B-tree
论文名称:《Organization and maintenance of large ordered indices Share on》
- 作者:R. Bayer,E. McCreight
- 单位:Mathematical and Information Sciences Laboratory
- 会议:SIGMOD【CCF A】
- 时间:1970年11月
为什么 B-tree 会诞生呢?
为了减少磁盘 I/O 操作
- 我们假设数据量达到了亿级别,内存根本存储不下,我们只能以块的形式从磁盘读取数据,与内存的访问时间相比,磁盘 I/O 操作相当耗时(慢上百倍千倍甚至万倍),所以,我们应当尽量减少从磁盘中读取数据的次数。
为了一次磁盘 I/O 操作读取更多数据
- 从磁盘中读取数据时,都是按照磁盘块来读取的,并不是一条一条的读。如果我们能把尽量多的数据放进磁盘块中,那一次磁盘读取操作就会读取更多数据,那我们查找数据的时间也会大幅度降低。
我们都知道平衡二叉树中一个结点只能最多 2 个子结点,每个节点只存储一个数据。那么我们如何改进呢?
一个自然而然的想法!让每个结点可以有更多的数据项和更多的子结点
好的,你已经发明了 B-Tree !!!
下面就来具体介绍一下 B-Tree
简介
B-tree 是一种多路平衡查找树,提出 B-tree 的主要目的就是减少磁盘的 I/O 操作。
一个 m 阶的 B-tree 具有如下几个特征:
- 1、根结点至少有 2 个子结点
- 2、每个非根的分支结点都有 k-1 个元素和 k 个孩子,其中 ⎡m/2⎤≤ k ≤ m
- 3、每一个叶子结点都有 k-1 个元素,其中 ⎡m/2⎤≤ k ≤ m
- 4、所有的叶子结点都位于同一层。
- 5、每个节点中的元素从小到大排列,节点当中 k-1 个元素正好是 k 个孩子包含的元素的值域分划。
术语:3 阶 B-tree 称为 2-3 树、4 阶 B-tree 称为 2-3-4 树
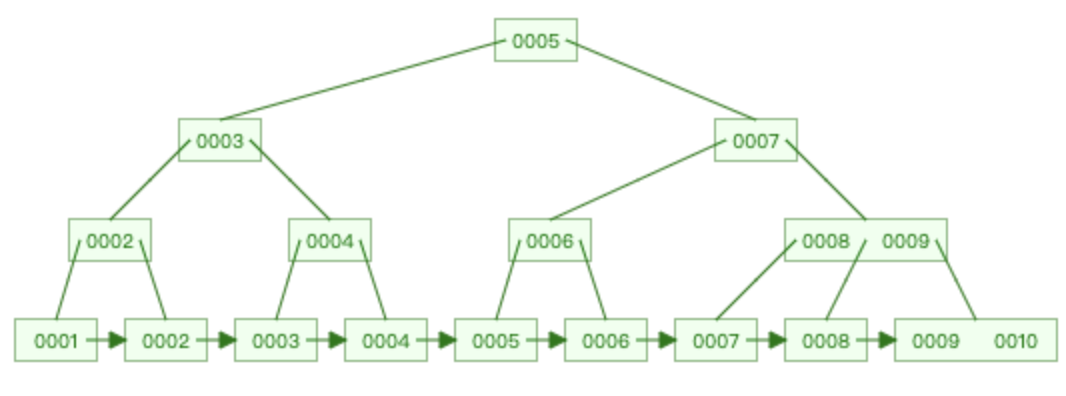
如下图是一颗标准的 3 阶 B-tree :
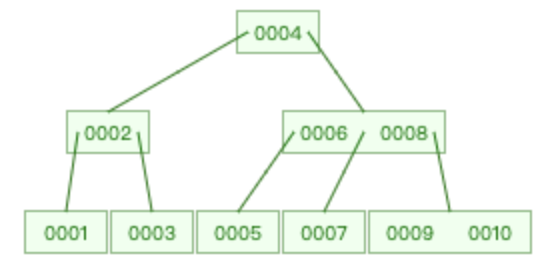
- m = 3、2 ≤ k ≤ 3
- 该树满足上述所有特征
那么如图的树是怎么构造的呢?下面为我们来一步一步来构造哈
