SE论文清单
| 序号 | 论文名称 | 作者 年份 |
单位 | 来源 | 等级CCF | 链接 |
|---|---|---|---|---|---|---|
| 7 | Prime Inner Product Encoding for EffectiveWildcard-based Multi-Keyword Fuzzy Search | 刘勤2020 | 湖南大学 | IEEE TSC | B | 原文 |
| 8 | Enabling Efficient Verifiable Fuzzy Keyword Search Over Encrypted Data in Cloud Computing | 葛新瑞 2018 | 青岛大学 | IEEE Access | —— | 原文 |
| 9 | Cuckoo-Filter Based Privacy-Aware Search over Encrypted Cloud Data | 薛清寒2015 | Lehigh University | MSN | C | 原文 |
| C | 原文 | |||||
| 11 | ESVSSE: Enabling Efficient, Secure, Verifiable Searchable Symmetric Encryption | 石振奎2020 | 广西师范大学 | IEEE TKDE | A | 原文 |
| 12 | Dynamic Multi-Phrase Ranked Search over Encrypted Data with Symmetric Searchable Encryption | 郭成2017 | 大连理工大学 | IEEE TSC | B | 原文 |
| - | VPSearch: Achieving Verifiability for Privacy-Preserving Multi-Keyword Search over Encrypted Cloud Data | 万志国2016 | 山东大学 | IEEE TDSC | A | 原文 |
| - | A New Lightweight Symmetric Searchable Encryption Scheme for String Identification | Indranil Ghosh 2020 | 伦敦大学 | IEEE TCC | C | 原文 |
⑦PIPE方案
论文名称:《Prime Inner Product Encoding for EffectiveWildcard-based Multi-Keyword Fuzzy Search》
- 作者:刘勤; 于鹏; 裴淑玉; 吴杰; 彭涛; 王国军
- 单位:湖南大学
- 刊物:IEEE TRANSACTIONS ON SERVICES COMPUTING【CCF B】
- 时间:2020年09月
- 阅读完成时间:2022年05月31日
1、总体思路
本文提出了一种素数内积编码(PIPE)方案,该方案利用素数的不可分解性来提供高效、高精度、灵活的多关键字模糊搜索。
主要思想:是将查询关键字或索引关键字编码为充满素数或素数倒数的向量,这样只有当两个关键字相似时,向量的内积的结果才是整数(因为素数除了1和它本身没有正因子,所以只有当两个关键字相似时,向量内积的结果才是整数)。为了支持多关键字模糊搜索,将关键字向量组织成矩阵,并利用矩阵乘法来支持and/or查询。
首先构建了在已知密文模型中安全的 PIPE0 方案。与难以同时支持 AND 和 OR 语义的现有作品不同,PIPE0 使用户能够灵活地在其查询中指定不同的搜索语义。
然后构造了 PIPES 方案,巧妙地将随机噪声添加到查询向量中,以抵制线性分析。理论分析和实验结果都证明了该方案的有效性。
2、使用技术
素数内积编码
编辑距离
安全k近邻方案(Secure k-Nearest Neighbor Scheme)
⋆矩阵乘法·向量内积
**EncI(p, sk)→p’**:将索引向量 p ∈ Rd 分成两个向量(pa, pb),如下:
for i = 1 to d
如果 s[i] = 1,p[i] 随机分成 pa[i], pb[i],使 pa[i] + pb[i] = p[i];
如果 s[i] = 0,pa[i] 和 pb[i] 都设置为 p[i]。
加密 (pa, pb) 并输出 p’ = (p’a, p’b),其中 (p’a = M1T⋆pa,p’b = M2T⋆pb)。
EncQ(q, sk) → q’ : 将查询向量 q∈Rd 分割为两个向量(qa, qb),如下:
- for i = 1 to d
- 如果 s[i] = 1,则 qa[i] 和 qb[i] 都设置为 q[i];
- 如果 s[i] = 0,则 q[i] 随机分成 qa[i], qb[i],使 qa[i] + qb[i] = q[i]。
- 加密 (qa, qb) 并输出 q’ = (q’a, q’b),其中 (q’a = M1-1⋆qa,q’b = M2-1⋆ b)。
Search(p’,q’)→v:计算 v = p’a·q’a + p’b·q’b 作为搜索结果。注意:
p’ · q’ = p’a(行向量)·q’a + p’b·q’b
= p’aT·q’a + p’bT·q’b
= (M1T⋆pa)T · (M1-1⋆qa) + (M2T⋆pb)T · (M2-1⋆qb)
= paT ⋆ qa + pbT⋆ qb
= pT⋆ q
= p · q
因此,加密后的向量的内积和等价于原始向量的内积。
3、方案实现
PIPE0=(GenKey0, BuildIndex0, Trapdoor0, Search0)
密钥生成算法
SK ← GenKey0(1k) 生成密钥,具体步骤如下:
- 给定安全参数 κ,云用户运行 KNN.Key(1k) 来生成 sk = (M1, M2, s)
- 随机选择一个 长度 L 素数序列 P = (p1,…, pL),一个由 L 个虚拟字符组成的字典 S = (s1,…, sL),使 S ∩ A = ∅,和 k 位字符串 kf
- k ∈ N 是安全参数
- A 是 26个英文字母构成的字典
- L = max(||w1||,…,||wm||) 是关键字的最大长度
- RPF:F:{0,1}k x {0,1}*→ {0,1}k
- 密钥 SK 为(sk,kf,P,S)
索引生成算法
Ii ← BuildIndex0(Wi,SK) 生成索引,具体步骤如下:
具有 mi 关键字的文件 Di 文件的关键字集合 Wi = {Wi,1, . ., wi,mi},云用户构建 |mi|× d 矩阵 Ai
- 1)对于k ∈ [mi],运行算法1为 Wi 中的第 k 个关键字 wi,k 输出 d 维向量 pi,k
- 2)对于k ∈ [mi],设置 Ai[k][∗] ← Pi,k
对于 k ∈ [mi],运行 KNN.EncI(Ai[k][∗],sk) 加密矩阵 Ai 的第 k 行并输出一对加密向量 (A’ia[k][∗],A’ib[k][∗]) 。加密索引 Ii 设为一对加密矩阵 A’i= (A’ia,A’ib)

- 第一步(第1-2行):用 S 中元素填充每个关键字,以隐藏其真正的长度。用 L 表示通用关键字的最大长度。填充之后,每个关键字的长度都等于 L 。
- 第二步(第3-4行):用 1 初始化索引向量的每个元素。
- 第三步(第5-7行):将指定素数的倒数放在索引向量的适当位置。对于关键字 wi,k 的第 l 个字符 wi,k[l],对应的素数为 pl,对应的位置计算为 posl = Fkf (wi,k[l])。因此,对于 l∈[l], pi,k [posl] 将乘以 1/pl。
- 第四步(第8行):为了增加内积结果的随机性,用随机数 z ∈ [d - L] 填充剩余部分元素。
陷门生成算法
TQj ← Trapdoor0(W’j, SK) 生成陷门,具体步骤如下:
具有 ni 关键字的查询 Qj 文件的关键字集合 W’i = {W’i,1, . ., w’i,nj},云用户构建 ni × d 矩阵 Bi
