前言
爬虫学习暂时咕咕了。。。,等有空再继续更新
一、基础知识准备
Python基础语法还是很简单的,我通过一个个简单的小段代码来进行学习,所需掌握的知识点都包含在这段段代码中,每段代码都有相应详细注释,如果你有其他语言的基础那么Python基础就是轻轻松松的事。
1 条件判断语句
score = 60
if score >=90 and score <=100:
print("本次考试等级为A")
elif score >=70 and score <90: #elif == else if
print("本次考试等级为B")
else:
print("本次考试等级为C") #output: 本次考试等级为C
2 循环语句
2.1 for循环
for i in range(5): #输出5个数 [0 1 2 3 4]
print(i)
for i in range(0,10,3):#从[0,10),以3为间距输出 #output: [0 3 6 9]
print(i)
for i in range(-10,-100,-30):#从[-10,-100),以-30为间距 #output: [-10 -40 -70]
print(i)
name="chengdu"
for x in name:
print(x) #output: [c h e n g d u]
a = ["a", "b", "c"]
for i in range(len(a)):
print(i, a[i]) #output: [0 a 1 b 2 c]
2.2 while循环
i=0
while i<3:
print("这是第%d次循环:"%(i+1))
print("i=%d"%i)
i+=1
'''#output:
这是第1次循环:
i=0
这是第2次循环:
i=1
这是第3次循环:
i=2
'''
count = 0
while count<3:
print(count,"小于3")
count +=1
else:
print(count,"大于或等于3")
'''#output:
0 小于3
1 小于3
2 小于3
3 大于或等于3
'''
3 字符串
str="chengdu"
print(str) #chengdu
print(str[0]) #c
print(str[0:5]) #[0,5) cheng
print(str[1:7:2]) #[起始位置:结束位置:步进值] hnd
print(str[5:]) #显示5以后的 du
print(str[:5]) #显示5以前的 cheng
print(str+",hello") #字符串连接 chengdu,hello
print(str*3) #打印3次 chengduchengduchengdu
print("hello\nchengdu") #\n换行 hello chengdu
print(r"hello\nchengdu") #前面加"r",表示显示原始字符串,不进行转义hello\nchengdu
print("-"*30) #打印30个“-”
4 列表-List
列表中的每个元素都分配一个数字 - 它的位置或索引,第一个索引是0,第二个索引是1,依此类推。
4.1 列表定义
namelist = ["小张","小王","小李"]
testlist = [1,"测试","str"] #列表中可以存储混合类型
testlist = [["a","b"],["c","d"],["e","f","g"]] #列表嵌套
4.2 列表元素输出
namelist = ["小张","小王","小李"]
#输出指定元素
print(namelist[1]) #output: 小王
#遍历输出
for name in namelist:
print(name)
'''output
小张
小王
小李
'''
#使用枚举函数enenumerate(),同时拿到列表下标和元素类容
for i,name in enumerate(namelist):
print(i,name)
'''output
0 小张
1 小王
2 小李
'''
4.3 列表元素切片
如下所示:L=[‘Google’, ‘Python’, ‘Taobao’]
| Python | 表达式 结果 | 描述 |
|---|---|---|
| L[2] | ‘Taobao’ | 读取第三个元素 |
| L[-1] | ‘Taobao’ | 读取最后一个元素 |
| L[1:] | [‘Python’, ‘Taobao’] | 输出从第二个元素开始后的所有元素 |
| L[:-1] | [‘Google’, ‘Python’] | 输出从第一个到倒数第一个的所有元素 |
| L[-2:] | [‘Python’, ‘Taobao’] | 输出从倒数第二个到末尾的所有元素 |
4.4 列表元素追加
#append
a = [1,2]
b = [3,4]
a.append(b) #将b列表当做一个元素加入到a中
print(a) #output: [1, 2, [3, 4]]
#extend
a = [1,2]
b = [3,4]
a.extend(b) #将b列表中的诶个元素,逐一追加到a中
print(a) #output: [1, 2, 3, 4]
#insert
a=[1,2,4]
a.insert(2,3) ##在下标为2的位置插入3 #指定下标位置插入元素(第一个表示下标,第二个表示元素)
print(a) #output: [1, 2, 3, 4]
4.5 列表元素删除
#del
a = ["小张","小王","小李"]
del a[2] #删除指定下标元素
print(a) #output: ['小张', '小王']
#pop
a = ["小张","小王","小李"]
a.pop() #弹出末尾元素
print(a) #output: ['小张', '小王']
#remove
a = ["小张","小王","小李"]
a.remove("小李") #直接删除指定内容的元素
print(a) #output: ['小张', '小李']
4.6 列表元素修改
a = ["小张","小王","小李"]
a[2] = "小红" #修改指定下标元素内容
print(a) #output: ['小张', '小王', '小红']
4.7 列表元素查找
#in / not in
a = ["小张","小王","小李"]
findName = input("请输入你要查找的学生姓名:")
if findName in a:
print("找到")
else:
print("未找到")
#index
a = ["小张","小王","小李"]
