⓪前言
本科的时候上过《数据结构与算法》课,但彼时天真的以为搞安全不需要懂太多算法,算法部分也就没有深入去学习,没想到读研还是没能逃过,此时也已经意识到算法的重要性,初学算法时真的觉得这东西晦涩难懂,貌似毫无用处,但渐渐明白搞懂算法背后的核心思想能让你写出更加优雅的代码。作此文的目的有四,一来是复习本科阶段学了但又遗忘的知识;二来感到近日记忆力下降明显,学过的东西不一会就忘了,记下来以便日后复习吧,再者好记性不如烂笔头;三来是以此做为 UESTC 研一《高级算法设计与分析》课程的期末复习笔记;四来是希望能给此时正在看此文的你一点点帮助吧。小简的水平和精力有限,文章中难免存在一些错误和不足,恳请读者批评指正,如发现错误,请及时与简简联系进行更正,我们共同使文章更加完善,大家可以在评论区留下自己想法,一起交流,谢谢🙏
课件下载:https://jwt1399.lanzouo.com/b01cy151a 密码:1399- 配合数据结构与算法 | 简言之 (jwt1399.top)食用效果更佳
①算法引论
本章重点:
- 理解什么是算法,算法的特征,算法和程序的差别;
- 理解什么是判断问题和优化问题。
❶什么是算法
- 算法是求解问题的一系列计算步骤,用来将输入数据转换成输出结果
从蛮力到策略 - 数据结构是数据的组织与存储:
从杂乱无章到井然有序 - 算法 + 数据结构 = 程序
❷算法的特征
输入性:必须有0个或多个输入(待处理信息)
输出性:应有一个或多个输出(已处理信息)
确定性:组成算法的每条指令是清晰的、无歧义
有穷性:算法必须总能在执行有限步之后终止
❸什么是好算法
正确性:符合语法、编译通过;
健壮性:能辨别不合法的输入并做适当的处理,不至于异常退出(崩溃)
可读性:结构化 + 准确的命名 + 注释
效率性:速度尽可能快;存储空间尽可能少
❹算法和程序的差别
- 程序是算法用某种程序语言的一个具体实现
- 程序是用来给计算机读的,算法是给人来读的
- 程序可以不满足算法的有穷性。
❺判断问题和优化问题
- 判断问题:是否存在一个…(如小于k的点覆盖)
- 优化问题:找出最大/最小的…(最小点覆盖)
很多经典的难问题都是优化问题,而一个优化问题往往可以转换成对应的判断问题。
❻经典算法分析
贪心算法:逐步建立一个解决方案,具体地优化一些局部准则。 自顶向下。
分治算法:将一个问题分解成独立的子问题,求解每个子问题,并将子问题的解组合起来形成原问题的解。 自顶向下。
动态规划:把一个问题分解成一系列相互重叠的子问题,并为越来越大的子问题建立解决方案。自底向上。
②算法复杂度
本章重点:
理解指数增长的恐怖;理解算法分析里为什么常数倍的差别可以被忽略
掌握渐近符号O、W、Q的含义,能判断一个函数属于哪个渐近增长阶;
能对给定函数按照渐进增长率进行排序,典型考题:
❶渐近符号

Θ(渐近紧确界):
存在正常数 c1 , c2和 n0 使得对所有n ≥ n0有:c1g(n) ≤ f(n) ≤ c2g(n),记为f(n) ∈ Θ(g(n))
例如:n2+3n+2∈Θ(n2)、n(n-1)/2∈Θ (n2)、4n2+5 ∈Θ (n2)
O(渐近上界):
存在正常数 c 和 n0 使得对所有n ≥ n0有:f(n) ≤ cg(n),记为f(n) ∈ O(g(n))
例如:n ∈O(n2)、100n+5 ∈O(n2)、n(n-1)/2 ∈O(n2)
Ω(渐近下界):
- 存在正常数 c 和 n0 使得对所有n ≥ n0有:f(n) ≥ cg(n),记为f(n) ∈ Ω(g(n))
- 例如:n3∈Ω (n2)、n(n+1)∈Ω (n2)、4n2+5 ∈Ω (n2)
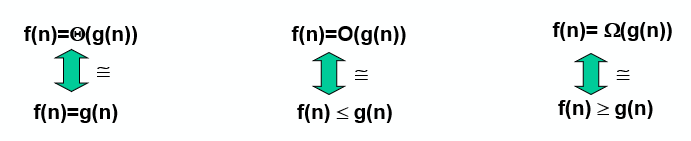
❷复杂度
时间复杂度具有「最差」、「平均」、「最佳」三种情况,分别使用 O , Θ , Ω 三种符号表示。
根据从小到大排列,常见的算法时间复杂度主要有:
O(1) < O(logn)<O(n)<O(nlogn)<O(n2)<O(n3)<O(2n)<O(n!)<O(nn)

❸渐进增长率比较
方法1:定义法
找到正常数 c 和 n0 使得对所有n ≥ n0 有 f(n) ≤ cg(n),则f(n) = O(g(n))
方法2:极限法
比较两个函数f(n)和g(n)的渐近增长率时,可以对两个函数相除,然后令变量 n 趋向于无穷,看这个极限值是无穷大还是一个大于零的常数还是趋向于0。

- 前两种情况意味着f(n) ∈ O(g(n))
- 后两种情况意味着f(n) ∈ Ω(g(n))
- 第二种情况意味着f(n) ∈ Θ(g(n))
方法3:取对数法
对于比较难的比较的两个函数,我们可以对它们同时取对数后再进行比较
常见对数公式:
logam*n = logam + logan
loga(m/n) = logam - logan
logamn = nlogam
logan√m = (1/n)logam
logab = logcb / logca
alogab = b
❹真题练习
➀题目1
判断 f(n) = 32n2 + 17n + 32 属于哪些渐近增长阶
O(n), Ω(n), Θ(n), O(n2), Θ(n2), Ω(n2),O(n3), Ω(n3), Θ(n3).
f(n) 属于 Ω(n),O(n2), Ω(n2), Θ(n2) ,O(n3)
f(n) 不属于 O(n), Θ(n), Ω(n3), Θ(n3)
➁题目2

f1(n) = √n + log100n = O(√n)
f2(n) = 2logn * 2loglogn = nlogn
f3(n) = 100logn + nlog3 = O(n)
f4(n) = O(3n)、f5(n) = 100log2n、f6(n) = O(n!)
(1)显然 f3(n) < f2(n) < f4(n)<f6(n)
(2)f5(n) 是对数的幂,f1(n) 是幂函数,因此 f5(n)< f1(n)
综上所述: f5(n) < f1(n)< f3(n) < f2(n) < f4(n)<f6(n)
➂题目3

f1(n) = nlognn 、f2(n) = logn、f3(n) = log5n
f4(n) = n1/5、f5(n) = n1/10log50n
(1)f2(n)< f3(n)
(2)f3(n)是对数的幂,f4(n) 是幂函数,因此 f3(n)< f4(n)
(3) lim f1(n)/ f4(n) = lim (n4/5lognn) = ∞ ,因此 f4(n) < f1(n)
lim f5(n)/ f4(n) = lim (n-1/10log50n) = 0 ,因此 f5(n) < f4(n)
(4)对f1(n)、f3(n)、f5(n)取对数
logf1(n) = logn + nloglogn = Θ(nloglogn) = O(n)
logf3(n) = 5loglogn = O(loglogn)
logf5(n) = (1/10)logn + 50loglogn = O(logn)
因此 f3(n) < f5(n) < f1(n)
综上所述: f2(n)< f3(n)< f5(n) < f4(n)< f1(n)
➃题目4

对f1(n)、f2(n)、f3(n)、f3(n)、f5(n)取对数
logf1(n) = nlog10 = O(n)
logf2(n) = 1/3logn = O(logn)
logf3(n) = nlogn = O(nlogn)
logf4(n) = loglogn = O(loglogn)
logf5(n) = √logn = O(√logn)
因此 f4(n)<f5(n)< f2(n)< f1(n) < f3(n)
➄题目5

f2(n) = 2logn*2loglogn = nlogn
lim f1(n)/ f2(n) = lim (log99n) = ∞ ,因此 f2(n) < f1(n)
lim f1(n)/ f3(n) = lim (log99.5n/n0.25) = 0 ,因此 f1(n) < f3(n)
lim f5(n)/ f3(n) = L = ∞ ,因此 f3(n) < f5(n)
lim f5(n)/ f4(n) = L = 0 ,因此 f5(n) < f4(n)
综上所述: f2(n)<f1(n)< f3(n)< f5(n) < f4(n)
➅题目6
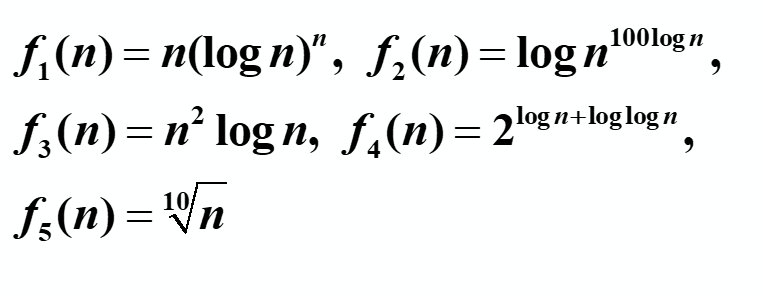
f1(n) = nlognn、f2(n) = 100log2n、f3(n) = n2logn、f4(n) = nlogn、f5(n) = n1/10
(1)显然 f4(n)<f1(n)
(2)f2(n)是对数的幂,f5(n) 是幂函数,因此 f2(n)< f5(n)
(3)lim f3(n)/ f5(n) = lim (n19/10logn) = ∞ ,因此 f5(n) < f3(n)
lim f1(n)/ f2(n) = lim (nlogn-2n/100) = ∞ ,因此 f2(n) < f1(n)
lim f2(n)/ f4(n) = lim (100logn/n) = 0 ,因此 f2(n) < f4(n)
lim f5(n)/ f4(n) = lim (100logn/n) = 0 ,因此 f5(n) < f4(n)
lim f3(n)/ f4(n) = lim (100logn/n) = ∞ ,因此 f4(n) < f3(n)
lim f1(n)/ f3(n) = lim ((logn-1n)/n) = ∞ ,因此 f3(n) < f1(n)
综上所述: f2(n) < f5(n) < f4(n)< f3(n)<f1(n)
③贪心算法
本章重点:
- 理解贪心算法的思想;
- 能判断一个算法是否为贪心算法;
- 掌握工作安排问题Interval scheduling的贪心算法及其正确性证明。
❶算法分析
贪心算法就是用计算机模拟一个「贪心的人」来做出决策。这个贪心的人是目光短浅的,他每次总是:
- 只做出当前看来最好的选择
- 只看眼前的利益,而不考虑做出选择后对未来造成的影响
- 并且他一旦做出了选择,就没有办法反悔(不可回溯)
总结:在对问题求解时,总是做出在当前最好的选择。也就是说并不从整体最优考虑,他所做出的是在某种意义上的局部最优解。 因此贪心算法不是对所有问题都能得到整体最优解。
应用场景
解决一个问题需要多个步骤,每一个步骤有多种选择。想清楚局部最优,想清楚全局最优,感觉局部最优是可以推出全局最优,并想不出反例,那么就试一试贪心。
解题步骤
贪心算法一般分为如下三步:
- 1.分解:将问题分解为若干个子问题
- 2.解决:找出适合的贪心策略,求解每一个子问题的最优解
- 3.合并:将局部最优解堆叠成全局最优解
❷正确性证明
贪心算法最难的部分不在于问题的求解,而在于正确性的证明,常用的证明方法有归纳法和反证法。
➀证明方法
- 先假设贪心算法得到的解不是最优解,假设 S1 是贪心算法得到的解,S2 是所有最优解中和 S1 具有最多相同元素的解;
- 然后比较 S1 和 S2,观察 S1 和 S2 中第一个(最前面一个)不一样的元素;
- 然后在解 S2 中将不一样的元素换成 S1 中的那个元素得到另一个最优解 S3,这样 S3 和 S1 比 S2 和 S1有更多相同元素,和假设 S2 是与 S1 有最多相同元素的最优解矛盾,这样来推导 S1 是最优解。
➁真题练习
有一堆货物需要被运走,现在有四种运货车:推车的容量最小,小货车的容量是推车容量的2倍,中货车的容量是两辆小货车的容量加上一辆推车的容量,大货车的容量是一辆中货车的容量加上一辆小货车的容量再加上两辆推车的容量。假设以上四种车的数量都非常多。现在要求你设计一种方案派出最少辆车将货物全搬走,其中除了推车以外其它三种车都必须装满才能发车。为这个问题设计一个算法,并证明该算法的正确性。 (8分)
参考答案:
贪心算法:
将车型按容量由大至小排列,能装满容量大的车就先装满发车,不行就考虑容量小一级的车。
证明:
设我们算法给出的结果为S1,即推车、小货车、中货车、大货车各a1,a2,a3,a4辆;S2 是所有最优解中和 S1 具有最多相同元素的解,即推车、小货车、中货车、大货车各b1,b2,b3,b4辆。假设 S1 和 S2 不一样,即 ai 和 bi 不一样。
如果i=4,则将 S2 中两个中货车(或者4个小货车)换成一个大货车和一个推车,或者一个中货车和两个小货车(或者。。。。)换成一个大货车。
如果i=3,则将 S2 中两个小货车和一个推车换成一个中货车;。。。
如果i=2,两个推车换成一个小货车。
通过如上变换得到另一个最优解 S3,这样 S3 和 S1 比 S2 和 S1有更多相同元素,和假设 S2 是与 S1 有最多相同元素的最优解矛盾,这样来推导 S1 是最优解。
❸区间调度(活动安排)
问题描述:设有 n 个活动的集合 E={1, 2, …, n},其中任意活动 i 都有一个起始时间 si 和一个结束时间 fi 。如果选择了活动 i,则它在半开时间区间 [si , fi) 内占用资源。若区间 [si , fi) 与区间 [sj , fj) 不相交,则称活动 i 与活动 j 是相容的。每个活动都要求使用同一资源,如演讲会场等,而在同一时间内只有一个活动能使用这一资源。活动安排问题就是要在所给的活动集合中选出最大的相容活动子集合。
➀理论分析
例如有如下 11 个活动,s[i] 代表第 i 个活动开始时间,f[i] 代表第 i 个活动的结束时间,选出最大的相容活动子集合
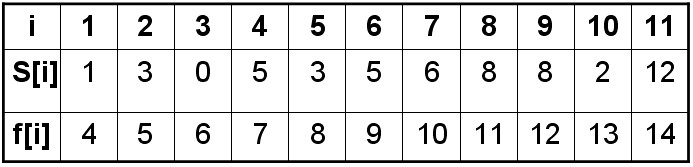
1、分析问题
本问题为选择尽可能多的相容活动
约束条件是下一个活动开始时间大于或等于上一个活动结束时间 s[i] >= f[j]
2、选择适合的贪心策略
可能的贪心选择策略:
- ①每次选择开始时间最早的活动
- ②每次选择持续时间最短的活动
- ③每次选择结束时间最早的活动
依次证明上面哪种思路可以应用于本题,为了方便,我们用不同颜色的线条代表每个活动,线条的长度就是活动所占据的时间段,蓝色的线条表示我们已经选择的活动;红色的线条表示我们没有选择的活动。
①每次选择开始时间最早的活动(不是最优解)