- 1)对于k ∈ [nj],运行算法2为 W’j 中的第 k 个关键字 w’j,k 输出d维向量 qj,k
- 2)对于k ∈ [nj],设置 Ai[k][∗] ← Pi,k
对于 k ∈ [nj],运行 KNN.EncQ(Bj[k][∗],sk) 加密矩阵 Bj 的第 k 行并输出一对加密向量 (B’ja[k][∗],B’jb[k][∗]) 。陷门 TQj 设为一对加密矩阵 B’j= (B’ja,B’jb)

- 第一步(第1-2行)填充步骤和第二步(第3-4行)初始化步骤与算法1相同
- 第三步(第5-15行):将指定的素数放置在索引向量的适当位置,对于关键字 wj,k 的第 l 个 字符 wj,k[l],有两种情况:
- (1)如果 wj,k[l] ≠ “∗”,执行 6-8 行,计算 posl = Fkf(wi,k[l]) 并将 qj,k [posl] 乘以 pl
- (2)如果 wj,k[l] = “∗”,表示在 A ∪ S 中任意一个字符都可能位于关键字的第 l 位。
- 执行 10-15 行,计算 1 ≤ i ≤ 26 的 posli = Fkf(A[i]) 和 26 < i ≤ 26 + L 的 posli = Fkf(S[i−26])
- 并将 x ∈ [1,26 + L] 的 qj,k[poslx] 乘以 pl
- 第四步(第16行):为了增加内积结果的随机性,用随机数 z ∈ [d- 26 - L] 填充剩余部分元素。
搜索算法
**{0,1} ← Search0(Ii,TQj) **搜索算法,具体步骤如下:
云服务商计算:Ri,j = A’ia ⋆ B’ja + A’ib ⋆ B’jb = Ai ⋆ Bj
对于 AND 查询,如果 Ri,j 每列中至少有一个整数,则输出1 ,否则输出0
对于 OR 查询,如果 Ri,j 至少有一个整数,则输出1,否则输出0
Remark 1:“除法”操作可能会导致搜索精度的降低,从而影响搜索精度。因此,1/3×3的结果可能是1.00001而不是1。为了解决这个问题,我们的方法是在小数点后的第 x 位进行四舍五入,x 可以在实验中调优。
栗子🌰:
- PIPE0的工作过程

- 由算法1和算法2输出的样本向量
- 云用户发出查询 Q1 = {“hel∗o”,”k∗y”} 和 Q2 = {“hel∗o”,”w∗r∗d”} 来检索适当的文件。
- 给定关键字最大长度 L= 5,随机素数 P = (3,5,7,11,13),虚拟字符 S = (“A”, “B”, “C”, “D”, “E”),构建索引/查询向量,如下图所示。
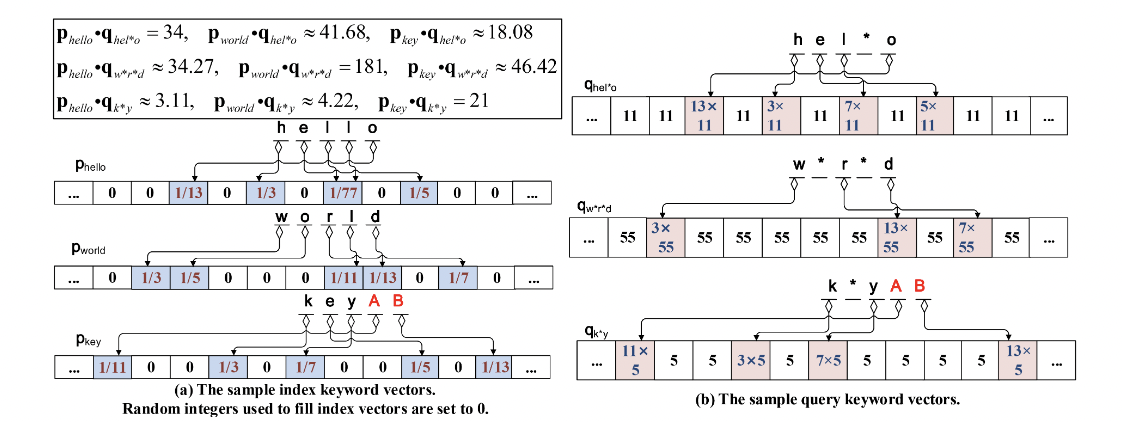
为了说明向量编码算法的工作过程,我们以索引关键字 “key” 和查询关键字 “k∗y” 为例。
- 在第一步中,将用字符 “A” 和 “B” 填充两个关键字,使其最大长度为 5
- 在第二步中,两个 d 维向量 pkey 和 qk∗y 被构造,并用 1 初始化。
- 对于索引关键字 “key”,素数的倒数放置如下:
- 因为“k”是第一个字符,pkey[Fkf(k)] 要乘以 1/3;
- 因为“e”是第二个字符,pkey[Fkf(e)] 将被乘以 1/5;
- 因为“y”是第三个字符,pkey[Fkf(y)] 将被乘以 1/7;
- 因为“A”是第四个字符,pkey[Fkf(A)] 将被乘以 1/11;
- 因为“B”是第五个字符,pkey[Fkf(B)] 要乘以 1/13。
- 对于查询关键字 “k∗y”,素数的放置方式如下:
- 因为“k”是第一个字符,所以 qk∗y[Fkf(k)] 将乘以3;
- 由于“∗”是第二个字符,A 和 S 中的任意元素都可以位于这个位置,并且 qk∗y[Fkf(a)],… ,qk∗y[Fkf(E)] 将乘以 5;
- 因为“y”是第三个字符,所以 qk∗y[Fkf(y)] 将乘以 7;
- 因为“A”是第四个字符,所以 qk∗y[Fkf(A)] 将乘以 11;
- 因为“B”是第五个字符,所以 qk∗y[Fkf(B)] 将乘以 13。
由于素数的不可分解性质,pkey · qk∗y 的结果是一个整数(等于21)。结果与两个关键字相似是一致的
上图所示的索引/查询向量,相应的样本矩阵如图[PIPE0的工作过程]-(b)所示
- 如果 Q1 是一个 AND 查询,将返回 D1,因为只有 R1,1 在每列中有一个整数元素;
- 如果 Q1 是一个 OR 查询,{D1, D2, D3} 将返回,因为 R1,1, R2,1 和 R3,1 至少有一个整数元素。
- 如果 Q2 是一个 AND 查询,将返回 D3,因为只有 R3,2 在每列中有一个整数元素
- 如果 Q2 是一个 OR 查询,{D1, D3} 将被返回,因为 R1,2 和 R3,2 至少有一个整数元素。
⑧VFKS方案
论文名称:《Enabling Efficient Verifiable Fuzzy KeywordSearch Over Encrypted Data in Cloud Computing》
- 作者:葛新瑞; 贾宇; 胡成宇; 张汉林; 荣浩
- 单位:青岛大学
- 刊物:IEEE Access
- 时间:2018年08月
1、总体思路
本文提出了一种基于加密云数据的新型可验证模糊关键字搜索方案(VFKS)。为了引入该方案,首先提出一个可验证的确切关键字搜索方案,然后将该方案扩展到模糊关键字搜索方案。在模糊关键字搜索方案中,采用链表作为安全索引,以实现高效存储。我们为每个关键字构造一个包含三个节点的链表,并为其生成一个模糊关键字集为了降低计算成本和存储空间,我们为每个模糊关键字集生成一个索引向量,而不是每个模糊关键字。为了抵御云服务器的恶意行为,为每个模糊关键字生成一个身份验证标签,以验证返回的密文的真实性。
2、使用技术
- PRF、PRP
- MAC
- 倒排索引
- 编辑距离(Levenshtein)
- 链表
3、基础知识
安全索引
数据所有者将普通索引加密为安全索引。他利用 PRP π 混淆关键字的重新分配,并利用 PRF f 模糊向量 v(wi),即 πk1(wi) 和 Ev(wi)←fk2(πk1(wi)) ⊕ v(wi)。数据所有者调用算法 SKE.Enc 将文件 F 加密成密文 C 。使用 ID(Cj) 表示加密文件 Cj 的标识符
PRF、PRP
伪随机函数(PRF:pseudo random function)和伪随机置换函数(PRP:pseudo random permutation)是多项式时间可计算函数,任何概率多项式时间对手都无法将其与随机函数区分开来。
文章中使用 PRF f 来加密索引向量(blind the index vectors ),使用 PRP π 来混淆关键字的位置。两个函数的参数如下:
- π:{0,1}k × {0,1}l → {0,1}l
- f: {0,1}k × {0,1}l → {0,1}N
- 其中 l 是关键字的最长长度。
MAC
MAC 是指消息认证码(带密钥的Hash函数),是密码学中通信实体双方使用的一种验证机制,保证消息数据完整性的一种工具。构造方法由 M.Bellare 提出,安全性依赖于 Hash 函数,故也称带密钥的 Hash 函数。消息认证码是基于密钥和消息摘要所获得的一个值,可用于数据源发送方认证和完整性校验。MAC 一般不会从头设计,而是从已有的哈希函数改造而来,比如加前缀、后缀或其他方法。
设 MAC:{0,1}k × {0,1}∗→{0,1}N 是一个认证标签生成函数
对于所选的消息攻击具有不可逆性和消息不可伪造性,我们用它为消息生成一个认证标签,并验证从云服务器返回的搜索结果的正确性。
在本文中使用 tag = MAC(k0,m) 代替 tag = MAC(m),其中 k0 为 key,m 为message
编辑距离
编辑距离,也叫莱文斯坦距离(Levenshtein),在模糊关键字搜索方案中,利用编辑距离来评估两个字符串的相似度。两个关键字 w1 和 w2 之间的编辑距离 (w1,w2) 是将其中一个转换为另一个所需的最小操作数。有三种基本操作
