论文名称:《Verifiable Fuzzy Multi-keyword Search over Encrypted Data with Adaptive Security》
- 作者:童秋云; 苗银斌; 熊健; 刘希萌; 金光·雷蒙德·周; 邓磊
- 单位:西安电子科技大学
- 期刊:IEEE Transactions on Knowledge and Data Engineering【CCF A】
- 时间:2022年02月
| 多关键字 | 模糊搜索 | 可验证 | 动态更新 | 排名 |
|---|---|---|---|---|
| ✅ | ✅ | ✅ | ❌ | ❌ |
| 正确性 | 完整性 | 安全性 | 复杂度 | |
| ✅ | ✅ | IND-CKA2 | O(log m) |
1、方案简介
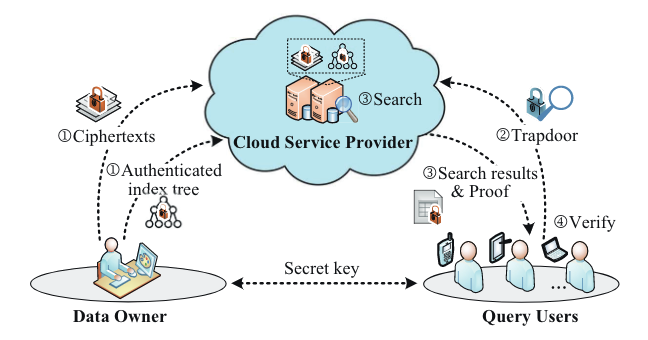
论文提出了一种具有自适应安全性的可验证模糊多关键字搜索(VFSA)方案。VFSA首先采用局部敏感散列(LSH)将拼写错误和正确的关键字散列到相同的位置,然后为每个文档设计一个双布隆过滤器(TBF)来存储和屏蔽文档中包含的所有关键字,然后基于图的关键字分区算法(GKP)构建索引树以实现自适应亚线性检索,最后将Merkle哈希树(MHT)结构与自适应的多集累加器(MSA)相结合,以检查搜索结果的完整性和正确性。通过安全分析表明,VFSA在IND-CKA2模式下是安全的,并实现了查询身份验证。使用真实数据集的实验证明了VFSA的实用性。
- 首先,使用 LSH 和 TBF 来支持自适应安全的模糊多关键字搜索
- 然后,使用 MHT 和 GPK 构造索引树,获得比线性搜索复杂度更快的搜索效果
- 最后,将 MHT 与MSA相结合,实现结果的正确性和完整性验证
2、使用技术
| 技术 | 作用 |
|---|---|
| 局部敏感散列(LSH) | 将拼写错误的关键字散列到相同的位置 |
| 双布隆过滤器(TBF) | 存储和屏蔽文档中包含的所有关键字 |
| Merkle哈希树(MHT) | 正确性和完整性验证 |
| 自适应多集累加器(MSA) | 正确性和完整性验证 |
| 基于图的关键字分区算法(GKP) | 提高搜索效率 |
⓵Locality Sensitive Hashing
主要用于高效处理海量高维数据的最近邻问题 ,使得 2 个相似度很高的数据以较高的概率映射成同一个hash 值,而令 2 个相似度很低的数据以极低的概率映射成同一个 hash 值。
⓶Twin Bloom Filter
TBF 是 BF 的一种扩展的数据结构。具体来说,TBF 是一个有 N 个双胞胎的位数组,其中每个双胞胎包含两个存储相反位的单元。TBF 可以掩盖插入位置和插入元素的数量,即可以同时存储和屏蔽关键字信息,而 BF 则完全暴露它们。TBF 包含四种算法:

❶$Setup(1^λ, k)→ {H_{key}, H}$
k+1 键控哈希函数 $H_{key}$ 可以使用 HMAC 生成 ,$ h_i(·) =HMAC (K_i, ·) $ , $K_i$ 是的随机生成的密钥,长度为 λ 。哈希函数 H 可以使用随机预言机 $\mathbb{H}:{0,1}^∗→{0,1}^∗$ 生成,$H =\mathbb{H}(·)%2$
$$
H_{key} = {h_i:{0,1}^∗ × {0,1}^λ → {0,1}^∗}
