🍉Sec-Tools
本项目已开源:学习的同时,给个 Star 吧 !!!
| GitHub | https://github.com/jwt1399/Sec-Tools |
|---|---|
| Gitee | https://gitee.com/jwt1399/Sec-Tools |
前言
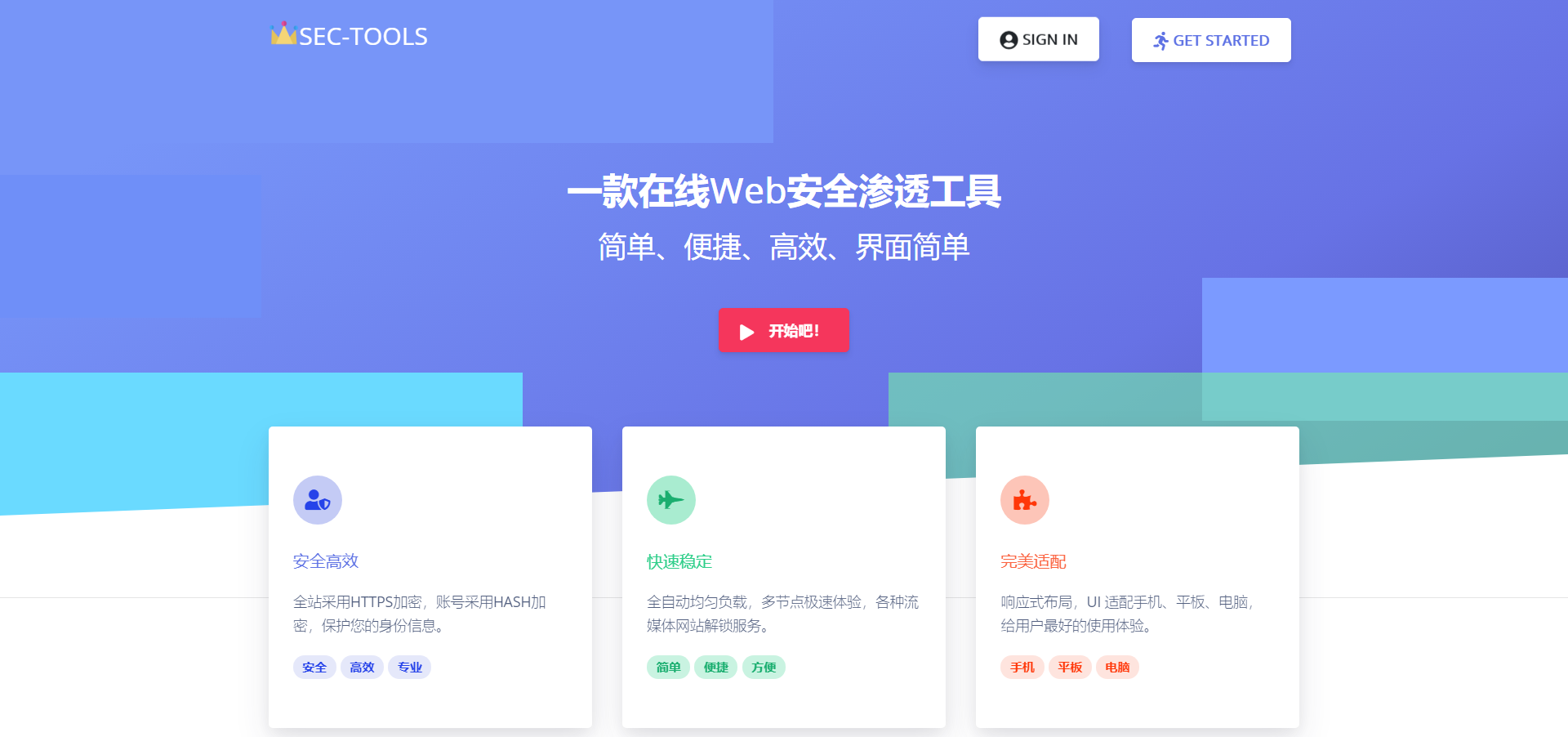
项目从12月底至今,期间因各种原因断断续续的开发,前前后后已经发布了5个版本,从最初只有框架的 V1.0 版本,到如今功能日趋完善的 V2.3 版本项目正在不断完善中,现已集成端口扫描、指纹识别、旁站探测、信息泄露扫描、安全导航等多个功能,后续将加入漏洞检测、目录识别、域名探测等功能,一起期待吧!页面我们尽可能做到简单、清新,便于用户使用。现 UI 已经适配PC端、Phone端、Pad端,使用户得到舒适的使用体验。我们致力于打造一款安全高效、操作简单、界面清爽、兼容适配的安全工具。本项目的灵感来自于国光师傅的文章Django 编写 Web 漏洞扫描器挖坑记录。就像国光师傅说的那样我们无论是开发还是安全都有很长的路要走,路漫漫其修远兮,吾将上下而求索!
2021.03.02更新:版本更新到 V2.5 ,新增了漏洞扫描、目录扫描等功能并且进行了一系列 UI 优化。
2021.04.20更新:版本更新到V2.7,新增了漏扫详情页、仪表盘、域名探测等功能并且进行了一系列优化和Bug修复。
项目介绍
系统简介
本项目命名为Sec-Tools,是一款基于 Python-Django 的在线多功能 Web 应用渗透测试系统,包含漏洞检测、目录识别、端口扫描、指纹识别、域名探测、旁站探测、信息泄露检测等功能。本系统通过旁站探测和域名探测功能对待检测网站进行资产收集,通过端口扫描、指纹识别、目录识别和信息泄露检测功能对待检测网站进行信息收集,通过收集的信息分析评估网站存在哪些安全隐患,然后使用漏洞检测功能揭示网站存在的漏洞以及危害等级并给出修复建议。通过这一系列的步骤,可以对Web应用进行全面检测,从而发现网站存在的安全隐患,因此用户可以针对相应的网络威胁做出应急响应,进而提升站点的安全性。
团队成员
本项目由我担任组长,带领其余3人共同开发,因此代码风格会有不同,相关功能的实现深度也会参差不齐 !
| 简同学 | 邓同学 | 王同学 | 林同学 |
| |
 |
相关技术
| 名称 | 版本 |
|---|---|
| Python | 3.7.0 |
| Django | 3.1.4 |
| SQLite | 3.35.2 |
| ECharts | 5.0.1 |
| Tabler | 1.0.0-beta2 |
| SimpleUI | 2021.1.1 |
| Docsify | 4.11.6 |
| Layer | 3.2.0 |
| Boostrap Table | 1.18.2 |
项目功能

项目首页
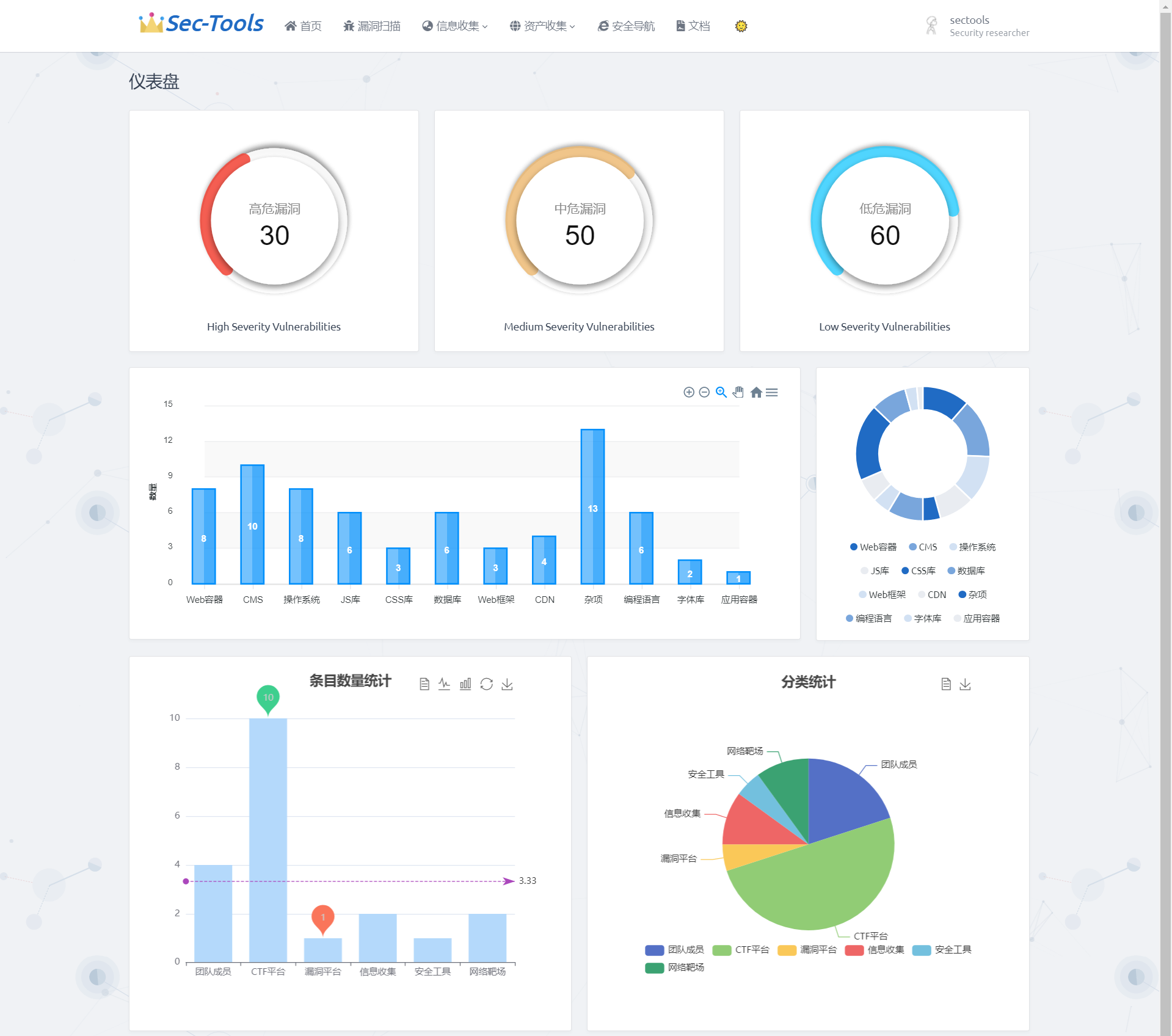
首页采用 ECharts 对漏洞扫描的漏洞等级、指纹识别组件、安全导航数据做了可视化图表展示,图表的风格没有统一,凑合看吧😂
身份验证
新用户想要使用系统功能必须要注册登录,游客只能访问部分页面。本系统有普通用户和超级用户。普通用户可以使用本系统的所有功能,但是不能登录后台管理系统。超级用户不仅可以使用所用功能还可以登录后台管理系统中所有的用户权限和数据。
设计思路:登录和注册模块在 Django 自带的认证模块的基础上进行实现,因此在后台-->用户与授权就可对注册用户进行权限分配和相应管理。我们使用 Django 自带的数据库 SQLite 来存放账户信息,重构了数据库表auth_user表,增加了用户邮箱字段,auth_user 中密码字段是加了 salt 的 sha256 值再经过 base64 编码之后的值,保障了用户的信息安全。

| 登录页 |  |
|---|---|
| 注册页 |  |
重设密码功能调用第三方包 django-password-reset 进行实现
| 步骤一 |  |
|---|---|
| 步骤二 |  |
漏洞检测
该模块主要是对目标Web系统进行安全漏洞扫描,包括SQL注入、跨站脚本攻击(XSS)、弱密码、中间件漏洞。中间件漏洞扫描包括对Weblogic、Struts2、Tomcat 、Jboss、Drupal、Nexus的已知漏洞进行检测,用户提供目标URL并选择CVE漏洞编号。
设计思路
该模块的全扫描、SQL注入漏洞扫描、XSS漏洞扫描、弱口令扫描、仅爬取是调用 AWVS API 进行实现。中间件漏洞扫描是基于脚本模拟网络请求实现。根据漏洞形成的原因,生成一些测试 payload 发送到目标系统,再由返回的状态码和数据来判断payload是否有效。
实现效果
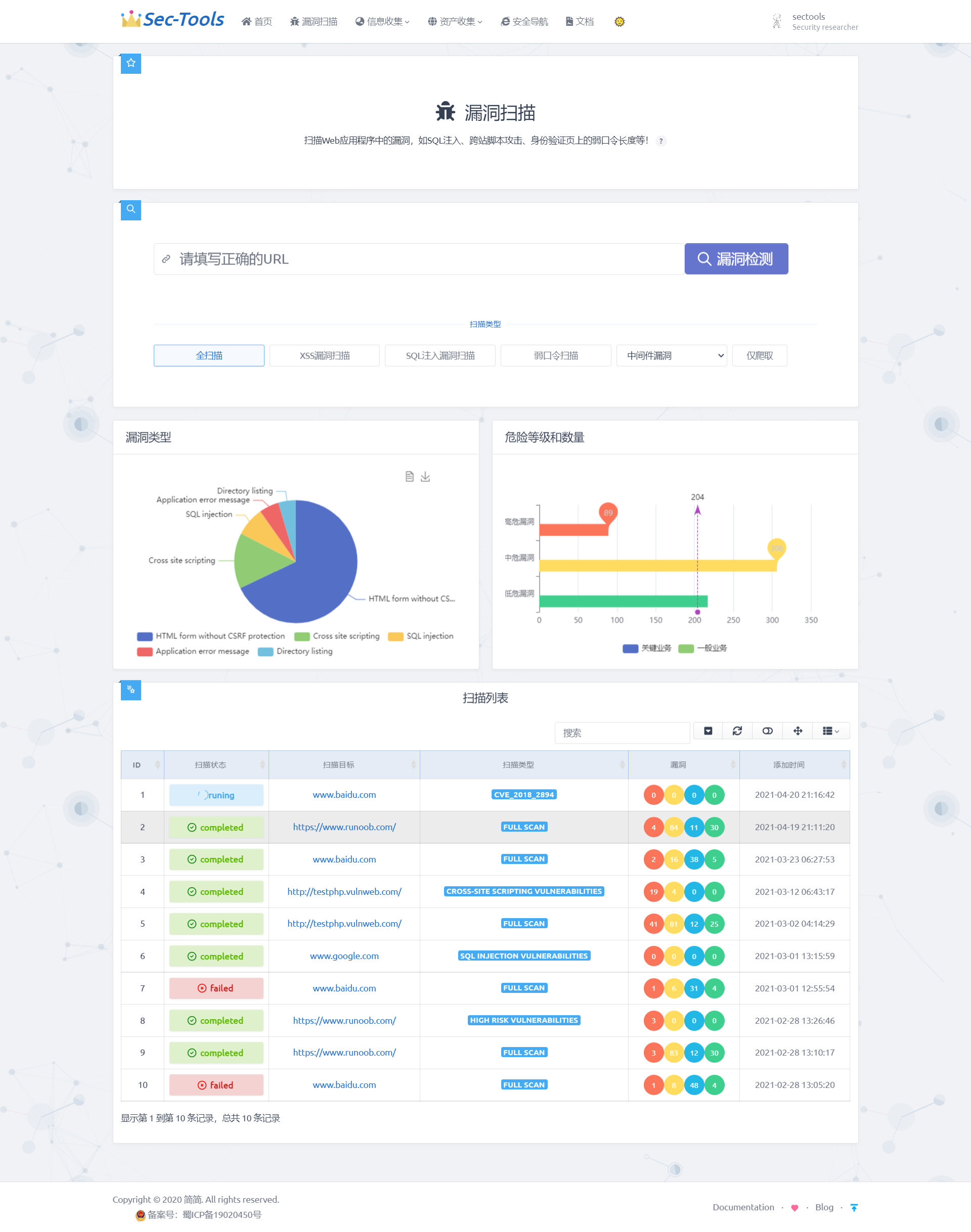
点击扫描目标跳转到漏洞结果页:
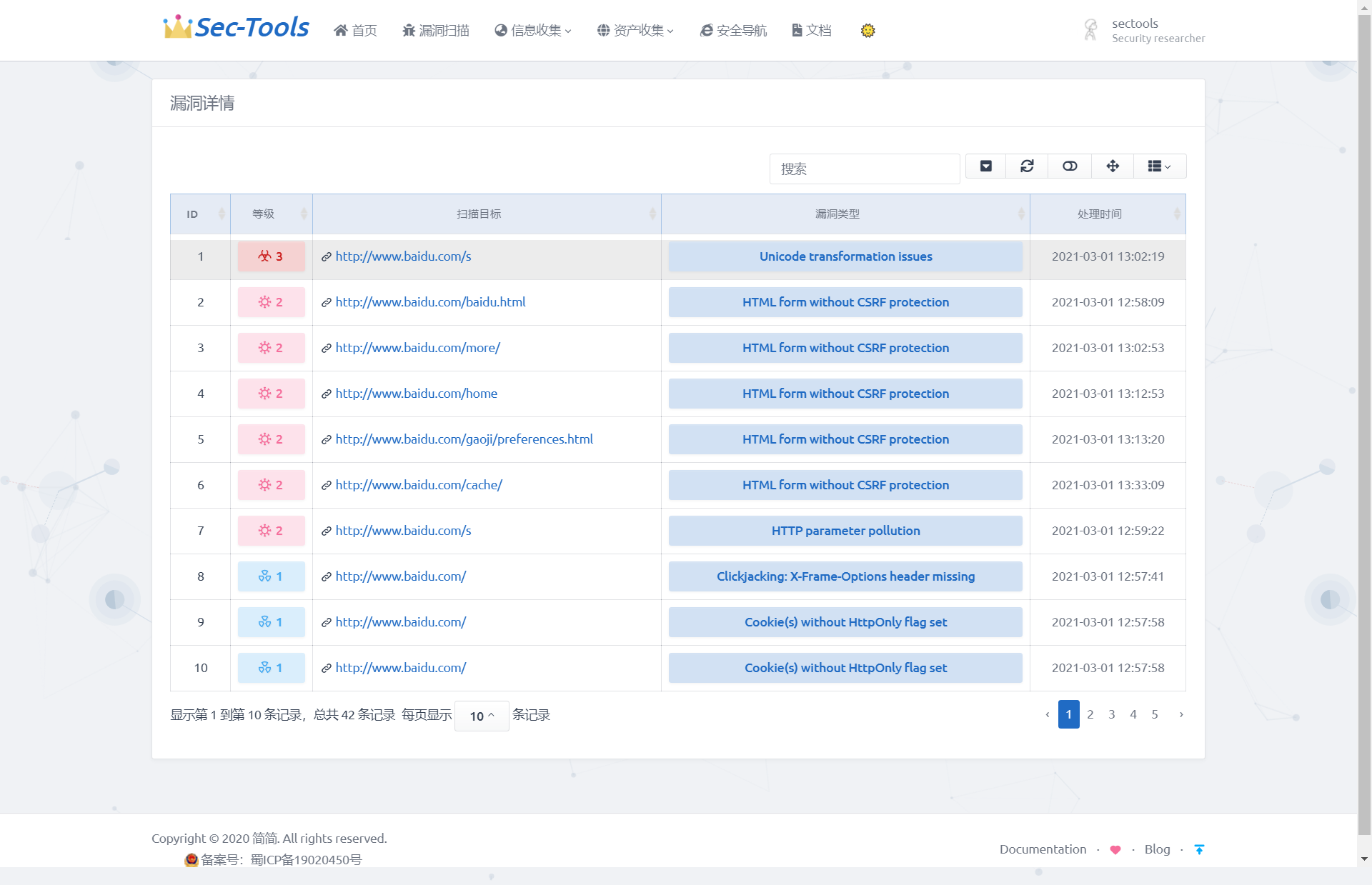
再点击扫描目标的跳转到漏洞详情页:
详细实现
添加扫描目标
漏洞扫描最开始的工作是添加扫描目标到 AWVS 的扫描队列中。AWVS 提供了一个 API 接口: /api/v1/targets,使用 POST 请求, POST 请求参数为:{"address":"XXXX.XXXX.XXXX","description":"xxxx","criticality":"10"}。
当目标添加成功后会返回一个 target_id ,这个值在所有扫描中是唯一的。通过 target_id 判断目标是否添加成功。添加完目标后并没有开始扫描,需要使用另一个 API 接口:/api/v1/scans,使用 POST 请求,传入刚刚添加目标生成的 target_id 和用户选择的扫描类型,POST 请求参数为:{"target_id":"xxxxxxx","profile_id":"xxxxxxx"}。开始扫描将会返回状态码200。
使用 Python 的第三方库 requests 来实现 API 接口访问。核心代码如下:
#Target: POST请求/api/v1/targets
try:
#data包含目标URL和类型,auth_headers包含API_KEY