- 替换:把一个字转换成另一个字。
- 删除:从一个单词中删除一个字母。
- 插入:在单词中插入一个字母。
例如,将关键字 kitten 转换为关键字 sitting 的操作如下:
- 1、kitten→sitten(k→s)
- 2、sitten→sittin(e→i)
- 3、sittin→sitting(insert g)
一般来说,编辑距离越小,两个关键词的相似度越大
4、方案1:VEKS
K←KeyGen(1k)
sk←SKE.Gen(1k)
- SKE=(Gen,Enc,Dec):文章中使用 AES
k0,k1,k2←{0,1}k
算法输出秘钥 K = {sk,k0,k1,k2}
sk 为加解密文件的密钥,k0 为 MAC 的密钥,k1 为 PRP π 的密钥,k2 为 PRF f 的密钥
(I,C)←BuildIndex(K,F)
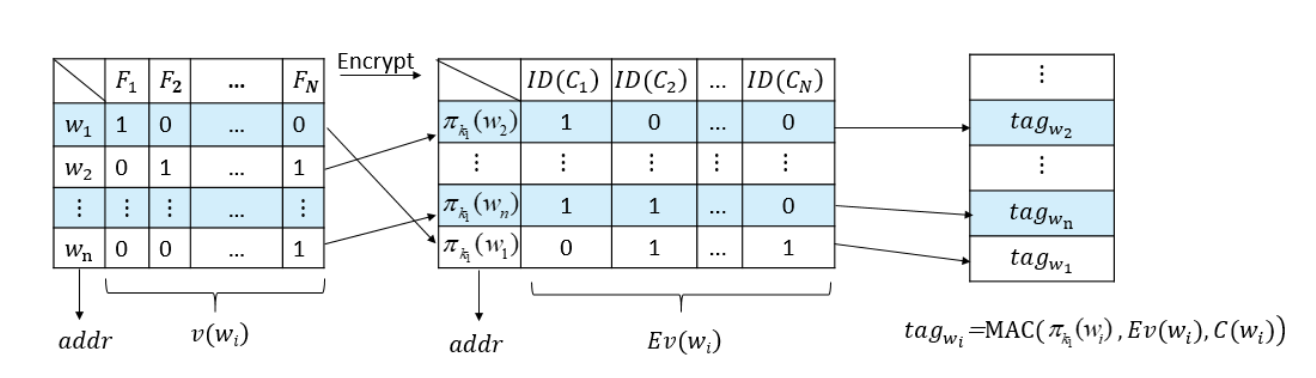
1、数据所有者扫描整个文档,提取所有不同的关键字,构造关键字集 W。对于每个关键字 wi ∈ W(1≤i≤n),数据所有者构造 F(wi),它是一个包含 wi 的文件集合。
2、设 v(wi)(1≤i≤n) 表示关键字 wi 的索引向量。
- 如果 wi 在 Fj (1≤j≤N) 中,则 v(wi )[j] = 1
- 否则, v(wi)[j] = 0
3、数据所有者通过计算 Ci←SKE.Encsk(Fi) 加密文档。然后生成关键字陷门 **πk1(wi)**,通过计算 **Ev(wi)**←fk2(πk1(wi)) ⊕ v(wi) 来加密向量 v(wi)。
4、数据所有者计算 **tagwi**←MAC(πk1(wi),Ev(wi),Ci),并将所有 tagwi 存储到 tag 表中
5、最后,数据所有者将安全索引 I、密文 C 和 tag 表上传到云服务器
Tw’←Trapdoor(K,w’)
当用户需要搜索包含关键字 w’ 的文档时,计算出陷门 Tw’ = (πk1(w’),fk2(πk1(w’))),并发送到云服务器
( tagw’,C(w’))←Search(Tw’,C,I)
- 云服务器根据 πk1(w’) 在安全索引 I 中找到相关的加密向量 Ev(w’)
- 然后通过计算 v(w’) ← fk2(πk1(w’)) ⊕ Ev(w’) 解密 Ev(w’)
- 如果 v(w’)[j] = 1 (1≤j≤N),云服务器将 Cj 加到 C(w’) 中
- 同时,云服务器对 tag 表中 πk1(w’) 位置提取 tagw’
- 最后,云服务器将 C(w’) 和 tagw’ 返回给数据用户。
(accept,reject)←Verify(K,tagw’,C(w’),Tw’)
- 用户从 C(w’) 中解析出 v(w’) ,如果 Cj 在 C(w’) 中,则 v(w’) 的第 j 位为 1,否则等于 0
- 用户计算 Ev(w’)←fk2(πk1(w’)) ⊕ v(w’)
- 然后检查 MAC(πk1(w’),Ev(w’),C(w’)) 是否等于 tagw’,如果是则用户接受结果,否则拒绝结果。
F(w’)←Dec(K,C(w’))
用户解密 C(w’) 通过计算 F(w’)←SKE.Decsk (C(w’))
5、方案2:VFKS
KeyGen(1k)
- sk←SKE.Gen(1k)
- SKE = (Gen,Enc,Dec),文章中使用 AES
- k0,k1,k2←{0,1}k
- 算法输出秘钥 K = {sk,k0,k1,k2}
- sk 为加解密文件的密钥,k0 为 MAC 的密钥,k1 为 PRP π 的密钥,k2 为 PRF f 的密钥。
BuildIndex(K,F)
为了方便、高效地建立索引,文章通过扩展倒排索引来构造包含三个节点的链表作为索引。
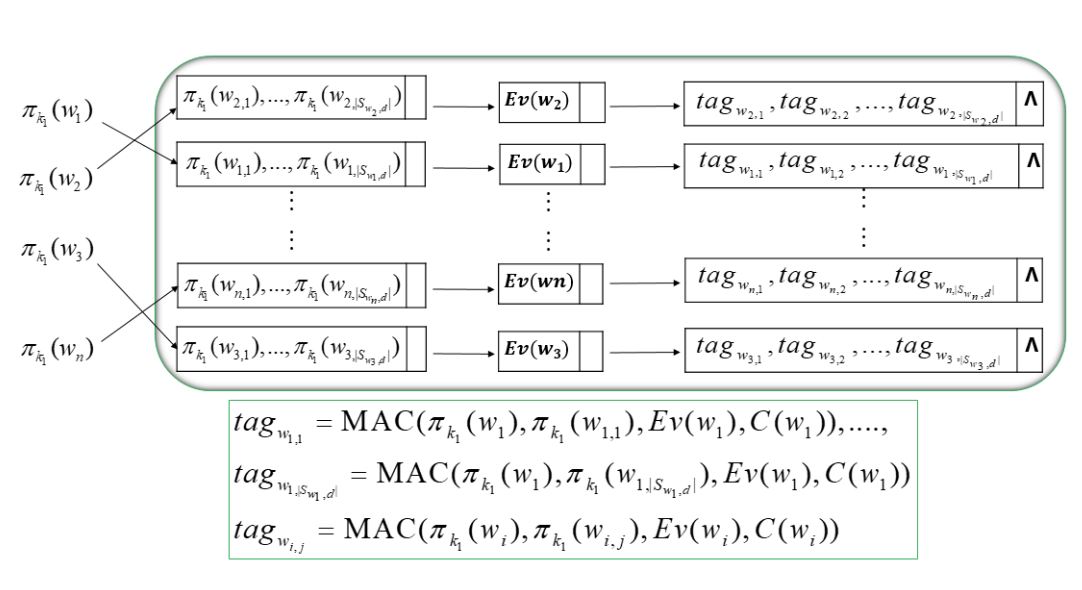
1、数据所有者扫描整个文档,提取所有不同的关键字,构造关键字集 W。对于每个关键字 wi ∈ W(1≤i≤n),数据所有者构造 F(wi),它是一个包含 wi 的文件集合。
2、设 v(wi )(1≤i≤n)表示关键字 wi 的索引向量。
- 如果 wi 在 Fj (1≤j≤N) 中,则 v(wi)[j] = 1
- 否则 v(wi)[j] = 0
3、数据所有者为每个关键字 wi 构造模糊关键字集。 Swi,d 表示有编辑距离的 wi 的模糊关键字集,wi,t (1≤i≤n,1≤t≤|Swi,d|) 表示 Swi,d 中的关键字
4、数据所有者通过计算 C(wi) ← SKE.Encsk(F(wi))加密所有文件。
- 对于 Swi,d 中的每个模糊关键字,计算 πk1(wi,t) (1≤i≤n,1≤t≤|Swi,d|),存储到第一个节点中
- 数据所有者计算 Ev(wi)←fk2(πk1(wi)) ⊕ v(wi),并将 Ev(wi) 存入第二个节点
- 对于 Swi,d 中的所有模糊关键字,计算一个认证标签 tagwi,t = MAC(πk1(wi),πk1(wi,t),Ev(wi),C(wi)),存储到第三个节点中
最后,数据所有者将这些链接列表存储到一个大数组中,该数组被视为安全索引 I
Trapdoor(K,w’)
当用户需要搜索包含关键字 w’ 的文档时,计算出陷门 Tw’ = ( πk1(w’),fk2(πk1(w’)) ),并发送到云服务器
Search(Tw’,C,I)
- 当云服务器收到陷门后,将 πk1(w’) 与每个列表的第一个节点中的元素进行比较。
- 在这里,我们使用加密的精确关键字 πk1(wi) 表示第一个节点 πk1(wi,1) 中的第一个元素。
- 也就是说,wi,1 表示确切的关键字 wi。如算法1所示,我们用两种情况来描述这个过程。

- 情况1:
- πk1(w’) 不等于第一个节点上的第一个元素 πk1(wi,1) ,而等于第一个节点上的另一个元素 πk1(wi,t)(1<t≤|Swi,d|),此时,云服务器返回 πk1(wi,1) 给数据用户
- 当用户接收到 πk1(wi,1) 时,计算出 fk2(πk1(wi,1)),发送给云服务器
- 云服务器通过计算 v(wi) ← fk2(πk1(wi,1)) ⊕ Ev(wi) 来解密第二个节点的 Ev(wi)
- 如果 v(wi)[j] = 1 云服务器将 Cj 添加到 C(w’)
- 然后云服务器从第三个节点的 πk1(wi,1)-th 位置提取 tagw’
- 最后,云服务器返回 C(w’) 和 tagw’ 给数据用户。
- 情况2:
- πk1(w’) 等于第一元素 πk1(wi,1),云服务器通过计算 v(wi) ← fk2(πk1(w’)) ⊕ Ev(wi) 直接解密第二个节点的 Ev(wi)。
- 如果 v(wi)[j] = 1 云服务器将 Cj 添加到C(w’)
- 然后云服务器从第三个节点的 πk1(w’)-th 位置提取 tagw’
- 最后,云服务器返回 C(w’),tagw’,πk1(wi,1)给数据用户
Verify(K,tagw’,C(w’),πk1(wi,1),Tw’)
- 用户从 C(w’) 中提取出 v(w’) 。
- 如果 Cj 在 C(w’) 中,则 v(w’) 的第 j 位为 1,否则等于0。
- 用户计算 Ev(w’) ← fk2(πk1(w’)) ⊕ v(w’)
- 然后检查 MAC(πk1(wi,1),πk1(w’),Ev(w’),C(w’)) 是否等于 tagw’,如果是则用户接受结果,否则拒绝结果。
Dec(K,C(w’))
用户解密 C(w’) 通过计算 F(w’)←SKE.Decsk (C(w’)) (sk∈K)
⑨CFPKS方案
论文名称:《Cuckoo-Filter Based Privacy-Aware Search over Encrypted Cloud Data》
- 作者:薛清寒;Mooi Choo Chuah