- 证明(反证法):
- 先来看开始最早,很容易找到反例,如图贪开始最早,那么选择蓝色的活动,显然不是最优解,因为选择红色的活动,可以参加2次,而蓝色活动只能参加一次
- 例如我们选择了10号活动(开始时间2点,结束时间13点);2号活动待选择(开始时间3点,结束时间5点);
则会出现上图所示的情况,这显然违背了约束条件。
②每次选择持续时间最短的活动(不是最优解)

- 证明(反证法):
- 贪持续时间最短,显然也不对,特殊情况发生在最短时间的活动,位置刚好和其他活动冲突,如果选择时间最短的活动,也不是最优解。
- 例如我们选择了2号活动(开始时间3点,结束时间5点);1号活动待选择(开始时间1点,结束时间4点);
则会出现上图所示的情况,这显然也违背了约束条件。
③每次选择结束时间最早的活动(最优解)
要证明一个算法是错的非常简单,要证明是对的却非常难。对于贪心算法的证明,一是使用归纳法,二是采用反证法。像上面两种策略,我们实际上就用到了反证法。那么怎么证明贪心算法是对的呢?
3、计算最优解
求解思路:将活动按照结束时间进行从小到大排序。挑选出结束时间尽量早的活动,并且满足后一个活动的起始时间晚于前一个活动的结束时间,全部找出这些活动就是最大的相容活动子集合。首先检查活动 i 是否与当前已选择的所有活动相容。若相容,活动 i 加入已选择活动的集合中,否则不选择活动 i,而继续检查下一活动与集合中活动的相容性。若活动 i 与之相容,则 i 成为最近加入集合 的活动,并取代活动 j 的位置。
图中每行相应于算法的一次迭代。阴影长条表示的活动是已选入集合A的活动,而空白长条表示的活动是当前正在检查相容性的活动。
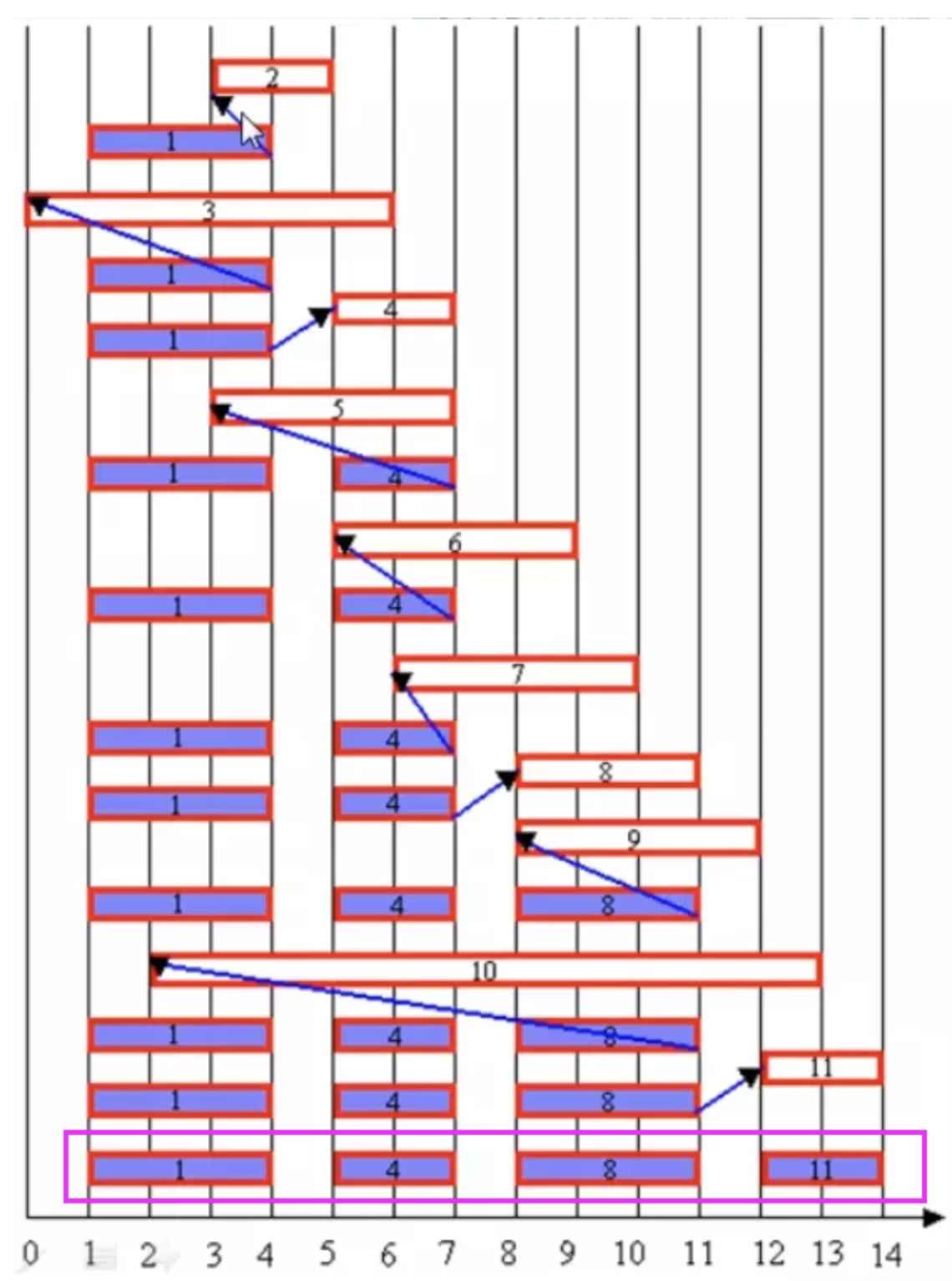
因此最大的相容活动子集合为{1,4,8,11}
➁代码实现
#include <iostream>
using namespace std;
void GreedyChoose(int len,int *s,int *f,bool *flag) {
flag[0] = true;
int j = 1;
for(int i=2;i<len;++i)
if (s[i] >= f[j]) {
flag[i] = true;
j = i;
}
else flag[i] = false;
}
int main(int argc, char* argv[]) {
int s[11] ={1,3,0,5,3,5,6,8,8,2,12};
int f[11] ={4,5,6,7,8,9,10,11,12,13,14};
bool mark[11] = {0};
GreedyChoose(11,s,f,mark);
for(int i=0;i<11;i++)
if (mark[i])
cout<<i+1<<" ";
//system("pause");
return 0;
}
其他经典贪心算法如下,等有空了再详细写吧!
找零钱的问题、单源最短路径中的Dijkstra算法、最小生成树的Prim算法、最小生成树的Kruskal算法、Huffman编码
❹真题练习
LC5.分发饼干
题目
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
输入: g = [1,2,3], s = [1,1]
输出: 1
解释:
你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
所以你应该输出1。
示例 2:
输入: g = [1,2], s = [1,2,3]
输出: 2
解释:
你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
你拥有的饼干数量和尺寸都足以让所有孩子满足。
所以你应该输出2.
提示:
- 1 <= g.length <= 3 * 104
- 0 <= s.length <= 3 * 104
- 1 <= g[i], s[j] <= 231 - 1
思路
为了了满足更多的小孩,就不要造成饼干尺寸的浪费。
这里的局部最优就是小饼干喂给胃口小的或者大饼干喂给胃口大的,充分利用饼干尺寸喂饱小孩,全局最优就是喂饱尽可能多的小孩。
可以尝试使用贪心策略,先将饼干数组和小孩数组排序。
然后从前向后或者从后向前遍历小孩数组,用小饼干满足胃口小的或者大饼干优先满足胃口大的,并统计满足小孩数量。
解答
// 优先考虑饼干,小饼干先喂饱小胃口
class Solution {
public int findContentChildren(int[] g, int[] s) {
Arrays.sort(g);
Arrays.sort(s);
int count = 0;
for(int i = 0, j = 0; i < g.length && j < s.length; j++){
if(g[i] <= s[j]){
count++;
i++;
}
}
return count;
}
}
// 优先考虑胃口,先喂饱大胃口
class Solution {
public int findContentChildren(int[] g, int[] s) {
Arrays.sort(g);
Arrays.sort(s);
int count = 0;
int j = s.length - 1;
// 遍历胃口
for (int i = g.length - 1; i >= 0; i--) {
if(j >= 0 && g[i] <= s[j]) {
count++;
j--;
}
}
return count;
}
}
④分治算法
本章重点:
- 理解分治算法的思想;
- 掌握Counting inversions问题的分治算法;
- 能用Master Theorem求解递归关系式
❶算法分析
分治算法的核心是分而治之,就是把一个复杂的问题分成多个相同/相似的子问题,递归地解决这些子问题然后进行合并,原问题的解即子问题解的合并。
分治法适用的情况
- 问题的规模缩小到一定的程度就可以容易地解决;
- 问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质;
- 问题分解出的子问题的解可以合并为问题的解;
- 问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
解题步骤
- 1.分解:将原问题分解为若干规模较小,相互独立,与原问题相同的子问题。
- 2.解决:若干子问题较小而容易被解决则直接解决,否则再继续分解为更小的子问题,直到容易解决。
- 3.合并:将已求解的各个子问题的解,逐步合并为原问题的解。
❷主定理
主定理适用于求解右边递归式算法的时间复杂度:T(n) = aT(n/b) + f(n)
其中:
- n:问题的规模大小
- a:原问题的子问题个数
- n/b:每个子问题的大小
- f(n):将原问题分解成子问题和将子问题的解合并成原问题的解的时间。
定理:设 a >= 1,b >=1 为常数,设 f(n) 为一函数,T(n) 由以下递归式给出 T(n) = aT(n/b) + f(n),则T(n)可能有如下渐近界:
①若 f(n) < nlogba 时,存在 ε > 0,有 f(n) = O(nlogba-ε),则 T(n) = Θ(nlogba)
②若 f(n) = nlogba 时,有 f(n) = Θ(nlogba),则 T(n) = Θ(nlogbalogn)
③若 f(n) > nlogba 时,存在 ε > 0,有 f(n) = Ω(nlogba+ε),且满足 af(n/b) ≤ cf(n), c<1,则 T(n) = Θ(f(n))
来几道例题,利用主定理求渐近表达式:
例一:求解递推方程 T(n) = 9T(n/3) + n
a = 9,b = 3 ,f(n) = n,nlogba = nlog39 = n2 > f(n)
存在 f(n) = O(nlogba-ε) = O(nlog39-6),ε = 6
满足主定理的条件1,因此 T(n) = Θ(nlogba) = Θ(n2)
例二:求解递推方程 T(n) = T(2n/3) + 1
a = 1,b = 3/2,f(n)=1,nlogba = nlog3/21 = n0 = 1 = f(n)
满足主定理的条件2,所以T(n) = Θ(nlogbalogn) = Θ(logn)
例三:求解递推方程 T(n) = 3T(n/4) + nlogn
a = 3,b = 4,f(n) = nlogn,nlogba = nlog43 < f(n)
再判断是否满足不等式:af(n/b) ≤ cf(n),代入f(n) = nlogn
(3n/4)log(n/4)和cnlogn,当 c ≥ 3/4 即可满足 af(n/b) ≤ cf(n) 的关系
即满足主定理的条件3,所以T(n) = Θ(f(n)) = Θ(nlogn)
❸计数逆序
问题描述:设 S 为一个有 n 个数字的有序集 ( n > 1 ),其中所有数字各不相同。如果存在正整数 i , j 使得 1 ≤ i < j ≤ n 并且 S [ i ] > S [ j ] ,则 (S [ i ] , S [ j ] ) 这个有序对称为 S 的一个逆序对,也称作逆序数。
分解:将 S 分为 A 和 B 两部分。
解决:递归计算A 、B、AB中的逆序数。
合并:返回三个计数的总和。