response = requests.post(targets_api, auth_headers, data, False)
result = response.json()
target_id = result.get('target_id')
return target_id
except Exception:
return None
#Scan: POST请求/api/v1/scans
try:
response = requests.post(scan_api, data, auth_headers, False)
status_code = 200
except Exception:
status_code = 404
return status_code
API 接口已经实现,还需要获取用户输入的数据。由于本系统是基于 Django 实现的,所以使用 HTML+JavaScript 提供用户界面和接受和发送数据到后端,后端使用 Python 实现。首先在 urls.py 里面加入添加访问路径
path('vuln_scan', views.vuln_scan, name='vuln_scan')
在 views.py 中定义 vuln_scan() 函数接收前端的用户输入,并调用已经写好的 API 函数。用户输入的 url 为扫描的目标,扫描类型包括SQL注入、XSS漏洞、弱口令和全扫描,其中全扫描就是扫描所有类型的漏洞,如果添加成功后返回的 target_id 不是 None,说明添加成功,就可以开始调用开始扫描的 API,开始扫描后返回状态码,为200则开始扫描,返回成功否则返回失败。核心代码如下:
@csrf_exempt
def vuln_scan(request):
#通过POST请求获取用户输入的URL和扫描类型
url = request.POST.get('ip')
scan_type = request.POST.get('scan_type')
t = Target(API_URL, API_KEY)
#将目标URL添加到扫描队列中
target_id = t.add(url)
#如果target_id不为None,则开始扫描
if target_id is not None:
s = Scan(API_URL, API_KEY)
status_code = s.add(target_id, scan_type)
if status_code == 200:
return success()
return error()
最后使用 JavaScript 来实现发送用户输入的数据,选择通过 POST 方法发送数据,并在发送之前判断用户输入的合法性,核心代码如下:
function get_scan_info(ip , scan_type) {
#使用POST请求发送用户输入
$.post('/vuln_scan', {
ip: ip ,
scan_type: scan_type
}, function (data) {
if (data.code !== 200) {
......
} else {
......
}
......});
}
var domain = $('input[name=scan_url]').val();
#使用循环判断用户选择的扫描类型
for(var i=0; i<document.getElementsByName("scan_type").length; i++) {
if (document.getElementsByName("scan_type")[i].checked) {
var scan_type=document.getElementsByName("scan_type")[i].value;
}
}
if(domain){
get_scan_info(domain,scan_type)
}else{
......
}
总体来说,通过上述的代码实现,实现了将用户输入通过 JavaScript 传输给后台,后台接收数据后将调用 AWVS API,然后 AWVS 开始根据用户输入开始扫描目标 URL,扫描结束后将结果保存在数据库中。实现效果如下:
获取扫描结果
在上一小节中,将目标扫描的结果保存到数据库中,我们需要得到所有的扫描目标,‘/api/v1/scans‘,请求方式为 GET,请求成功后会返回所有扫描目标的信息,利用这个 API 可以实现展示所有扫描目标。要实现展示每个扫描目标的所有漏洞的功能,需要按照 target_id 来在所有扫描目标中搜索。AWVS 也提供了相应的 API,我们需要用到的 API 为:/api/v1/vulnerabilities
?q=severity:{int};criticality:{int};status:{string};cvss_score:{logicexpression};cvss_score:{logicexpression};target_id:{target_id};group_id:{group_id}。请求方式为 GET。利用 target_id 搜索每个扫描目标。这也解决了漏洞细节页面的 URL 问题。当使用 target_id 搜索扫描目标成功时将会返回这个目标的所搜漏洞信息,包括这个目标包含的漏洞个数、每个漏洞的危险等级、扫描时间、扫描类型、扫描状态等信息。
具体实现步骤和添加扫描目标大体相似,首先第一步使用 requests 来实现 API 请求。核心代码如下:
#获取所有扫描目标
response=requests.get(scan_api, self.auth_headers, False)
scan_response=response.json().get('scans')
for scan in scan_response:
scan['request_url'] = request_url
scan_list.append(scan)
return scan_list
#搜索状态为“open“,对应target_id的扫描目标
vuln_search_api=f'{vuln_api}?q=status:{status};target_id:{target_id}'
try:
#使用get方式请求
response = requests.get(vuln_search_api, auth_headers, False)