\\
H:{0,1}^∗→[0,1]
$$
❷$Initi(N, H_{key}, H, γ)→B$
生成长度为 N 的 TBF,对于每个双胞胎,选择的单元格和未选择的单元格分别初始化为 0 和 1
$$
B[ι][H(h_{k+1}(ι)⊕γ)] = 0
\\
B[ι][1−H(h_{k+1}(ι)⊕γ)] = 1, ι ∈ [1,N]
$$
γ 是一个随机数,用于消除不同 TBF 之间的相关性。否则,$B_i$ 和 $B_j$ 中第 $ι$ 个双胞胎选择的单元格是相同的,这降低了随机性,增加了数据暴露的风险
❸$Insert(B, w, H_{key}, H, γ) → B$
对集合 $W$ 中的每个元素 $w$ ,将其散列到 k 个位置 $B[h_1(w)],····,B[h_k(w)]$,然后对这 k 个位置选中的单元格设置为1,未选中的单元格设置为 0
$$
h_i(w) = h_i(w)\ mod \ N,i ∈ [1,k]
\\
B[h_i(w)][H(h_{k+1}(h_i(w))⊕γ)] = 1
\\
B[h_i(w)][1−H(h_{k+1}(h_i(w))⊕γ)] = 0, i∈[1, k]
$$
❹$Check(B, w’, γ)→0/1$
为了测试一个元素 $w’$ 是否存储在 $B$ 中,计算并检查下式。如果它对每个 $i ∈ [1,k]$成立,那么 $w’$ 在 B 中
$$
B[h_i(w’)][H(h_{k+1}(h_i(w’))⊕γ)]\overset{\text{?}}{=}1
$$
⓷Merkle hash tree
MHT 是一个简单而有效的身份验证结构模型,以二叉哈希树的形式呈现。MHT 的叶子节点是真实数据值的哈希值,非叶子节点是左右子节点哈希值的串联。
$$
h(h(left \ child)||h(right \ child))
$$
MHT 就是用来做完整性校验的, 允许对大规模数据的内容进行高效、安全的验证。但是,MHT有一个节点平衡的缺点,在插入或删除一系列请求后发生。因此,此技术不直接适用于可证明的数据拥有方案。
但是将 MHT 数据结构(Merkle,1980)和双线性聚合签名(Boneh等人,2003)相结合,可以解决 MHT 中的节点平衡问题。当数据所有者决定更新数据块时,她会将新数据块及其身份验证标记发送到云。收到更新请求后,云执行更新操作,重新生成 MHT 的根,更新聚合块标签并返回已签名的根 $sign_{pr} (root)$

参考:Merkle Hash Tree | ScienceDirect Topics、双线性配对、双线性配对- BLS 签名
⓸adapted multiset accumulator
自适应多集累加器(MSA)是通过从 CSP 中集合 $T_i$ 得到的,是一种基于双线性对 $(p,\mathbb{G},\mathbb{G}_T, e, g)$ 为两个集合 $T_1$ , $T_2$ 的不相交提供简短证明的有效方法。其中$\mathbb{G}$,$\mathbb{G}_T$ 是素数阶 $p$ 的两个乘法循环群,$g$ 是 $\mathbb{G}$ 的生成器,$e:\mathbb{G}×\mathbb{G}→\mathbb{G}_T$ 是一个双线性映射。MSA由以下四种算法组成:©
❶$KGen(1^λ)→{sk, pk}$