插入
规则
首先判断是否是空树
若是空树,则创建结点,插入key
若不是空树
1、根据左大右小规则找到待插入结点位置
2、判断当前结点 key 的个数是否小于 k-1,若满足,则直接插入
3、若不满足,以结点中间的 key 为中心分裂成左右两部分,中间关键字元素上移到父结点中(如果父结点空间满了,也同样需要“分裂”操作),这个 key 的左子树指向分裂后的左半部分,这个 key 的右子支指向分裂后的右半部分,然后将当前结点指向父结点。
示例
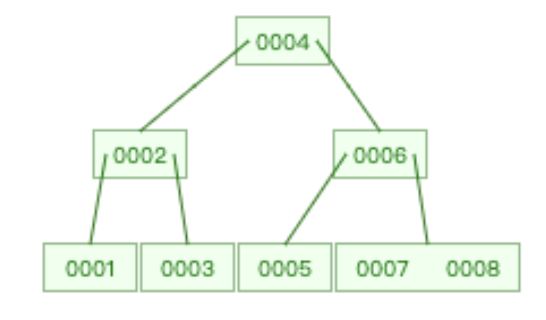
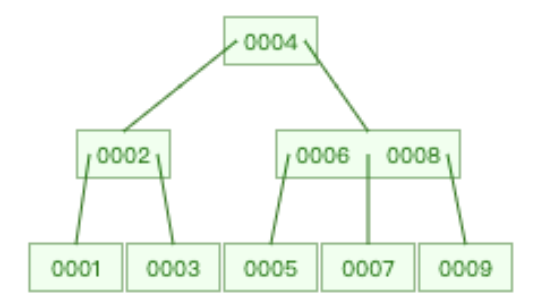
🌰:构造一个 3 阶 B-tree ,存储数据{1,2,3,4,5,6,7,8,9,10}
- m = 3、2 ≤ k ≤ 3、1 ≤ k-1 ≤ 2
| 插入1,2 | 插入3 | 插入4 |
|---|---|---|
 |
 |
 |
| 插入5 | 插入6 | 插入7 |
 |
 |
 |
| 插入8 | 插入9 | 插入10 |
 |
 |
|
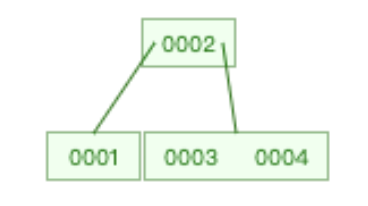
- 插入1时,为空树,建立结点直接插入
- 插入2时,满足结点的key个数 ≤ k-1,直接插入当前结点
- 插入3时,不满足结点的key个数 ≤ k-1,进行分裂操作
- 将2升至父结点,1为左结点,3为右结点
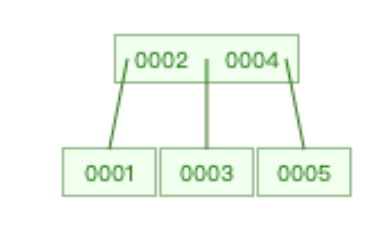
- 插入4时,满足结点的key个数 ≤ k-1,直接插入当前结点
- 插入5时,不满足结点的key个数 ≤ k-1,进行分裂操作
- 将4升至父结点,3为左结点,5为右结点
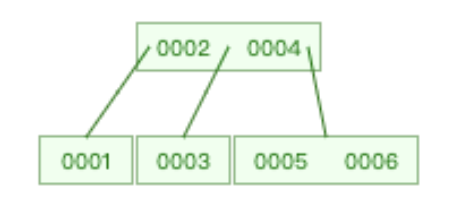
- 插入6时,满足结点的key个数 ≤ k-1,直接插入当前结点
- 插入7时,不满足结点的key个数 ≤ k-1,进行分裂操作
- 将6升至父结点,5为左结点,7为右结点
- 6升至父结点后,父结点key个数已经超过 k-1
- 执行分裂操作,再将4升入父节点,2为左结点,6为右结点
- 插入8时,满足结点的key个数 ≤ k-1,直接插入当前结点
- 插入9时,不满足结点的key个数 ≤ k-1,进行分裂操作