#返回搜索结果目标的所有漏洞信息
return response.text
except Exception:
return None
在 urls.py 中加入用户访问的 url ,这个需要提供一个 target_id 方便后续功能的实现,先获取所有目标的target_id,然后使用循环将所有 target_id 加入到 urlpatterns 列表中。因为在 Django 中 views 函数通常只能使用一个 request 参数,由于这里需要将 target_id 传入到 views 函数中,使用正则匹配的 “(?P<target_id>.*)$” 接收传入的 target_id,在 views 里对应函数的第二个形参名必须和 <> 里的值一致才有效。核心代码如下:
path('vulnscan', views.vulnscan, name="vulnscan"),
for target_id in target_ids:
#使用正则匹配获取第二个参数:taget_id
urlpatterns.append(url(r'^vuln_result/(?P<target_id>.*)$', views.vuln_result, name='vuln_result/'+target_id))
在 views.py 里定义函数 vulnscan(request) 获取所有对应的目标漏洞信息。使用 API 得到返回的漏洞危险等级、扫描目标URL、每个漏洞唯一标识的 vuln_id、扫描类型、扫描处理时间,API 返回的扫描处理时间不是标准的时间格式,使用正则匹配的方式,将其转换为 “%Y-%m-%d %H:%M:%S“ 的格式,再定义函数 vuln_result(request,target_id),根据 target_id 获取扫描目标中所有漏洞信息,包括存在漏洞的URL、漏洞类型、状态和处理时间等信息。核心代码如下:
@login_required
def vuln_result(request, target_id):
d = Vuln(API_URL, API_KEY)
data = []
vuln_details = json.loads(d.search(None,None, "open", target_id=str(target_id)))
id = 1
for target in vuln_details['vulnerabilities']:
item={
'id': id,
'severity': target['severity'],
'target': target['affects_url'],
'vuln_id':target['vuln_id'],
'vuln_name': target['vt_name'],
'time': re.sub(r'T|\..*$', " ", target['last_seen'])
}
id += 1
data.append(item)
return render(request,'vuln-reslut.html',{'data': data})
在这个子功能中,前端的数据展示使用的是 Bootstrap Table。这个模板有很多实用的功能,比如表格的搜索功能、分页展示功能等等,增加了用户体验。表格的数据在 HTML 中使用双花括号来接收,在 views.py 函数中返回的到相应的 HTML 页面时,将 data 字典一起返回。这样的返回方式可以将使用字典中的 key 值获取对应的 values 值。还可以是使用 if-else、for 等语句来分类展示数据。核心代码如下:
{% for item in data %}
……………
# 这个只展示了扫描目标列,其他列类似
{{ item.target }}
……………
{% endfor %}
最后实现的效果如下图所示,根据每个扫描状态不同有不同的显示,使用红黄蓝绿来分类高危、中危、低危、info等级的漏洞。最后展示了扫描的处理时间。
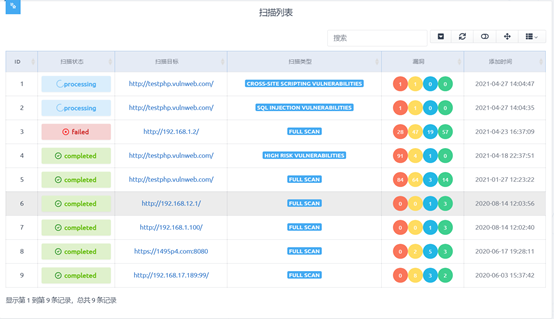
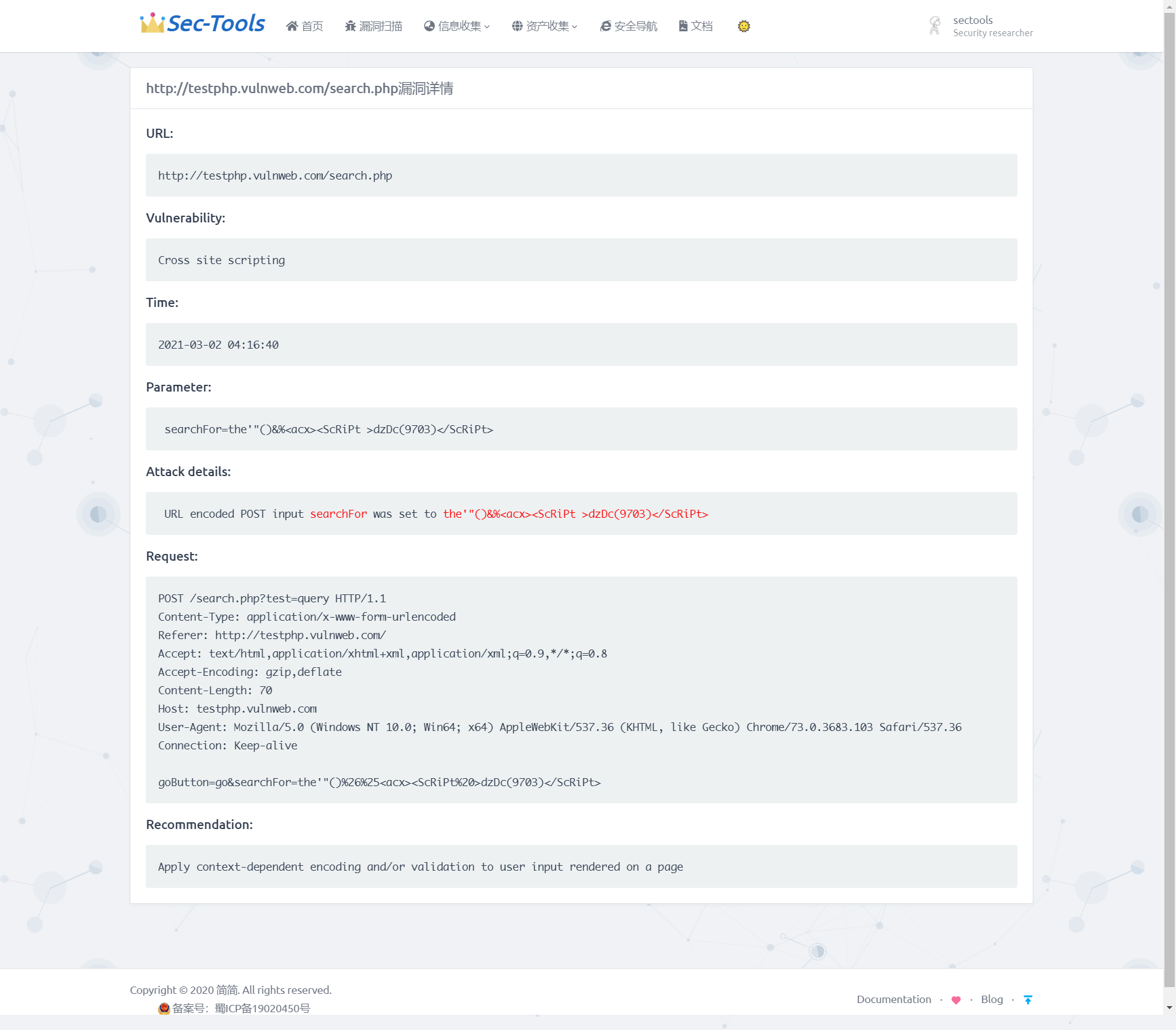
表格中扫描目标列可以点击进入查看目标的所有漏洞信息,如下图所示,展示了特定的扫描目标每个漏洞的危险等级、存在漏洞的URL、漏洞的类型。
获取漏洞细节
在实现漏洞扫描和结果展示后,还需要获取每个漏洞的细节。包括导致漏洞的请求参数、测试的 payload、数据请求包、简要的修复建议等等。因为每个漏洞也存在一个唯一的标识 vuln_id,可以根据这个值查询指定漏洞的所有信息。使用的 API 为:/api/v1/vulnerabilities/{vuln_id},请求方式为 GET。
同样地,首先使用 requests 来实现 API 的调用,传入 vuln_id 来查询指定漏洞的所有信息,代码如下:
#获取指定漏洞的相关信息
def get(self, vuln_id):
vuln_get_api = f'{self.vuln_api}/{vuln_id}'
try:
#使用GET请求将vuln_id传给API,结果以json格式返回
response = requests.get(vuln_get_api, auth_headers, False)
return response.json()
except Exception:
return None
在 urls.py 中添加漏洞细节的 url,这里与上一节展示扫描目标的所有漏洞类似,都用正则匹配的形式接收 views.py里函数的第二个形参,但是这里不在使用 target_id 而是使用 vuln_id。代码如下:
for vuln_id in vuln_ids:
urlpatterns.append(url(r'^vuln_detail/(?P<vuln_id>.*)$', views.vuln_detail, name='vuln_detail/' + vuln_id))
在 views.py 里面定义 vuln_details(request,vuln_id) 函数,根据 vuln_id 查询指定漏洞的相关信息。该函数将 API 返回的值中有用的信息提取出来到字典 data 里,返回给 vuln-details.html 页面,使用 双花括号 来接收该漏洞的受影响的URL、处理时间、漏洞类型、漏洞测试参数、数据请求包、简要的修复建议等信息。实现效果如下图所示。
