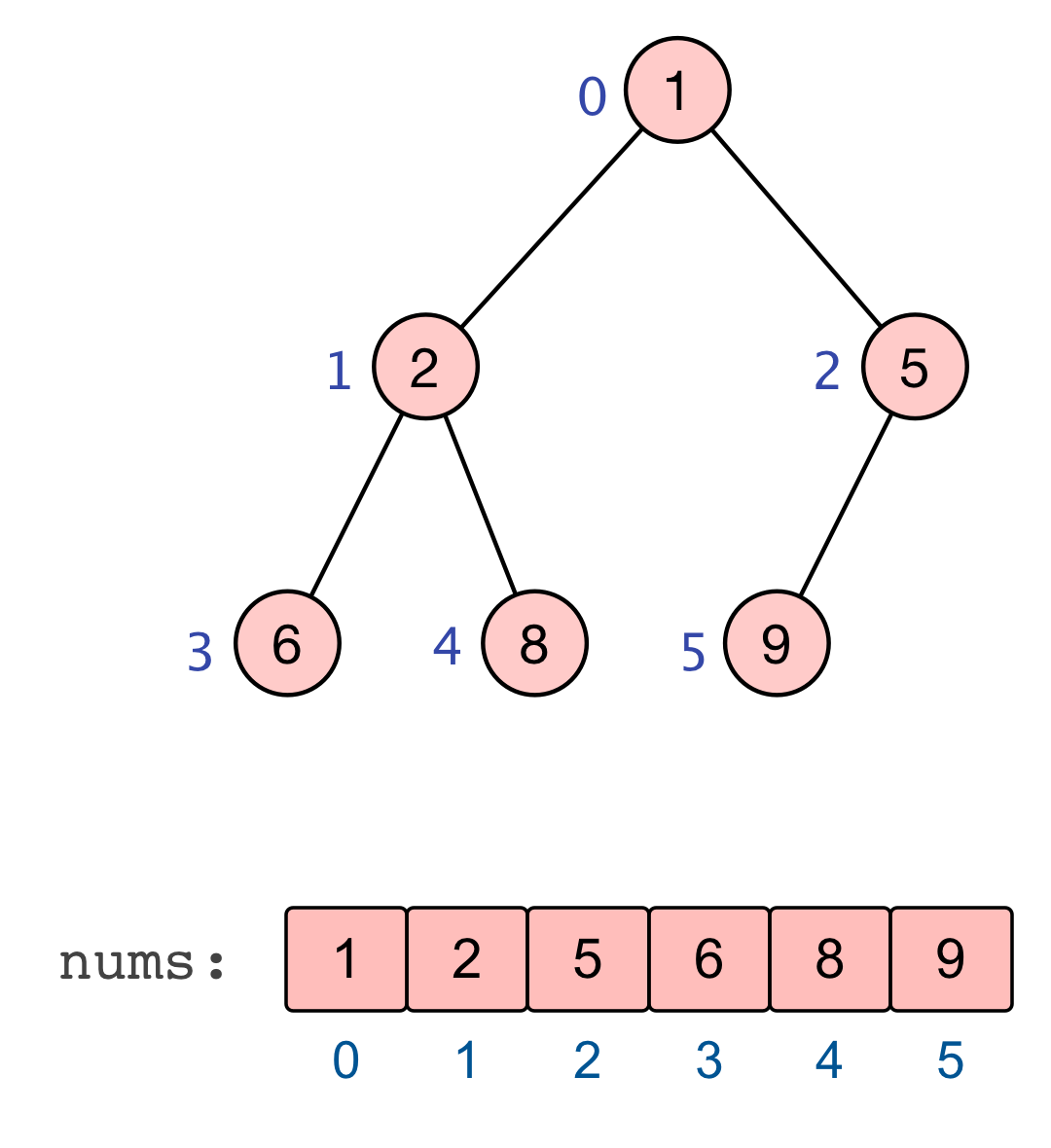 |
至此,基于大根堆的升序排列完成 |
public class Solution {
public static void main(String[] args) {
int[] arr = {2, 9, 7, 8, 3, 5, 4, 1, 6, 0};
System.out.println("排序前的数组:" + Arrays.toString(arr));
System.out.println("排序后的数组:" + Arrays.toString(sort(arr)));
}
private static int[] sort(int[] arr) {
// 建立大顶推
buildMaxHeap(arr);
// 交换和调整
// 将这个根节点与最后的叶子节点进行替换,也就是将最大的数放到了最后
for (int i = arr.length - 1; i > 0; i--) {
// 交换最前和最后的数
swap(arr, 0, i);
// 交换后,需要将根节点的数进行一次调整,重新变为大顶堆
// 除去末尾元素后,将其他 n−1 个元素重新构造成一个大顶堆
heapify(arr, 0, i); // i 表示元素个数,每次除去交换到最后的数,刚好i--
}
return arr;
}
//建立大顶堆
private static void buildMaxHeap(int[] arr) {
// 从最后一个非叶子节点开始向前遍历,调整节点位置
//arr.length / 2 - 1 表示最后一个非叶子节点
for (int i = arr.length / 2 - 1; i >= 0; i--) {
heapify(arr, i, arr.length);
}
}
//堆化:调整节点位置
public static void heapify(int[] arr, int i, int heapLen) {
int left = i * 2 + 1; // 左节点
int right = i * 2 + 2; // 右节点
// 当前节点和左右节点进行对比
int max = i; // 记录当前节点和左右节点中的最大值
if (left < heapLen && arr[left] > arr[max])
max = left;
if (right < heapLen && arr[right] > arr[max])
max = right;
// 如果最大值不是当前节点,则进行交换
if (max != i) {
// 将最大值和当前节点进行交换
swap(arr, max, i);
// 交换位置后,需要再对替换的i向下判断
// 从刚刚较大者的位置出发继续进行调整操作,直至堆有序
heapify(arr, max, heapLen);
}
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
}
手撕单例模式
饿汉式(线程安全)
类加载就会导致该单实例对象被创建,避免了多线程同步问题。天然线程安全。
方式1(静态变量方式)
public class Singleton {
//私有构造方法
private Singleton() {}
//在成员位置创建该类的对象
private static Singleton instance = new Singleton();
//对外提供静态方法获取该对象
public static Singleton getInstance() {
return instance;
}
}
该方式在成员位置声明Singleton类型的静态变量,并创建Singleton类的对象instance。instance对象是随着类的加载而创建的。如果该对象足够大的话,而一直没有使用就会造成内存的浪费。