print(a.index("小王",0,2)) #可以查找指定下标范围的元素,并返回找到对应数据的下标 #output: 1
print(a.index("小李",0,2)) #范围区间:左开右闭[0,2) # ValueError: '小李' is not in list
#count
print(a.count("小王")) #查找某个元素出现的次数 #output: 1
4.8 列表元素反转和排序
a = [1,4,2,3]
a.reverse() #将列表所有元素反转
print(a) #output: [3, 2, 4, 1]
a.sort() #升序
print(a) #output: [1, 2, 3, 4]
a.sort(reverse=True) #降序
print(a) #output: [1, 2, 3, 4]
5 前段知识综合练习
Topic: 将8个老师随机分配到3个办公室
import random
offices = [[],[],[]] #3个教室
teachers = ["A","B","C","D","E","F","G","H"] #8个老师
for teacher in teachers: #遍历teachers放入office中
index = random.randint(0,2) #产生随机数0,1,2
offices[index].append(teacher) #将teachers追加到office中
i=1 #office1
for office in offices: #输出每个office人数和对应的老师
print("office%d的人数为:%d"%(i,len(office)))
i += 1 #遍历offices
for name in office:
print("%s"%name,end="\t") #打印每个office老师的名字
print("\n") #打印完一个office换行
print("-"*20) #打印完一个office输出20个-
6 元组-Tuple
元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
6.1 元组定义
tup1=() #空元组
tup2=(5) #<class 'int'> 不是元组
tup2=(5,) #<class 'tuple'>
tup3 = ('Google', 'Python', 1997, 2000)
6.2 元组元素切片
tup=(1,2,3)
print(tup[0]) #第一个元素 #output: 1
print(tup[-1]) #最后一个元素 #output: 3
print(tup[0:2]) #左闭右开[0,2) #output: (1, 2)
6.3 元组元素增加(连接)
tup1 = (12,34,56)
tup2 = ("ab","cd","ef")
tup3 = tup1+tup2
print(tup3) #(12, 34, 56, 'ab', 'cd', 'ef')
6.4 元组元素删除
tup1 = (12,34,56)
#del tup1[0] #不允许删除单个元素
del tup1 #删除了整个元组变量
6.5 元组元素不能修改
tup1 = (12,34,56)
tup1[0] = 72 #报错 不能修改
7 字典-dict
字典使用键值对(key=>value)存储;键必须是唯一的,但值则不必。
7.1 字典定义
dict = {key1 : value1, key2 : value2 }
info = {"name":"简简","age":18}
7.2 字典访问
info = {"name":"简简","age":18}
print(info["name"])
print(info["age"])
#访问不存在键
print(info["sex"]) #直接访问不存在的键,会报错
print(info.get("sex")) #使用get()方法,访问不存在的键,默认返回:none
print(info.get("sex","没有")) #没有找到的时候,返回自定义值 #output: 没有
7.3 字典键值增加
info = {"name":"简简","age":18}
info["sex"]="man" #新增sex
print(info) #output: {'name': '简简', 'age': 18, 'sex': 'man'}
7.4 字典键值删除
#del
info = {"name":"简简","age":18}
del info["name"] #删除name键值对
print(info) #output: {'age': 18}
del info #删除整个字典
print(info) #output: NameError: name 'info' is not defined
#clear
info = {"name":"简简","age":18}
info.clear() #清空字典内键值对
print(info) #output: {}
7.5 字典键值修改
info = {"name":"简简","age":18}
info["age"]=20
print(info)
7.6 字典键值查找
info = {"name":"简简","age":18}
print(info.keys()) #得到所有的键 #output: dict_keys(['name', 'age'])
print(info.values()) #得到所有的值 #output: dict_values(['简简', 18])
print(info.items()) #得到所有的键值对 #output: dict_items([('name', '简简'), ('age', 18)])
#遍历所有的键
for key in info.keys():
print(key) #output: name age
#遍历所有的值
for value in info.values():
print(value) #output: 简简 18
#遍历所有的键值对
for key,value in info.items():
print("(key=%s,value=%s)"%(key,value))
#output: (key=name,value=简简) (key=age,value=18)
8 函数
8.1 函数定义和使用
def printinfo(a,b): #函数定义
c =a + b
print(c)
printinfo(1,2) #函数的使用
8.2 带返回值的函数
def info(a,b):
c =a + b
return c #返回值