- 单位:Lehigh University
- 会议:2015 11th International Conference on Mobile Ad-hoc and Sensor Networks (MSN)【CCF C】
- 时间:2015年12月
1、总体思路
提出了一种基于布谷鸟过滤器的私有关键字搜索方案(CFPKS),以对加密数据提供隐私感知关键字搜索。该 CFPKS 方案使用基于Bed-tree 结构的索引来提高搜索效率,使用通配符方法支持模糊关键字搜索,并使用 Cuckoo 过滤器来提高搜索准确性和存储效率。方案可以处理拼写错误和查询不可链接性。
本文的主要贡献归纳如下:
- 1.我们提出了一种基于布谷鸟过滤器的私有关键字搜索方案(CFPKS),该方案支持多词关键字搜索,具有高搜索精度和高效存储;
- 2.方案旨在处理查询中的拼写错误,并通过生成不同的加密搜索请求来提供查询不可链接性,即使使用相同的关键字搜索;
2、使用技术
- Bed-tree
- wildcard
- 布谷鸟过滤器
3、相关说明
相似度关键字搜索
- 给定一个加密文件集合 F = {F1,F2,···},一组不同的单词 W = {w1,w2 ,···, wp} 和预定义的编辑距离阈值 d
- 相似度搜索时,如果 ED(vwi,vwj) <= d,则返回一组包含单词 wi 的文件标识符
- wi 是数据库中存储的单词,其数据向量为 vwi
- wj 是查询中的单词,其数据向量为 vwj
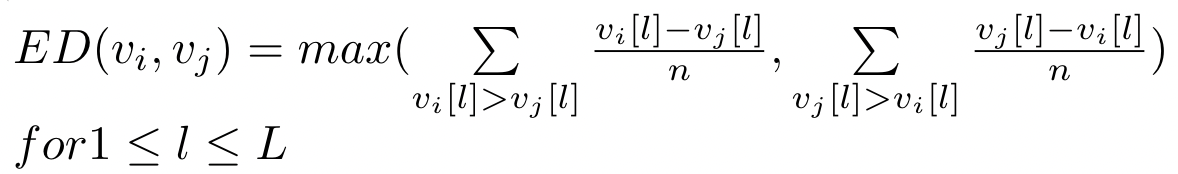
布谷鸟过滤器
一种实用的数据结构,它比相同存储大小的计数过滤器和传统的布隆过滤器具有更好的搜索精度和搜索时间。它由一个桶数组组成,每个桶包含多个条目。
对于每个数据项 x,哈希方案计算两个候选桶 i1 和 i2 的索引,设 Fingerprint(x) 为 hash(x) 的最小 k bit
# Trunc(hash(x),k) 计算hash(x)的最小 k 位。
Fingerprint(x) = Trunc(hash(x),k)
f = Fingerprint(x)
i1 = hash(x) mod M
i2 = (i1 ⊕ hash(f)) mod M
Bed-tree结构
构造了一个含两个层次 Bed-tree 型索引结构,每个中间节点代表一个叶节点集群与单词在特定字符串的间隔,即每个中间节点包含数据的上下边界向量(表示为 lb[m] 和 ub[m] (for 1≤m≤L))的所有叶节点下。
每个 Bed-tree 的叶节点包含一个数据向量和 hash(w)
一个布谷鸟过滤器,它包含的单词的编辑距离为 d 到 w,以及包含单词 w 的加密文件标识符列表。
查询词将按 N-gram 顺序转换为向量 vq,使用 ED 计算公式搜索每个中间节点的 lb[m] 和 ub[m](1≤m≤L),判断是否需要搜索该中间节点下的子节点。
随着允许的约束区间的增加(即中间节点的减少), Bed-tree 结构的构建成本降低,但由于每个中间节点将附加更多的叶节点,搜索成本将增加

4、方案实现
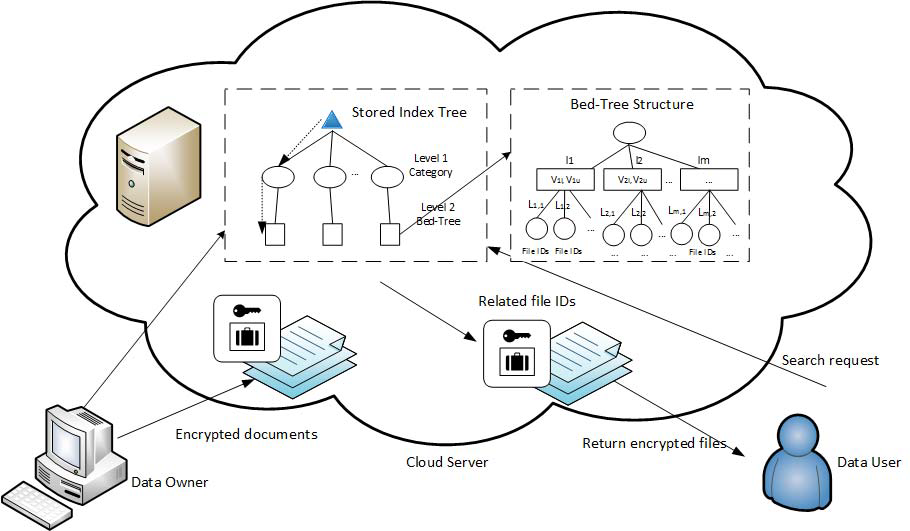
Setup
在初始化阶段,数据所有者生成密钥 SK,SK 由两部分组成
- (L+1)×(L+1) 随机矩阵 R,R 用于提供查询不可链接功能
- 四个随机变量 a、b、N、k
- SK = {R,a,b,N,k}
GenIndex(L,I,SK,M,e)
设需要构造加密索引树的关键字集合 I = {I1,I2},其中 I1 用于构造第一层类别节点,I2 用于构造附属的 Bed-tree 结构。选择 SHA-256 作为我们的键控哈希函数。此外,使用 L-element 数据向量和 M-bucket 布谷鸟过滤器,每个桶中有 e 个条目
对于每个包含关键字 CAi 的类别节点,CAi ∈ I1,所有者将 CAi 的哈希值的最低 k 位插入索引树第 1 层的 M-bucket 布谷鸟过滤器中
对于每个叶子节点包含关键字 kwi,其中 kwi ∈ I2,所有者通过 IndVec(N, kwi) 函数生成 V(kwi)。然后计算EncVec(kwi) = (V(kwi),1) × R,其中随机秘密矩阵R的元素 ∈ [1,L]
- IndVec(N,w):通过 N-gram 计数顺序计算单词 w 的 L-bucket 数据向量 V(w)。
对于每个 kwi,所有者计算一个行向量 EncHash(kwi) = [1/(a*hash(kwi)), 1/(b*hash(kwi))]
所有者生成一个集合 Ti = {wi1 ,···, wij···},其中 wij 为 kwi 的单错字。对于每个元素 wij,将其哈希值的最低 k 位插入到 M-bucket 布谷鸟过滤器中
加密的数据向量 EncVec(kw)、加密的哈希向量 EncHash(kw)、M-bucket 布谷鸟过滤器和加密的文件标识符存储在叶子节点中。然后,利用 Bed-tree 构造过程,计算出存储的所有关键字的数据向量,构造加密索引树 EncSK(I)。
GenQuery(L,Q,SK)
为了提供查询不可链接性,我们需要生成一个不同的加密查询,即使是使用相同的关键字。大小为 (L+1)×L 的排列矩阵 P,其中 L 是数据向量的长度,用于提供该特征。对于 P 的前 L 行,每一行只有一个非零元素。P的最后一行包含值为 1 或 -1 的元素
给定一个查询 Q = {Caq,kwq},其中 Caq 是 category 关键字,数据用户首先生成一个随机散列值,表示为
RH(Caq)) = {hash(Caq) + 2k*γ},其中 γ 是一个随机偶数
然后数据用户生成 P,并构造大小为 (L+1)×L 的 P’,它在第 1 个 L 行中具有与 P 相同的元素。P’ 的最后一行是由 P 的最后一行与标量值 α 相乘得到的,其中 α ∈ [1,L]。接下来,数据用户还计算(R−1 × P’)
对于每个 kwq,数据用户生成其数据向量 V(kwq),然后用 (V(kwq),α))乘以 P
再生成 hash(kwq),然后,他将 hash(kwq) 拆分为两个随机值 {hash(kwq)’,hash(kwq)”},这样 hash(kwq) = hash(kwq) ‘ +hash(kwq)”。接下来,数据用户计算列向量

- 其中 g1 = a*(hash(kwq)’) 和 g2 = b*(hash(kwq)”)。即使关键字是相同的,这个 MH(kwq) 向量将是不同的,因此提供关键字不可链接
数据用户还生成一个集合 tq= {q1,···,qi,···},其中 qi 是 kwq 的单错别字。对于每个元素 qi ,生成 RH(qi) = {hash(qi) + 2k*γ},其中 γ 是一个随机偶数。这一步确保相同的 qi 会产生不同的 RH(qi),因此提供了模糊关键字集合中任何单词的不可链接性
最后将加密搜索请求 EncSK(Q) = { RH(Caq),(V(kwq),α) × P,(R−1×P’), MH(kwq),RH(tq) },其中RH(tq)={RH(q1),···,RH(qi),···} 提交给云服务器。
Search(EncSK(I),EncSK(Q))

- 服务器首先检查存储在第一级节点的 M-bucket 布谷鸟过滤器中是否存在任何最低 k 位 hash 的 RH(Caq)。
- 如果找到,则从最匹配的类别节点中,云服务器在 bed-tree 结构中找到一个合适的第一个节点 im(i),并沿着节点 im(i) 下的叶子节点进行搜索,如下所示:
- 云服务器首先将 (V(kwi),1) × R 与 (R−1 × P’) 相乘。然后它将计算 (V(kwq),1) × P’ 和 (V(kwq),α) × P 之间的编辑距离使用 ED 计算公式
- 如果 ED((V(kwq),1) × P’, (V(kwq),α) × P) ≤ 编辑距离阈值 d,则云服务器将比较存储在叶节点中的加密哈希值