随机选择一个元素 $u∈\mathbb{Z}^*_p$ 作为私钥 $sk$,生成 $g^u$ 作为公钥 $pk$
❷$Acc(T_i, sk)→acc_i$
给定集合 $T_i$,$T_i$ 的累积值可计算为 $acc_i=g^{P(T_i)}= g^{r_i∏_{t∈T_i}(t+sk)}$,其中 $r_i$ 是 $\Z^*_p$ 中的一个随机元素
❸$PDisjoint(P(T_1), P(T_2), pk)→π$
如果 $T_1∩T_2=\varnothing$,则可计算不匹配证明 $π= (pk^{Q_1}, pk^{Q_2})$,根据扩展欧氏算法, $Q_1$、$Q_2$ 是满足 $P(T_1)Q_1+P(T_2)Q_2= 1$ 的两个多项式
❹$VDisjoint(acc_1, acc_2, π, sk)→{0,1}$
$T_1∩T_2=\varnothing$ 当且仅当 $e(acc_1, pk^{Q_1})·e(acc_2, pk^{Q_2}) =e(g,g)^{sk}$ 成立
请注意,CSP无法通过密文$P(T_1)$获得 $T_i$ 和 $sk$。因此,它不能通过伪造累积值来伪造不匹配证明
⓹Graph-based keyword partition
索引树中的文档分布对查询效率有很大影响,因为与左右子树都匹配的子查询将导致遍历两个子树。因此,使用基于图的关键字划分算法(GKP)来尽可能减小遍历宽度,其主要思想是最小化左右索引子树中相同关键字的数量
将每个文档 $f_i$ 作为顶点 $v_i$,两个文档 $f_i, f_j$ 相同关键词的个数为 $v_i$ 和 $v_j$ 之间的边的权值 $ω_{i,j}$,DO 构造了一个加权无向图 G 。然后,DO 按照下图的步骤将 $G$ 中的 $m$ 个顶点合并为两个顶点。为了保证索引是一个平衡二叉树,只能合并两个顶点 $v_i$ , $v_j$ 满足 $|v_i|+|v_j|≤⌈m/2⌉$,其中 $|v_i|$ 为顶点 $v_i$ 中包含的文档数量。
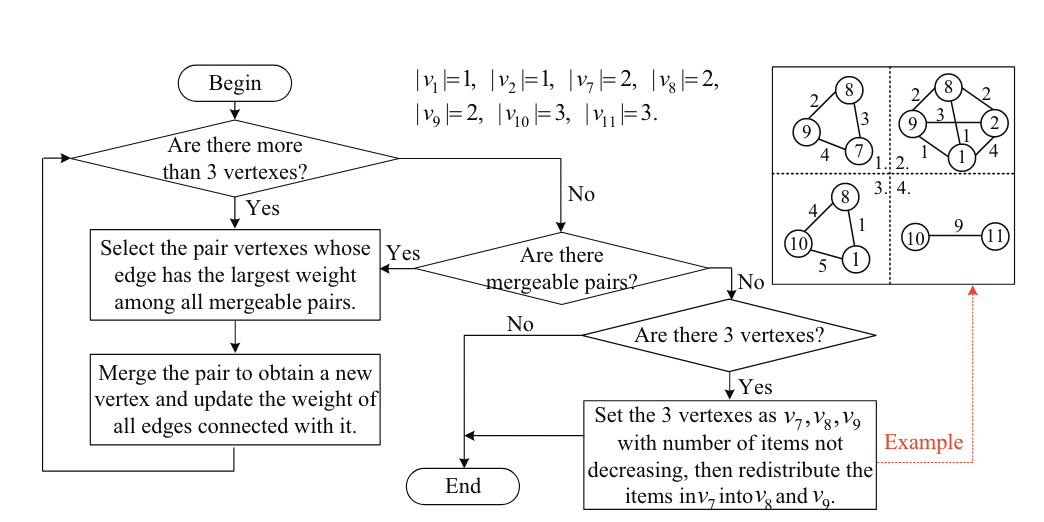
在所有可合并的顶点对中,DO首先选择边权值最大的对 ($v_i$ , $v_j$),然后将它们合并成一个新的顶点 $v_ρ$,最后更新与之相连的每条边的权值,边权满足 $ω_{ρ,s}≤ω_{i,s}+ω_{s,j}$ 。合并过程不断重复,直到没有两个顶点可以合并为止。在那之后,会发生两种情况
- Case 1:
结果图中只剩下两个顶点。DO 将这两个顶点作为的 $root$ 的左右子树,并将基于图的关键字分区算法分别应用于这两个点中包含的文档子集
- Case 2:
结果图中还剩下三个顶点 $v_{τ_1}, v_{τ_2}, v_{τ_3}$ 。DO 首先找出包含最少文档数量的顶点,然后将顶点中的所有文档重新分配到其他两个顶点。具体而言,我们假设 $|v_{τ_1}|≥|v_{τ_2}|≥|v_{τ_3}|$。对于每个文档 $f_i∈v_{τ_3}$, DO 计算它与 $v_{τ_1}、v_{τ_2}$相同关键字的个数 (表示权重 $ω_{i,τ_1}, ω_{i,τ_2}$) 。在所有这些权重中,DO 选择了最高的一个。假设最大权重 $ω_{i,τ_1}$, DO 比较 $|v_{τ_1}|$ 与$⌈m/2⌉$。如果 $|v_{τ_1}|≤⌈m/2⌉$,DO 将 $f_i$ 合并到$v_{τ_1}$中,重新计算 $v_{τ_3}$ 和 $v_{τ_1}$、$v_{τ_2}$ 中各文档之间的新权重,并重复这个重分配过程。否则,DO会将 $v_{τ_3}$ 中的所有文档合并到 $v_{τ_2}$ 中。