print(info(1,2))
8.3 返回多个值的函数
def divid(a,b):
shang = a//b
yushu = a%b
return shang,yushu #多个返回值用逗号隔开
sh,yu = divid(5,2) #需要用多个值来保存返回内容
print("商:%d 余数:%d"%(sh,yu))
9 文件操作
9.1 打开文件(open)
用法:对象=open(文件名,访问模式)
f = open('test.txt', 'w')
| 模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
9.2 关闭文件(close)
用法:对象.close()
f.close()
9.3 写数据(write)
用法:对象.write()
f=open("test.txt","w") # 打开文件,w(写模式)-文件不存在就在当前路径给你新建一个
f.write("hello,world") # write将字符写入文件
f.close()
9.4 读数据(read)
用法:对象.read()
f=open("test.txt","r") #打开文件,r(读模式)
content=f.read(5) #read读取5个字符
print(content)
f.close()
9.5 读一行数据(readline)
用法:对象.readline()
f = open('test.txt', 'r')
content = f.readline()
print("1:%s"%content)#读取一行
content = f.readline()
print("2:%s"%content)#再读下一行
f.close()
9.6 读多行数据(readlines)
用法:对象.readlines()
f=open("test.txt","r") #打开文件,r(读模式)
content=f.readlines() #readlines读取整个文件,以列表形式输出
print(content) #输出形式为列表 #output: ['hello,world\n', 'hello,world']
#对列表进行处理,按序号一行一行输出
i=1
for temp in content:
print("%d:%s" % (i, temp))
i += 1 #output: 1:hello,world 2:hello,world
f.close()
9.7 OS模块
- 使用该模块必须先导入模块:
import os
os模块中的函数:
| 序号 | 函数名称 | 描述 | 格式 |
|---|---|---|---|
| 1 | getcwd() | 获取当前的工作目录 | 格式:os.getcwd() 返回值:路径字符串 |
| 2 | chdir() | 修改当前工作目录 | 格式:os.chdir() 返回值:None |
| 3 | listdir() | 获取指定文件夹中的 所有文件和文件夹组成的列表 | 格式:os.listdir(目录路径) 返回值:目录中内容名称的列表 |
| 4 | mkdir() | 创建一个目录/文件夹 | 格式:os.mkdir(目录路径) 返回值:None |
| 5 | makedirs() | 递归创建文件夹 | 格式:os.makedirs(路径) |
| 6 | rmdir() | 移除一个目录(必须是空目录) | 格式:os.rmdir(目录路径) 返回值:None |
| 7 | removedirs() | 递归删除文件夹 | 格式:os.removedirs(目录路径) 返回值:None 注意最底层目录必须为空 |
| 8 | rename() | 修改文件和文件夹的名称 | 格式:os.rename(源文件或文件夹,目标文件或文件夹) 返回值:None |
| 9 | stat() | 获取文件的相关 信息 | 格式:os.stat(文件路径) 返回值:包含文件信息的元组 |
| 10 | system() | 执行系统命令 | 格式:os.system() 返回值:整型 慎用! 玩意来个rm -rf 你就爽了! |
| 11 | getenv() | 获取系统环境变量 | 格式:os.getenv(获取的环境变量名称) 返回值:字符串 |
| 12 | putenv() | 设置系统环境变量 | 格式:os.putenv(‘环境变量名称’,值) 返回值:无 注意:无法正常的getenv检测到。 |
| 13 | exit() | 推出当前执行命令,直接关闭当前操作 | 格式:exit() 返回值:无 |
10 异常处理
10.1 异常简介
print '-----test--1---'
open('123.txt','r')
print '-----test--2---'

打开一个不存在的文件123.txt,当找不到123.txt 文件时,就会抛出给我们一个IOError类型的错误,No such file or directory:123.txt (没有123.txt这样的文件或目录)
10.2 捕获异常
try:
print('-----test--1---')
open('123.txt','r')
print('-----test--2---')
except IOError:
pass
此程序看不到任何错误,因为用except 捕获到了IOError异常,并添加了处理的方法
pass 表示实现了相应的实现,但什么也不做;如果把pass改为print语句,那么就会输出其他信息
总结:
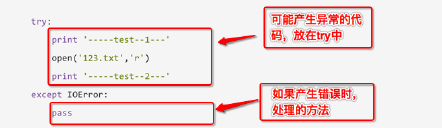
把可能出现问题的代码,放在try中
把处理异常的代码,放在except中
try:
print num
except IOError:
print('产生错误了')
上例程序,已经使用except来捕获异常,但是还会看到错误的信息提示
except捕获的错误类型是IOError,而此时程序产生的异常为 NameError ,所以except没有生效
try:
print num
except NameError:
print('产生错误了')
Python的一些內建异常:
| 异常 | 描述 |
|---|---|
| Exception | 常规错误的基类 |
| AttributeError | 对象没有这个属性 |
| IOError | 输入/输出操作失败 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| NameError | 未声明/初始化对象 (没有属性) |