方式2(静态代码块方式)
public class Singleton {
//私有构造方法
private Singleton() {}
//在成员位置创建该类的对象
private static Singleton instance;
static {
instance = new Singleton();
}
//对外提供静态方法获取该对象
public static Singleton getInstance() {
return instance;
}
}
该方式在成员位置声明Singleton类型的静态变量,而对象的创建是在静态代码块中,也是对着类的加载而创建。所以和饿汉式的方式1基本上一样,当然该方式也存在内存浪费问题。
方式3(枚举方式)-推荐
public enum Singleton {
INSTANCE;
}
枚举类实现单例模式是极力推荐的单例实现模式,因为枚举类型是线程安全的,并且只会装载一次,设计者充分的利用了枚举的这个特性来实现单例模式,枚举的写法非常简单,而且枚举类型是所用单例实现中唯一一种不会被破坏的单例实现模式。
懒汉式
类加载不会导致该单实例对象被创建,而是首次使用该对象时才会创建
方式1(线程不安全)
public class Singleton {
//私有构造方法
private Singleton() {}
//在成员位置创建该类的对象
private static Singleton instance;
//对外提供静态方法获取该对象
public static Singleton getInstance() {
// 保证始终只创建一个对象
if(instance == null) { //这里会出现线程安全问题
instance = new Singleton();
}
return instance;
}
}
该方式在成员位置声明Singleton类型的静态变量,当调用getInstance()方法获取Singleton类的对象的时候才创建Singleton类的对象,这样就实现了懒加载的效果。但是,如果是多线程环境,会出现线程安全问题。
方式2(线程安全)
public class Singleton {
//私有构造方法
private Singleton() {}
//在成员位置创建该类的对象
private static Singleton instance;
//对外提供静态方法获取该对象 synchronized保证线程安全
public static synchronized Singleton getInstance() {
if(instance == null) {
instance = new Singleton();
}
return instance;
}
}
该方式也实现了懒加载效果,同时又解决了线程安全问题。但是在getInstance()方法上添加了synchronized关键字,导致该方法的执行效果特别低。从上面代码我们可以看出,其实就是在初始化instance的时候才会出现线程安全问题,一旦初始化完成就不存在了。
方式3(双重检查锁)-推荐
对于 getInstance() 方法来说,绝大部分的操作都是读操作,读操作是线程安全的,所以我们没必让每个线程必须持有锁才能调用该方法,我们需要调整加锁的时机。由此也产生了一种新的实现模式:双重检查锁模式
public class Singleton {
//私有构造方法
private Singleton() {}
private static Singleton instance;
//对外提供静态方法获取该对象
public static Singleton getInstance() {
//第一次判断,如果instance不为null,不进入抢锁阶段,直接返回实例
if(instance == null) {