@login_required
def vuln_detail(request,vuln_id):
d = Vuln(API_URL,API_KEY)
data = d.get(vuln_id)
print(data)
parameter_list = BeautifulSoup(data['details'], features="html.parser").findAll('span')
request_list = BeautifulSoup(data['details'], features="html.parser").findAll('li')
data_dict = {
'affects_url': data['affects_url'],
'last_seen': re.sub(r'T|\..*$', " ", data['last_seen']),
'vt_name': data['vt_name'],
'details': data['details'].replace(" ",'').replace('</p>',''),
'request': data['request'],
'recommendation': data['recommendation'].replace('<br/>','\n')
}
try:
data_dict['parameter_name'] = parameter_list[0].contents[0]
data_dict['parameter_data'] = parameter_list[1].contents[0]
except:
pass
num = 1
try:
Str = ''
for i in range(len(request_list)):
Str += str(request_list[i].contents[0])+str(request_list[i].contents[1]).replace('<strong>', '').replace('</strong>', '')+'\n'
num += 1
except:
pass
data_dict['Tests_performed'] = Str
data_dict['num'] = num
data_dict['details'] = data_dict['details'].replace('class="bb-dark"','style="color: #ff0000"')
return render(request, "vuln-detail.html", {'data': data_dict})
基于POC验证的中间件漏洞扫描
本系统使用POC脚本实现对一些中间件的漏洞扫描[7],包括Weblogic、Tomcat、Drupal、JBoss、Nexus、Struts2等等。通过每个漏洞的特点,使用Python编写不同的POC脚本验证目标是否存在该漏洞。
首先这里的用户界面和基于AWVS的漏洞扫描共用,单独加入了中间件漏洞CVE编号的选择。使用JavaScript发送用户输入的数据到后端。核心代码如下:
#使用POST请求提交用户的输入
function get_Middleware_scan(ip , CVE_id) {
$.post('/Middleware_scan', {
ip: ip , #目标URL
CVE_id: CVE_id #选择的CVE编号
}, function (data) {
#处理返回结果
………
………});
}
将目标添加到数据库后,再查询数据库开始扫描,通过 ajax 来访问 start_Middleware_scan 调用开始扫描的函数,由于扫描时间可能会很长,需要设置足够的 timeout 来等待扫描的结果返回。核心代码如下:
$.ajax({
#使用POST请求发送目标URL和CVE编号,设置超时为1秒
type: "POST",
url: '/start_Middleware_scan',
timeout: 10000,
data: {
ip: ip,
CVE_id: CVE_id
}
});
在 urls.py 里加入中间件漏洞扫描的访问路径,需要加入两个路径:’Middleware_scan‘,‘start_Middleware_scan’。前者是用户添加扫描目标时的路径,用于接收用户输入的目标和CVE编号之后将其插入数据库。后者是将目标插入数据库之后,通过时间戳、状态、目标 URL 以及 CVE 编号查询出来开始扫描。当扫描结束时更新数据库中对应扫描目标的状态。这样的设计可以实时的看到扫描的状态。
数据库使用的是 Sqlite,在 models.py 里创建一个数据库表 Middleware_vuln ,字段包括ID、目标URL、状态、结果、CVE编号、时间戳。在 Django 里定义这个类表示我们需要创建的数据库,在 modles.py 里创建好之后,使用命令python manage.py makemigrations来记录 modles.py 的所有改动,并且将这个改动迁移到 migrations 这个文件下生成一个文件例如:0001文件,如果你接下来还要进行改动的话可能生成就是另外一个文件不一定都是0001文件,但是这个命令并没有作用到数据库,再使用命令 python manage.py migrate 将根据刚刚检测到的改动来创建数据库表和字段属性。核心代码如下:
class Middleware_vuln(models.Model):
#类名为数据库表名,变量名为字段名,字段属性定义如下
id = models.AutoField(primary_key=True)
url = models.CharField(max_length=100, null=True)
status = models.CharField(max_length=20, null=True)
result = models.CharField(max_length=100, null=True)
CVE_id = models.CharField(max_length=100, null=True)
time = models.CharField(max_length=100, null=True, unique=True)