| SyntaxError | Python 语法错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| 更多可以参考:http://blog.csdn.net/gavin_john/article/details/50738323 |
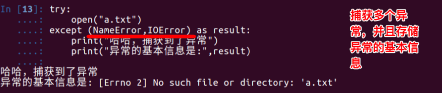
10.3 捕获多个异常
#coding=utf-8
try:
print('-----test--1---')
open('123.txt','r') # 如果123.txt文件不存在,那么会产生 IOError 异常
print('-----test--2---')
print(num)# 如果num变量没有定义,那么会产生 NameError 异常
except (IOError,NameError):
#如果想通过一次except捕获到多个异常可以用一个元组的形式
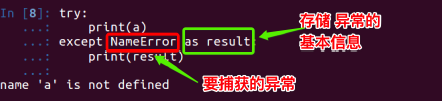
10.4 获取异常的信息描述
10.5 try…finally…
在程序中,如果一个段代码必须要执行,即无论异常是否产生都要执行,那么此时就需要使用finally。 比如文件关闭,释放锁,把数据库连接返还给连接池等
import time
try:
f = open('test.txt')
try:
while True:
content = f.readline()
if len(content) == 0:
break
time.sleep(2)
print(content)
except:
#如果在读取文件的过程中,产生了异常,那么就会捕获到
#比如 按下了 ctrl+c
pass
finally:
f.close()
print('关闭文件')
except:
print("没有这个文件")
test.txt文件中每一行数据打印,但是我有意在每打印一行之前用time.sleep方法暂停2秒钟。这样做的原因是让程序运行得慢一些。在程序运行的时候,按Ctrl+c中断(取消)程序。
我们可以观察到KeyboardInterrupt异常被触发,程序退出。但是在程序退出之前,finally从句仍然被执行,把文件关闭。
11 Python知识
除法
- 除 /
- 整除 //
- 求余 %
- 商和余数的元组 divmod
移位操作
左移(<<)
a<<n,则a' =a*(2^n),左移 n 位相当于原操作数乘以 2^n,原操作数不发生变化。
>>> 3<<1 # 向右移动一位,相当于是乘以2
6
>>> -3<<2 # 向右移动一位,相当于是乘以4
-12
右移(>>)
a>>n,则a' =a//(2^n),左移 n 位相当于原操作数整除 2^n,原操作数不发生变化。
>>> 2>>1 # 移动一位,相当于是2//2
1
>>> 2>>2 # 相当于先左移一位得到1,结果1再除以2等于0
0
>>> 2>>3 # 相当于2//8
0
>>> -8>>2 # 移动2位,相当于-8//4
-2
>>> -8>>3 # 移动3位,相当于是用结果-2再除以2
-1
>>> -8>>4 # 移动4位,相当于是用结果-1再除以2
-1
如果操作数是正数,那么对之不停进行右移操作,最终结果一定可以得到 0;如果操作数是负数,对之不停进行右移操作,最终结果一定可以得到 -1。
匿名函数lambda
匿名函数 lambda 是指一类无需定义标识符(函数名)的函数或子程序。
lambda 函数可以接收任意多个参数 (包括可选参数) 并且返回单个表达式的值。
语法:
lambda [arg1,arg2,.....argn]:expression
冒号前是参数,可以有多个,用逗号隔开,冒号右边的为表达式(只能为一个)。其实lambda返回值是一个函数的地址,也就是函数对象。
lambda arg: print("hello,world",arg)
lambda表达式限制只能包含一行代码,但是其实可以利用元组或列表强行让其包含多行。(但是这么做会严重影响可读性,除非万不得已不要使用)
lambda :(
print("hello"),
print("world"),
)
切片

t=[1,2,3,4,5]
print(t[1:]) 取第二个到最后一个元素
结果:[2 3 4 5]
print(t[:]) 取所有元素
结果:[1 2 3 4 5]
print(t[1:3]) 取t[1]-t[2]
结果:[ 2 3 ]
print(t[:-1]) 除了最后一个取全部
结果:[ 1 2 3 4 ]
print(t[::-1]) 取从后向前(相反)的元素
结果:[ 5 4 3 2 1 ]
print(t[2::-1]) 取从下标为2的元素翻转读取
结果:[ 3 2 1 ]
字符串方法
join(iterable)
获取可迭代对象(iterable)中的所有项目,并将它们连接为一个字符串。
实例1:
myTuple = ("Bill", "Steve", "Elon")
x = "#".join(myTuple)
print(x)
'''
输出:
Bill#Steve#Elon
'''
实例2:
myDict = {"name": "Bill", "country": "USA"}
mySeparator = "TEST"
x = mySeparator.join(myDict)
print(x)
'''
输出:
nameTESTcountry
'''
注释:在使用字典作为迭代器时,返回的值是键,而不是值。
split(separator, max)
将字符串拆分为列表,您可以指定分隔符,默认分隔符是任何空白字符。若指定 max,列表将包含指定数量加一的元素。
实例1:
txt = "welcome to China"
x = txt.split()
print(x)
'''
输出:
['welcome', 'to', 'China']
'''
实例2:
txt = "apple#banana#cherry#orange"
# 将 max 参数设置为 1,将返回包含 2 个元素的列表!
x = txt.split("#", 1)
print(x)
'''
输出:
['apple', 'banana#cherry#orange']
'''
内置函数
enumerate()
用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
实例1:
>>>seq = ['one', 'two', 'three']
>>> for i, element in enumerate(seq):
... print i, element
...