synchronized (Singleton.class) {
//抢到锁之后再次判断是否为null
if(instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
双重检查锁模式是一种非常好的单例实现模式,解决了单例、性能、线程安全问题,上面的双重检测锁模式看上去完美无缺,其实是存在问题,在多线程的情况下,可能会出现空指针问题,出现问题的原因是JVM在实例化对象的时候会进行优化和指令重排序操作。
要解决双重检查锁模式带来空指针异常的问题,只需要使用 volatile 关键字, volatile 关键字可以保证可见性和有序性。
public class Singleton {
//私有构造方法
private Singleton() {}
private static volatile Singleton instance;
//对外提供静态方法获取该对象
public static Singleton getInstance() {
//第一次判断,如果instance不为null,不进入抢锁阶段,直接返回实际
if(instance == null) {
synchronized (Singleton.class) {
//抢到锁之后再次判断是否为空
if(instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
添加 volatile 关键字之后的双重检查锁模式是一种比较好的单例实现模式,能够保证在多线程的情况下线程安全也不会有性能问题。
方式4(静态内部类)-推荐
静态内部类单例模式中实例由内部类创建,由于 JVM 在加载外部类的过程中,是不会加载静态内部类的, 只有内部类的属性/方法被调用时才会被加载, 并初始化其静态属性。静态属性由于被 static 修饰,保证只被实例化一次,并且严格保证实例化顺序。
public class Singleton {
//私有构造方法
private Singleton() {}
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
//对外提供静态方法获取该对象
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
第一次加载Singleton类时不会去初始化INSTANCE,只有第一次调用getInstance,虚拟机加载SingletonHolder,并初始化INSTANCE,这样不仅能确保线程安全,也能保证 Singleton 类的唯一性。静态内部类单例模式是一种优秀的单例模式,是开源项目中比较常用的一种单例模式。在没有加任何锁的情况下,保证了多线程下的安全,并且没有任何性能影响和空间的浪费。
手撕二分查找
int binarySearch(int[] nums, int target) {
int left = 0;
int right = nums.length - 1; // 注意
while(left <= right) {
int mid = left + (right - left) / 2;
if(nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1; // 注意
else if (nums[mid] > target)
right = mid - 1; // 注意
}
return -1;
}
手撕链表
手撕二叉树
手撕LRU
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
LRU:把最不常用的淘汰。把所有元素按使用情况排序,最近使用的移动到末尾,缓存满了就从头删除。
方法一:用 Java 的内置类型 LinkedHashMap 实现
哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢,所以结合二者的长处,可以形成一种新的数据结构:哈希链表
LinkedHashMap
首先要接收一个 capacity 参数作为缓存的最大容量,然后实现两个 API,一个是 put(key, val) 方法存入键值对,另一个是 get(key) 方法获取 key 对应的 val,如果 key 不存在则返回 -1。
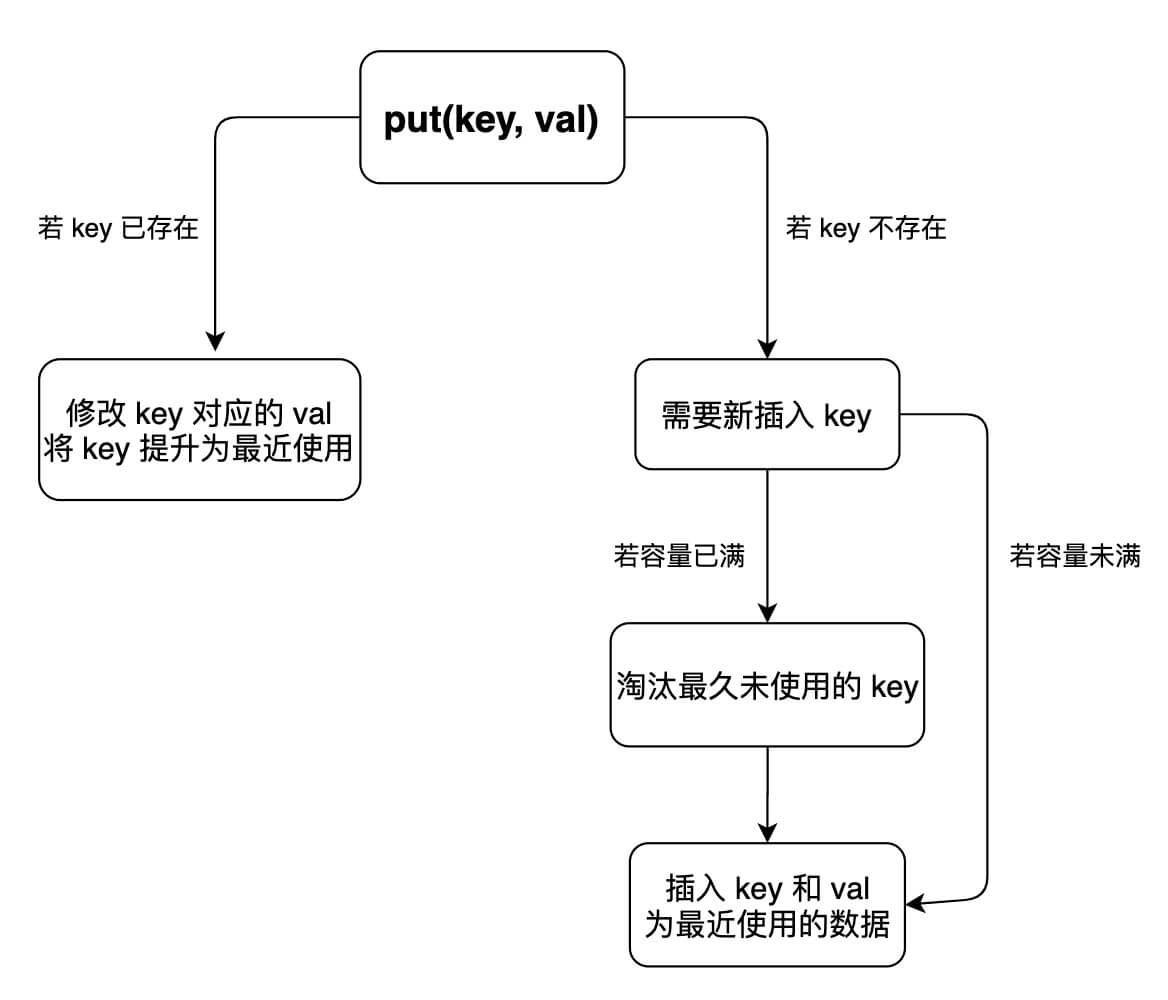
class LRUCache {
int cap;
LinkedHashMap<Integer, Integer> cache;
public LRUCache(int capacity) {
this.cap = capacity;
cache = new LinkedHashMap<>();
}
public int get(int key) {
if(cache.containsKey(key)){
// 将 key 变为最近使用
makeRecently(key);
return cache.get(key);
} else{
return -1;
}
}
public void put(int key, int value) {
if(cache.containsKey(key)){
cache.put(key, value);
// 将 key 变为最近使用
makeRecently(key);
} else{
//若容量已满,逐出最久未使用的关键字
if(cache.size() >= this.cap){
// 链表头部就是最久未使用的 key
int lruKey = cache.keySet().iterator().next();
cache.remove(lruKey);
}
// 将新的 key 添加链表尾部
cache.put(key, value);
}
}
//将 key 变为最近使用, 删除 key,重新插入到队尾
public void makeRecently(int key){
int value = cache.get(key);
cache.remove(key);
cache.put(key, value);
}
}
//写法2
class LRUCache extends LinkedHashMap<Integer, Integer>{
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
//写法3
class LRUCache {
int capacity;
LinkedHashMap<Integer, Integer> cache;
public LRUCache(int capacity) {
this.capacity = capacity;
cache = new LinkedHashMap<Integer, Integer>(capacity, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return cache.size() > capacity;
}
};
}
public int get(int key) {
return cache.getOrDefault(key, -1);
}
public void put(int key, int value) {
cache.put(key, value);
}
}
方法二:自己实现LinkeHashMap
class LRUCache {
// key -> Node(key, val)
private HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)...