在添加目标和开始检测的时候我们需要插入数据库和查询数据库,这里使用 Django 的函数来处理数据库的增删查改。对于 Middleware_vule 的插入使用 Middleware_vuln.objects.create(url, status, result, CVE_id, time),更新使用 Middleware_vuln.objects.filter(time).update(status, result)。还需要使用 try-except 来处理异常情况并打印出错信息。
def insert_Middleware_data(url, CVE_id, Time, result=None, status="runing"):
try:
Middleware_vuln.objects.create(url=url, status=status, result=result, CVE_id=CVE_id, time=Time)
print("insert success")
return True
except:
print("data insert error")
return False
def update_Middleware_data(url, CVE_id, Time, result):
try:
Middleware_vuln.objects.filter(url=url, status='runing', CVE_id=CVE_id, time=Time).update(status="completed", result=result)
print("update success")
except:
print("data updata error")
在views.py里定义 Middleware_scan() 获取用户输入,并插入到数据库中,其中时间戳 Time 为全局变量,作为后面开始扫描部分查询数据库的条件,在插入数据成功就返回 success(),否侧返回 error(),这里返回的函数时返回的状态码,success()返回的是200,error()返回404,通过上面 JavaScrip t接收后做出判断,并弹出相应的提示框,核心代码如下:
Time = 0.0
@csrf_exempt
@login_required
def Middleware_scan(request):
#使用POST请求获取用户输入,并将其插入数据库中。
#Time作为全局变量插入到数据库中,作为查询目标信息的条件。
global Time
try:
url= request.POST.get('ip')
CVE_id = request.POST.get('CVE_id').replace('-',"_")
Time = time.time() # time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(t))时间戳转日期格式
if insert_Middleware_data(url, CVE_id, Time):
return success()
except:
return error()
又定义函数 start_Middleware_scan(),实现将数据库中时间戳为 Time,状态为 run 的目标查询出来,根据 CVE编号调用对应的 POC 脚本。最后更新数据库的扫描结果和扫描状态,由于在上一步中将数据插入数据库中可能会花费一点时间,所以需要使用 sleep() 等待数据插入后再进行查询工作和扫描工作,保证不遗漏扫描目标。
@csrf_exempt
@login_required
def start_Middleware_scan(request):
try:
url = request.POST.get('ip')
ip, port = urlparse(url).netloc.split(':')
CVE_id = request.POST.get('CVE_id').replace('-', "_")
time.sleep(5) #等待数据插入成功后在查询出来扫描
msg = Middleware_vuln.objects.filter(url=url, status='runing', CVE_id=CVE_id, time=Time)
print(msg)
#扫描条目可能不止一条,需要使用循环来扫描
for target in msg:
result = POC_Check(target.url, target.CVE_id)
#将扫描结果和状态更新
update_Middleware_data(target.url, target.CVE_id, Time, result)
return success()
except:
return error()
端口扫描
本系统端口扫描当用户指定了目标IP地址后,系统正式工作,IP传入后台对目标进行扫描,扫描完成后将开放端口和对应服务显示到前端界面上。在“按端口分布划分”和“按协议类型划分”两个栏目中对端口划分进行讲解,使用户免于查询的繁琐。同时该模块还将内置常见端口查询表,在此可进行端口及其对应服务和功能的相关查询和筛选,通过这一系列功能用户能够更加清晰的认识到目标主机开放了哪些服务,以此来分析可能存在漏洞的服务。
设计思路
本系统端口扫描的实现方法是利用Python提供的库函数Socket进行调用,通过TCP三次握手与目标计算机的端口建立连接。当完成一次完整的三次握手时,则可以推断出端口和对应服务是开放的,反之则没有开放,为了提高了扫描的效率,本系统引入多线程扫描机制。
实现效果

详细实现
端口扫描
通过 Python 直接定义 socket,尝试与目标端口进行连接。本程序中使用sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM);的方式进行 TCP 连接,调用sock.connect_ex((ip,port)),来尝试连接端口,如果端口开放则返回0,否则返回错误代码。使用try语句来捕获异常,如果 socket 连接超时,则返回异常处理信息。核心代码如下:
def socket_scan(self, hosts):
'''端口扫描核心代码'''
global PROBE