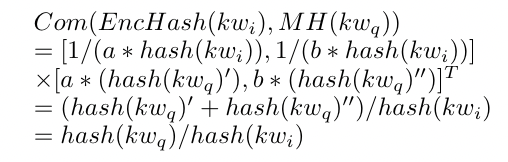
如果存在匹配 Com(EncHash(kwi),MH(kwq)) == 1,则返回存储在该节点中的文件标识符。
如果没有精确的匹配,则服务器判断存储的叶节点的 M-bucket 布谷鸟过滤器中是否存在最小 k 位的 RH(qi) 哈希值。如果找到,则服务器将检索匹配节点中的加密文件标识符,并将它们返回给数据用户。
⑩VCKSCF方案
论文名称:《VCKSCF: Efficient Verifiable Conjunctive Keyword Search Based on Cuckoo Filter for Cloud Storage》
- 作者:陈凡;董小磊;曹振富;沈家辰
- 单位:上海市可信计算重点实验室、华东师范大学
- 会议:TrustCom【CCF C】
- 时间:2021年12月
1、总体思路
提出了一种基于 Cuckoo 过滤器 (VCKSCF) 的可验证连接关键字搜索方案,该方案显着降低了验证和存储开销。安全性分析表明,该方案在面临选择关键字攻击下的不可区分性以及证明和搜索令牌的不可伪造性时实现了安全性。
本文的主要贡献归纳如下:
- 1.通过 Cuckoo 过滤器 (VCKSCF) 构建了一个高效且可验证的连接关键字搜索方案。创新策略产生更少的计算和存储开销
- 2.通过在服务器端采用特定的矩阵作为存储结构来保护最不频繁关键字的隐私,其中每个最不频繁关键字的位置由其左右部分确定
- 3.我们给出了正式的安全分析来证明我们的方案实现了IND-CKA安全,搜索令牌和特定关键字查询的证明是不可伪造的。在真实数据库中的实验表明,我们的方案具有较低的通信成本和优化的效率
由于本篇论文采用公钥密码实现,故不再深入。。。
⑪ESVSSE方案
论文名称:《ESVSSE: Enabling Efficient, Secure, Verifiable Searchable Symmetric Encryption》
- 作者:石振奎;傅雪梅;李贤贤;朱凯
- 单位:广西师范大学
- 会议:IEEE Transactions on Knowledge and Data Engineering【CCF A】
- 时间:2020年09月
1、总体思路
本文提出了一种基于 B+-Tree 和计数布隆过滤器 (CBF) 的高效 SSE 方案,该方案支持安全验证、动态更新和多用户查询。与之前的最新技术相比,我们设计了新的数据结构 CBF,以支持动态更新和增强验证。我们通过综合实验评估我们的方案。结果与我们的分析一致,表明我们的方案是安全的,并且与以前具有相同功能的方案相比更有效。当搜索关键字的缺失率为 20% 时,云服务器和用户的平均性能可以提高 20% 左右。并且丢失率越高,性能可以提高的越多。
2、使用技术
- B+-Tree
- 计数布隆过滤器(CBF)
3、方案概述
密钥生成
Gen(1k) → {K1,K2,K3,(ssk,spk)}
- 输入:安全参数 k
- 输出:私有密钥 K1,K2,K3 ,随机签名密钥对(ssk,spk)
初始化
Init(K1,K2,K3,ssk,D) → {I,π,πbf,C}

- 输入:
- 密钥 K1,K2,K3,签名私钥 ssk ,文档集 D
- 伪随机函数 F、G: {0,1}k x {0,1}* → {0,1}*
- 哈希函数 IH: {0,1}* → {0,1}k
- 输出:
- 基于 B+-Tree 的安全索引 I,加密文档 C,认证器 π 和 CBF 的认证器 πbf
- πbf 是一个验证器,当用户查询的关键字不存在时,它可以提供验证
- 操作:
- 倒排索引 ∆ = <ωi,Dωi> ,Dωi = {fi,fj,fk…}
- 陷门: τωi = F(K1,ωi)
- 关键字对应文档哈希值:Vωi = ∑fi∈Dωi IH(G(K2,fi))
- 索引:I = I.Insert(∆,τωi,Vωi)
- π = (Vωi,Sig(Vωi))、πbf = (ψnbf,Sig(ψnbf))
- 数据所有者在本地存储数据 I 和 πbf,同时将 I、C、π 和 πbf 发送到云服务器
预更新
PreUpdate(K1,K2,K3,ssk,f) → {τω,π,πbf}
- 输入:私钥 K1,K2,K3 ,签名私钥 ssk,要更新的文件 f
- 输出:更新 token τω ,认证器 π
- 操作:数据所有者将 τω,πbf 和 π 发送到云服务器
更新
Update(I,τω) → {I’}
输入:安全索引 I ,更新 token τω
输出:新的安全索引 I’
陷门
Trapdoor(K1,ω) → {τω}
由经过身份验证的用户运行,以生成给定关键字的陷门。
输入:密钥 K1,关键字 ω
输出:与 ω 对应的陷门 τω
操作: τωi = F(K1,ωi)
搜索
Search(I,τω,tq)→ {(ρ,πtq,πc,Rω)or(πbf)}
- 输入:安全索引 I ,陷门 τω、查询时间 tq
- 输出:搜索结果的路径列表 ρ,验证器 πtq、πc 、搜索结果的加密文档 Rω
- 操作:服务器将 ρ,πtq,πc,Rω 发送给用户,或者输出一个校对验证器 πbf
验证
Validation(K1,K2,K3,spk,Rω,ρ,πtq,πc,τω,πbf) → {0,1}
- 输入:对称密钥 K1,K2,K3,公钥 spk,查询结果 Rω,安全列表 ρ,认证器 πtq,πc,πbf ,ω对应的令牌 τω
- 输出:用户接受查询结果返回 1 ,拒绝查询结果返回 0
4、方案构建
安全索引
使用 B+ 树结构来构建安全索引,索引是根据文档集合 D 和倒排列表 ∆ 构建
完整倒排列表包括四部分:<ωi,Dωi,τωi ,Vωi>
- 关键字
- 关键字对应文档
- 关键词对应的陷门(Token)
- 关键字对应文档的哈希值
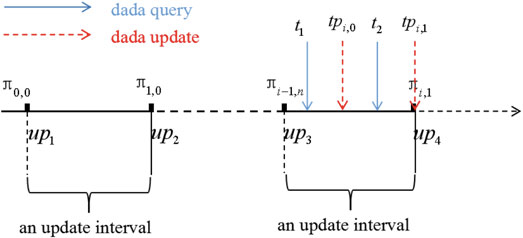
为了防止云服务器发起重放攻击,并保证根的新鲜度,为验证者维护了一个时间戳链,这样用户就可以跟踪链中的身份验证者,并确保根是否新鲜。
数据所有者根据下式生成验证者
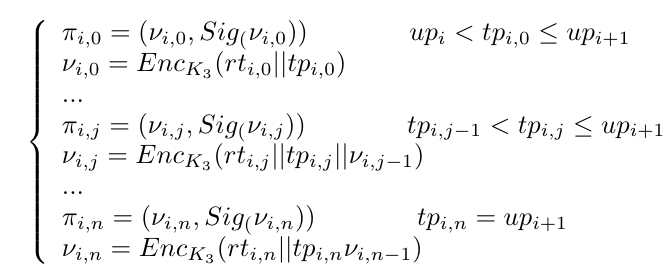
i 表示第 i 个更新间隔,j 表示该间隔内的第 j 个验证器
νi,j 代表 B+-Tree 的时间戳 tpi,j 和根 rti,j 的加密
πi,j 包含了νi,j 和数据所有者对 νi,j 的签名
根据下式计算 πbf ,πbf 是一个维护时间戳链和签名的验证器
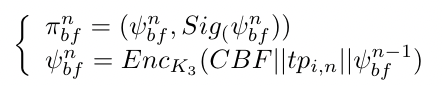
由于普通的 Bloom Filter 不支持动态更新。所以我们引入了 CBF,CBF 是一个 Counting Bloom Filter,本文中用它存储所有 token
假设数据所有者有三个令牌,服务器通过四个散列函数将其散列到 Bloom Filter。
假设用户查询一个令牌。服务器检查 CBF 中是否有一个 τωi对应,云服务器只需要检查对应的位置是否都是 1。如果全为 1,则要查询的 τωi 存在,否则不存在。
如下图所示,如果有两个关键字,被 3 个哈希函数散列到 Bloom Filter,CBF 对于加法操作,相应的位增加 1,删除操作对应的位减少 1
查询过程
当授权用户需要查询云服务器的数据时,用户首先为关键字生成一个陷门 token,然后用户将 token 发送到云服务器,云服务器执行搜索算法,具体算法如下图所示

Search(I,τω,tq)→ {(ρ,πtq,πc,Rω)or(πbf)}
当云服务器接收到用户发送的 token 时,考虑两种情况: 在索引中 token 存在或不存在。
服务器只需要将查询的 token 散列到另一个具有 k 个散列函数的 CBF。服务器通过测试对应位是否全部为 1 来验证用户查询到的 token 是否存在。
- 1、如果不是所有测试位都是 1,则证明 token 不存在。在这种情况下,服务器只需要返回 πbf 给用户,而不需要遍历 B+-Tree。搜索复杂度是 O(1)