❹真题练习
➀题目1

(1) f(n) = 9f(n/6) + Θ(nlogn)
a = 9 , b = 6 , f(n) = Θ(nlogn), nlogba = nlog69 ,Θ(nlogn) < Θ(nlog69),
f(n) < Θ( nlogba),因此 f(n) = Θ(nlogba) = Θ(nlog69 )
(2) f(n) = 2f(n-3) + Θ(n)
f(n) - 2f(n -3) = n ①
2f(n -3) - 22f(n-6) = 2(n-3) ②
22f(n-6)- 23f(n-9) = 22(n-3) ③
……
2k-1f(n-3(k-1)) - 2kf(n-3k) = 2k-1(n-3(k-1)) 第k项
① + ② + ③ + … + 第k项 得:
f(n) - 2kf(n-3k) = n(20+21+22+…+2k-1) - 3(2+2*22+3*23+…+(k-1)*2k-1)
= -n*(1-2k) - 3*(2k(k-2)+2)
= (2k-1)*n -3*2k(k-2) - 6
⇒ f(n) = (2k-1)*n -3*2k(k-2) - 6 + 2kf(n-3k)
令 k = n/3 则:⇒ f(n) = n*2n/3 - n - n*2n/3 + 6*2n/3 - 6 + 2n/3
⇒ f(n) = 7*2n/3 - n - 6
因此 f(n) =Θ(2n/3)
(3) f(n) = 4f(n/2) + Θ(n2)
a = 4 ,b = 2 ,f(n) = Θ(n2),nlogba = nlog24 = 2
f(n) = Θ( nlogba ),因此 f(n) = Θ(nlogbalogn) = Θ(n2logn)
➁题目2
一个数的序列中排在前面的数比排在后面的数要大的话则称为一对逆序。问下面这个序列中存在多少对逆序:5,10,7,9,13,1,8,4,12,2,6,3,11,14。(4分)
答:4+8+5+6+8+0+4+2+4+0+1+0+0=42
⑤动态规划
本章重点:
- 理解动态规划算法的思想。
- 对相应问题能建立基本的递归关系式并用从底至上的方法来求解,在求解过程中知道如何建立数据储存的表格。
- 重点掌握的问题:带权重的活动安排问题、0-1背包问题、最长公共子序列问题、矩阵连乘的最优计算次序问题。
- 理解0-1背包问题的动态规划算法不是多项式时间算法。
❶算法分析
动态规划问题分析是自顶而下的思路,但是算法实现却是自底而上的策略。
动态规划与分治法类似,都是把大问题拆分成小问题,通过寻找大问题与小问题的递推关系,解决一个个小问题,最终达到解决原问题的效果。
但不同的是,分治法在子问题和子子问题等上被重复计算了很多次,而动态规划则具有记忆性,通过填写表把所有已经解决的子问题答案纪录下来,在新问题里需要用到的子问题可以直接提取,避免了重复计算,从而节约了时间,所以在问题满足最优性原理之后,用动态规划解决问题的核心就在于填表,表填写完毕,最优解也就找到。
❷带权区间调度
问题描述:给定若干个工作 job 的开始时间 **sj**、结束时间 fj 和权重 vj(可以理解成重要程度),求出能完成的最大的工作权重(尽可能地完成更重要的工作),且必须满足各个工作相容(工作安排的时间没有重叠)。
例如有如下三个工作:
job s f v 工作1 0 3 4 工作2 5 6 5 工作3 2 8 10 由不带权重的区间调度方法(贪心),按最早结束时间且相容选择工作,这里就选出{工作1, 工作2},能实现的最大权重是4+5=9。但是,选择{工作3}权重可达到10,因此最早结束时间的贪心策略在带权区间调度问题里已不适用。那么如何求相互兼容工作的最大权值子集呢?
➀理论分析
1、分析最优子结构
- 工作 job 按照完成时间升序排列:f1≤f2≤…≤ fn
- 定义两个参数:
p(j)、OPT(j)
p(j) = 与工作 j 相容的最大的工作 i 且 i < j,也就是说 i 是 j 左边的在 j 开始之前结束的区间。
如下图:
p(1) = 0,p(2) = 0,p(3) = 0,p(4) = 1
p(5) = 0,p(6) = 2,p(7) = 3,p(8) = 1
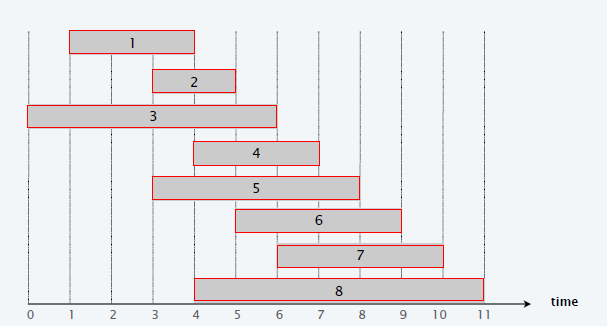
OPT(j)表示前 j 个工作 ( 1,2,3,…,j )的最大的工作权重。
OPT(j) 显然有两种方案:
- ①选择 j 工作
- 如果选择工作 j,原问题退化成 **vj+OPT(P(j))**,选择了 j 活动,则下一个活动为不能和 j 活动冲突的最大活动 P(j)
- ②不选择 j 工作
- 如果不选择工作 j,原问题退化成 **OPT(j-1)**,即从(1,2,3…j-1)中找最优解
2、建立递推公式
递推公式如下: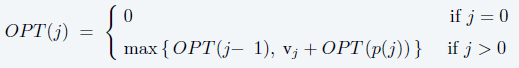
3、计算最优值、构造最优解
例如:给定如下8个候选活动的开始时间、结束时间和权重

依据递推公式,计算出 p(j)、OPT(j)
| j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| p(j) | 0 | 0 | 0 | 1 | 0 | 2 | 3 | 5 |
| OPT(j) | 12 | 20 | 23 | 25 | 26 | 40 | 40 | 42 |
p(8) = 5,与 活动8 相容的最大活动为 5
p(5) = 0,与 活动5 相容最大活动没有
因此选择活动 8 和 5
OPT(2) = max{ OPT(1) ,v2 + OPT(p(2)) } = max{12,20} = 20
OPT(4) = max{ OPT(3) ,v4 + OPT(p(4)) } = v4 + OPT(1) = 13 + 12 = 25
OPT(7) = max{ OPT(6) ,v7 + OPT(p(7)) } = max{40,34} = 40
OPT(8) = max{ OPT(7) ,v8 + OPT(p(8)) } = max{40,42} = 42
因此最大权重之和为42
➁代码实现
#include <iostream>
using namespace std;
typedef struct {
int iStartT;
int iFinshT;
int iWight;
}TASK_INFO;
void CreatWeightedScheduling(TASK_INFO *, int); //创建每个任务
void PrintWeightedScheduling(TASK_INFO *, int);
void DynamicScheduling(TASK_INFO *, int **, int); //用动态算法求解最大权重问题
void FindSolution(TASK_INFO *, int **, int, int *); //寻求最大权重任务的集合
void CreatWeightedScheduling(TASK_INFO *schedule, int taskNum)
{
cout << "请逐个输入任务的开始时间s、结束时间f、权重v\n";
for (unsigned int i = 0; i < taskNum; i++)
{
cout << "Task " << i + 1 << " information: ";
cin >> schedule[i].iStartT >> schedule[i].iFinshT >> schedule[i].iWight;
}
}
void PrintWeightedScheduling(TASK_INFO *schedule, int taskNum)
{
for (unsigned int i = 0; i < taskNum; i++)
{
cout << "Task" << i + 1 << ":\t" << schedule[i].iStartT << "\t" << schedule[i].iFinshT << "\t" << schedule[i].iWight << endl;
}
}
/**
** key: j号task的开始时间,即startArray[j]
** finsh[] && currentIndex: 查找“j号task的开始时间”在j-1号之前的任务的结束时间finishArray[1...j-1]
**/
int binarySereach(int key, int finsh[], int currentIndex)
{
int low = 1, high = currentIndex;
while (low <= high) {
int mid = (low + high) / 2;
if (key == finsh[mid]) //找到即返回Index
return mid;
else if (key < finsh[mid]) { //key小于所有的finshTime,即没有一个任务相容
high = mid - 1;
if (high < low)
return 0;
}
else { //key大于所有的finshTime,最大的相容的,即high
low = mid + 1;
if (low > high)
return high;
}
}
return 0;
}
void DynamicScheduling(TASK_INFO *schedule, int **compute, int taskNum)
{
int* startArray = new int[taskNum + 1]; //将每个任务的开始、结束时间转存下,方便计算P(j)
int* finishArray = new int[taskNum + 1];
for (unsigned int i = 1; i < taskNum + 1; i++)
{
startArray[i] = schedule[i - 1].iStartT;
finishArray[i] = schedule[i - 1].iFinshT;
}
//compute P(j) & OPT(j)
for (unsigned int j = 1; j < taskNum + 1; j++) {
//P(j)
compute[0][j] = binarySereach(startArray[j], finishArray, j - 1);
//OPT(j):OPT(j) ? Wj+OPT(P(j))
if (compute[1][j - 1] > schedule[j - 1].iWight + compute[1][compute[0][j]]) //第一个任务信息在0号内存单元的,所以是j-1
compute[1][j] = compute[1][j - 1];
else
compute[1][j] = schedule[j - 1].iWight + compute[1][compute[0][j]];
}
delete[] startArray; //从理论上讲,new的内存必需要delete才能释放,不知道编译器有优化没?,还是显示的释放下
delete[] finishArray;
}
int g_i = 0;
void FindSolution(TASK_INFO *schedule, int **compute, int j, int* path)
{
if (j == 0)
return;
else if (schedule[j - 1].iWight + compute[1][compute[0][j]] > compute[1][j - 1]) //后面值大于前面的,则加入;否则j-1
{
path[g_i++] = j;
return FindSolution(schedule, compute, compute[0][j], path);
}
else
return FindSolution(schedule, compute, j - 1, path);
}
int main()
{
int taskNum = 0;
cout << "请输入你要分配总任务数: ";
cin >> taskNum;
TASK_INFO *schedule = new TASK_INFO[taskNum];
CreatWeightedScheduling(schedule, taskNum);
//用动态算法求解最大权重问题
//compute[2][]:first clow means P(j); second clow means OPT(j)
int **compute = new int*[taskNum + 1];
for (unsigned int i = 0; i < 2; i++) //分配内存及置0
compute[i] = new int[taskNum + 1];
for (unsigned int i = 0; i < 2; i++)
for (unsigned int j = 0; j < taskNum + 1; j++)
compute[i][j] = 0;
DynamicScheduling(schedule, compute, taskNum);
cout << "\n";
for (unsigned int i = 0; i < 2; i++) { //输出P(j)、OPT(j)
if (i == 0)
cout << " P(j): ";
else
cout << "OPT(j): ";
for (unsigned int j = 1; j < taskNum + 1; j++)
cout << compute[i][j] << "\t";
cout << "\n";
}
cout << "\n最大权重之和:" << compute[1][taskNum] << endl;
//输出任务
int* path = new int[taskNum]; //存储任务的数组
for (int i = 0; i < taskNum; ++i)
path[i] = 0;
FindSolution(schedule, compute, taskNum, path);
cout << "最优活动子集:";
for (unsigned int i = 0; i < taskNum && path[i] != 0; i++)
cout << path[i] << " ";
cout << "\n";
//PrintWeightedScheduling(schedule, taskNum);
for (unsigned int i = 0; i < 2; i++)
{
delete[] compute[i];
}
delete[] compute;
delete[] schedule;
delete[] path;
}

➂真题练习
题目1

设 p(j) 为与工作 j 相容的最大的工作 i 且 i < j 。OPT(j)表示前 j 个工作 ( 1,2,3,…,j )的最大的工作权重。则递归关系式为:

依据递推公式,计算出 p(j)、OPT(j)

因为 OPT(17) = 50 ,因此最大权重之和为 50
OPT(17) = OPT(16) = OPT(15) = 50 ,选择活动 15,p(15) =13;
OPT(13) = OPT(12) = 45 ,选择活动 12,p(12) = 7;
OPT(7) = OPT(6) = 25 ,选择活动 6,p(6) = 3;
OPT(3) = 18 ,p(3) = 0,选择活动 3,且选择完毕。
因此最优活动子集为 3、6、12、15
❸0-1背包问题
问题描述:有n个物品,它们有各自的重量 wi 和价值 vi ,现有给定容量为 C 的背包,如何让背包里装入的物品具有最大的价值总和?
➀理论分析
1、分析最优子结构
定义一个参数:OPT(i,w)
OPT(i,w)表示表示前 i 个物品 ( 1,2,3,…,i )的最大价值,i(当前背包存放物品的数量)、w(当前背包容量)
OPT(i,w) 显然有两种方案:
- ①不选择 i 物品
- 如果不选择 i 物品,原问题退化成 **OPT(i-1,w)**,即包的剩余容量比 i 物品重量小,装不下,此时的价值与前 i-1 个的价值是一样的,从(1,2,3…i-1)中找最优解
- ②选择 i 物品
- 如果选择 i 物品,原问题退化成 **vi + OPT(i-1,w-wi)**,即既然选择了 i 物品,能装的重量减少 wi,并尝试 i-1 是否装入
2、建立递推公式
递推公式如下:
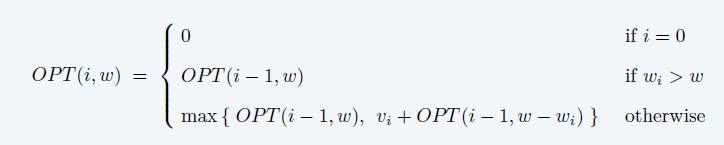
3、计算最优值、构造最优解
例如:给定如下 5 个物品的价值 vi 和重量 wi,限制包的容量 C 为11
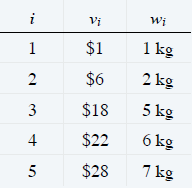
依据递推公式,计算出OPT(i,w)
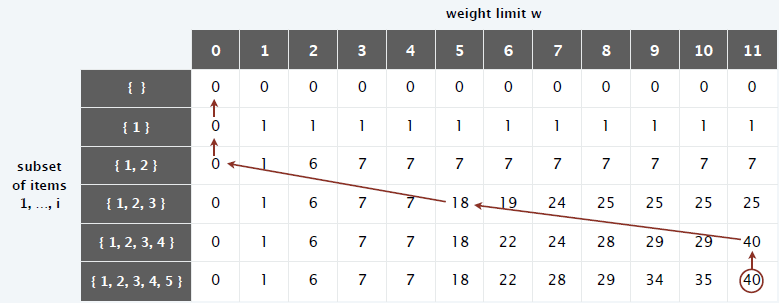
OPT(2,2) = max{ v2 + OPT(1,2-w2),OPT(1,2)} = max{6,1} = 6
…
OPT(3,5) = max{ v3 + OPT(2,5-w3),OPT(2,5)} = max{18,7} = 18
OPT(4,11) = max{ v4 + OPT(3,11-w4),OPT(3,11)} = max{40,25} = 40
OPT(5,11) = max{ v5 + OPT(4,11-w5),OPT(4,11)} = max{35,40} = 40
因此最大价值为 40,由图中红线回溯可知,背包装了物品 3 和 4
➁代码实现
#include <iostream>
#include <iomanip> //setw()函数
using namespace std;
typedef struct ITEM {
int wight; //单个物品的重量
int value; //单个物品的价值
}ITEM_INFO;
void creatItemInfo(ITEM_INFO *items, int itemNum)//创建背包物品基本信息
{
cout << "请输入(value weigh),例如(1 1)" << endl;
for (unsigned int i = 0; i < itemNum; i++)
{
cout << "Enter item " << i + 1 << " information: ";
cin >> items[i].value >> items[i].wight;
}
}
void PrintItemInfo(ITEM_INFO *items, int itemNum)
{
for (unsigned int i = 0; i < itemNum; i++)
{
cout << "Item" << i + 1 << ":\t" << items[i].value << "\t" << items[i].wight << "\t" << endl;
}
}
void DynamicKnapsack(ITEM_INFO *items, int** m, int maxWeight, int itemNum)//用动态规划解决0/1背包问题
{
//其实首先是将m[0, ],第一行清零,由于之前全清零了,所以就没做这步了
for (unsigned int i = 1; i <= itemNum; i++) //i:物品的数量,从1到itemNum
{
for (unsigned int w = 0; w <= maxWeight; w++) //w:背包的当前重量,最开始没有物品为0,慢慢增加到maxWeight
{
//分两种情况,(1)i号物品不放入背包;(2 else)i号物品放入背包
if (items[i - 1].wight > w) {
m[i][w] = m[i - 1][w];
}
else {
//OPT(i,w) <== OPT(i-1, w) ? Vi+OPT(i-1, w-wi)
if (m[i - 1][w] > items[i - 1].value + m[i - 1][w - items[i - 1].wight])
m[i][w] = m[i - 1][w];
else
m[i][w] = items[i - 1].value + m[i - 1][w - items[i - 1].wight];
}
}
}
}
int g_i = 0; //返回活动j存在path中
void FindSolution(ITEM_INFO *items, int** m, int i, int w, int* path)//回溯求解问题的解
{
if (i == 0 || w == 0)
return;
else if (m[i - 1][w] < items[i - 1].value + m[i - 1][w - items[i - 1].wight]) //当w=0,不能执行这里了,重量已经0,还减少?越界,所以不加m==0判断,下面执行出错误
{
//i物品选中,迭代时候数量i减一,背包能容量的重量减wi
path[g_i++] = i;
return FindSolution(items, m, i - 1, w - items[i - 1].wight, path); //这里是items[i - 1],因为第一个物品信息存放在0号内存单元的
}
else
//i物品没选中,迭代时候数量i减一即可
return FindSolution(items, m, i - 1, w, path);
}
int main()
{
int itemNum = 0; //物品的数量
int maxWeight = 0; //背包最大能放的重量
cout << "物品个数:";
cin >> itemNum;
cout << "背包容量:";
cin >> maxWeight;
ITEM_INFO *items = new ITEM_INFO[itemNum];
creatItemInfo(items, itemNum);
//PrintItemInfo(items, itemNum);
//其实m[][]是(itemNum+1)*(maxWeight+1),要多一行一列
int **m = new int*[maxWeight+1];
for (unsigned int i = 0; i < itemNum+1; i++)
m[i] = new int[maxWeight + 1];
for (unsigned int i = 0; i < itemNum+1; i++)
for (unsigned int j = 0; j < maxWeight +1; j++)
m[i][j] = 0;
DynamicKnapsack(items, m, maxWeight, itemNum);
cout << "\nm[][]:\n";
for (unsigned int i = 0; i <= itemNum; i++)
{
for (unsigned int j = 0; j <= maxWeight; j++)
cout << m[i][j] << setw(6);
cout << "\n";
}
int* path = new int[itemNum]; //存储任务的数组
for (int i = 0; i < itemNum; ++i)
path[i] = 0;
FindSolution(items, m, itemNum, maxWeight, path);
cout << "\n最大权重物品:";
for (unsigned int i = 0; i < itemNum && path[i] != 0; i++)
cout << path[i] << " ";
//释放内存
for (unsigned int i = 0; i < itemNum; i++)
delete[] m[i];
delete[] m;
delete[] items;
delete[] path;
return 0;
}