0 one
1 two
2 three
实例2:
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
exec()
exec 执行储存在字符串或文件中的 Python 语句,相比于 eval,exec可以执行更复杂的 Python 代码。
# 单行语句字符串
>>>exec('print("Hello World")')
Hello World
# 多行语句字符串
>>> exec ("""for i in range(5):
... print ("iter time: %d" % i)
... """)
iter time: 0
iter time: 1
iter time: 2
iter time: 3
iter time: 4
二、Python爬虫
下面的学习方式是以爬取豆瓣top250 网页进行开展的
基本流程: 爬取网页—>解析数据—>保存数据
1 requests库
Requests是一个简单方便的HTTP 库。比Python标准库中的urllib2模块功能强大。Requests 使用的是 urllib3,因此继承了它的所有特性。Requests 支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持URL和POST数据自动编码。帮助我们轻松解决关于HTTP的大部分问题。
爬取网页首先要学习requests库或者urllib库的使用,不然你无法看懂下面代码
学习requests库,请看我另外一篇文章,里面对requests库进行了详细的讲解Python模块-Requests学习
2 爬取网页
2.1 爬取豆瓣top250第一页数据
#-*- coding =utf-8 -*-
import requests
def askUrl(url):
head = { #模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.69 Safari/537.36 Edg/81.0.416.34"
# 用户代理:告诉豆瓣服务器,我们是什么类型的浏览器(本质上是告诉浏览器我们可以接收什么水平的文件内容)
}
html="" #用来接收数据
r = requests.get(url, headers = head) #get方式发送请求
html = r.text #接收数据
print(html)
return html
if __name__ == "__main__": # main函数用于测试程序
askUrl("https://movie.douban.com/top250?start=") #调用函数
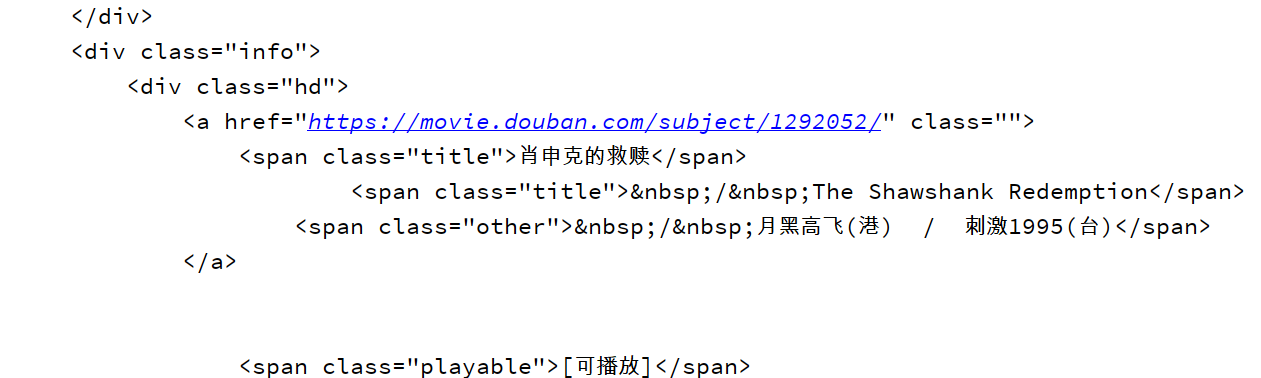
可以看到成功的爬取到豆瓣top250第一页的数据
2.2 爬取豆瓣top250前10页数据
#-*- coding =utf-8 -*-
import requests
#爬取一个页面
def askUrl(url):
head = { #模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.69 Safari/537.36 Edg/81.0.416.34"
# 用户代理:告诉豆瓣服务器,我们是什么类型的浏览器(本质上是告诉浏览器我们可以接收什么水平的文件内容)
}
#html=""
r = requests.get(url, headers = head)
html = r.text
print(html)
# 爬取所有页面
def getData(baseurl):
for i in range(0, 10):
url = baseurl + str(i * 25)
html = askUrl(url)
if __name__ == "__main__": # main函数用于测试程序
baseurl = "https://movie.douban.com/top250?start="
getData(baseurl)
可以看到排名250的梦之安魂曲也被成功爬取到
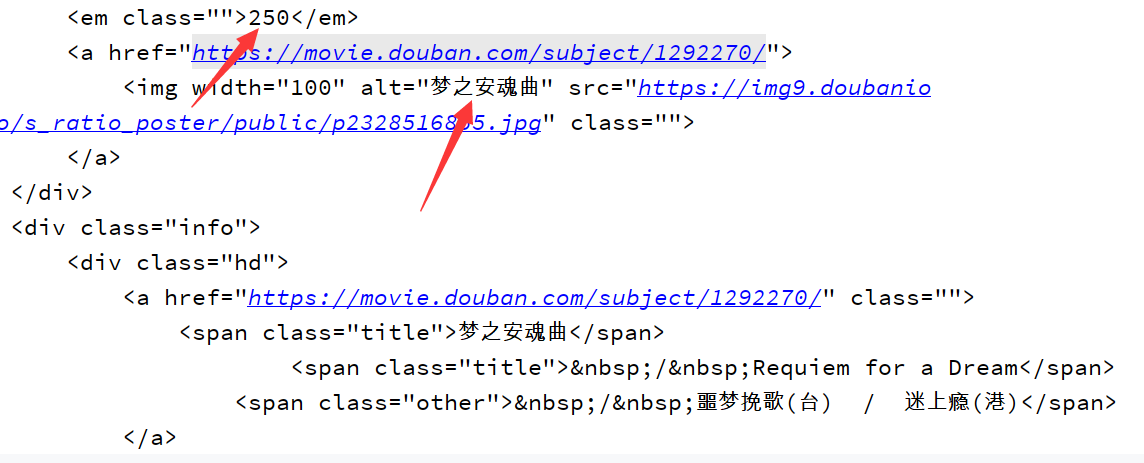
3 BeautifulSoup4库
BeautifulSoup4和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
以下只涉及基础使用,详情请看中文文档:Beautiful Soup 4.4.0 文档
假设有这样一个baidu.html,放在py文件目录下,下面的例子都基于该html,具体内容如下:
<!DOCTYPE html>
<html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="content-type" />
<meta content="IE=Edge" http-equiv="X-UA-Compatible" />
<meta content="always" name="referrer" />
<link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css" />
<title>百度一下,你就知道 </title>
</head>
<body link="#0000cc">
<div id="wrapper">
<div id="head">
<div class="head_wrapper">
<div id="u1">
<a class="mnav" href="http://news.baidu.com" name="tj_trnews"><!--新闻--></a>
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123</a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图</a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频</a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧</a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">更多产品 </a>
</div>
</div>
</div>
</div>
</body>
</html>
3.1 快速使用案例
# 导入模块
from bs4 import BeautifulSoup
# 读取html文件信息(在真实代码中是爬取的网页信息)
file = open("./baidu.html",'rb') #解析器
content = f.read()
f.close()
# 创建解析器
bs = BeautifulSoup(content,"html.parser")