例如,在上图中,我们注意到 $v_7, v_8, v_9$ 中的任何两个顶点都是不可合并的,因为$|v_7|=|v_8|=|v_9|= 2$。在不丧失一般性的情况下,我们取 $v_7$ 为包含文档数量最少的顶点,并假设 $v_7$ 包含文档 $f_1, f_2$。
在 $f_i(i= 1,2)$ 和 $v_8, v_9$ 之间的权重中,我们发现最高的权重是 $ω_{2,9}= 3$。由于$|v_9|= 2<⌈5/2⌉$保持不变,我们将$f_2$ 合并到 $v_9$ 以生成新的顶点 $v_{10}$。之后,在顶点 $v_1、v_8、v_{10}$ 中分别包含1、2、3个文档。虽然最高权值是$ω_{1,10}= 5$,但我们将 $f_1$ 合并到 $v_8$ 中以生成新的顶点 $v_{11}$,因为$|v_{10}|=⌈5/2⌉$。
举个🌰:下图是基于GKP的五个文档 ${f_1,f_2,f_3,f_4,f_5}$ 的索引树构造示例
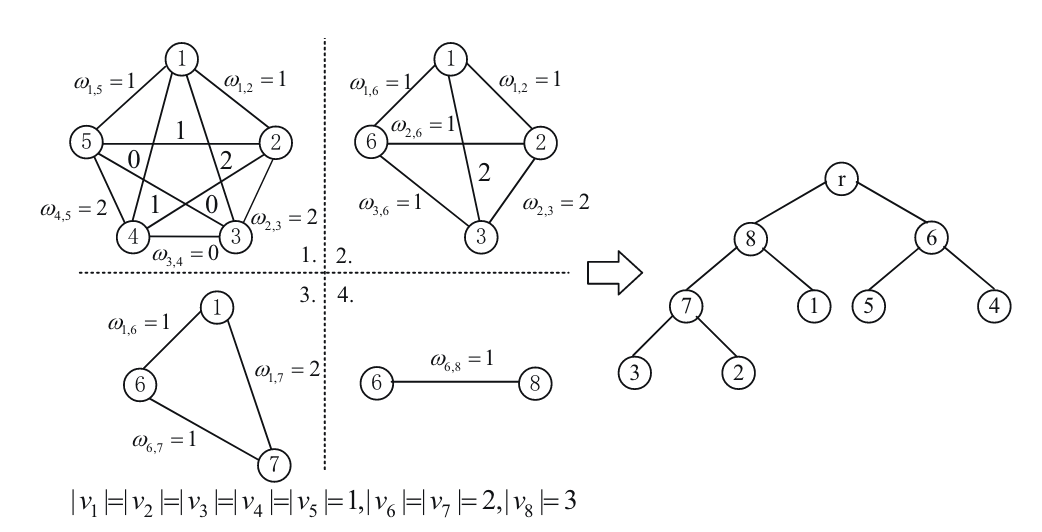
步骤一:顶点对 $(v_4, v_5),(v_2, v_3),(v_2, v_4)$ 具有最高的边权 $ω_{4,5}=ω_{2,3}=ω_{1,3}= 2$,在不丧失一般性的情况下,我们合并 $v_4, v_5$ 以获得一个新的顶点 $v_6$,
步骤二:为简便起见,假设 $ω_{ρ,s}=ω_{i,s}+ω_{s,j}$,重新计算与 $v_6$ 相连的每条边的权值
$$
ω_{1,6}=ω_{1,4} + ω_{1,5} = 0+1= 1
\
ω_{2,6} =ω_{2,4} +ω_{2,5} =0+1= 1
\
ω_{3,6} =ω_{3,4} +ω_{3,5} =0+1= 1
$$
在新的图中,最大边权值是 $ω_{2,3}=ω_{1,3}= 2$,在不丧失一般性的情况下,我们合并 $v_2, v_3$ 得到一个新的顶点 $v_7$
步骤三:当前图由 $v_1、v_6、v_7$ 三个顶点组成,分别包含1、2、2个文档。重新计算权重
$$
|v_7|≥|v_6|≥|v_1|
\
v_1={f_1}={w_1,w_3}\
v_6={f_4,f_5}={w_1,w_2,w_4}\
v_7={f_2,f_3}={w_1,w_3,w_5}
\
ω_{1,7}= 2, ω_{6,7}= 1
$$
由于最高边权值是 $ω_{1,7}= 2$ 和 $|v_1|+|v_7|= 3≤⌈5/2⌉$,我们合并 $v_1, v_7$ 得到一个新的顶点 $v_8$
步骤四:最后,我们将 $v_6、v_8$ 作为 $root$ 的左右子树来构建索引树。为了生成基于 GKP 的认证索引树,我们只需要将 $Algorithms \ 2$ 中的第8-9行替换为 $ID_l,ID_r←GKP(ID)$
3、流程概述