➂01背包是NP
理解0-1背包问题的动态规划算法不是多项式时间算法。
P 是否等于 NP 是计算复杂度理论里面最著名的未解决的问题之一,一个 NP 完全问题,如果能找到解决它的多项式时间算法,那么就说明了 P = NP。
如今 0-1 背包问题已经被证明是 NP 完全问题,而它却有着一个动态规划解法,该解法有着 O(n*W) 的时间复杂度,其中 n 是物品的个数,W 是背包限制的最大负重。所以时间复杂度对输入 n,W 来说是多项式时间的,所以说明了 NP = P 是不是哪里出错了呢?
其实多项式时间是相对于输入规模来说的,输入规模最直观的理解就是输入到该算法的数据占了多少比特内存。0-1 背包的输入有 n 个物品的价值,n 个物品的重量,还有背包的最大负重 W。如今假设 W 占用的比特数为 L(也就是说背包的最大负重的输入规模是 L),那么 log(W) = L,所以 O(n*W) = O(n*2L),由此看到,该算法的时间复杂度对于输入规模 L 来说是指数级别的,随着输入规模 L 的增加,运算时间会迅速增长。
实际上,人们把这种动态规划的算法称为伪多项式时间算法(pseudo-polynomial time algorithm),这种算法不能真正意义上实现多项式时间内解决问题。
➃真题练习
题目1

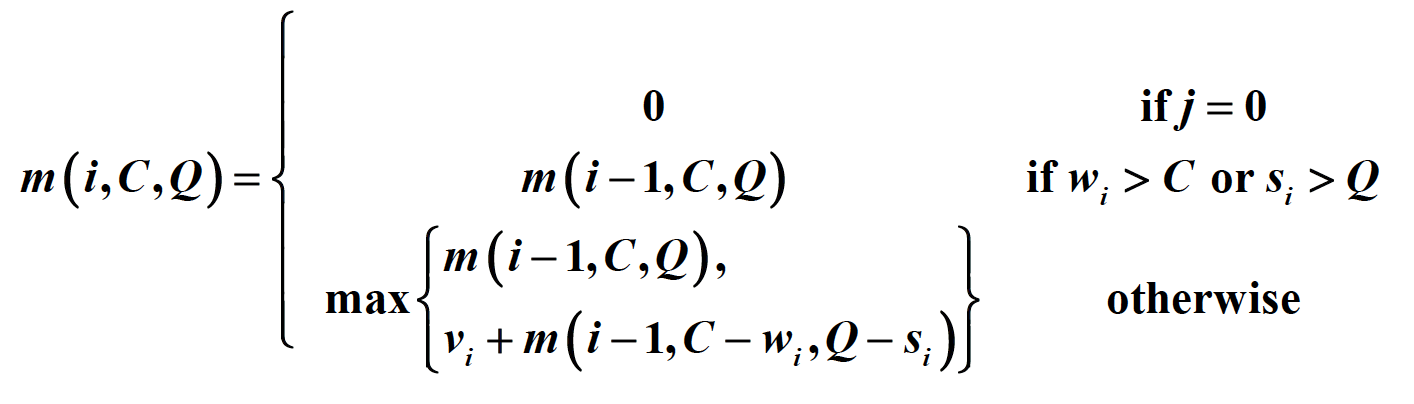
题目2
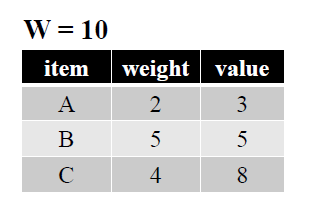
❹最长公共子序列
问题描述︰给定两个字符串,求解这两个字符串的最长公共子序列(LCS)。如: X={1,5,2,8,9,3,6},Y={5,6,8,9,3,7},其最长公共子序列为{5,8,9,3},最长公共子序列长度为4。那么如何求解呢?
➀理论分析
1、分析最优子结构
设序列 X={x1, x2, …, xi} 和 Y={y1, y2, …, yj} 的最长公共子序列为 **Z={z1, z2, …, zk}**,则
①若 xi=yj ,则 zk=xi=yj 且 Zk-1 是 Xi-1 和 Yj-1 的最长公共子序列;
②若 xi≠yj 且 zk≠xi ,则 Zk 是 Xi-1 和 Yj 的最长公共子序列;.
③若 xi≠yj 且 zk≠yj ,则 **Zk **是 Xi 和 Yj-1 的最长公共子序列。
2、建立递推公式
用**c[i][j]**表示 Xi={x1, x2, …, xi} 和 Yj={y1, y2, …, yj} 的最长公共子序列的长度,那么得到以下的递推公式:
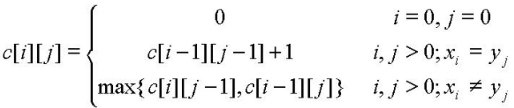
递推公式代码版:
int[][] c = new int[m + 1][n + 1];
for(int i = 0; i <= n; i++){
for(int j = 0; j <= m; j++){
c[i][0] = 0;
c[0][j] = 0;
}
}
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++){
if(X[i] == Y[j]){
c[i][j] = c[i-1][j-1] + 1;
}
else{
c[i][j] = max(c[i - 1][j], c[i][j - 1]);
}
}
}
3、计算最优值
假设 X={A,B,C,E} 和 Y={B,D,C,E}
根据上方递推公式得到下表:
c[i][j] |
0 | 1B | 2D | 3C | 4E |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 1A | 0 | 0 | 0 | 0 | 0 |
| 2B | 0 | 1 | 1 | 1 | 1 |
| 3C | 0 | 1 | 1 | 2 | 2 |
| 4E | 0 | 1 | 1 | 2 | 3 |
在 C[2][0] 处,j = 0 ,此时根据公式C[2][0]= 0
在 C[2][1] 处,B = B,即 xi=yj ,此时根据公式C[2][1]=C[1][0]+1=0+1=1
在 C[2][2] 处,B ≠ C,即 xi≠yj ,此时根据公式C[2][2]=max{C[2][1],C[1][2]}=1
根据最右下角的值(c[][]),我们可以知道最长公共子序列长度为3。
最优值代码版:
int LCSLength(char *X,char *Y){
for(int i = 0; i <= n; i++){
for(int j = 0; j <= m; j++){
c[i][0] = 0;
c[0][j] = 0;
}
}
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++){
if(X[i] == Y[j]){
c[i][j] = c[i-1][j-1] + 1;
}
else{
c[i][j] = max(c[i - 1][j], c[i][j - 1]);
}
}
return c[n][m];
}
4、构造最优解
b[i][j]记录c[i][j]的值是由哪个子问题的解得到的
if(X[i]==Y[j])用b=1代表if(X[i]!=Y[j])用b=2代表
b[i][j] |
0 | 1B | 2D | 3C | 4E |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 1A | 0 | 2 | 2 | 2 | 2 |
| 2B | 0 | 1 | 2 | 2 | 2 |
| 3C | 0 | 2 | 2 | 1 | 2 |
| 4E | 0 | 2 | 2 | 2 | 1 |
c[i][j] |
0 | 1B | 2D | 3C | 4E |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 1A | 0 | 0 | 0 | 0 | 0 |
| 2B | 0 | 1↖ |
1← |
1 | 1 |
| 3C | 0 | 1 | 1 | 2↖ |
2 |
| 4E | 0 | 1 | 1 | 2 | 3↖ |
↖处则为最长公共子序列{B,C,E}
➁代码实现
//自底向上计算最优值,并记录相关信息
void LCSLength(){
int i,j;
for(i=1; i<=m; i++){
c[i][0] = 0;
}
for(i=1; i<=n;i++){
c[0][i] = 0;
}
for(i=1; i<=m; i++){
for(j=1; j<=n; j++){
if(x[i] == y[j]){
c[i][j] = c[i-1][j-1] + 1;
b[i][j] = 1;
}else if(){
c[i][j] = c[i-1][j];
b[i][j] = 3;
}else{
c[i][j] = c[i][j-1];
b[i][j] = 2;
}
}
}
}
void LCS(int i,int j,char *x,int **b){
if(i == 0 || j == 0){
return;
}
if(b[i][j] == 1){
LCS(i-1,j-1,x,b);
cout<➂真题练习
题目1
给定两个字符串A和B,长度分别为m和n,设计动态规划算法找出它们最长公共子序列长度,并给出最长公共子序列。例如:A = “HelloWorld”,B = “loopbird”,则A与B的最长公共子序列为”loord”,返回的长度为5。
题目2
设计一个 O(n2) 时间的算法,找出由 n 个数组成的序列的最长单调递增子序列(LIS)。
解法一:转化成 LCS 问题求解,时间复杂度为 O(n*n).
思路:原序列为 A,把 A 按升序排序得到序列 B,求出 A,B 序列的最长公共子序列,即为 A 的最长单调递增子序列。
解法二:设 d[i] 为以第 i 个元素结尾的最长递增子序列的长度,
则 d(i) = max(d(j)) + 1; ( j<i && a[j] < a[i] ) , 时间复杂度O(n*n)
❺矩阵连乘
➀理论分析
问题描述:给定 n 个矩阵 {A1,A2,…,An} ,其中 Ai 与 Ai+1 是可乘的,用加括号的方法表示矩阵连乘的次序,不同加括号的方法所对应的计算次序是不同的,求矩阵连乘的最佳计算次序。
例如,矩阵连乘积 A1A2A3 有以下 2 种加括号方式:A1(A2A3),(A1A2)A3,所以那种加括号方式是最优的呢?
说明:
- 1.矩阵 A 和矩阵 B 可乘的条件:
矩阵 A 的列数 = 矩阵 B 的行数- 2.设矩阵 A 是 p × q 的矩阵,B 是 q × r 的矩阵,
乘积结果 C 是 p × r的矩阵,计算量是 p * q * r
1、分析最优子结构
将矩阵连乘的积 Ai Ai+1 … Aj 简记为A[i][j] ,Ai 的维度记为 **pi-1 × pi**,那么上述问题变为求解 A[1][n]的最佳计算次序。
A[1][n]的最佳计算次序:设这个计算次序在矩阵 AK (1≤k<n) 和 AK+1 之间将矩阵链断开,则相应的加括号方式:( Ai Ai+1 … Ak )( Ak+1Ai+1 … An ),依此计算顺序,总计算量为 Ai Ai+1 … Ak 的计算量加上 Ak+1Ai+1 … An 的计算量,再加上 ( Ai Ai+1 … Ak ) 和 ( Ak+1Ai+1 … An )相乘的计算量。即 A[1][n] = A[1][k] + A[k+1][n] + pi-1pkpn
2、建立递推公式
设计算 A[i][j] (i≤j) 所需的最少乘法次数为 m[i][j],那么得到以下的递推公式:
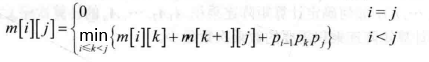
3、计算最优值
例如,要计算矩阵连乘积A1A2A3A4A5A6,其中各矩阵的维数分别为:
| A1 | A2 | A3 | A4 | A5 | A6 |
|---|---|---|---|---|---|
| 30x35 | 35x15 | 15x5 | 5x10 | 10x20 | 20x25 |
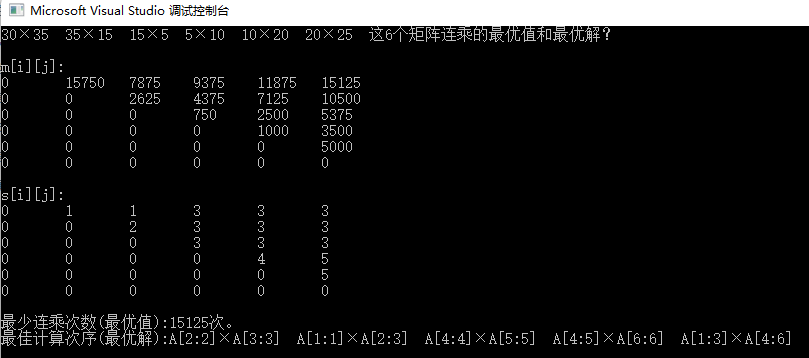
依据递推公式,按照图 a 的次序,计算出 m[i][j]