# 输出网页内容:注:此内容已被缩进格式化(自动更正格式),其实这个是在上一步实例化时就已完成
print(bs)
#输出网页中title标签中的内容
print(bs.title.string)
3.2 BeautifulSoup4主要解析器
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库,执行速度适中,文档容错能力强 | Python 2.7.3 or 3.2.2前的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快 文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, [“lxml-xml”]) BeautifulSoup(markup, “xml”) | 速度快 唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性,以浏览器的方式解析文档,生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
3.2 BS4四大对象种类
BeautifulSoup4将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种
- Tag
- NavigableString
- BeautifulSoup
- Comment
3.2.1 Tag
Tag通俗点讲就是为了获取HTML中的一个个标签
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
# 获取title标签的所有内容
print(bs.title) #<title>百度一下,你就知道 </title>
# 获取head标签的所有内容
print(bs.head)
# 获取第一个a标签的所有内容
print(bs.a)
# 类型
print(type(bs.a)) # <class 'bs4.element.Tag'>
#bs 对象本身比较特殊,它的 name 即为 [document]
print(bs.name) # [document]
# head #对于其他内部标签,输出的值便为标签本身的名称
print(bs.head.name) # head
# 获取a标签里的所有属性,打印输出来,得到的类型是一个字典。
print(bs.a.attrs)
# {'class': ['mnav'], 'href': 'http://news.baidu.com', 'name': 'tj_trnews'}
#还可以利用get方法,传入属性的名称,二者是等价的
print(bs.a['class']) # 等价 bs.a.get('class')
# 可以对这些属性和内容等等进行修改
bs.a['class'] = "newClass"
print(bs.a)
# 还可以对这个属性进行删除
del bs.a['class']
print(bs.a)
3.2.2 NavigableString
既然我们已经得到了标签的内容,那么问题来了,我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可,例如
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
#获取title标签中的字符串
print(bs.title.string) #百度一下,你就知道
# 类型
print(type(bs.title.string))
#<class 'bs4.element.NavigableString'>
3.3.3 BeautifulSoup
BeautifulSoup对象表示的是一个文档的内容。大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性,例如:
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
#获取整个文档
print(bs)
print(type(bs)) #<class 'bs4.BeautifulSoup'>
3.3.4 Comment
Comment 对象是一个特殊类型的 NavigableString 对象,其输出的内容不包括注释符号。
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
print(bs.a)
# a标签如下:
# <a class="mnav" href="http://news.baidu.com" name="tj_trnews"><!--新闻--></a>
print(bs.a.string) # 新闻 #不会输出上面a标签中的注释符号
print(type(bs.a.string))
# <class 'bs4.element.Comment'>
3.3 遍历文档数
.contents:获取Tag的所有子节点,返回一个list
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
print(bs.head.contents) #获取head下面的所有直接子节点,返回列表
print(bs.head.contents[1 #用列表索引来获取它的某一个元素
.children:获取Tag的所有子节点,返回一个生成器
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
for child in bs.body.children:
print(child)
| .descendants | 获取Tag的所有子孙节点 |
|---|---|
| .strings | 如果Tag包含多个字符串,即在子孙节点中有内容,可以用此获取,而后进行遍历 |
| .stripped_strings | 与strings用法一致,只不过可以去除掉那些多余的空白内容 |
| .parent | 获取Tag的父节点 |
| .parents | 递归得到父辈元素的所有节点,返回一个生成器 |
| .previous_sibling | 获取当前Tag的上一个节点,属性通常是字符串或空白,真实结果是当前标签与上一个标签之间的顿号和换行符 |
| .next_sibling | 获取当前Tag的下一个节点,属性通常是字符串或空白,真是结果是当前标签与下一个标签之间的顿号与换行符 |
| .previous_siblings | 获取当前Tag的上面所有的兄弟节点,返回一个生成器 |
| .next_siblings | 获取当前Tag的下面所有的兄弟节点,返回一个生成器 |
| .previous_element | 获取解析过程中上一个被解析的对象(字符串或tag),可能与previous_sibling相同,但通常是不一样的 |