- 将8升至父结点,7为左结点,9为右结点
- 插入10时,满足结点的key个数 ≤ k-1,直接插入当前结点
插入动态演示:B-Tree 动态演示
删除
B-tree 的删除比插入更复杂一些,因为删除之后还涉及到移动元素的操作。
规则
根据左大右小规则找到待删除结点位置
- 情况1:位于叶子结点上,直接删除
- (1.1)如果删除后,结点key个数还是满足 k-1 范围 ,那么结束删除操作
- (1.2)反之,父节点中的key下移…
- 情况2:位于分支结点上,首先找到删除节点的后继节点,用后继节点覆盖要删除的节点,再删除后继节点
- (2.1)如果删除后该节点中关键字的个数大于等于 k-1,那么结束删除操作
- (2.2)如果兄弟节点key个数满足 k-1,将父节点中的key下移到该节点,兄弟节点中的一个key上移,删除操作结束
- (2.3)如果兄弟节点key个数小于 k-1,将父节点中的key下移到该节点,并与它的兄弟节点中的key合并,形成一个新的节点,然后修改指向即可。
示例
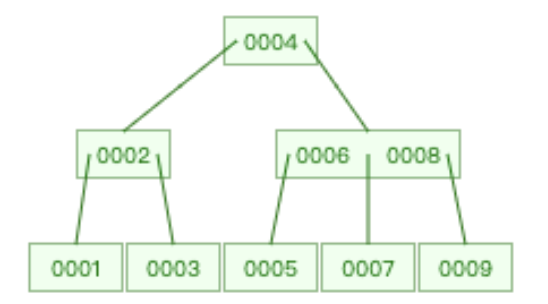
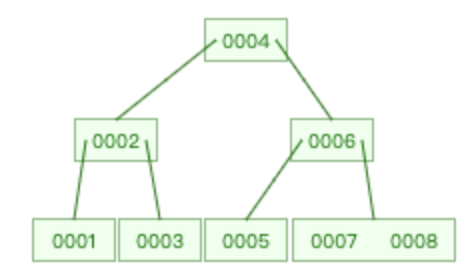
| 原始B-Tree | 删除10 | 再删除9 |
|---|---|---|
|
 |
 |
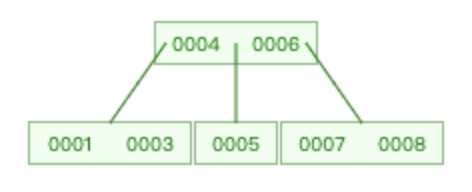
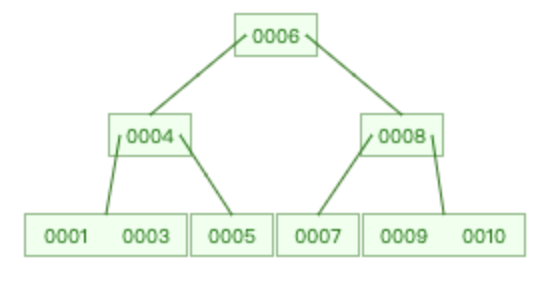
| 再删除2 | 原图-删除2 | 原图-删除8 |
 |
 |
 |
删除 10 时,满足情况 1.1
再删除 9 时,满足情况 1.2
再删除 2 时,满足情况 2.3
删除 8 时,满足情况 2.1
删除 2 时,满足情况 2.2
效率
假设我们现在有 838,8608 条记录
对于 AVL 树而言,树的高度 h = log2(838,8608) ≈ 23,也就是说如果要查找到叶子结点需要 23 次磁盘 I/O 操作
对于 B-Tree,假设每个结点 8 个元素(当然真实情况下没有这么平均,有的结点比8多一些,有些比 8 少一些),树的高度 h = log8(838,8608) ≈ 8 ,也就是说如果要查找到叶子结点需要 8 次磁盘 I/O 操作
B+-tree
为什么 B+-tree 会诞生呢?