socket.setdefaulttimeout(1)
ip, port = hosts.split(':')
try:
if len(self.port) < 25:
# 创建套接字
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# TCP/IP三次握手建立连接
result = sock.connect_ex((ip, int(port)))
# 调用socket.connect_ex((ip, port)),端口开放返回0,否则返回错误代码
# 实现和nmap的全连接扫描类似的功能。
if result == 0: # 成功建立TCP链接
self.port.append(port) # 结果集中增加端口
for i in PROBE: # 通过HTTP1.1刺探
sock.sendall(i.encode()) # 发送完整的TCP数据包
response = sock.recv(256) # 接受最大256byte
sock.close()
if response:
break
if response:
for pattern in SIGNS:
pattern = pattern.split(b'|')
if re.search(pattern[-1],response, re.IGNORECASE):
# 正则匹配banner信息与字典中的服务
proto = '{}:{}'.format(pattern[1].decode(), port)
self.out.append(proto) # 添加至输出结果
break
else:
self.num = 1
except (socket.timeout, ConnectionResetError): # 异常处理
pass
except:
pass
如果这样单线程(串行)阻塞运行,会耗费大量时间,因此,通过并发的方式,并发请求,提升扫描速度,通过对比扫描300个端口单线程需要30s左右,多线程仅需10s左右。
本端口扫描功能中采用了并发64条线程来进行扫描,因此,在定义run方法时,每个线程扫描的两个端口号间差数为64,在程序中使用 concurrent.futures 来实现。concurrent.futures 模块提供了一个高水平的接口用于异步执行调用。异步执行可以使用线程实现,使用 ThreadPoolExecutor,或者独立的进程,使用 ProcessPoolExecutor 实现。两者都实现相同接口,都是由抽象 Executor 类定义的。
THREADNUM = 64 # 线程数
def run(self, ip): #多线程扫描
hosts = []
global PORTS, THREADNUM
for i in PORTS:
hosts.append('{}:{}'.format(ip, i))
try:
with concurrent.futures.ThreadPoolExecutor(
max_workers=THREADNUM) as executor:
executor.map(self.socket_scan, hosts)
except EOFError:
pass
端口查询表
端口查询表功能通过收集网上端口信息建立端口查询库,涉及到的端口数据是存储在数据库中,包括端口ID、端口号、端口对应服务、端口对应协议和端口所属状态。端口查询表结构如下表所示。
| 字段名 | 字段类型 | 允许空 | 是否主键 | 备注 |
|---|---|---|---|---|
| id | integer | Not null | True | 端口ID |
| num | bigint | Not null | False | 端口号 |
| service | text | Not null | False | 端口对应服务 |
| protocol | Varchar(20) | Not null | False | 端口对应协议 |
| status | Varchar(10) | Not null | False | 端口所属状态 |
端口查询数据库采用Django Model进行建立,字段包含端口号、服务、协议、和状态。实现代码如下:
class PortList(models.Model):
'''端口查询表'''
num=models.BigIntegerField(verbose_name='端口号')
service=models.TextField(max_length=100,verbose_name='服务')
protocol=models.CharField(max_length=20,verbose_name='
协议',blank=True,default='未知')
status=models.CharField(max_length=10,verbose_name='
状态',blank=True,default='未知')
class Meta:
# 后台表头设置
verbose_name=verbose_name_plural='端口列表'
数据库建立后需要进行后台注册,这样可以进入后台对数据进行管理,实现代码如下:
@admin.register(PortList)
class PortListAdmin(ImportExportModelAdmin):
# 设置哪些字段显示在后台
list_display = ('num', 'service', 'protocol', 'status',)
# 设置num字段进入编辑界面
list_display_links = ('num',)
search_fields = ('num', 'service',)
# 过滤器,按字段进行筛选
list_filter = ('protocol','status')
# 设置num为默认排序字段
ordering = ('num', )
list_per_page = 15 #设置每页显示数据条数
指纹识别
该模块采用提取指纹特征码特征信息来识别Web指纹,系统通过构造大量特殊的HTTP请求与Web服务器交互,从其响应数据包信息中提取提取指纹特征信息,然后通过与指纹数据库进行比对,从而获取到Web服务器及应用的组件信息和版本信息。通过发现这些特征信息并对它进行识别可以帮助我们快速地制定渗透策略,是渗透环节中关键的一步。