private DoubleList cache;
// 最大容量
private int cap;
public LRUCache(int capacity) {
this.cap = capacity;
map = new HashMap<>();
cache = new DoubleList();
}
public int get(int key) {
if (!map.containsKey(key)) {
return -1;
}
// 将该数据提升为最近使用的
makeRecently(key);
return map.get(key).val;
}
public void put(int key, int val) {
if (map.containsKey(key)) {
// 如果 key 存在,修改 value
Node node = map.get(key);
node.val = val;
// 将 key 变为最近使用
makeRecently(key);
} else{
//若容量已满,逐出最久未使用的关键字
if(cache.size() >= this.cap){
// 删除最久未使用的元素
removeLeastRecently();
}
// 将新的 key 添加链表尾部,即添加为最近使用的元素
addRecently(key, val);
}
}
/* 将某个 key 提升为最近使用的 */
private void makeRecently(int key) {
Node x = map.get(key);
// 先从链表中删除这个节点
cache.remove(x);
// 重新插到队尾
cache.addLast(x);
}
/* 添加最近使用的元素 */
private void addRecently(int key, int val) {
Node x = new Node(key, val);
// 链表尾部就是最近使用的元素
cache.addLast(x);
// 别忘了在 map 中添加 key 的映射
map.put(key, x);
}
/* 删除最久未使用的元素 */
private void removeLeastRecently() {
// 链表头部的第一个元素就是最久未使用的
Node deletedNode = cache.removeFirst();
// 同时别忘了从 map 中删除它的 key
map.remove(deletedNode.key);
}
}
class Node{
int key, val;
Node prev, next;
public Node(){}
public Node(int key, int val){
this.key = key;
this.val = val;
}
}
//构建一个双链表,实现几个 LRU 算法必须的 API
class DoubleList{
// 头尾虚节点
private Node head, tail;
// 链表元素数
private int size;
//构造函数
public DoubleList(){
// 初始化双向链表的数据
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
size = 0;
}
// 在链表尾部添加节点 x,时间 O(1)
public void addLast(Node x) {
x.prev = tail.prev;
x.next = tail;
tail.prev.next = x;
tail.prev = x;
size++;
}
//删除链表中的 x 节点(x 一定存在),时间 O(1)
public void remove(Node x) {
x.prev.next = x.next;
x.next.prev = x.prev;
size--;
}
// 删除链表中第一个节点,并返回该节点,时间 O(1)
public Node removeFirst() {
if(head.next == tail){
return null;
}
Node first = head.next;
remove(first);
return first;
}
// 返回链表长度,时间 O(1)
public int size() {
return size;
}
}
实现一个阻塞队列
阻塞队列的实现需要保证多线程围绕队满/队空这两个条件来协作。当队满时,添加元素的线程应当阻塞;当队空时,获取元素的线程应当阻塞。
public class MyBlockingQueue<T>{
private volatile List<T> queue;
private int size;
public MyBlockingQueue(int size){
queue = new ArrayList<>();
this.size = size;
}
public synchronized void put(T element) throws InterruptedException {
while(queue.size()>=size){
wait();
}
if(queue.size()==0){
// 如果为0,则可能有其他线程在阻塞get,因此调用notifyAll
notifyAll();
}
queue.add(element);
}
public synchronized T get() throws InterruptedException {
while(queue.isEmpty()){
wait();
}
if(queue.size()>=size){
// 如果为size,则可能有其他线程在阻塞put,因此调用notifyAll
notifyAll();
}
return queue.remove(0);
}
}
实现生产者/消费者模型
使用上面的阻塞队列实现:
public class ProducerConsumer{
private static MyBlockingQueue<Integer> queue;
static class Producer extends Thread{
private MyBlockingQueue<Integer> queue;
public Producer(MyBlockingQueue<Integer> queue){
super();
this.queue = queue;
}
@Override
public void run(){
Random rnd = new Random();
for(int i=0;i<100;i++) {
try {
queue.put(i);
System.out.println("Producing "+i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class Consumer extends Thread{
private MyBlockingQueue queue;
public Consumer(MyBlockingQueue<Integer> queue){