方案设计了一种自适应安全的模糊多关键字搜索机制。对于每个文档,我们首先使用LSH函数将拼写错误的关键字散列到相同的位置,然后设计一个TBF来存储和屏蔽这些散列值,以在IND-CKA2模型下实现隐私保护的模糊多关键字搜索。在查询阶段实现了比线性搜索复杂度更快的搜索。我们将所有文档的TBF作为叶节点来构建平衡索引树。在构建索引树时,我们使用基于图的关键字划分算法来最小化遍历宽度,从而进一步提高搜索效率。方案实现了正确性和完整性验证。我们首先使用自适应的多集累加器对未返回文档的不相交性和相应的查询关键字生成不匹配证明,以确保不丢失有效结果,然后通过MHT对索引树进行身份验证,以确保索引树中存储的内容不被篡改。
⓵首先为每个文档建立索引,然后基于这些索引构建索引树,最后检索包含所有查询关键字的文档。
⓶对于自适应安全的模糊多关键字搜索,每个文档的索引是一个 TBF,包含文档中的所有关键字。
- 具体来说,方案首先使用 LSH 处理每个关键字,这样拼写错误和正确的关键字就可以散列到相同的 bucket 中。
- 然后,方案将这些关键字的 bucket 值存储并屏蔽到 TBF 中,以实现自适应安全。这样,就生成了每个文档的索引。
⓷对于比线性搜索复杂度更快的搜索,方案通过将所有文档的索引作为叶节点来构建一个平衡的二叉树作为索引树。
- 索引树中的每个非叶节点也是一个TBF,由其子节点表示的所有关键字的联合构成。
- 如果非叶节点不包含查询关键字,则其子节点肯定不满足查询条件,因此可以修剪以非叶节点为根的子树中存储的文档,以实现次线性检索。
- 此外,在索引树的构建中,考虑文档分布对检索效率的影响,采用基于图的关键字划分算法来最小化左右索引子树中相同关键字的数量,以进一步提高检索效率。
⓸为了进行正确性和完整性验证,首先使用 MSA 对未返回文档的不相交性和相应的查询关键字生成不匹配证明,以确保不丢失有效结果;然后通过MHT对索引树进行身份验证,以确保索引树中存储的内容不被篡改。
首先方案运行 $MSA.Acc$ 分别计算每个树节点和每个查询关键字的累积值
如果树节点不包含某个查询关键字,则方案运行 $MSA.PDisjoint$ 生成一个不匹配证明表示它们的不相交。
在不匹配证明的帮助下,QU 运行$MSA.VDisjoint$,验证未返回的文档是否确实不满足查询条件,以确保没有遗漏有效结果。
使用 MSA 来验证搜索结果的完整性的前提是索引树被完整地存储,没有被篡改,这是由 MHT 来保证的。
方案根据 MHT 对存储在每个树节点中的内容进行散列。 root digest 采用数字签名技术进行签名,以防止被篡改。
如果原始 root digest 等于基于辅助证明信息重新计算的 root digest,则索引树没有被篡改。这样,实现了对搜索结果的正确性和完整性的验证。
4、具体实现
❶KeyGen
$KeyGen(1^λ, k)→ {PP, SK}$
⓵DO首先运行 $MSA.KGen→{pk, sk}$,用于结果验证
⓶再生成一对公私对 ${K_{pub}, K_{pri}}$ ,用于数字签名
⓷再运行 $TBF.Setup$ 输出 $H_{key}$ 和 $H$
⓸再生成一个键控哈希函数 $H_1 : {0,1}^∗× {0,1}^λ→ \mathbb{Z}_p$
⓹再随机生成传统的抗碰撞哈希 $H_2 : {0,1}^∗→ {0,1}^λ$
DO 最终输出 $PP={pk, K_{pub}, H, H_2},$ $SK={sk,K_{pri},H_{key}, H_1}$
❷IndexGen
$IndexGen(F, N, PP, SK)→I$