| .next_element | 获取解析过程中下一个被解析的对象(字符串或tag),可能与next_sibling相同,但通常是不一样的 |
| .previous_elements | 返回一个生成器,可以向前访问文档的解析内容 |
| .next_elements | 返回一个生成器,可以向后访问文档的解析内容 |
| .has_attr | 判断Tag是否包含属性 |
详情请看中文文档:Beautiful Soup 4.4.0 文档
3.4 文档的搜索find_all()
name参数
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
#字符串过滤:会查找与字符串完全匹配的内容
t_list = bs.find_all("a")
t_list = bs.find_all("title")
print(t_list)
#正则表达式过滤:如果传入的是正则表达式,那么BeautifulSoup4会通过search()来匹配内容
import re
t_list = bs.find_all(re.compile("a"))
print(t_list)
函数参数
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
#定义函数:传入一个函数,根据函数的要求来搜索
def name_is_exists(tag):
return tag.has_attr("name")#搜索包含name的标签
t_list = bs.find_all(name_is_exists)
for item in t_list: #打印列表内容
print(item)
keyword参数
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
#搜索id=head的内容
t_list = bs.find_all(id="head")
for item in t_list:
print(item)
#搜索class=manav的内容
t_list = bs.find_all(class_="mnav")
for item in t_list:
print(item)
#搜索链接的内容
t_list = bs.find_all(href="http://news.baidu.com")
for item in t_list:
print(item)
text参数
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
import re
#t_list = bs.find_all(text="hao123")
#t_list = bs.find_all(text=["hao123","贴吧","地图"])
t_list = bs.find_all(text=re.compile("\d"))#查找包含数字的文本
for item in t_list:
print(item)
limit 参数
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
t_list = bs.find_all("a",limit=3)
for item in t_list:
print(item)
3.5 css选择器
from bs4 import BeautifulSoup
file = open('./baidu.html', 'rb')
content = file.read()
bs = BeautifulSoup(content,"html.parser")
#通过标签来查找
t_list = bs.select('title')
#通过类名(.表示类)来查找
t_list = bs.select('.mnav')
#通过id(#表示id)来查找
t_list = bs.select('#u1')
#通过属性来查找 查找a标签中class=bri的内容
t_list = bs.select("a[class='bri']")
#通过父子标签来查找
t_list=bs.select("head > title")
#通过兄弟标签来查找
t_list=bs.select(".mnav ~ .bri")
for item in t_list: #打印列表内容
print(item)
print(t_list[0].get_text()) #拿到t_list中的文本
4 re库
正则表达式(Regular Expression)通常被用来
匹配、检索、替换和分割那些符合某个模式(规则)的文本。
4.1 正则表达式常用操作符
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示除 “\n” 之外的任何单个字符。 | |
| [ ] | 宇符集,对单个字符给出取值范围 | [abc]表示a,b,c;[a-z]表示a到z单个字符 |
| [^ ] | 非字符集,对单个字符恰给出排除范围 | [^abc]表示非a或非b或c的单个字符 |
| * | 前一个字符0次或无限次扩展 | abc* 表示ab、abc、abcc、abcc等 |
| + | 前一个字符1次或无限次扩展 | abc+ 表示abc、abcc、abcc等 |
| ? | 前一个字符0次或1攻扩展 | abc? 表示ab、abc |
| | | 左右表达式任意一个 | abc|def 表示abc、def |
| {m} | 扩展前一个字符m次 | ab(2}c表示abbc |
| {m,n} | 扩展前一个字符m至n次(含n) | ab{1,2}c表示abc、abbc |
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$表示abc且在一个字符串的结尾 |
| ( ) | 分组标记,内部只能使用|操作符 | (abc)表示abc ,(abc|def)表示abc、def |
| \d | 数字,等价于[0-9] | |
| \w | 单词字符,等价于[A-Za-z0-9_ ] |
4.2 re库常用函数
| 函数 | 说明 |
|---|---|
| re.compile() | 返回一个正则对象的模式。 |
| re. search() | 在一个字符串中搜素匹配正则表达式的第一个位置 ,返回match对象 |
| re. match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re. findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
| re. split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re. finditer() | 擅索字符串。返回一个匹配结果的迭代类型,每个选代元素是match对象 |