★最优值:本题是求解 A[1][6] 的最佳计算次序,即求m[1][6] 。由图 b 可知, m[1][6] =15125,因此矩阵连乘积A1A2A3A4A5A6 的最优值为 15125
4、构造最优解
若将对应m[i][j]的断开位置k记为s[i][j],计算出最优值m[i][j]后,可递归地由s[i][j][][]构造出相应的最优解。

例如,m[2][5] = m[2][3] + m[4][5] + p1p3p5 ,则 k = 3,因此 s[2][5] = 3
★最优解:
s[1][6] = 3 ,因此矩阵链在A3和A4之间断开,则加括号方式为 (A1A2A3)(A4A5A6 )
s[1][3] = 1,因此矩阵链在A1和A2之间断开,则加括号方式为 (A1(A2A3))(A4A5A6 )
s[4][6] = 5,因此矩阵链在A5和A6之间断开,则加括号方式为 (A1(A2A3))((A4A5)A6 )
因此最优解为 (A1(A2A3))((A4A5)A6 )
➁代码实现
#include <iostream>
using namespace std;
#define N 100
int s[N][N], m[N][N]; //s存储切割位置,m存储最优值
void MatricChain(int *p , int n) {//p矩阵维数数组,n为矩阵个数
for (int i = 1; i <= n; i++) {//初始化,对角线上的计算量和加括号的位置为0
m[i][i] = 0;
s[i][i] = 0;
}
for (int r = 2; r <= n; r++) {//r为矩阵链的长度
for (int i = 1; i <= n - r + 1; i++) { //i为首矩阵的序号
int j = i + r - 1; //j为尾矩阵的序号
m[i][j] = m[i][i] + m[i + 1][j] + p[i - 1] * p[i] * p[j];//首先尝试在矩阵 i 处分开
s[i][j] = i;
for (int k = i + 1; k < j; k++) {
int t = m[i][k] + m[k + 1][j] + p[i - 1] * p[k] * p[j]; // 然后尝试在矩阵 k 处分开 (i<=k<j)
if (t < m[i][j]) {
m[i][j] = t;
s[i][j] = k;
}
}
}
}
}
void Traceback(int i, int j) {
if (i == j) {
return;
}
int k = s[i][j];
Traceback(i, k);
Traceback(k + 1, j);
cout << "A" << "[" << i << ":" << k << "]" << "×" << "A""[" << (k + 1) << ":" << j << "]"<<" " ;
}
int main(){
int p[] = {30,35,15,5,10,20,25};//矩阵维数
int n = sizeof(p) / sizeof(int) - 1;//矩阵个数
for(int i = 0; i < n; i++){
cout << p[i]<<"×"<<p[i+1]<<" ";
}
cout << "这" << n << "个矩阵连乘的最优值和最优解?" << endl;
cout << endl;
MatricChain(p,n);
cout << "m[i][j]:" << endl;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++)
cout << m[i][j] << "\t";
cout << endl;
}
cout << endl;
cout << "s[i][j]:" << endl;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++)
cout << s[i][j] << "\t";
cout << endl;
}
cout << endl;
cout << "最少连乘次数(最优值):" << m[1][n] << "次。" << endl;
cout << "最佳计算次序(最优解):" ;
Traceback(1, n);
cout << endl;
}
➂真题练习
题目1

(1)令计算**A1 x A2 x A3 x … x An*所需要的最少乘法次数为m*[i, j] (3分)
则递归关系式为 (5分,其中边界条件1分)
(5分,其中边界条件1分)
(2)
| m(i, j) | j = 1 | j = 2 | j = 3 | j = 4 | j = 5 |
|---|---|---|---|---|---|
| i = 1 | 0 | 1440 | 3360 | 4000 | 5856 |
| i = 2 | / | 0 | 2400 | 2800 | 4800 |
| i = 3 | / | / | 0 | 1600 | 2880 |
| i = 4 | / | / | / | 0 | 3200 |
| i = 5 | / | / | / | / | 0 |
将对应m(i,j)的断开位置k记为s(i,j)
| s(i, j) | j = 1 | j = 2 | j = 3 | j = 4 | j = 5 |
|---|---|---|---|---|---|
| i = 1 | / | 1 | 2 | 2 | 2 |
| i = 2 | / | / | 2 | 2 | 2 |
| i = 3 | / | / | / | 3 | 4 |
| i = 4 | / | / | / | / | 4 |
| i = 5 | / | / | / | / | / |
s(1,5) = 2 因此矩阵链在A2和A3之间断开,则加括号方式为 (A1A2)(A3A4A5)
s(3,5) = 4 因此矩阵链在A4和A5之间断开,则加括号方式为 (A1A2)((A3A4)A5)
最优加括号方式为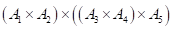
题目2
| A1 | A2 | A3 | A4 | A5 |
|---|---|---|---|---|
| 3x7 | 7x8 | 8x5 | 5x12 | 12x10 |
计算矩阵连乘积A1A2A3A4A5最优值和最优解?
| m[i][j] | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | 0 | 168 | 288 | 468 | 828 |
| 2 | 0 | 280 | 700 | 1230 | |
| 3 | 0 | 480 | 1000 | ||
| 4 | 0 | 600 | |||
| 5 | 0 |
| s[i][j] | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | 0 | 1 | 2 |
3 |
4 |
| 2 | 0 | 2 | 3 | 3 | |
| 3 | 0 | 3 | 3 | ||
| 4 | 0 | 4 | |||
| 5 | 0 |
最少乘法次数为(最优值):828
s[1][5] = 4 因此矩阵链在A4和A5之间断开,则加括号方式为 (A1A2A3A4)A5
s[1][4] = 3 因此矩阵链在A3和A4之间断开,则加括号方式为 ((A1A2A3)A4)A5
s[1][3] = 2 因此矩阵链在A2和A3之间断开,则加括号方式为 (((A1A2)A3)A4)A5
最优加括号方式为(最优解): (((A1A2)A3)A4)A5
❻真题练习
题目1
题目:LC746. 使用最小花费爬楼梯
数组的每个下标作为一个阶梯,第 i 个阶梯对应着一个非负数的体力花费值 cost[i](下标从 0 开始)。每当你爬上一个阶梯你都要花费对应的体力值,一旦支付了相应的体力值,你就可以选择向上爬一个阶梯或者爬两个阶梯。请你找出达到楼层顶部的最低花费。在开始时,你可以选择从下标为 0 或 1 的元素作为初始阶梯。
示例 1:
输入:cost = [10, 15, 20]
输出:15
解释:最低花费是从 cost[1] 开始,然后走两步即可到阶梯顶,一共花费 15 。
示例 2:
输入:cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1]
输出:6
解释:最低花费方式是从 cost[0] 开始,逐个经过那些 1 ,跳过 cost[3] ,一共花费 6 。
思路
创建长度为 n + 1 的数组 dp,其中 dp[i] 表示达到下标 i 的最小花费。
由于可以选择下标 0 或 1 作为初始阶梯,因此有 dp[0] = dp[1] = 0
当 2 ≤ i ≤ n 时,可以从下标 i−1 使用 cost[i−1] 的花费达到下标 i,或者从下标 i−2
使用 cost[i−2] 的花费达到下标 i。为了使总花费最小,dp[i] 应取上述两项的最小
值,因此状态转移方程如下:
dp[i]=min(dp[i−1]+cost[i−1],dp[i−2]+cost[i−2])
依次计算 dp 中的每一项的值,最终得到的 dp[n] 即为达到楼层顶部的最小花费。
解答
class Solution {
public int minCostClimbingStairs(int[] cost) {
int n = cost.length;
int[] dp = new int[n + 1];
dp[0] = dp[1] = 0;
for (int i = 2; i <= n; i++) {
dp[i] = Math.min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
}
return dp[n];
}
}
题目2



⑥网络流
本章重点:
理解最大流、任意流、最小割、任意割之间的关系;
掌握网络最大流问题和最小割问题及其求解算法,给出一个网络能求出它的最大流或者最小割。
❶基础概念
**网络流(Network-Flows)**是一种类比水流的解决问题方法,与线性规划密切相关。网络流是图论中的一种理论与方法,研究网络上的一类最优化问题。
网络(NetWork):是指一个有向图 G =(V,E),V 是图 G 中顶点的集合,E 是图 G 中边的集合。(运输水流的水管线路)
每条
边 (u,v)∈ E 都有一个权值 c(u,v),称之为容量(Capacity),当 (u,v) ∉ E 时 c(u,v) = 0。图 G 有两个特殊的点:
源点 s∈ V 和汇点 t∈ V 。
弧 (arc) : 图 G 的边 (u,v)(水管)
源点 (Sources): 可以理解为起点。它会源源不断地放出流量,表示为 s 。(可无限出水的水厂)
汇点 (Sinks):可以理解为终点。它会无限地接受流量,表示为 t 。(可无限接收水的小区)
容量 (Capacity) :每条弧 (u,v) 的权值 c(u,v) (水管规格。即可承受的最大水流量)
容量网络: 拥有源点和汇点且每条弧都给出了容量的网络。(安排好了水厂、小区和水管规格的路线图)

流量 (Flow) :容量网络G中每条弧< u,v>上的实际流量 ,表示为 f(u,v) (运输的水流量)
设 f(u,v)定义在二元组 (u∈V, v∈V) 上的实数函数满足:
容量限制:对于每条边,流经该边的流量不超过该边的容量,即 f(u,v)≤c(u,v) (水流量超过了水管规格就爆了)
斜对称性:每条边的流量与其相反边的流量之和为 0 ,即 f(u,v)+f(v,u)=0 (可以暂且感性理解为矢量的正负)
流守恒性:从源点流出的流量等于汇点流入的流量。即 ∀x ∈ V - {s,t},∑(u,x)∈Ef(u,x) = ∑(x,v)∈Ef(x,v) (对于所有的水管交界处,有多少水流量过来,就应有多少水流量出去)

流量网络: 拥有源点和汇点且每条弧都给出了流量的网络。(分配好了各个水管水流量的路线图)

剩余容量(Residual):对于每条边,剩余容量(Residual) = 容量(Capacity) − 流量(Flow)。(表示水管分配了水流量后还能继续承受的水流量)
残量网络: 拥有源点和汇点且每条弧还有剩余容量的网络。残量网络 = 容量网络 − 流量网络。初始的残量网络即为容量网络。(表示了分配了一定的水流量后还能继续承受的水流量路线图)