B-tree 仍然有一个致命的缺陷,那就是它的索引与数据绑定在一块,而数据的大小很有可能远远超过了索引数据,查找中途过程会加载很多无用的数据,这会大大减小一次 I/O 有用数据的获取,间接的增加 I/O 次数去获取有用的索引数据。
因此,如果只把数据存储在最终查询到的那个节点是不是就可以了?但是谁知道哪个节点就是最终要查询的节点呢?
B+-tree 横空出世,B+-tree 树就是为了拆分索引与数据的多路平衡查找树。
简介
B+-tree 是 B-tree 的变体
一个 m 阶 B+-tree 树具有如下几个特征:
1、根结点至少有 2 个子结点
2、每个非根的分支结点都有 k-1 个元素和 k 个孩子,其中 ⎡m/2⎤≤ k ≤ m
- 此处颇有争议,到底是与B-tree k-1 个元素和 k 个孩子,还是不一致:k 个元素和 k 个孩子,待查证
3、B+-tree 非叶子节点上是不存储数据的,仅存储键值用来索引,所有数据都保存在叶子节点且叶子结点本身依关键字的大小自小而大顺序链接。
如下图是一颗标准的 3 阶 B+-tree :

头叶结点之前其实还有一个头指针,上图没有画出
插入
插入规则与 B-tree 类似
示例
🌰:构造一个 3 阶 B-tree ,存储数据{1,2,3,4,5,6,7,8,9,10}
- m = 3、2 ≤ k ≤ 3
| 插入1、2 | 插入3 | 插入4 |
|---|---|---|
|
 |
 |
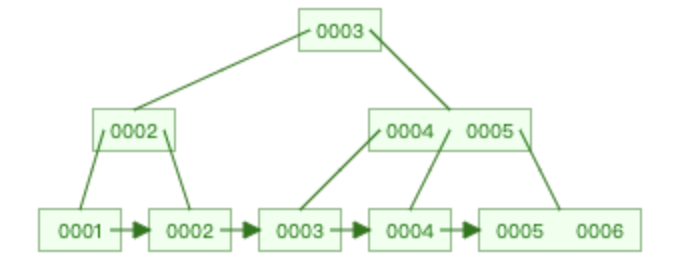
| 插入5 | 插入6 | 插入7 |
 |
 |
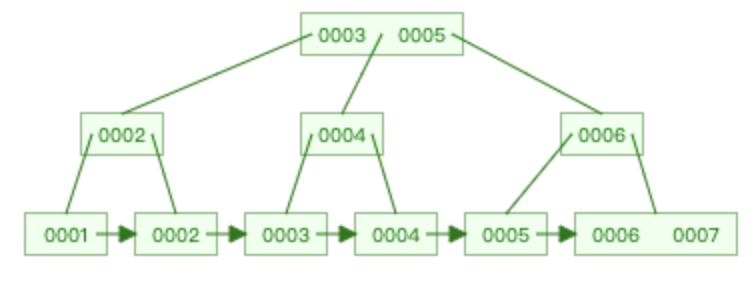 |
| 插入8 | 插入9 | 插入10 |
 |
 |
 |
删除
与 B-tree 类似
查找
B+-tree 的查找与B树不同,当索引部分某个结点的关键字与所查的关键字相等时,并不停止查找,应继续沿着这个关键字左边的指针向下,一直查到该关键字所在的叶子结点为止。
效率
生产环境中B+-tree的高度一般就 3~4 层
一棵 B+ 树的存放总记录数为:索引结点指针数 * 单个叶子节点记录行数。
我们假设主键 ID 为 bigint 类型,长度为 8 字节,而指针大小在设置为 6 字节,这样一共 14 字节,我们一个结点中能存放多少这样的单元,其实就代表有多少指针,即 16384/14=1170
InnoDB 中页的默认大小是 16KB,假设一行记录的数据大小为 1k,则一个叶子结点(页)中的记录数 = 16K/1K = 16
一个高度为 3 的 B+ 树可以存放: 1170*1170*16 = 21902400 条这样的记录。
一般根节点是常驻内存的,所以一般我们查找 2千多万的数据,只需要 2 次磁盘 IO。
B+-tree和B-tree的区别
- B-tree 内部节点是保存数据的;B+-tree内部节点是不保存数据的,只作索引作用,它的叶子节点才保存数据。
- B+-tree 相邻的叶子节点之间是通过链表指针连起来的,B-tree却不是。
- 查找过程中,B-tree在找到具体的数值以后就结束,B+-tree则需要通过索引找到叶子结点中的数据才结束
- B-tree中任何一个关键字出现且只出现在一个结点中,B+-tree可以出现多次。
B+-tree优点
- I/O次数更少:B+-tree 的内部结点没有存储关键字,所以同样大小的磁盘页能容纳更多结点。一次性读入内存中的也就越多,相对来说IO读写次数也就降低了