super();
this.queue = queue;
}
@Override
public void run(){
while(true){
try {
System.out.println("Consuming "+queue.get());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args){
MyBlockingQueue<Integer> queue = new MyBlockingQueue<>(10);
Producer p = new Producer(queue);
Consumer c = new Consumer(queue);
p.start();
c.start();
}
}
Java面试——写一个生产者与消费者 - 腾讯云开发者社区-腾讯云 (tencent.com)
实现两个线程交替打印
两个线程围绕一个合作变量flag进行合作。
需要将flag声明为volatile,否则程序会卡住,这跟JMM有关系。 理论上说,每次工作线程修改了flag都迟早会同步到主内存,但是如果while循环体为空的话,访问flag会太频繁导致JVM来不及将修改后的值同步到主内存,这样一来程序就会一直卡在一个位置。
如果不使用volatile也是可以的,将循环体里面加上一句就行了,这样可以降低访问flag的频率,从而使JVM有空将工作内存中的flag和主内存中的flag进行同步。System.out.print("")
public class PrintAlternately {
static volatile int flag = 0;
static class EvenThread extends Thread{
@Override
public void run(){
for(int i=0;i<101;i+=2){
while(flag!=0){}
System.out.println(i);
flag = 1;
}
}
}
static class OddThread extends Thread{
@Override
public void run(){
for(int i=1;i<100;i+=2){
while(flag!=1){}
System.out.println(i);
flag = 0;
}
}
}
public static void main(String[] args){
EvenThread e = new EvenThread();
OddThread o = new OddThread();
e.start();
o.start();
}
}
顺序输出
固定运行顺序,先输出 2 后 输出 1
wait notify 版
public class ShunXu {
static Object obj = new Object(); // 用来同步的对象
// t2 运行标记, 代表 t2 是否执行过
static boolean t2runned = false;
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
synchronized (obj) {
// 如果 t2 没有执行过
while (!t2runned) {
try {
// t1 先等一会
obj.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("1");
}
}, "t1");
Thread t2 = new Thread(() -> {
synchronized (obj) {
System.out.println("2");
// 修改运行标记
t2runned = true;
// 通知 obj 上等待的线程(可能有多个,因此需要用 notifyAll)
obj.notifyAll();
}
}, "t2");
t1.start();
t2.start();
}
}
Park Unpark 版
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
LockSupport.park();
System.out.println("1");
}, "t1");
Thread t2 = new Thread(() -> {
System.out.println("2");
LockSupport.unpark(t1);
}, "t2");
t1.start();
t2.start();
}
交替输出
线程 1 输出 a 5 次,线程 2 输出 b 5 次。现在要求输出 ababababab 怎么实现
wait notify 版
/*
输出内容 等待标记 下一个标记
a 1 2
b 2 1
*/
class SyncWaitNotify {
private int flag; // 等待标记
private int loopNumber; // 循环次数
public SyncWaitNotify(int flag, int loopNumber) {
this.flag = flag;
this.loopNumber = loopNumber;
}
public void print(int waitFlag, int nextFlag, String str) {
for (int i = 0; i < loopNumber; i++) {
synchronized (this) {
while (this.flag != waitFlag) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.print(str);
flag = nextFlag;
this.notifyAll();
}
}
}
public static void main(String[] args) {
SyncWaitNotify syncWaitNotify = new SyncWaitNotify(1, 5);
new Thread(() -> {
syncWaitNotify.print(1, 2, "a");
}).start();
new Thread(() -> {
syncWaitNotify.print(2, 1, "b");
}).start();
}
}
Park Unpark 版
public class SyncPark {
private int loopNumber; // 循环次数
public SyncPark(int loopNumber) {
this.loopNumber = loopNumber;
}
public void print(String str, Thread next) {
for (int i = 0; i < loopNumber; i++) {
LockSupport.park();
System.out.print(str);
LockSupport.unpark(next);
}
}
static Thread t1, t2;
public static void main(String[] args) {