- 2、如果所有测试位均为 1,则证明 token 存在。然后服务器需要搜索 B+-Tree 索引,并返回搜索路径 σ = (r0,…,ri,…,rm) ← I.search(τωi) 中每个节点的 token,从底部到根,不包括叶节点本身。ri ∈ {IN;LN},IN 为内部节点,LN 为叶节点
注意,对于内部节点,我们还需要返回不在搜索路径 σ 中的 token。然后,服务器需要找到验证器 πtq 和校验点 πc,且校验点 πc 与查询时间相近。服务器发送 ρ,πtq,πc,Cωi 给用户
验证结果
为了验证数据完整性,我们使用哈希函数将 B+-Tree 的每个节点从叶节点逐层哈希到根节点。用户可以根据根节点验证查询结果的完整性。另一种方法是,数据所有者只对所有叶节点进行散列。本文采用时间戳机制来验证数据的新鲜度。
时间戳机制如下图所示。它包括更新间隔和验证者π。更新间隔由数据所有者根据更新频率设置。验证器由根和 B+-Tree 的时间戳组成。
为了防止服务器返回查询结果的部分版本或历史版本。授权用户在收到云服务器发来的查询结果后,执行验证算法。同样,在两种情况下,结果得到了验证。一种是关键字不存在,另一种是关键字存在
当查询到的关键字不存在时,可以通过πbf验证器验证该关键字是否真的不存在。通过验证算法,用户可以验证服务器是否是恶意的。
CBF验证器由带时间戳的CBF Bloom Filter和数据所有者的相应签名组成。
用户可以通过CBF检查token是否存在。
通过时间戳机制可以检测CBF的新鲜度。
如果验证算法返回1,则用户接受服务器的结果。否则,它将拒绝返回的结果。用户可以证明该服务器是否是恶意的。验证的复杂度为O(1)。用户的成本可以忽略不计。
当搜索的关键字存在时,用户需要根据服务器返回的结果构建B+-Tree的根,并使用根来验证搜索结果的完整性。结果的新鲜度基于解密验证器中的时间戳进行验证。用户可以根据服务器返回的列表构建根,并通过与验证者的根进行比较来验证返回结果的完整性。
让我们通过下面的例子来解释什么是重放攻击。让我们考虑以下情况:
当用户在t1(见图7)查询时,其中t1<tpi,0,服务器只能返回πi−1,n给用户。当用户在t2查询tpi,0的数据更新事件后,服务器有两个选项:一个是返回验证者πi,0给用户;另一种是验证方发送πi−1,n给用户。当服务器向用户返回πi−1,n时,发起新鲜度攻击。
更新操作
更新算法更新服务器上的安全索引,支持三种操作,即添加、删除和编辑操作。
数据所有者首先执行预更新算法,为更新算法、CBF 和签名创建 token,并将它们发送到云服务器。
然后,云服务器执行更新算法对 CBF 和安全索引 I 进行更新。
因为安全索引和文件都是加密的。服务器无法从中学到任何有用的东西。
对于加法运算,数据所有者需要生成 {τω,GK2(f)} 对,其中 τω 是从文件 f 中提取的特定关键字的标记,GK2(f) 是 f 的伪随机字符串。
云服务器根据其 token 和值 {IHK2(f) }找到对应的叶节点。如果令牌没有对应的叶节点,则会创建一个新的叶节点。计数布卢姆滤波器中相应的位也需要增加1(见图5)。验证器πbf和π也需要根据数据进行更新
方案示例
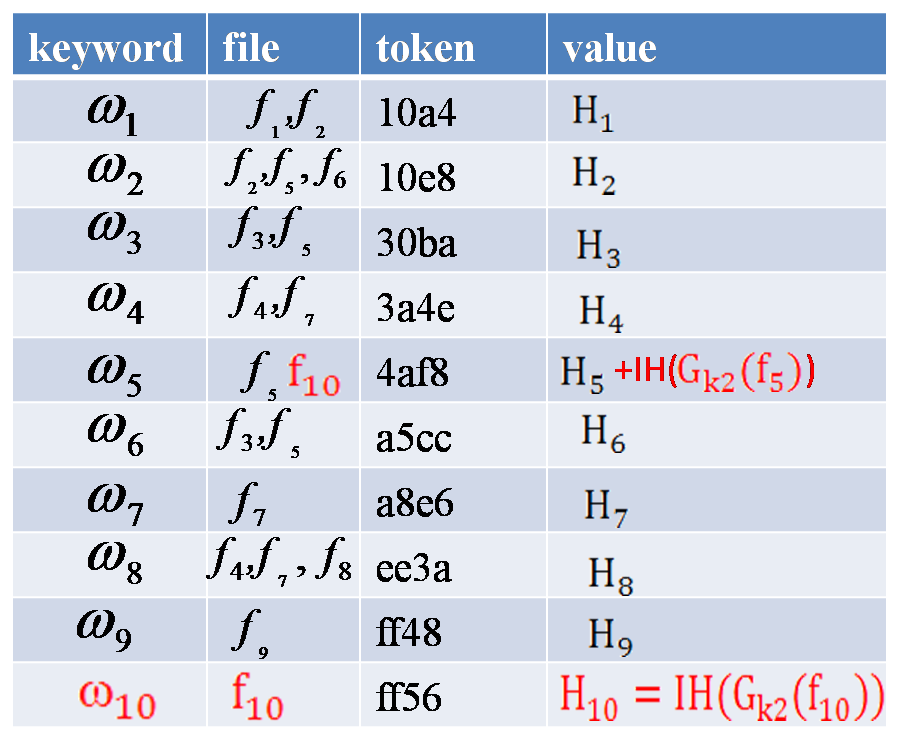
假设有 9 个文件需要初始化,即 D = {f1、f2、f3、f4、f5、f6、f7、f8、f9},其中包含 9 个关键字
倒排索引
数据所有者将所有 token 散列到 CBF,并生成 πbf 和验证器 π。
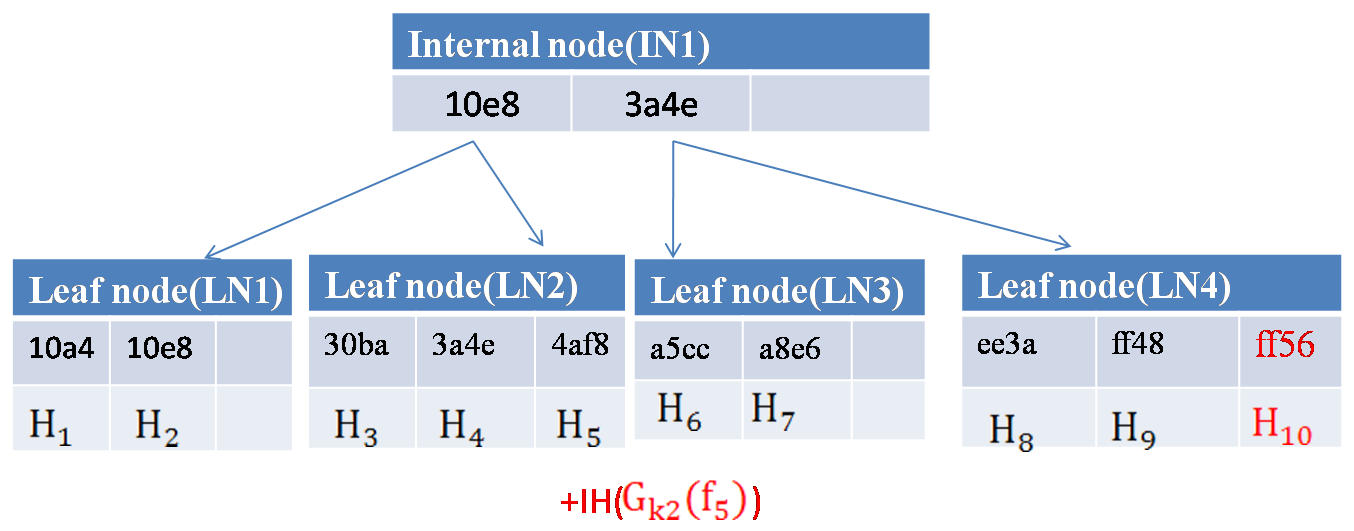
安全索引
通过将 (token-value) 键值对插入到 B+-Tree 中来构建安全索引
更新
添加新文件 f10 = {ω5,ω10},更新 token 和 value 分别为 [‘ 4af8 ‘,IH(GK2(f10))]和[‘ ff56 ‘,IH(GK2(f10))]。
对于已经存在的 token ‘4af8’,服务器需要在原始节点之后添加 IH(GK2(f10))。
对于新 token ‘ff56’,服务器需要创建一个新节点,并给它分配一个新值 IH(GK2(f10))。
数据所有者需要验证 πbf 和 π
查询
假设用户想要查询关键字 ω3 并提交相应的 token ‘30ba’
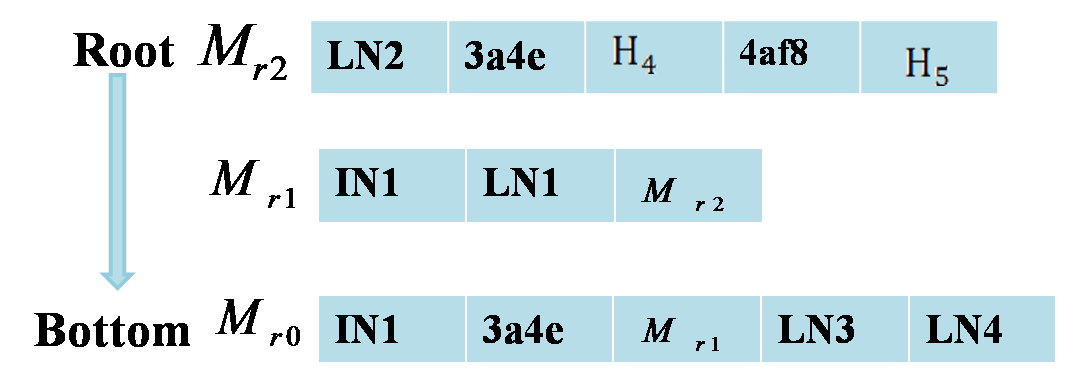
服务器收到用户的 token 后,首先测试该 token 是否存在于 CBF 中
如果存在,服务器将向用户搜索它。该 token 的搜索路径为 { IN1, LN2 },搜索列表为ρ = [Mr2,Mr1,Mr0]
当用户从服务器收到结果列表 ρ 时,运行验证算法
用户可以根据列表 ρ 生成根哈希
- 例如,如果存在攻击,服务器只返回文件 f3。用户可以重新构建根哈希值,该哈希值将与验证器的根不相同。所以它会返回0。如果它们相等,则证明服务器为用户返回正确的结果。
假设用户提交了一个索引中不存在的 token ,例如 token = ‘30bb’
服务器只需要发送给用户一个验证者 πbf 。用户验证签名,然后将查询到的 token 散列到 CBF’ 中。通过比较验证者 πbf 中解密的 CBF’ 和 CBF,验证了结果的正确性
⑫DMPR方案
论文名称:《Dynamic Multi-Phrase Ranked Search over Encrypted Data with Symmetric Searchable Encryption》
- 作者:郭成; 陈雪; 英默杰; 傅张杰; 李明初; 冯斌
- 单位:大连理工大学
- 会议:IEEE Transactions on Services Computing【CCF B】
- 时间:2017年10月
| 多关键字 | 模糊搜索 | 可验证 | 动态更新 | 排名 |
|---|---|---|---|---|
| ✅ | ❌ | ✅ | ✅ | ✅ |
1、总体思路
本文提出了一种对加密云数据的多短语排名搜索,该搜索还支持动态更新操作。使用倒排索引来记录关键字的位置,并判断该短语是否出现。此索引可以有效地搜索关键字。为了对结果进行排名并保护相关性评分的隐私性,在客户端的搜索过程中采用了相关性评分评估模型。此外,索引的特殊构造使方案具有动态性。数据所有者可以以非常低的成本更新云数据。通过安全分析和广泛实验,验证了所提方案的安全性和有效性。
本文中要解决的问题是如何设计一个支持动态、多短语、排名搜索的可搜索加密系统。
多短语排名搜索可以按相关性条件的排名顺序返回文件。排名搜索提高了传统搜索方法的实用性。
该方案是轻量级短语对称可搜索加密(LPSSE)和动态对称可搜索加密(DSSE)的扩展
2、使用技术
- 倒排索引
- TF-IDF
3、方案概述
动态多短语排名可搜索加密方案包含九种算法(KeyGen,Trapdoor,BuildIndex,Search,Verify,AddToken,Add,DeleteToken和Delete)。该方案由四个阶段的九种算法组成
Setup
数据所有者执行 KeyGen 和 BuildIndex 来初始化索引 I
首先,数据所有者通过执行算法 KeyGen 生成密钥,这些密钥用于加密文件集合 F 并构建索引 I
然后,数据所有者使用 BuildIndex 处理文件集合,数据所有者收集有关文件中关键字的信息,并以安全的方式将其存储在索引中。
在 Setup 阶段,数据所有者还应与一组授权数据用户共享必要的密钥(例如,在本例中为用于生成搜索令牌的密钥)
Retrieval
数据用户使用 Trapdoor 生成与待搜索短语相对应的安全搜索令牌,并将其发送到云服务器。
当云服务器收到搜索令牌时,它将搜索索引 I ,并获取有关候选文件的一组信息。
术语“候选文件”是指构成这些文件中显示的短语的单词。在此阶段,云服务器仅返回索引的部分信息 I 到数据用户。
Verify