- 查询速度更稳定:B+-tree 所有关键字数据地址都存在叶子结点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
- 范围查询更简便:B+-tree 所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
- 全结点遍历更快:B+-tree 遍历整棵树只需要遍历所有的叶子节点即可, B-tree 需要对每一层进行遍历,这有利于数据库做全表扫描。
为什么 MySQL 的索引要使用 B+树而不是B树?
因为 B 树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少,指针少的情况下要保存大量数据,只能增加树的高度,导致 IO 操作变多,查询性能变低。
高性能 GPU 并发 B+ 树【CCF A】
设计高性能 GPU B 树【CCF A】
B*-tree
B*-tree 是 B+-tree 的变体,它是在 B+-tree 的基础上,将索引层也以指针连接起来,使搜索取值更加快捷。
与B+-tree
首先是关键字个数限制问题
- B+-tree 初始化个数是⎡m/2⎤≤ k ≤ m
- B*-tree 初始化个数为⎡2m/3⎤≤ k ≤ m
B+-tree 结点满时就会分裂,B*-tree 结点满时会检查兄弟节点是否满(因为每个节点都有指向兄弟的指针)
- 如果兄弟结点未满则向兄弟节点转移关键字
- 如果兄弟节点已满,则从当前节点和兄弟节点各拿出 1/3 的数据创建一个新的节点出来
| B+-tree | B*-tree |
|---|---|
 |
 |
对比
B+-tree:在 B-tree 基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中
B*-tree:在 B+-tree 基础上,为非叶子结点也增加链表指针,将结点的空间利用率从1/2提高到2/3,查询速率也有所提高。又存有兄弟节点的指针,可以向兄弟节点转移关键字的特性使得 B*-tree 分解次数变得更少;
Bed-tree
论文名称:《Bed-tree: an all-purpose index structure for string similarity search based on edit distance》
作者:Zhenjie Zhang, Marios Hadjieleftheriou, Beng Chin Ooi, Divesh Srivastava
单位:新加坡国立大学、AT&T Labs
会议:SIGMOD ‘10【CCF A】
时间:2010年06月
本文中提出 Bed-tree,一种基于 B-tree 的索引结构,用于评估编辑距离和标准化编辑距离的相似度查询。我们确定从字符串空间到整数空间的映射的必要属性,以支持搜索和修剪这些查询。提出了三种转换用于捕获字符串中固有信息的不同方面,从而在树上的搜索过程中实现高效的剪枝。与最先进的字符串相似性搜索方法相比, Bed-tree 是一个完整的解决方案,满足所有应用程序的要求,提供高可扩展性和快速响应时间。
参考
❤️Sponsor
您的支持是我不断前进的动力,如果您恰巧财力雄厚,又感觉本文对您有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用,拒绝白嫖,从你我做起!🥰🥰🥰
| 支付宝支付 | 微信支付 |
 |
 |