设计思路
国内外对Web服务器及应用指纹的研究,主要都是通过构造大量特殊的HTTP请求与Web服务器交互,从其响应数据包信息中提取提取指纹特征信息,然后通过与指纹数据库进行比对,从而获取到Web服务器及应用的组件信息和版本信息。本文采用基于关键字特征匹配的方法实现指纹识别功能,为了使检测结果更加准确,对比网上一些主流的指纹数据库,对本系统的数据库进行了一系列优化。
实现效果
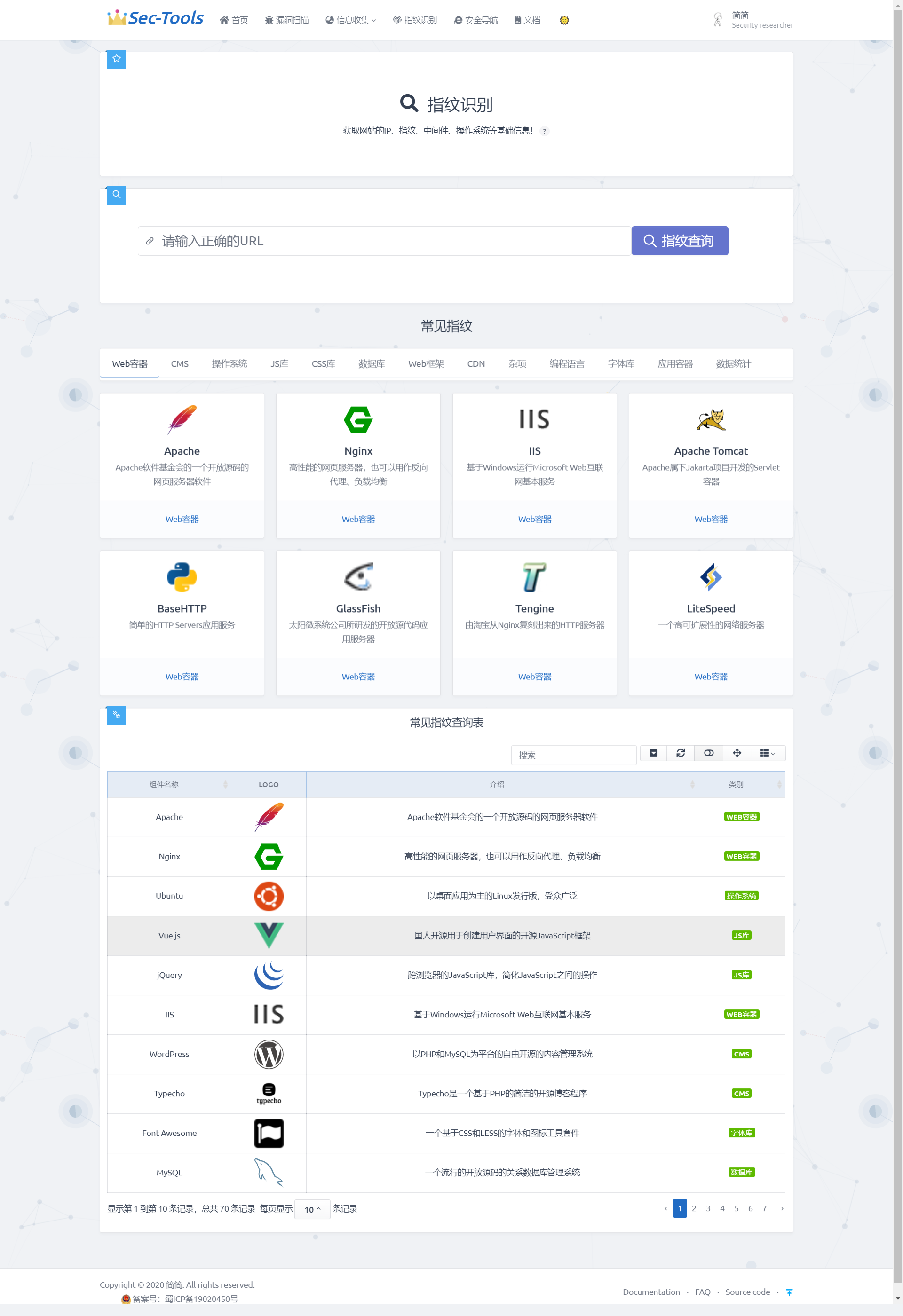
详细实现
指纹识别流程中最关键的就是提取指纹特征这一步骤。提取指纹特征首先需要确定应该提取响应数据报文中的哪些数据。因此需要设计特征提取算法对响应数据报文进行分析,响应数据包是由响应行、响应头、响应体三部分构成。响应行由HTTP版本、状态码、状态码描述构成。响应头用于指示客户端如何处理响应体,响应头里面包含很多的组件信息,用于告诉浏览器响应的类型、字符编码服务器类型和字节大小等信息。响应体则是服务器根据客户端的请求返回给客户端的具体数据。响应头和响应体中包含了能够识别Web指纹组件的字段内容,因此,对响应头和响应体中关键字段的提取,是实现指纹识别技术的核心。
指纹识别技术分为信息收集阶段和Web指纹识别阶段。
(I)信息收集阶段:通过用户输入的URL,收集Web应用的特定字段信息,返回页面关键字或者特殊文件和路径等这些特征。收集的关键数据越多对接下来的指纹识别结果越准确。
(2)Web指纹识别阶段:该阶段包含两部分,一部分是指纹库的建立,该部分主要负责从已知的Web应用程序中收集特征信息,并且建立指纹特征库;本文通过分析HTTP响应数据报文,设计了网站指纹的提取规则,通过分析响应头字段和响应体内容构建了一个指纹组件信息库,信息库采用JSON格式进行存储。指纹信息是从Wappalyzer和FOFA等平台上进行收集归纳的。另一部分从待测的Web应用程序中收集特征信息,并与指纹特征库中的数据进行比较,从而识别出待测的web应用程序。
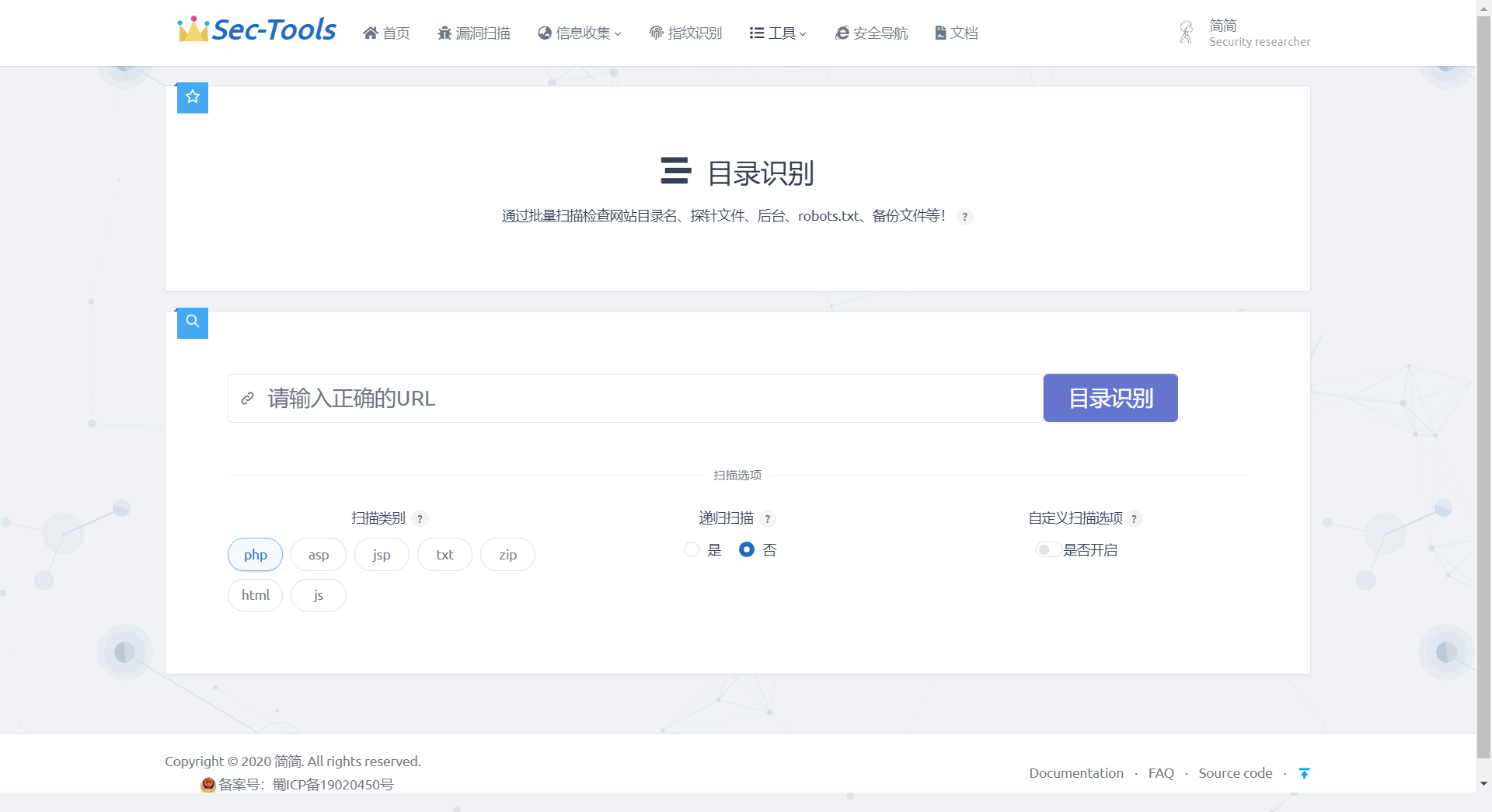
目录扫描
目录识别参照dirsearch实现,包含php、asp、jsp等网站类型进行扫描,还设置了递归扫描和自定义扫描选项。支持自定义前后缀或者子目录。
设计思路
Dirsearch 扫描的结果通过 JSON的格式保存在对应的路径下,因此我们可以减轻对数据库的依赖。获取的数据被分成 URL 和 TIMR,URL下又分为 content-length、path、redirect、starus四个部分。因为在 JSON 格式中被不同类型括号的数据会被 Django 解析为列表、字典等格式,因此我们需要对获得的 JSON 数据进行处理,将其转换为 Django 可以识别的数据,使之在前端进行读取。
要正确解析数据,需要先理解 Python 数据结构和 JSON 数据的转换方法。我们基于当前的固定的 JSON 格式去解析取得的数据。
实现效果

信息泄露
该模块主要为用户提供常见的信息泄露检查。在前端直观的展示后台地址、配置文件等可能存在泄露的信息,在结果列表中,用户可以非常清晰的知道某个Web服务存在的信息泄露问题。

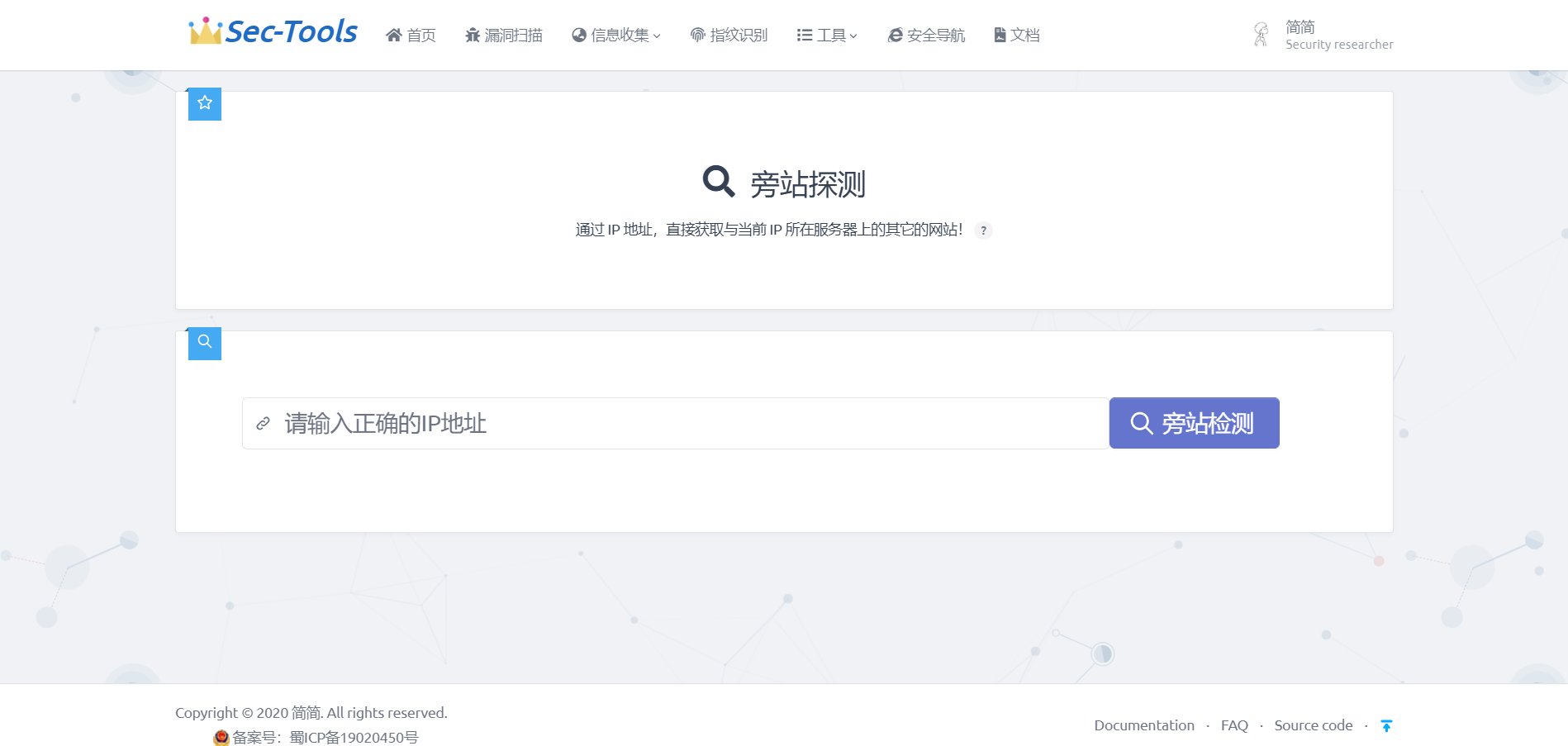
旁站探测
该模块主要对通过 IP 地址,直接获取与当前 IP 所在服务器上的其它网站, 本模块直接调用 api 实现
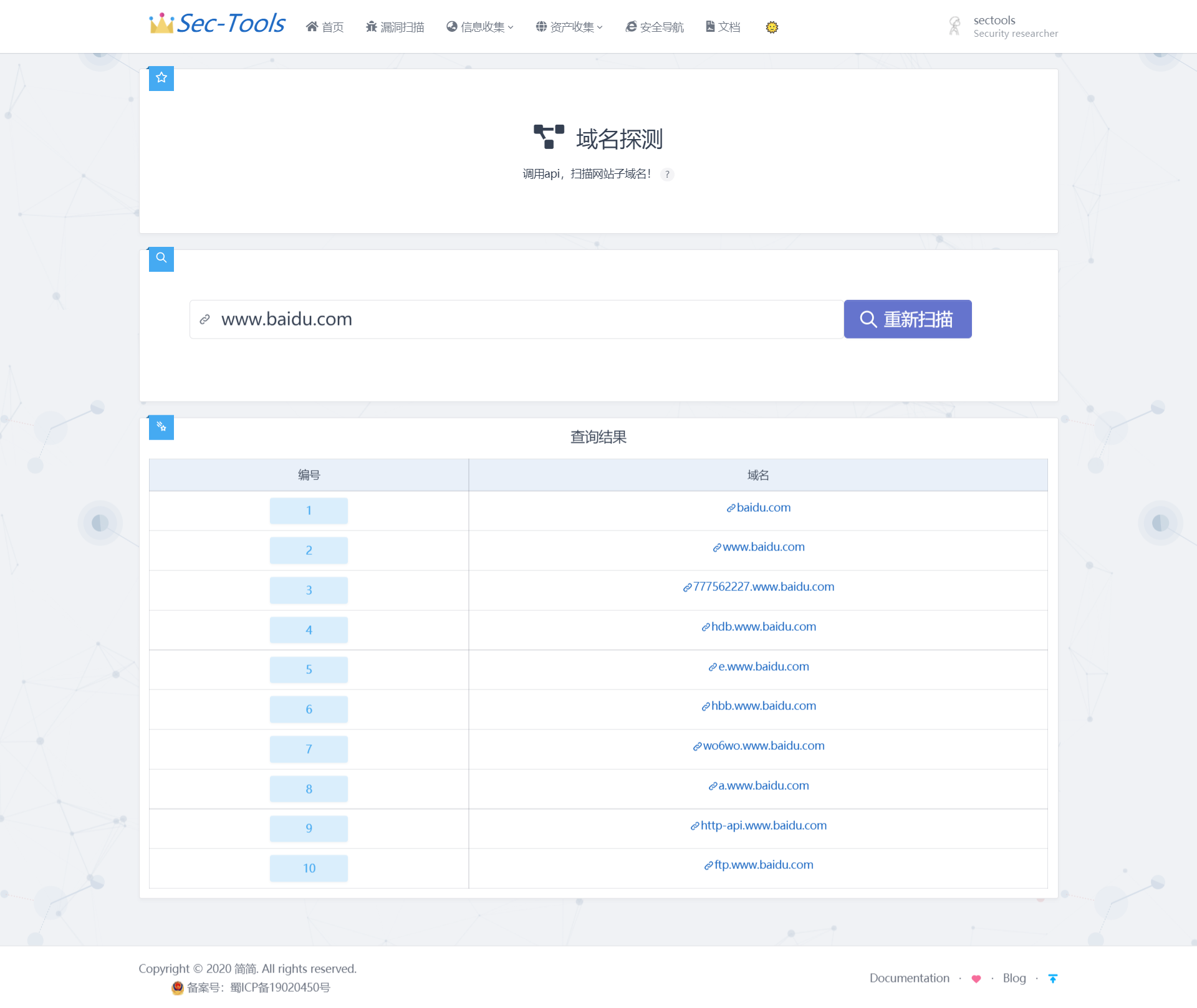
域名探测
该模块主要通过调用 api 来扫描网站的子域名
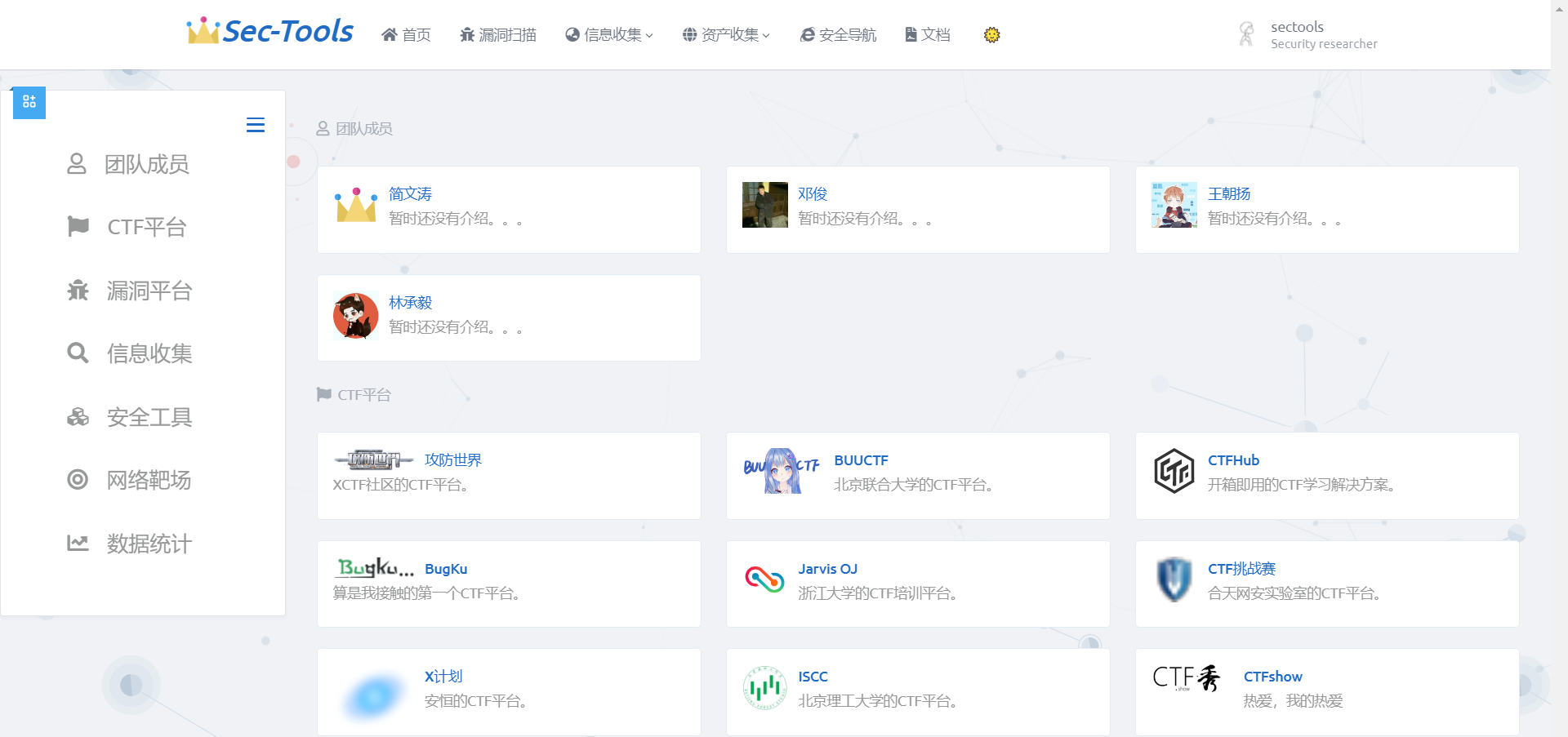
安全导航
安全导航页面的灵感来自于Viggo大佬开发的Webstack项目,该项目是基于Bootstrap开发的纯前端页面,因此前端我沿用了Webstack 的风格并融合了Tabler UI 风格,并用 Django 写了后台管理,可在线对分类和条目进行管理。
前端页面
后台管理页面
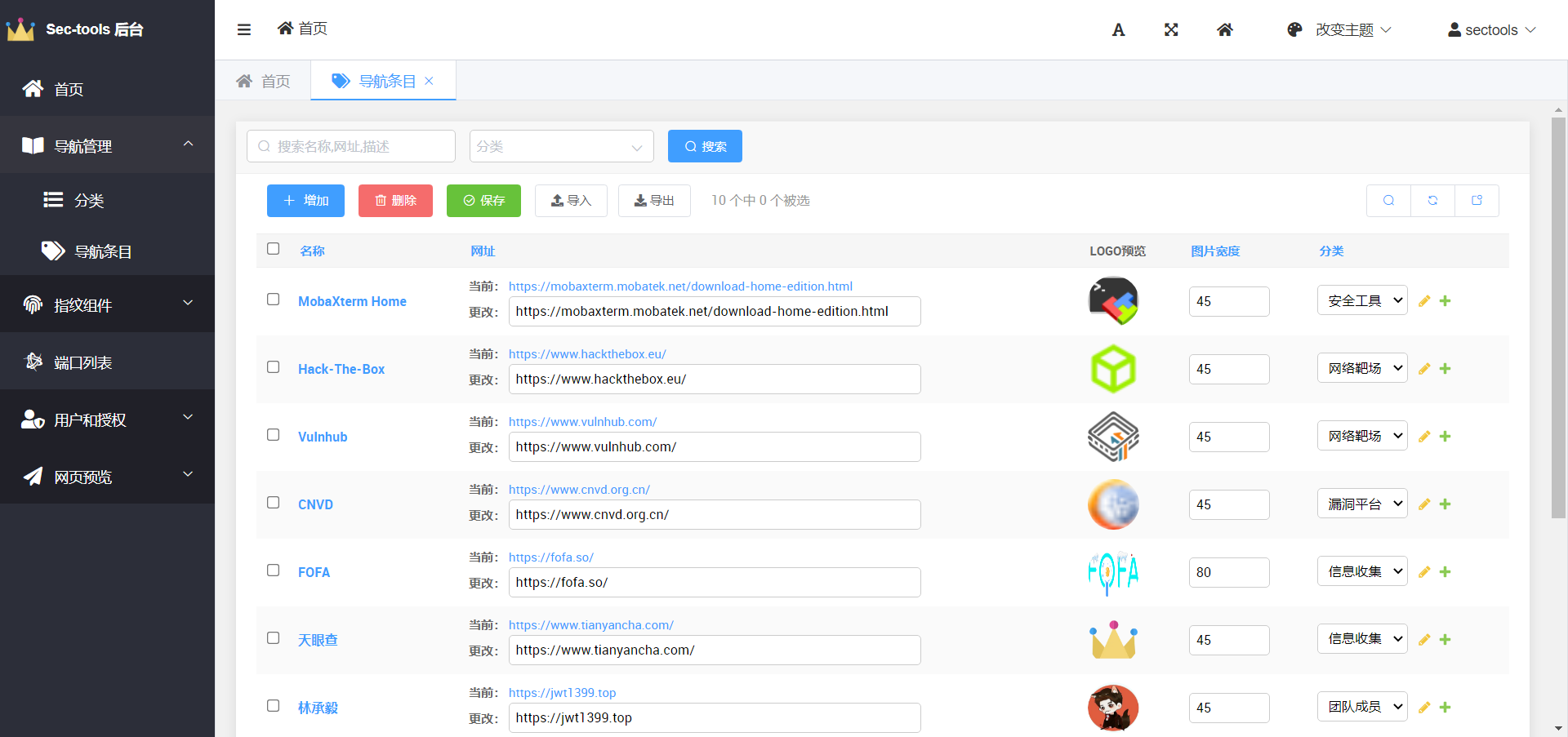
数据库设计

导航条目-Item
标题title 描述desc 网址url 分类category(外键) 图片img 图片宽度img_width
class Item(models.Model):
'''导航条目'''
title = models.CharField(max_length=50,verbose_name='名称')
desc = models.TextField(max_length=100,verbose_name='描述')
url = models.URLField(verbose_name='网址',blank=True)
img = models.URLField(default='https://jwt1399.top/favicon.png',verbose_name='logo')
img_width = models.IntegerField(default=45, verbose_name='图片宽度')
category = models.ForeignKey(Category, blank=True, null=True, verbose_name='分类', on_delete=models.CASCADE)
class Meta:
verbose_name=verbose_name_plural='导航条目'
#后台条目图片预览
def img_admin(self):
return format_html( '<img src="{}" width="50px" height="50px" style="border-radius: 50%;" />',self.img,)
img_admin.short_description = 'logo预览'
def __str__(self):
return self.title
条目分类-Category
名称name 排序 sort 是否添加到导航栏add_menu 图标icon
class Category(models.Model):
"""条目分类"""
name = models.CharField(max_length=20, verbose_name='名称')