❷最大流
问题描述:我们有一张有向图,要求从源点 s 流向汇点 t 的最大流量(可以有很多条路到达汇点),这就是我们的最大流问题。
➀基础概念
网络的流量: 在某种方案下形成的流量网络中汇点接收到的流量值。(小区最终接收到的总水流量)
最大流(Maximum-Flow) :网络的流量的最大值。(小区可接受到的最大水流量)
最大流网络: 达到最大流的流量网络。(小区接收到最大水流量的分配方案路线图)
增广路径(Augmenting Path): 一条在残量网络中从 s 到 t 的路径,路径上所有边的残留容量都为正。
(可以成功从水厂将水送到小区的一条路线)
➁增广路算法
当残量网络不包含增广路径时能求得最大流
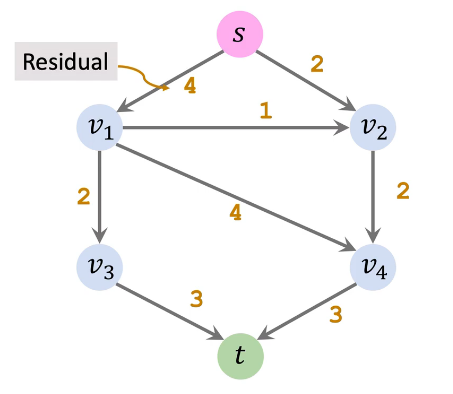
例如如下网络:
| 初始容量网络 | 初始残量网络 |
|---|---|
|
 |
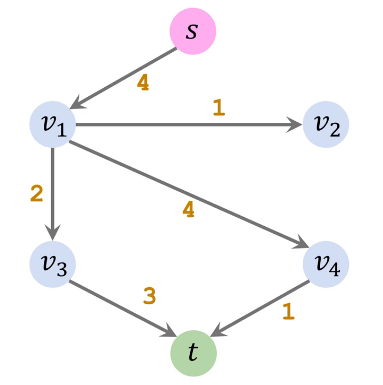
寻找增广路径,增广路径上的流量为路径上最小容量
| 增广路径1(s→v2→v4→t) | 残量网络1 |
|---|---|
 |
 |
| 增广路径2(s→v1→v3→t) | 残量网络2 |
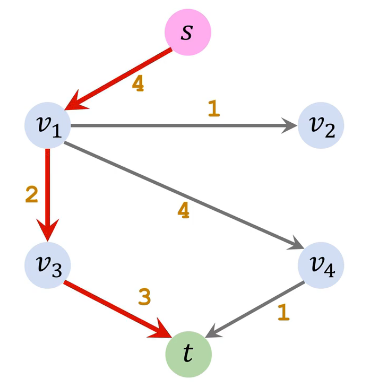 |
 |
| 增广路径3(s→v1→v4→t) | 最终残量网络 |
 |
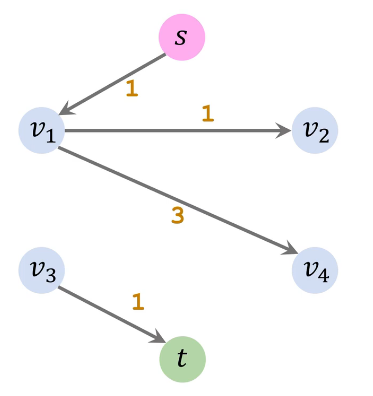 |
求流量网络,流量网络 = 初始容量网络 - 最终残余网络
因此最大流为从 s 流出的流量 3 + 2 = 5 或者流入 t 的流量 2 +3 =5
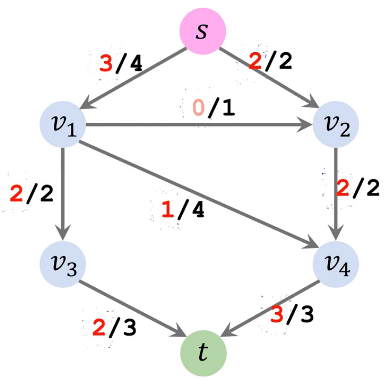
但是这种算法并不能保证一定能得到最大流,取决于你选择增广路径的顺序,我们同样以上方初始容量网络图为例,假设第一条增广路径选择 s→v1→v4→t,第二条增广路径选择 s→v1→v3→t,得到如下残量网络 和 流量网络
| 容量网络 | 残量网络 | 流量网络 |
|---|---|---|
|
 |
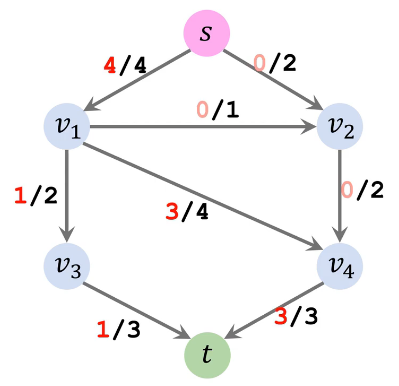 |
因此该种方法求得最大流为从 s 流出的流量 4 + 0 = 4 或者流入 t 的流量 1 +3 =4,显然比刚刚求得的最大流 5 要小
总结:这种算法并不能保证一定能得到最大流,取决于你选择增广路径的顺序,那么如何保证无论怎么选择增广路径仍然能求得最大流呢?且听我娓娓道来。
➂Ford-Fulkerson
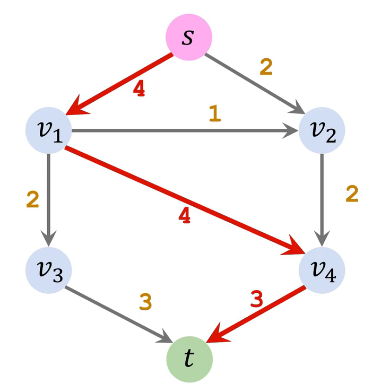
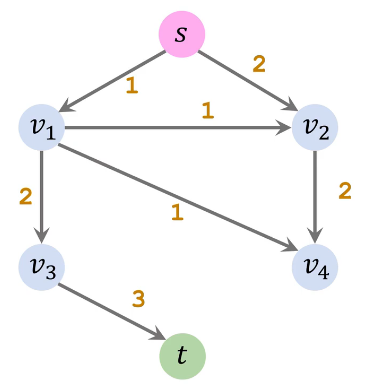
FF 算法核心是引入反向边,有了反向边,哪怕之前选择的增广路径顺序不好,也有了一个后悔和改正的机会
FF算法复杂度:O(f*m) (f 为最大流,m为原图边的数量)
我们来改造上方的错误求解方法
| 增广路径1(s→v1→v4→t) | 残量网络1 | 加入路径1反向边 |
|---|---|---|
 |
 |
 |
| 增广路径2(s→v1→v3→t) | 残量网络2 | 加入路径2反向边 |
 |
 |
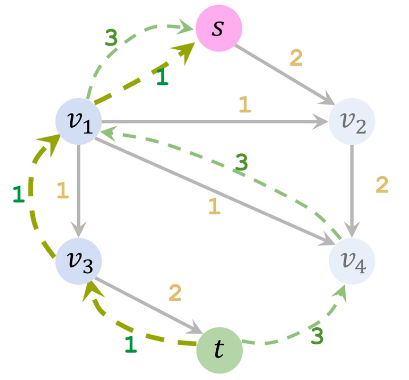 |
| 增广路径3(s→v2→v4→v1→v3→t) | 残量网络3 | 加入路径3反向边 |
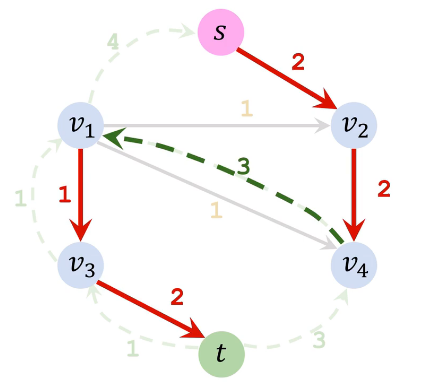 |
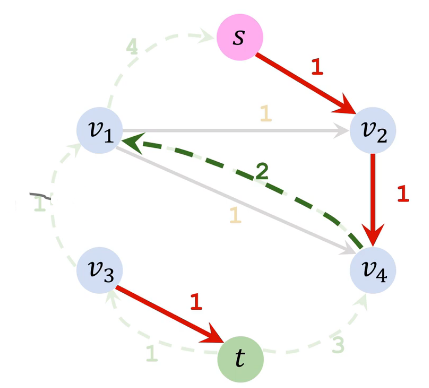 |
 |
| 移除所有反向边得最终残量图 | 流量图 | 最大流 |
 |
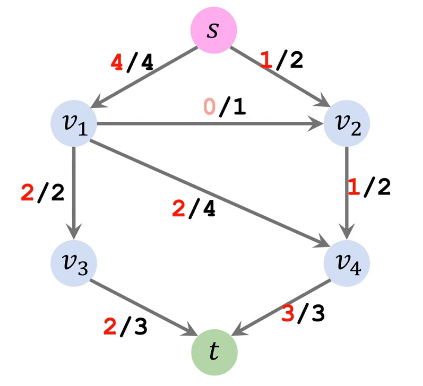 |
因此最大流为从 s 流出的流量4 + 1 = 5 或者流入 t 的流量 2 +3 =5 |
❸最小割
割:对于一个网络流图 G = (V,E),其割的定义为一种 点的划分方式:将所有的点 V 划分为 S 和 T 两个集合,其中源点 s ∈ S ,汇点 t ∈ T。割并不唯一

上图就为一种割,S = {s,v1,v2},V ={t,v3,v4},s的水无法流到t了
割的容量:我们的定义割 (S,T) 的容量 c(S,T) 表示所有从 S 到 T 的边的容量之和,即 c(S,T) = ∑u∈S,v∈Tc(u,v) 。
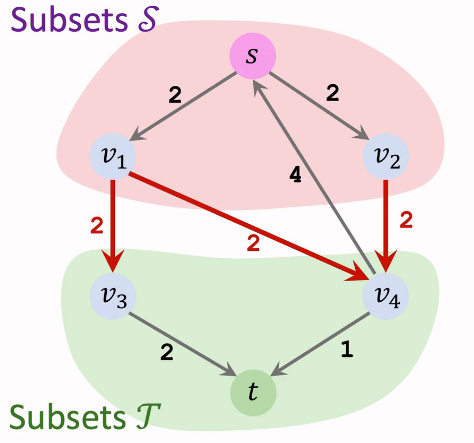
容量 c(S,T) = 2 + 2 + 2 = 6

容量 c(S,T) = 2 + 1 = 3
最小割:求得一个割 (S,T) 使得割的容量 c(S,T) 最小,最小割并不一定唯一。
最大流最小割定理:f(s,t)max = c(S,T)min 最小割的容量等价于最大流的流量
求解最小割:
求最小割的容量,那么只要跑一遍网络最大流即可得出答案。
求 S 集合和 T 集合,那么先跑一遍网络最大流,然后在跑完网络最大流的残留网络中,从源点 s 开始进行 DFS,能遍历到的节点都属于 S 集合,剩下的节点都属于 T 集合。
| 初始容量网络 | 最终残量网络 | 最小割 |
|---|---|---|
|
|
 |
因此最小割为{ {s,v1,v2,v4}{t,v3}},容量(最大流)为 5
❹流与割
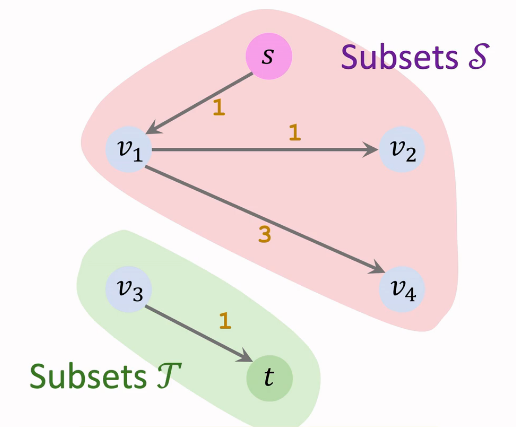
对任意流 f,任意割 (A, B),流的大小为流出A的流量与流入A的流量之差。
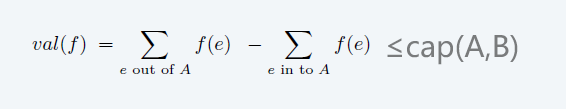
例如如下 ,A集合为黑色小圆圈,B集合为白色小圆圈

val(f) = (10 + 10 + 5 +10 + 0 + 0) - (5 +5 + 0 +0 ) = 25

val(f) = (20 + 22) - (8 + 4 + 4 ) = 26
❺真题练习
➀题目1
计算下图中从S到T的最大流和最小割.
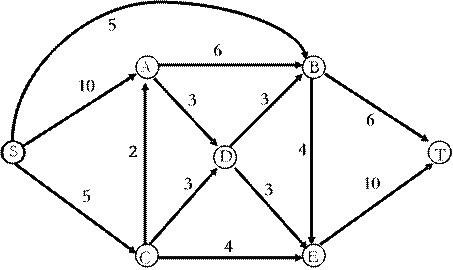
增广路径:(S, A, B, T),网络流大小+6
增广路径:(S, B, E, T),网络流大小+4
增广路径:(S, A, D, E, T),网络流大小+3
增广路径:(S, C, E, T),网络流大小+3
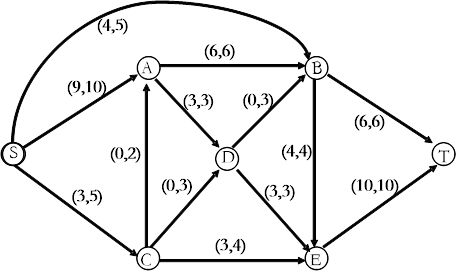
最大流 6 + 4 + 3 + 3 = 16
最小割 [ {S,A,B,C,D,E},{T} ]
➁题目2
求下图中S和T间的最大流,要求给出最少两个中间计算步骤。