当从云服务器接收信息时,数据用户将使用 Verify 验证目标短语是否出现在这些文件中。
在此过程中,数据用户将检查构成短语的关键字是否连续出现在文件中。
还将计算短语的 TF-IDF 并对结果进行排名,根据排名结果,数据用户可以向云服务器询问感兴趣的文件。
Update
当数据所有者想要将文件添加到文件集合或从中删除文件时,首先,他应该生成 addToken 或 deleteToken 并将其发送到云服务器。当云服务器收到 Token 时,它将更新索引 I 和文件集合 C 通过执行“Add or Delete”。
4、方案实现
K←Keygen(1k)
- K = (x,y,z,s,r)← {0, 1}k
(I,C)←BuildIndex(F,k)
索引 I 主要由搜索列表 As 和更新列表 Au 组成,搜索表 Ts 和更新表 Tu 用于确定列表的头部
数据所有者有一个文件集合 F = (f1,f2,…,fn) 和关键字集合 W = (w1,w2,…,wm),搜索列表 As 和搜索表 Ts 用于搜索操作。
对于每个关键字 wi ∈ W,都有一个与之相关联的列表 Lwi,列表中的节点数为 |Fwi|
如果有一个文件包含关键字 wi ,我们将在列表 Lwi 中添加一个节点,为了找到列表 Lwi 的头部,我们将头部的地址存储在搜索表 Ts 中。
为了高效地更新文件集合,我们使用更新列表 Au 和更新表 Tu,对于每个文件 fj ∈ F,我们建立一个列表 Lfj 来记录其中所有不同的单词。使用更新列表,我们可以更新索引,而不需要重新构建整个索引。

1.设 Ts 和 Tu 是大小为 |W| 和 |F| 的字典
2.对于关键字 wi ∈ W
a>产生 ki,0 ← {0,1}l
b>创建 |Fw| 个节点的 Lwi 列表 (N1, N2, …, N|Fw|),每个节点 value = Nki,j-1(gx(wi) || id(fj) || πs(loc) || φz(addr+1) || ki,j),并将 value 存储在 As[(φz(addr)]
id(fj) 是文件 fj 的标识符
πs(loc) 是 wi 在文件 fj 中的所有位置
φz(addr+1) 是下一个节点的索引
最后一个节点 N|Fw|,value 为 φz(addr+1) 设置为无效值。
- c>在搜索表 Ts 中,存储 value 为 (gx(wi) , <φz(addr) || ki,0 > ⊕ fy(wi)),其中 φz(addr) 是列表 Lwi 的头节点位置
3.对于在 F 中的文件 fi
a>产生 ki,0 ← {0,1}l
b>创建包含 | fi | 节点的列表 Lfi,定义 value = Nki,j-1(gx(id(fi)) || gx(wj) || fy(wj) || φz(addr+1) || ki,j),并将 value 存储在 Au[(φz(addr)]
c>在更新表 Tu 中存储 (gx(id(fi)), <φz(addr) || ki,0> ⊕ fy(id(fi)))
4.使用私钥加密 F 中的每个文件 f,得到 C
5.输出(I,C),其中 I 定义为 (Ts,As,Tu,Au), C 定义为 (c1,c2,. . . , cn)
Tp ← Trapdoor(phrase,K)
1.解析短语为 (w1,w2,. . . , wp)
2.对于关键字 wi ∈ phrase,Twi = (gx(wi), fy(wi))
3.输出 Tp = (Tw1, Tw2, …, Twp)
info←Search(I,Tp)
1.如果 |phrase| = 1
- a>解析 Tp 为 (α, β)
- b>在搜索表 Ts 中搜索 α
- c>设<ℇ || *k*> = Ts[α] ⊕ β
- d>使用密钥 k 解密节点 As[ℇ] ,然后逐个解密列表中的节点
- e>将列表中包含的节点输出为 info
2.如果 |phrase| > 1
- a>解析 Tp 为 (Tw1,Tw2,…,Twp)
- b>对于 Twi ∈ Tp,执行(1),并获取列表中包含的所有节点
- c>将列表中包含的节点输出为 info
如果我们假设数据用户想要搜索一个短语 p = (w1, w2)
首先,生成一个搜索令牌 Tp = (Tw1, Tw2),其中 Twi = {gx(wi),fy(wi)}
Tw1 = {gx(w1),fy(w1)} = (α1, β1)、Tw2 = {gx(w2), fy(w2)} = (α2, β2)
在搜索表 Ts 中搜索 α1 和 α2,计算 <ℇ1 || k> = Ts[α1] ⊕ β1 和 <ℇ2 || k> = Ts[α2] ⊕ β2,
- 即 <φz(addr1) || k1,0> = Ts[gx(w1)] ⊕ fy(w1) 和 <φz(addr2) || k2,0> = Ts[gx(w2)] ⊕ fy(w2)
服务器在 As 中找到对应列表 Lw1 = As[ℇ1] 和 Lw2 = As[ℇ2]
然后,服务器解密 Lw1 和 Lw2 列表的所有节点,并返回文件包含 w1 和 w2 两者的节点 info
Ip←Verify(info,Tp)
1.解析 info 为 (L1,L2,. . . , L|phrase|)
2.对于 Li ∈ info,解密节点并获取关键字的位置 πs(loc)
3.如果短语中的关键字在同一个文件 f 中连续出现,则将文件标识符添加到 Ip,用频率来计算短语出现的次数
- Ip 表示包含短语 p 的文件标识符
4.对于 Ip 中的每个文件,用频率和文件长度计算 TF-IDF 值,并在 Ip 中排序。
5.输出排序后的结果 Ip
当数据用户收到节点的信息时,将用它们来查找包含短语 p 的文件,这里假设短语 p 出现在 f1,f2 和 f3 中。数据使用者计算短语 p 在 f1, f2 和 f3 中的相关性得分。
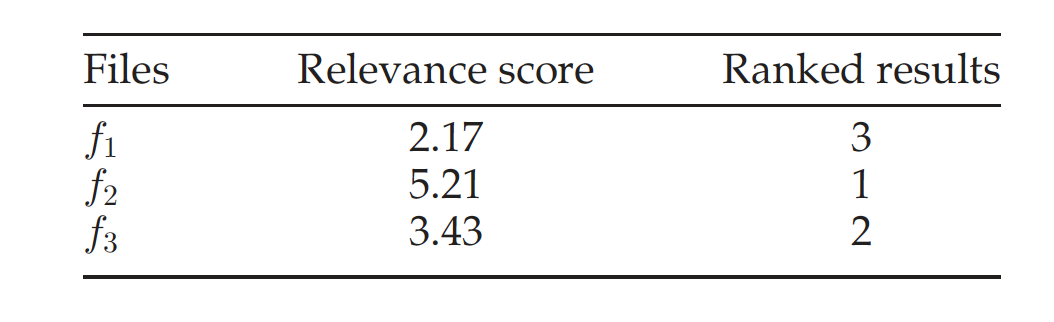
由表可知,相关得分分别为 2.17、5.21 和 3.43。数据用户可以根据这些相关性得分对文件进行排序,并获得排序结果。从表中,我们知道 f2 是与查询请求最相关的文件,而 f1 是最不相关的文件。数据用户可以获得排序结果,并从服务器请求所需的文件。
(Ta,cf)←AddToken(f,K)
1.设 (w1,w2,. . . ,wf) 是文件 f 中出现的关键字
2.设 Add token Ta = (α1, α2, . . . , αf, β, λ1, . . . , λf), 对于 i ∈ [1, 2, …, f]
- αi 为 (gx(wi), fy(wi), id(f), πs(loc), ki+1)
- β 为 (gx(id(f)), fy(id(f)), k0)
- λi 为 (gx(id(f)), gx(wi), fy(wi), ki+1)
3.对于文件 f,使用对称加密方案将其加密为 cf
4.输出 (Ta, cf)
Td←DeleteToken(f,K)
- 输出 Delete Token Td = (gx(f), fy(f))
(I’,C’)←Add(I,C,Ta,c)
- 1.解析 Ta 为 (α1, α2, . . . , αf, β, λ1, . . ., λf)
- 2.解析 β 为 (β1, β2, k’)
- 3.在更新表中 Tu 添加一个新的条目 (β1, <φz(addr) || k’> ⊕ β2)
- 4.对于 i ∈ [1,2,…, f],解析 αi 为 (α1, α2, γ, β, π’,k’),在搜索表 Ts 搜索 αi ,设 <ℇ || *k*> = Ts[α1] ⊕ α2,计算 Nk(α1 || γ || π’ || φz(addr+1) || k’) ,并将此节点添加到列表 Lwi 的末尾
- 5.在更新列表 Au 中添加一个新列表 Lf
- 6.对于 i ∈ [1,2,…, f],解析 λi 为 (λ1, λ2, λ3, k’),在 Lf 存储 Nk(λ1|| λ2 || λ3 || φz(addr+1) || k’)