从文档 $F = {f_1,···, f_m}$ 中采用 Porter Stemming Algorithm 提取关键词 $W={w_1, w_2,···}$;DO 通过 $Algorithms \ 1,2$ 生成经过身份验证的索引树
 |
 |
|---|
| Fuzzy setting & adaptive encryption | Index tree & Authentication |
|---|---|
 |
 |
⓵Fuzzy setting
- 160 uni-gram vector $\vec{v_j}$
- LSH family: $ {h_{a_ι,b_ι}}^n_{ι=1}$
$$
S_j=h_{a_1,b_1}(\vec{v_j})||···||h_{a_n,b_n}(\vec{v_j})
$$
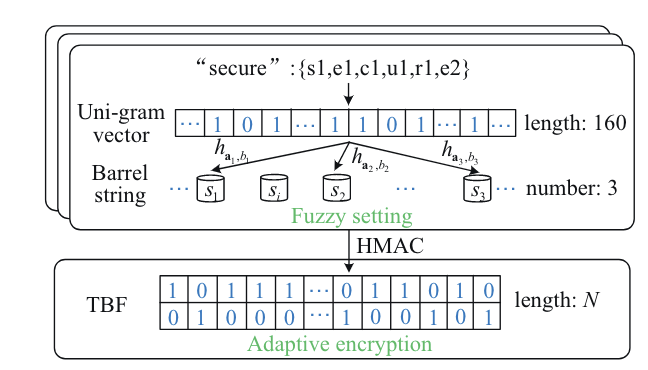
举个🌰:将单词 “secure” 放入 uni-gram 集合
1.首先分片: ${s1,e1,c1,u1,r1,e2}$
2.计算位置:${19,5,3,21,18,26+5}$
3.设置值:对应位置设为1,其他位置设置为0,生成160维 uni-gram 集合
4.映射到Bucket:使用 3 个 LSH ${h_{a_1,b_1},h_{a_2,b_2},h_{a_3,b_3}}$,将 $\vec{v_j}$ 散列为 3 个哈希值,如 $s_1,s_2,s_3$,并生成 Bucket String $S=s_1||s_2||s_3$
假设文档包含三个关键字,我们将相应的 3 个 Bucket String 映射到 TBF $B_i$
温馨提示:uni-gram 向量的长度和 LSH 函数的数量可以根据 DO 的需要改变。
⓶Adaptive encryption
DO 运行 $TBF.Initi$ 生成长度为 N 的 TBF $B_i$
再运行 $TBF.Insert$ 将 Bucket String $S_j$ 映射到 $B_i$
$$
B_i[h_1(S_j)],···, B_i[h_k(S_j)]
$$再生成 $tag$ $t_j=H_1(h_1(S_j)||···||h_k(S_j))$
$T_i $ 由 $f_i$ 所包含的关键字的所有标签组成,用于稍后生成累积值
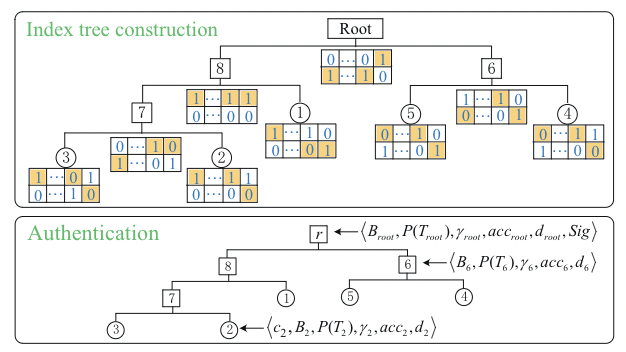
⓷Index tree construction
为了实现亚线性检索,DO 将所有文档的 TBF 作为叶节点来构造平衡的二进制索引树,索引树中的每个非叶节点也是一个 n 维 TBF,由其子节点表示的所有关键字集的并集构造而成。
- 设 $B_l$ 和 $B_r$ 是存储在节点 $L_f$ 的左右子节点中的两个 TBF ,存储在节点 $L_f$ 中的 TBF $B_f$ 构造如下:
$$
B_f = B_l ∨ B_r
\\
B_f[ι][H(h_{k+1}(ι)⊕γ_f)] =B_l[ι][H(h_{k+1}(ι)⊕γ_l)]∨B_r[ι][H(h_{k+1}(ι)⊕γ_r)]
\\
B_f[ι][1−H(h_{k+1}(ι)⊕γ_f)] = 1−B_f[ι][H(h_{k+1}(ι)⊕γ_f)]
$$
⓸Authentication
DO使用 MSA 和 MHT 验证索引树,如下所示
- 1.对于表示每个文档 $f_i$ 的叶节点,DO 生成一个累积值 $acc_i$ 和一个摘要 $d_i$