SyncPark syncPark = new SyncPark(5);
t1 = new Thread(() -> {
syncPark.print("a", t2);
});
t2 = new Thread(() -> {
syncPark.print("b", t1);
});
t1.start();
t2.start();
LockSupport.unpark(t1);
}
}
实现两个线程相互死锁
死锁代码
一个线程需要同时获取多把锁,这时就容易发生死锁
线程1 获得 资源 1 ,接下来想获取 资源 2
线程2 获得 资源 2,接下来想获取 资源 1
public class Dead {
public static Object resources1 = new Object();
public static Object resources2 = new Object();
public static void main(String[] args) {
new Thread(() -> {
// 线程1:占用资源1 ,请求资源2
synchronized(resources1) {
System.out.println("线程1已经占用了资源1,开始请求资源2");
try {
Thread.sleep(2000);//保证线程2先获得资源2
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
//2秒内线程2肯定可以锁住资源2
synchronized(resources2) {
System.out.println("线程1已经占用了资源2");
}
}
},"线程 1").start();
new Thread(() -> {
// 线程2:占用资源2 ,请求资源1
synchronized(resources2){
System.out.println("线程2已经占用了资源2,开始请求资源1");
try {
Thread.sleep(2000);//保证线程1先获得资源1
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized(resources1){
System.out.println("线程2已经占用了资源1");
}
}
},"线程 2").start();
}
}
死锁定位
定位死锁的方法:
使用 jps 定位进程 id,再用
jstack id定位死锁,找到死锁的线程去查看源码,解决优化Found one Java-level deadlock: ============================= "t2": waiting to lock monitor 0x0000000126019ac0 (object 0x000000076ac25d88, a java.lang.Object), which is held by "t1" "t1": waiting to lock monitor 0x000000012601c400 (object 0x000000076ac25d98, a java.lang.Object), which is held by "t2" Java stack information for the threads listed above: =================================================== "t2": at JJTest.Dead.lambda$main$1(Dead.java:43) - waiting to lock <0x000000076ac25d88> (a java.lang.Object) - locked <0x000000076ac25d98> (a java.lang.Object) at JJTest.Dead$$Lambda$2/1096979270.run(Unknown Source) at java.lang.Thread.run(Thread.java:748) "t1": at JJTest.Dead.lambda$main$0(Dead.java:28) - waiting to lock <0x000000076ac25d98> (a java.lang.Object) - locked <0x000000076ac25d88> (a java.lang.Object) at JJTest.Dead$$Lambda$1/2003749087.run(Unknown Source) at java.lang.Thread.run(Thread.java:748) Found 1 deadlock.Linux 下可以通过 top 先定位到 CPU 占用高的 Java 进程,再利用
top -Hp 进程id来定位是哪个线程,最后再用jstack <pid>的输出来看各个线程栈可以使用可视化工具 jconsole 、Visual VM
避免死锁:避免死锁要注意加锁顺序
解决死锁
解决该问题最简单的方式就是两个线程按顺序获取资源,线程1和线程2都先获取资源1再获取资源2,无论哪个线程先获取到资源1,另一个线程都会因无法获取线程1产生阻塞,等到先获取到资源1的线程释放资源1,另一个线程获取资源1,这样两个线程可以轮流获取资源1和资源2。
public class Dead2 {
public static Object resources1 = new Object();
public static Object resources2 = new Object();
public static void main(String[] args) {
new Thread(() -> {
// 线程1:先请求资源1 ,再请求资源2
synchronized(resources1) {
System.out.println("线程1已经占用了资源1,开始请求资源2");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (resources2) {
System.out.println("线程1已经占用了资源2");
}
}
},"线程 1").start();
new Thread(() -> {
// 线程2:先请求资源1 ,再请求资源2
synchronized(resources1){
System.out.println("线程2已经占用了资源1,开始请求资源2");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (resources2){
System.out.println("线程2已经占用了资源2");
}
}
},"线程 2").start();
}
}
❤️Sponsor
您的支持是我不断前进的动力,如果您恰巧财力雄厚,又感觉本文对您有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用,拒绝白嫖,从你我做起!🥰🥰🥰
| 支付宝支付 | 微信支付 |
 |
 |