sort = models.IntegerField(default=1, verbose_name='显示顺序')
add_menu = models.BooleanField(default=True, verbose_name='添加到导航栏')
icon = models.CharField(max_length=30, default='fas fa-home',verbose_name='图标')
class Meta:
verbose_name_plural=verbose_name = '分类'
#统计分类对应条目数,并放入后台
def get_items(self):
return len(self.item_set.all())
get_items.short_description = '条目数' # 设置后台显示表头
#后台图标预览
def icon_data(self):#引入Font Awesome Free 5.11.1
return format_html('<h1><i class="{}"></i></h1>',self.icon) #转化为<i class="{self.icon}"></i>
icon_data.short_description = '图标预览'
def __str__(self):
return self.name
文档页
将 Docsify 直接嵌入了 Django 中构造了文档页。

兼容性
Phone端
| 竖屏 | 横屏 |
|---|---|
 |
 |
Pad端
| 竖屏 | 横屏 |
|---|---|
 |
 |
版本变更记录
v2.7(2021-04-18)
- 新增
域名探测功能; - 新增
中间件漏洞扫描; - 修复
忘记密码功能; - 优化AWVS未启动报错信息;
- 优化
用户登录逻辑; - 优化
漏扫详情页UI; - 优化导航栏布局;
- 优化若干小细节;
v2.6(2021-03-31)
- 新增漏洞
扫描详情功能; - 新增首页
仪表盘; - 安全导航页导航栏
移动端优化; - 安全导航页目录栏
缩放优化; - 注册&登录界面优化;
- 文档页
导航栏优化; - 新增
UI夜间模式; - 修复若干
UI显示Bug;
v2.5(2021-03-02)
- 新增了
漏洞扫描功能; - 端口扫描页新增
常见端口查询表; - 信息泄露页新增
常见信息泄露列表; - 指纹识别页新增
数据分析图表; - 漏洞扫描页
界面优化;
v2.4(2021-02-22)
- 新增了
目录识别功能; - 重写
欢迎页; - 安全导航页
移动端界面适配; - 安全导航页
UI优化; - 目录识别页
界面优化; - 指纹识别页新增
常见指纹显示与搜索; - 引入
Boostrap Table实现分页; - 淘汰
LayUI改用Layer进行弹窗; - 文档页增加
导航栏;
v2.3(2021-02-08)
- 全新的
页面布局; - UI适配
移动端; - 优化
导航页布局; - 优化一系列
UI显示问题;- 优化了
手机端页脚显示 - 优化了
平板端导航条显示 - 页面底部增加
回到顶部按钮 - 按钮
触发跳转页面相对位置 回车键触发查询按钮- 优化
导航页页脚显示
- 优化了
v2.2 (2021-02-03)
- 新增了
信息泄露探测功能; - 新增了
旁站探测功能; - 新增了导航页
数据分析功能; - 新增了基于
Docsify的文档页; - 重构了
静态文件static文件结构 - 优化了项目
文件结构; - 美化了
注册页面; - 引入了
动态粒子背景效果; - 修复了一些
UI显示问题;
v2.1 (2021-01-13)
- 新增了
指纹识别功能; - 新增了
登录和注册功能功能; - 新增了
欢迎页; 新增了文档页;- 修复了一些
UI显示问题;
v2.0(2021-01-04)
- 新增了
端口扫描功能; - 新增了
安全导航功能; - 连入了
SQLite数据库,后续考虑改为MySQL; - 修复了一些
UI显示问题; - 修复了后台头部小图标无法显示问题;
- 新增了后台数据导入导出功能;
v1.0(2020-12-20)
- 基于
Tabler框架构造了前端页面; - 采用基于
Python的 Django 框架编写后端; - 引入了
SimpleUi美化 Django 后台框架; - 引入了
Font-Awsome 5.15.1图标;
项目部署
本地部署
1.使用 Pycharm 打开本项目,在 Pycharm 的 setting—>Project Interpreter中 add 一个新的虚拟环境。
2.在该虚拟环下打开 Pycharm 自带 Terminal 运行 pip install -r requirements.txt 下载项目所需的第三方包。
3.现在项目已经可以正常运行了,但是想要使用漏洞扫描功能,需要安装AWVS,并在项目的setting.py 中配置 AWVS的 API URL和API KEY
4.忘记密码功能相关配置在项目的setting.py 中修改
EMAIL_HOST = 'smtp.163.com'
EMAIL_PORT = 25 # 发件箱的smtp服务器端口
EMAIL_HOST_USER = 'xxx' # 你的邮箱账号
EMAIL_HOST_PASSWORD ="xxx" # 邮箱授权码
EMAIL_USE_TLS = True # 这里必须是 True,否则发送不成功
EMAIL_FROM = 'xxx' # 你的邮箱账号
DEFAULT_FROM_EMAIL = 'xxx' # 你的邮箱账号
5.创建超级管理员 python manage.py createsuperuser
服务器部署
TO DO
不论是开发还是安全感觉都有很长的路要走,路漫漫其修远兮,吾将上下而求索,共勉 !
- 安全工具页
- 安全图书页
- 引入MySQL数据库
- 扫描算法优化
- 代码变量、数据库结构优化
- 漏洞报告导出功能
- 页面异步刷新
赞助💰
您的支持是我不断前进的动力,如果您恰巧财力雄厚,又感觉本文对您有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用,拒绝白嫖,从你我做起!🥰🥰🥰
| 支付宝支付 | 微信支付 |
 |
 |