$$
acc_i=MSA.Acc(T_i, sk)
\\
d_i=H_2(c_i||B_i||acc_i)
$$
其中密文$c_i$是通过标准加密算法(如AES)加密文档而生成的
- 2.对于每个非叶节点 $L_f$,DO 生成一个累积值 $acc_f$ 和一个摘要 $d_f$
$$
acc_f=MSA.Acc(T_f, sk)
\\
d_f=H_2(H_2(d_l||d_r)||B_f||acc_f)
$$
其中 $T_f$ 是其子节点 $tag$ 集的并集($T_f=T_l∪T_r$)。$d_l$,$d_r$ 是其左右子节点的摘要
- 3.计算 root 摘要后,DO对其进行签名以获得 $Sig=sign_{K_{pri}}(d_{root})$
举个🌰:给定 5 个文档 ${f_1, f_2, f_3, f_4, f_5}$, 其中 $f_1={w_1, w_3}$, $f_2={w_1, w_5}$, $f_3={w_1, w_3, w_5}$, $ f_4={w_2, w_4}$, $f_5={w_1, w_2, w_4}$
1.首先将它们转换为 5 个 TBF,然后以 5 个TBF为叶节点构造平衡二叉索引树,实现亚线性检索。在使用 MSA 和 MHT 对其进行身份验证后
每个非叶节点存储五个组件:$<B,P(T),γ,acc,d>$
每个叶节点多存储一个组件:密文 c
根节点多存储一个组件:签名 Sig
2.假设关键字 $w_1$ 的 Bucket String 散列到位置 1、2、3,其标签 $t_1=H_1(1||2||3)$类似地,$w_2、w_4、w_5$ 标签是计算 $t_2、t_4、t_5$
3.将叶节点 $L_2$ 的累积值和摘要计算为 $acc_2=MSA.Acc({t_1,t_5},sk)$ 和 $d_2=H_2(c_2||B_2||acc_2)$
4.非叶节点 $L_6$ 的累积值和摘要计算为 $acc_6=MSA.Acc({t_1,t_2,t_4},sk)$ 和 $d_6=H_2(H_2(d_4||d_5)||B_6||acc_6)$
❸TrapGen
$TrapGen(Q, SK)→ {TK, T_Q}$
对于每个查询关键字 $w_i’∈Q$,QU 首先像 DO 在模糊设置步骤中一样将其转换为Bucket String $S_i’$,然后将 $S_i’$ 加密为 $tk_i$,并生成标签 $t_i’$
$$
tk_i={(h_1(S_i’), h_{k+1}(h_1(S_i’))),···,(h_k(S_i’), h_{k+1}(h_k(S_i’)))},
\\
t_i’=H_1(h_1(S_i’)||···||h_k(S_i’))
$$
这样,QU 得到陷门 $TK = {tk_1,···,tk_q}$ 和标签集 $T_Q={t_1’,···,t_q’ }$,其中$q$ 为搜索查询 $Q$ 中包含的查询关键词的个数
❹Search
$Search(I, TK, T_Q, PP)→ {R, AP}$

收到搜索请求 $TK = {tk_1,···,tk_q}$ 后,CSP 从根节点检索经过身份验证的索引树 $I$,通过 $Algorithm \ 3$ 查找包含所有查询关键字的叶节点
从根节点开始,CSP 检查当前节点 node 是否包含所有查询关键字(第1-8行)