- 7.将密文 c 添加到文件集合 C
添加一个文件。假设数据所有者想添加一个包含关键字 w1 和 w2 的新文件 f5
首先,他应该生成一个添加令牌 Ta = (infoa, c5),其中 c5 表示 f5 对应的加密文件,infoa 表示服务器必须添加到索引的节点信息。当服务器接收到“添加令牌”时,索引必须按照如下方式更新。
首先,在更新列表 Au 中添加一个包含文件 f5 的新列表 Lf5 ,在 Lf5 中的节点将存储 f5 中出现的所有关键字
在更新表 Tu 中,添加一个新的条目 Tu [gx(f5)]
服务器通过将条目 gx(f5) 设置为列表 Lf5 的头部来更新更新表
由于关键字 w1 和 w2 出现在文件 f5 中,服务器还应该更新搜索列表 Lw1 和 Lw2 ,服务器根据搜索表 Ts 获取列表 Lw1 和 Lw2 的头部,并在列表中添加新的节点。
(I’,C’)←Delete(I,C,Td)
- 1.解析 Td 为 (α, β)
- 2.在更新表中 Tu 中搜索 α
- 3.设<*ℇ* || *k*> = Tu[α] ⊕ β
- 4.使用密钥 k 解密节点 Au[ℇ] ,然后逐个解密列表中的节点,服务器将从这些节点获取文件 f 中包含的所有关键字,这里,我们假设文件 f 包含关键字 (w1,w2,. . . , wf),服务器将定位 L’ = (L1,L2,. . . , L|phrase|)的右边开始,服务器将从更新表 Tu 中删除条目 Tu[α]
- 5>对于列表 Lwi ∈ L’
- a>逐个解密列表中的节点
- b>如果 id(fj) 的值等于 id(f),请删除此节点
- 6.删除文件集合 C 中的密文 c
删除一个文件。假设数据所有者希望删除包含关键字 w1 和 w3 的现有文件 f1
首先,他应该生成一个删除令牌 Td = (gx(f1), fy(f1)),并将其提交给服务器。
当服务器收到删除令牌时,可以在更新表 Tu 中找到文件 f1 对应的条目,服务器计算 Tu = [gx(f1)⊕fy(f1)],得到列表 Lf1 的头部。
之后,服务器获取文件 f1 中包含的关键字,例如 (gx(w1), fy(w1)) 和 (gx(w3), fy(w3))
当删除一个文件时,服务器应该同时更新搜索列表和更新列表。根据列表 Lf1 的信息,服务器可以在搜索表中找到列表 Lw1 和 Lw3 的开始位置,并删除节点 (w1, f1) 和 (w3, f1) 。然后,服务器将从文件集合 C 中删除加密文件 c1
📌待看
矩阵在信息加密中的应用(密码学)_Juanrr的博客-CSDN博客_矩阵加密
CN107220343 基于局部敏感哈希的中文多关键词模糊排序密文搜索方法 (wipo.int)
对云中加密数据进行隐私保护的多关键字模糊搜索【CCF A】
本文利用局部敏感哈希技术,提出了一种新型的多关键词模糊搜索方案。我们提出的方案通过算法设计而不是扩展索引文件来实现模糊匹配。它还消除了对预定义字典的需求,并有效地支持多个关键字模糊搜索,而不会增加索引或搜索复杂性。对真实数据的广泛分析和实验表明,我们提出的方案是安全、高效和准确的。据我们所知,这是第一个在加密的云数据上实现多关键字模糊搜索的工作。
使用外部存储器|回答大型数据集上的近似字符串查询【CCF A】
本文开发了一种基于成本的自适应算法,该算法可以平衡检索候选匹配项和访问倒排列表的 I/O 成本。对大型真实数据集的实验证实,简单地将现有算法适应基于磁盘的设置并不能很好地工作,并且我们的新技术可以有效地回答查询。此外,我们的解决方案明显优于最近的基于树的指数 Bed-tree。
对云中的加密数据使用 N-Gram 和加密方法进行模糊关键字匹配|SpringerLink
布谷鸟搜索改进:https://link.springer.com/article/10.1007/s00500-016-2062-9【CCF C】
基于文档向量的多关键词密文检索 - 知乎 (zhihu.com)
No.13 PPPSED方案
论文名称:《Privacy-Preserving Phrase Search over Encrypted Data》
作者: 侯佳伟, 刘雅茹, 荣浩
单位:青岛大学
会议:ICBDT ‘21: 2021 4th International Conference on Big Data Technologies
时间:2021年12月
在本文中,我们提出了一个支持动态更新的短语搜索SSE方案。我们的方案只需要用户和云服务器之间的单轮交互,位置信息无法泄露。我们的方案利用虚拟二叉树(VBTree),它只是一个用于存储关键字的逻辑结构。在实际存储中,每个叶节点的元素都存储在哈希表中,非叶节点映射到布隆过滤器。为了确定搜索关键字的位置关系,我们的方案利用同态加密和双线性映射。这样,位置信息就无法泄露。
No.14 CBFED方案
论文名称:《A Searchable Ciphertext Retrieval Method Based on Counting Bloom Filter over Cloud Encrypted Data》
作者: kuang YueJuan, Li Yong, Li Ping
单位:
时间:2021年12月
本文首先构建了文献索引基于计数布隆过滤器检索,并映射关键字哈希在文件集合的计数布隆过滤器索引向量,所以实现了基于关键字的密文检索。同时,支持检索的动态更新文件索引。其次,对检索结果进行排序根据关联度不能达到的原因计数布隆过滤器本身没有语义函数。使用了频率矩阵,采用 TF-IDF 模型计算关键词的关联得分以便根据相关性得分对搜索结果进行排序。
📋Reference
- 可搜索加密SWP方案实现 - 简书
- 可搜索加密基础知识的归纳与总结
- 精选12篇区块链与可搜索加密相结合论文进行汇总与概括
- 专利:一种密文检索方法
- 专利:一种云存储密文检索方法及其系统
- 冯登国:密文检索——打开云存储加密桎梏的金钥匙
- 论文 | 可搜索加密 · 开山之作 - 知乎 (zhihu.com)
- 加密技术的未来:从服务端密码存储到用户数据加密方案
- 可搜索加密_笔记
- 可搜索加密1_笔记
- 可搜索加密之倒排索引
- 最牛一篇布隆过滤器详解
- 简单的复现 多关键字模糊可搜索加密
- Python学习-numpy高级数组和矩阵的内积函数inner和matmul
- TF-IDF(词频-逆文档频率)介绍 - 简书
- Searchable Symmetric Encryption (SSE)介绍
- 一种基于BloomFilter的改进型加密文本模糊搜索机制研究
- 密码学中的MAC
- Homomorphic MAC (unb.ca)
- bloom filter浅析(基本概念,概率分析,源码分析)
- NLP–文本向量化
- Secure nearest neighbor revisited
- 分类算法之K最近邻算法(KNN)的python实现
- [密码学的安全性浅析-3 - SecPulse.COM | 安全脉搏](https://www.secpulse.com/archives/175281.html#:~:text=MAC是指消息认证码(带密钥的Hash函数),是密码学中通信实体双方使用的一种验证机制,保证消息数据完整性的一种工具。,构造方法由M.Bellare提出,安全性依赖于Hash函数,故也称带密钥的Hash函数。 消息认证码是基于密钥和消息摘要所获得的一个值,可用于数据源发送方认证和完整性校验。)
- 密码学的安全性浅析-2 (qq.com)
- 编辑距离详解 - 知乎 (zhihu.com)
- 文本离散表示(三):TF-IDF结合n-gram进行关键词提取和文本相似度分析 - Luv_GEM - 博客园 (cnblogs.com)
❤️Sponsor
您的支持是我不断前进的动力,如果你觉得本文对你有帮助,你可以请我喝一杯冰可乐!嘻嘻🤭
| 支付宝支付 | 微信支付 |
 |
 |