| re. sub() | 在一个字符串中普换所有匹配正则表达式的子串,返回替换后的字符申 |
4.2.1 compile()
格式:re.compile(pattern[,flags=0])
pattern: 编译时用的表达式字符串。flags: 编译标志位,用于修改正则表达式的匹配方式,如:re.I、re.S等
import re
pat=re.compile("A")
m=pat.search("CBA") #等价于 re.search(A,CBA)
print(m)#<re.Match object; span=(2, 3), match='A'> 表示匹配到了
m=pat.search("CBD")
print(m) #None 表示没匹配到
4.2.2 search()
在字符串中寻找模式
格式:
re.search(pattern, string[, flags=0])re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None。
import re
m = re.search("asd" , "ASDasd" )
print(m)# <_sre.SRE_Match object at 0xb72cd6e8> #匹配到了,返回MatchObject(True)
m = re.search("asd" , "ASDASD" )
print(m) #没有匹配到,返回None(False)
4.2.3 match()
- 在字符串开始处匹配模式
- 格式:
re.match(pattern, string[, flags=0])
import re
pat=re.compile( "a" )
print(pat.match( "Aasd" )) #输出None
pat=re.compile( "A" )
print(pat.match( "Aasd" )) #输出<_sre.SRE_Match object; span=(0, 1), match='A'>
注:match和search一旦匹配成功,就是一个match object对象,而match object对象有以下方法:
group() 返回被 RE 匹配的字符串
start() 返回匹配开始的位置
end() 返回匹配结束的位置
span() 返回一个元组包含匹配 (开始,结束) 的位置
4.2.3 findall()
列表形式返回匹配项
格式:
re.findall(pattern, string[, flags=0])
import re
#前面字符串是规则(正则表达式),后面字符串是被校验的字符串
print(re.findall("a","ASDaDFGAa"))
#[a,a] #列表形式返回匹配到的字符串
p = re.compile(r'\d+')
print(p.findall('o1n2m3k4'))
#执行结果如下:
#['1', '2', '3', '4']
print(re.findall("[A-Z]","ASDaDFGAa"))
#[ A , S , D , D , F , G , A ]
print(re.findall("[A-Z]+","ASDaDFGAa"))
#[ ASD , DFGA ]
pat = re.compile("[A-Za-z]")
print(pat.findall("ASDcDFGAa"))
#[ A , S , D , c , D , F , G , A , a ]
4.2.4 re. split()
按照能够匹配的子串将string分割后返回列表。
可以使用re.split来分割字符串,如:re.split(r’\s+’, text);将字符串按空格分割成一个单词列表。
格式:
re.split(pattern, string[, maxsplit])maxsplit: 用于指定最大分割次数,不指定将全部分割。
print(re.split('\d+','one1two2three3four4five5'))
# 执行结果如下:
# ['one', 'two', 'three', 'four', 'five', '']
4.2.5 finditer()
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
找到 RE 匹配的所有子串,并把它们作为一个迭代器返回。
格式:
re.finditer(pattern, string[, flags=0])import re iter = re.finditer(r'\d+','12 drumm44ers drumming, 11 ... 10 ...') for i in iter: print(i) print(i.group()) print(i.span()) ''' # 执行结果如下: <_sre.SRE_Match object; span=(0, 2), match='12'> 12 (0, 2) <_sre.SRE_Match object; span=(8, 10), match='44'> 44 (8, 10) <_sre.SRE_Match object; span=(24, 26), match='11'> 11 (24, 26) <_sre.SRE_Match object; span=(31, 33), match='10'> 10 (31, 33) '''
4.2.6 sub()
格式:
re.sub(pattern, repl, string, count)用repl替换 pattern匹配项
import re print(re.sub(a,A,abcasd)) #找到a用A替换,后面见和group的配合使用 #AbcAsd #第四个参数指替换个数。默认为0,表示每个匹配项都替换。 text = "JGood is a handsome boy, he is cool, clever, and so on..." print(re.sub(r'\s+', '-', text)) #\s:空格 #JGood-is-a-handsome-boy,-he-is-cool,-clever,-and-so-on...
4.3 模式修正符
所谓模式修正符,即可以在不改变正则表达式的情况下,通过模式修正符改变正则表达式的含义,从而实现一些匹配结果的调整等功能。
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
import re
string = "Python"
pat = "pyt"
rst = re.search(pat,string,re.I) # 第三个参数
print(rst)#<_sre.SRE_Match object; span=(0, 3), match='Pyt'>