增广路径:(S,C,F,T),流量值+1
增广路径:(S,C,B,F,T),流量值+1
增广路径:(S,A,B,F,T),流量值+1
增广路径:(S,A,D,T ),流量值+1
增广路径:(S,A,E,D,T ),流量值+1
增广路径:(S,A,E,T),流量值+1
增广路径:(S,B,F,E,T),流量值+3
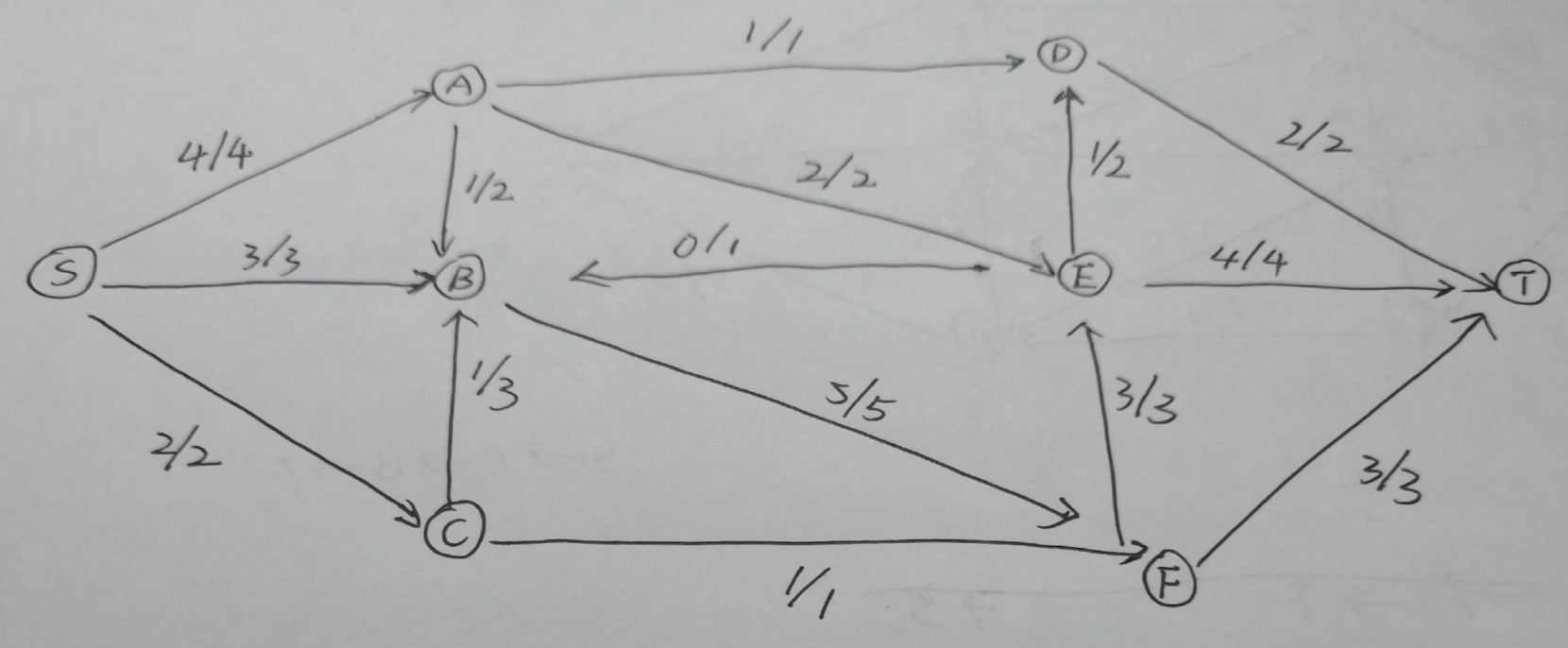
最大流 1 + 1 + 1 + 1 + 1 + 1 + 3 = 9
⑦NP完备性理论
本章重点:
理解什么是多项式归约(polynomial-time reduction)
从一个问题 A 多项式归约到另一个问题 B 时,掌握针对问题 A 的任意实例构造问题 B 的实例的方法。
自身归约
掌握如果P≠NP ,P、NP和NPC三个集合之间的关系, 以及NP问题定义的非对称性
记住证明一个问题属于NPC的基本步骤
能证明给定的问题是NP完全问题
❶P&NP&NPC
➀基础概念
P(Polynomial-time,多项式时间):能在多项式时间内求解的问题。
- 多项式时间算法,对于规模为 n 的输入,在最坏情况下的运行时间是O(nk),其中 k 为某一确定常数。
- 伪多项式时间算法,典型的0-1背包问题算法复杂度为O(n*W),其运行时间与输入的规模相关,是伪多项式的。
NP(Nondeterministic Polynomial-time,非确定性多项式时间):能多项式时间内可以被验证的问题
NPC(NP Completeness,NP完全):NP中最难的问题,可能没有多项式时间算法的问题 ,满足两个条件①是一个NP问题②所有的NP问题都可以约化到它
NP-Hard:比NP问题都要难的问题,满足NPC问题的第二条,但不一定要满足第一条
➁P&NP&NPC关系
- 当 P ≠ NP 时,NP 问题和 NP-hard 的交集就是 NPC 问题
- 当 P = NP 时,P = NP = NPC
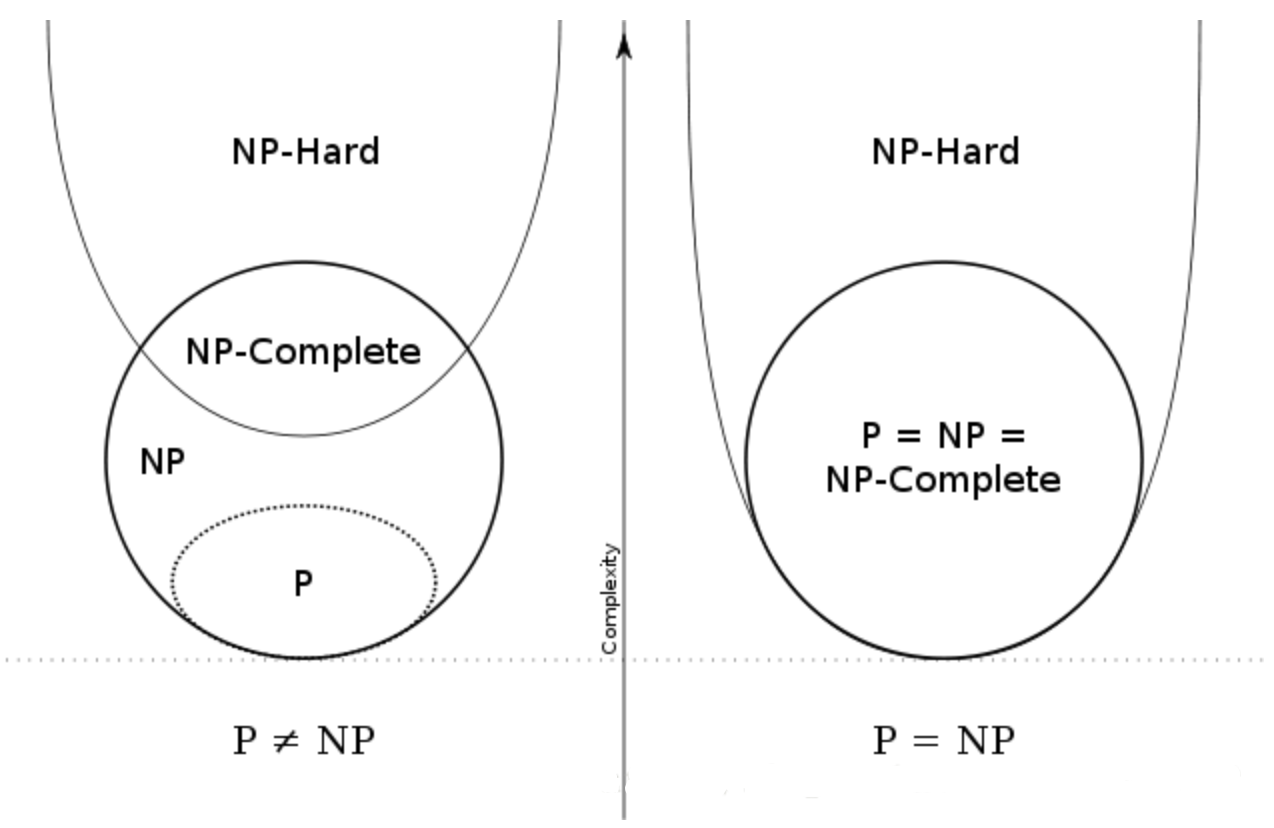
➂NP问题定义的非对称性
这个问题小简也不太懂,不知道如何写,有知道的大佬可以给小简讲讲吗
❷多项式时间归约
归约
描述:在研究不同问题的难度时,希望表达“问题 Y 至少像问题 X 一样的难”,这就是归约。
定义:设计一个函数 f(x),把问题 A 的输入转换成问题 B 的一个输入,这样就能用问题 B 的解法来求解。这样就是归约技术,将这个问题转换为类似的其他问题。
多项式时间归约
描述:所谓多项式归约是指转换函数 f(x) 不能太复杂,需要在多项式时间内完成,如果是指数级或其他复杂度就没有意义了。
定义:如果问题 X 和问题 Y 满足以下两条性质,那么问题 X 可以在多项式时间归约到问题 Y 。记为:X ≤p Y
- 问题 X 可以通过多项式时间的基本运算步骤转换为问题 Y;
- 问题 X 多项式次调用求解问题 Y 的算法,且问题 Y 可以在多项式时间内被求解。
根据以上定义,可以得到三个定理:
- 假设 X ≤p Y,如果 Y 能够在多项式时间内求解,那么 X 也能在多项式时间内求解。
- 假设 X ≤p Y,如果 X 不能在多项式时间内求解,那么 Y 也不能在多项式时间内求解。
- 如果 X ≤p Y 且 Y ≤p X,那么 X ≡p Y, 即 X 和 Y 等价。
例题:
 |
 |
|---|---|
| C | B |
有多项式时间算法的问题和可能没有多项式时间算法的问题
| 有多项式时间算法 | 可能没有多项式时间算法 |
|---|---|
| 最短路问题 | 最长路问题 |
| 最小割问题 | 最大割问题 |
| 2元可满足性问题 | 3元可满足性问题 |
| 平面图4着色问题 | 平面图3着色问题 |
| 二部图顶点覆盖问题 | 一般图顶点覆盖问题 |
| 匹配问题 | 3D匹配问题 |
| 素性测试问题 | 质因子分解问题 |
| 线性规划问题 | 整数线性规划问题 |
看到这里,小简觉得你已经对归约有了一个基本的认知,但是我们如何进行规约呢,莫慌莫慌,下面小简将对具体问题如何规约进行详细叙述,友情提示下方内容高能,请读者做好心理准备,耐心阅读,反复研读,加油!
❸一般归约方法
归约是指问题 A 的任何实例能用问题 B 的方法来解决(判断),并且 A 的解为“是”,当且仅当 B 的解也是“是”。因此,证明归约是双向的,目前遇到的大多归约问题(A ≤p B)都可以按以下步骤进行:
- 构造图 G ,存在问题 A 的解集;
- 在图 G 基础上,构造图 G’(常添加边或点),使得问题 A 的解集能反应在 G’ 中问题 B 的解集(注意两个问题解集的规模 k 一定要有确定的联系);
- 图 G 中存在问题 A 的解集 S,当且仅当图 G’ 中存在问题 B 的解集 S’ ;
- 规约的正确性,需双向证明。
也有不用构造新图的,比如点覆盖到独立集的规约,这种方法叫直接规约。但大多有些难度的归约一般都需要构造。
❹重点掌握的归约
①顶点覆盖≡p独立集
Vertex-Cover ≡p Independent Set(顶点覆盖 ≡p 独立集)
顶点覆盖问题:给定一个图 G = ( V , E )和一个整数 k ,是否存在一个大小为 k 的顶点子集,使图中每一条边至少有一个顶点在上述顶点子集中。
如图,黑色的点集合都是顶点覆盖集合,图的每一条边都至少有一个顶点在点集合中。

独立集问题:给定一个图 G = ( V,E )和一个整数 k ,是否存在一个大小为 k 的顶点子集,使子集中任意两个顶点不邻接。即顶点集合中的任意两个点之间没有边。
如图,红色s的点集合都是独立集,任意两个红色的顶点没有边。

例题:

两个问题可以归纳为:
独立集问题: 给定图 G 和数 k ,问 G 是否包含大小为 k 的独立集?
顶点覆盖问题:给定图 G 和数 k ,问 G 是否包含大小为 k 的顶点覆盖?
(顶点覆盖 ≡p 独立集)问题描述:设图 G = ( V , E ) ,S ⊆ V,若 S 是一个大小为 k 的
独立集当且仅当 V − S 是一个大小为 n − k 的顶点覆盖
证明:
⇒
S 是图 G 的任一独立集
则任意边 (u,v) ∈ E,有u ∉ S 或 v ∉ S 或 u,v 都 ∉ S;那么 u∈V-S 或 v∈V-S 或 u,v 都 ∈ S
所以图的任意边 (u,v) 至少有一个顶点在集合 V-S 中,即集合 V-S 是一个顶点覆盖
⇐
V-S 是图 G 的任一顶点覆盖
则任意边 (u,v) ∈ E,有 u ∈ V-S 或 v ∈ V-S 或 u,v 都 ∈ V-S ;那么 u ∉ S 或 v ∉ S 或 u,v 都 ∉ V-S
所以图的任意边至少有一个端点不在集合 S 中,集合 S 是一个独立集
∴ Vertex-Cover ≡p Independent Set
②顶点覆盖≤p集合覆盖
Vertex-Cover ≤p Set-Cover(顶点覆盖 ≤p 集合覆盖)
集合覆盖问题:给定 n 个元素的集合 U , S1,S2,… ,Sm 是 U 的子集,给定数 k , 问在这些子集中是否有几组子集,它们的并集等于整个 U 且至多含有 k 组子集?
如图,集合覆盖大小为 k = 2

例题:

(顶点覆盖 ≤p 集合覆盖)问题描述:给任意一个顶点覆盖问题的实例 G=(V,E)和 k,都能构造出对应的集合覆盖实例(U,S,k)。集合覆盖大小为 k 当且仅当顶点覆盖大小为 k 。
证明:
构造思路:原顶点覆盖的顶点相当于集合覆盖中的子集合,原顶点覆盖的边相当于集合覆盖的子集合中元素。
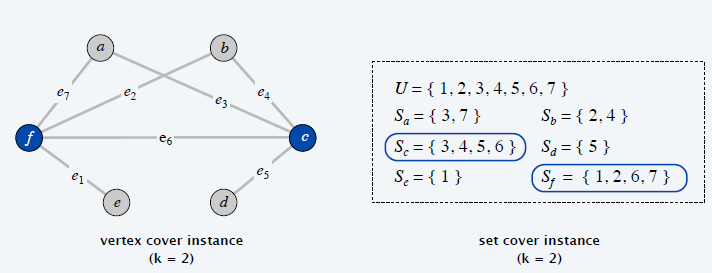
⇒
令 X ⊆ V 为 G 中大小为 k 的顶点覆盖,则 Y = {S v | v ∈ X } 为大小为 k 的集合覆盖。
⇐
令 Y ⊆ S 为 (U,S,k) 中大小为 k 的集合覆盖,则 X = { v | Sv ∈ Y } 为 G 中大小为 k 的顶点覆盖。
∴ Vertex-Cover ≤p Set-Cover
③3-SAT≤p独立集
3-SAT ≤p Independent Set(3-SAT ≤p 独立集)
SAT问题:SAT 问题叫作布尔可满足性问题(Boolean satisfiability problem)
给定变量集 X = {x1,x2,… ,xn} 上的一组子句 C1,C2,… ,Cn ,子句为 X 中一些元素的并集,多个子句的交集构成一个合取范式,问是否存在使合取范式为真的分配方案?
3-SAT问题:3-SAT 问题叫作三元可满足性问题。
若限定 SAT问题合取范式中的每个子句中元素的数量为 3 个,则为 3-SAT 问题。
(3-SAT ≤p 独立集)问题描述:给定一个 3-SAT 问题的实例 Ф ,我们都能构造出一个图 G = ( V , E ) 独立集问题的实例。3-SAT问题有解,当且仅当 G 中 k = ∣ Ф ∣,∣ Ф ∣ 大小为合取范式中子句的个数。
证明:
构图思路:
- G中三个顶点构成一个三角形表示一个子句,每个节点表示一个元素
- 每个顶点与其对立节点连线
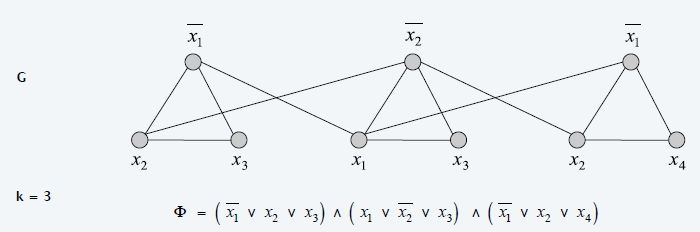
规约的正确性,需双向证明,即独立集存在,则 Ф 被满足;Ф 被满足,则独立集存在。
⇒
图 G 存在大小为 k 的独立集,那么各三角形中必然有一点在独立集中(三角形内的点均相邻,不独立);
将这 k 个点(变量)的值设为 true,那么其余所有点的取值均可确定下来;
因为这 k 个点在 k 个不同的句子中,则 Ф 能被满足。
⇐
Ф 被满足,在 k 个句子中选取三个变量设为 true,它们对应图 G 中 k 个三角形中的 k 个点;
这 k 个点刚好构成图 G 大小为 k 的独立集(因为互反的变量不会同时为 true,即不会同时在 k 个点中)。
∴ 3-SAT ≤p Independent Set
①②③总结:3-SAT ≤p 独立集问题 ≡p 顶点覆盖 ≤p 集合覆盖
④顶点覆盖≤p支配集
Vertex-Cover ≤p Dominating-Set(顶点覆盖 ≤p 支配集问题)
支配集问题:给定无向图 G 和正整数 k,问图 G 中是否存在 k 个顶点的子集 s ,使得对于图 G 中的任意顶点 v ,要么 v∈s,要么 v 至少与 S 中的至少一个顶点相邻。
(顶点覆盖 ≤p 支配集问题)问题描述:给任意一个顶点覆盖问题的实例 G=(V,E)和 k,都能构造出对应的支配集实例 G’。支配集大小为 k 当且仅当顶点覆盖大小为 k 。
证明:
构图思路:对给定的图G,作如下处理:对于图G的任意一边uv,添加一个点w,使得该边的两个顶点u、v分别与w相邻,得到新的一个无向图G’。