如果 $node.B[h_ι(S_i’)][H(h_{k+1}(h_ι(S_i’))⊕node.γ)] = 1$ 适用于 $∀ι ∈ [1,k], i∈[1,q]$,则返回1,表示该节点包含所有查询关键字。
然后,CSP 检查当前节点 node 是否是叶子节点。如果是,CSP将相应的密文 $c_i$ 添加到搜索结果集 $R$ (第10-11行)
之后,CSP 添加元组 $⟨node.B, node.acc⟩$ 到辅助证明集 $AP$,并以相同的方式处理其左右子树(第12-14行)
如果 $∃i∈[1, q], ι∈[1, k], node.B[h_ι(S_i’)][H(h_{k+1}(h_ι(S_i’))⊕node.γ)] = 0$,它返回标签 $t_i’$ ,表示该 node 不包含查询关键字 $w_i’$。
然后, CSP 运行$MSA.PDisjoint$ 为当前节点 node 和查询关键字 $w_i’$ 生成不匹配证明 $\pi$,并添加元组 $⟨node.d, node.acc, t_i’, π⟩$ 到 $AP$ (第16-17行)
🙋🏻♂️🌰:当查询为 $Q={w_1,w_3}$ 时辅助证明集的示例
在 5 个文档中,只有文档 $f_1、f_3$ 包含这两个关键字。
因此,返回 $c_1、c_3$ 作为搜索结果
辅助证明集 $AP$ 由搜索路径上各节点的 TBF $B_i$ 和累积值 $acc$、搜索路径外各节点的摘要 $d_i$ 、累积值 $acc$、不匹配标记 $t_i’$ 和不匹配证明 $\pi$ 以及签名 Sig 组成。

❺Verify
$Verify(R, AP, PP, SK)→1/0$
使用辅助证明集 $AP$,验证者首先运行 $MSA.VDisjoint$ 检查搜索查询 $Q$ 是否确实与未返回的文档不匹配,然后重构最小认证树,并将其 $root$ 摘要与原始 $root$ 摘要进行比较,以验证搜索结果的正确性和完整性。
在我们的例子中,验证者首先检查公式 14,以证明文档 $f_2, f_4, f_5$ 不包含查询关键字 $w_3$,这确实与搜索查询 $Q={w_1, w_3}$ 不匹配。
然后验证者使用对应的公钥对签名 $Sig$ 进行解密,得到原始根摘要 $d_{root}$,即 $d_{root}=ver_{K_{pub}}(Sig)$。最后,验证者重新计算公式15中的根摘要 $d_{root}’$,并将其与根进行比较。如果它们相等,则搜索结果是正确和完整的
$$
MSA.VDisjoint(acc_2,MSA.Acc(t_3, sk), π_2, sk) = 1
\\
MSA.VDisjoint(acc_6,MSA.Acc(t_3, sk), π_6, sk) = 1
$$
$$
d_i’=H_2(c_i||B_i||acc_i), i= 1,3
\\
d_7’=H_2(H_2(d_3’||d_2)||B_7||acc_7)
\\
d_8’=H_2(H_2(d_7’||d_1’)||B_8||acc_8)
\\
d_{root}’=H_2(H_2(d_8’||d_6)||B_{root}||acc_{root})
$$
Sponsor❤️
您的支持是我不断前进的动力,如果您感觉本文对您有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用,拒绝白嫖,从你我做起!🥰🥰🥰
| 支付宝 | 微信 |
 |
 |