⇒
假设 s 是 G 的一个顶点覆盖,由于所有边都被 s 覆盖,因此图 G’ 所有顶点也都被 s 所支配。
⇐
假设 s 是 G’ 的一个支配集,如果 s 含有新顶点 w,它可以被 v 或者 u 替换并且仍旧是一个支配集(因为顶点 v 和 u都能覆盖 w 所覆盖的顶点),可以假定 s 仅包含 G 中的顶点。由于 s 支配了所有新顶点,它一定至少包含原图中每条边的两端顶点之一,因此它也是 G 的一个顶点覆盖。
∴ Vertex-Cover ≤p Dominating-Set
⑤有向图Ham≤p无向图Ham
Directed Ham-cycle ≤p Ham-cycle(有向图哈密尔顿圈 ≤p 无向图的哈密尔顿圈)
哈密尔顿圈:设有一个图 G=(V,E),若其上存在一个圈 C,这个圈包含该图上的每一节点,则称该圈 C 为哈密顿圈,图 G 称为哈密顿图。下图就是一个含有哈密顿圈的哈密顿图。
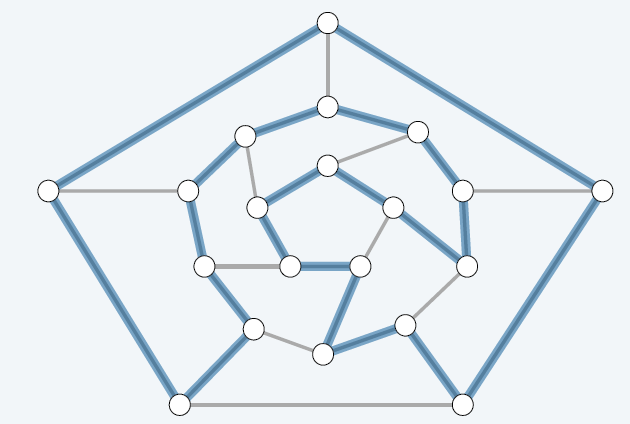
(有向图哈密尔顿圈 ≤p 无向图的哈密尔顿圈)问题描述:给定一个 n 个节点的有向图 G = ( V , E ) ,我们可以构造一个含 3n 个顶点的无向图 G ′。有向图 G 拥有哈密尔顿圈当且仅当无向图 G ′ 拥有哈密尔顿圈。
证明:
构图思路:把有向图 G 中的一个顶点,拆分成三个顶点(蓝、黑、白)
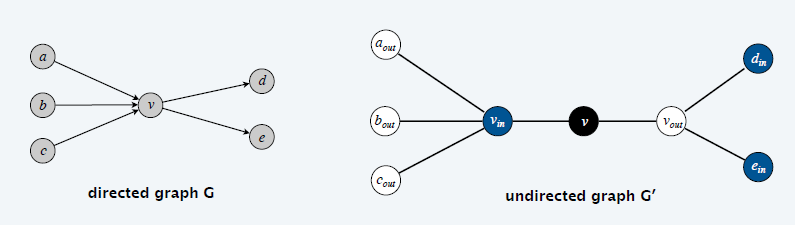
⇒
假设 G 存在一个有向的哈密尔顿圈 Γ ,那么 G′ 也有一个跟上述顺序一致的无向哈密尔顿圈 Γ′
⇐
假设 G′ 有一个无向哈密尔顿圈 Γ′ ,Γ′ 访问 G′ 中的顶点必须选择以下两种顺序中的一个:
- 黑,白,蓝
- 黑,蓝,白
Γ′ 中的黑色节点对应 Γ 中的哈密尔顿圈或者逆序中的一个。
∴ Directed Ham-cycle ≤p Ham-cycle
⑥3−SAT≤p有向图Ham
(3−SAT ≤p 有向图哈密尔顿圈)问题描述:给定一个 3−SAT 的实例,我们都能构造出一个图 G,3−SAT 实例有解当且仅当图 G 含有一个哈密尔顿圈。
证明:
构图思路:
- 图 G 中哈密尔顿圈的个数为 2n 个,每个元素有真假 2 种可能,一共有 n 个,从左到右赋值为真,从右到左赋值为假
- 对于每个子句,若存在 xi ,则增加一个节点,并从左到右增加边;若存在 ¬xi,则增加一个节点,并从右到左增加边
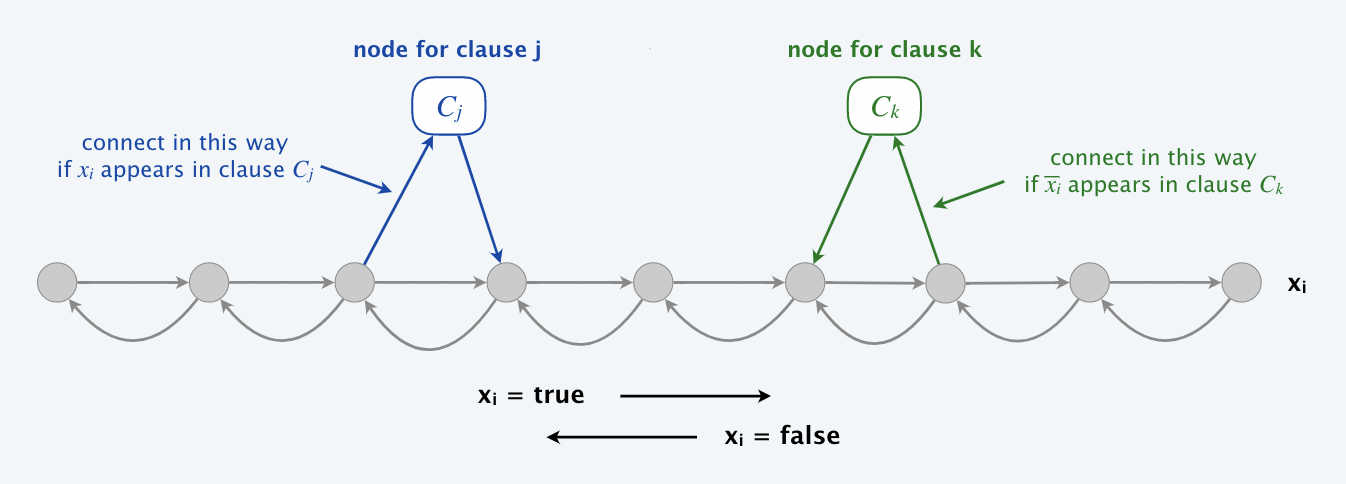
- 对每个变量 xi(1≤i≤n),创建 3m+3 个顶点,命名为vi,1,vi,2,⋯ vi,3m+3 并且对相邻序号的两个顶点添加互相之间的有向边。如果 xi = 1,则形成从左向右的一个路径;如果 ¬xi=1,则形成从右向左的一个路径。
- 对每个 1≤i≤n−1,添加四条有向边(vi,1,vi+1,1),(vi,3m+3,vi+1,3m+3),(vi,1,vi+1,3m+3),(vi,3m+3,vi+1,1)
- 添加两个节点 s,t,添加有向边(s,v1,1),(s,v1,3m+3),(vn,1,t),(vn,3m+3,t)。然后再添加有向边(t,s)。这时得到的图中有 hamiltonian cycle。
- 对于每一个 clause Cj = z1z2z3,创建对应的顶点 Cj。
- 如果 z = xi,则添加有向边 (vi,3j,Cj) 和 (Cj,vi,3j+1) ;
- 如果z = ¬xi,则添加有向边 (Cj,vi,3j) 和 (vi,3j+1,Cj)。
- 这里 1 ≤ j ≤ m,1 ≤ i ≤ n。
- 如对子句C1 = x1∨¬x2∨x3 生成如下图中蓝色所示。
- 如果选择子句中 x1 = 1,则 x1 对应的路径为从左向右;
- 如果选择 ¬x2=1,则 x2 对应的路径为从右到左;
- 如果选择 x3=1,则 x4 对应的路径为从左到右。
- 这样我们就得到了最终的图G。
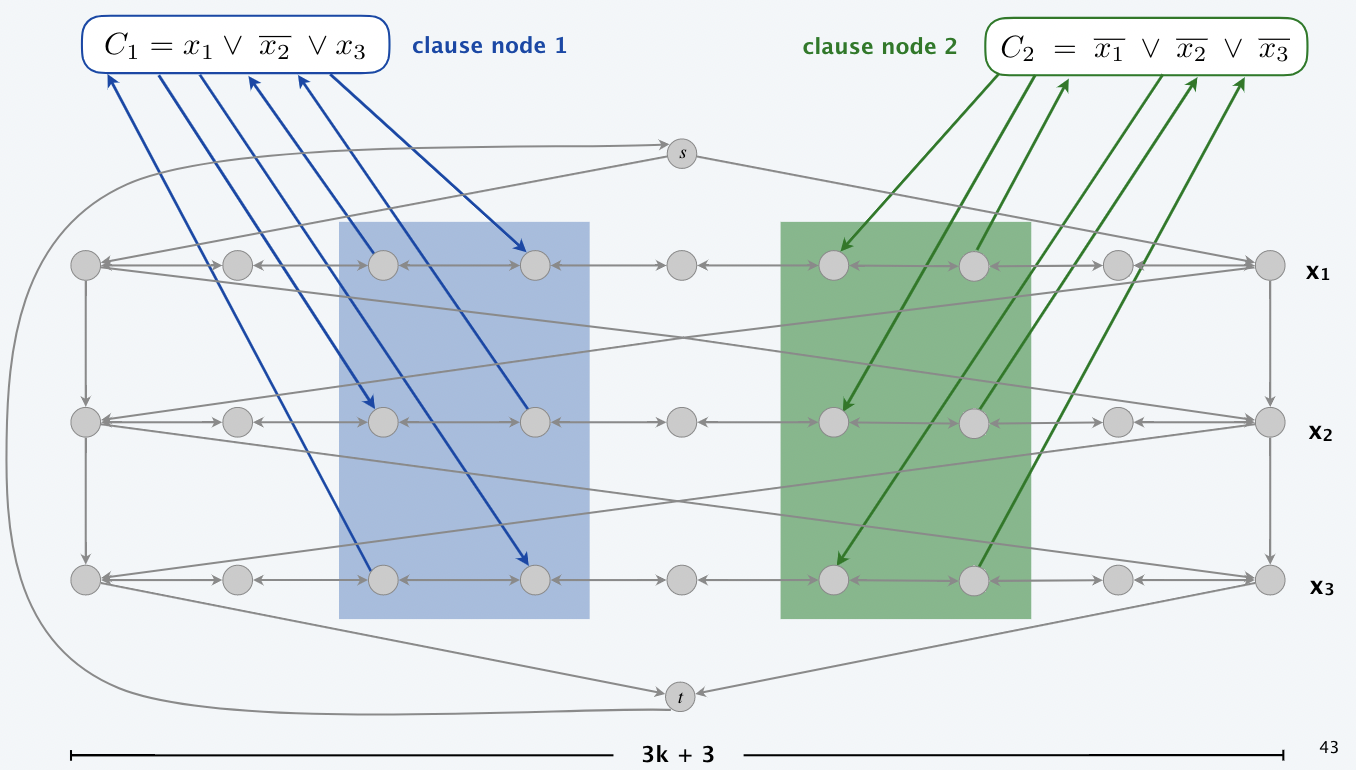
⇒
假设 3−SAT 实例 ϕ 有满足的真值指派 x∗,那么我们在 G 中找到一个哈密尔顿圈 Γ 如下:
如果 xi∗ = true 我们从左到右穿过第 i 行
如果 xi∗ = false 我们从右到左穿过第 i 行
对于每个字句 Cj ,至少存在一行 i 按照我们上述的方向,把子句节点拼接进圈内(我们只把子句节点拼接进圈有且仅有一次)
⇐
假设 G 中有一个哈密尔顿圈 Γ
如果 Γ 加入了子句节点 Cj ,
- 并假设与 Cj 前后邻接的节点通过边 e ∈ E 相连。
- 我们从圈中删除节点 Cj 和其直连边,并用边 e 代替,得到 G − { Cj } 的哈密尔顿圈。
循环执行上述方法,我们得到在 G − { C1 , C2 , … , Ck } 上的哈密尔顿圈 Γ′
如果 Γ′ 在第 i 行的遍历方向是从左到右的,那么置 xi∗ = true ,否则置 xi∗= false
按照上述正确方向遍历进行真值指派,每个子句都会被满足,即原实例 ϕ 可满足。
⑦哈密尔顿圈≤p旅行售货员
Ham-cycle ≤p TSP(哈密尔顿圈 ≤p 旅行售货员问题)
TSP:给定 n 个城市以及两两城市之间的距离 d(u,v),问是否存在一个旅游访问 n 个城市一次且长度 ≤ D。
问题描述:给定一个哈密尔顿圈的实例 G = (V,E),创建一个 TSP 问题的完全图实例 G’, n 个城市两两间的距离函数定义如下:
TSP问题有一个长度 ≤ n 的旅游当且仅当 G 中含有一个哈密尔顿圈

TSP实例满足三角形不等式:d(u,w) ≤ d(u,v)+d(v,w)
⑧三着色 ≤p k着色
3-Color ≤p K-Color (K > 3)(三着色问题 ≤p k着色问题)
⑨哈密尔顿圈≤p最长路径
Ham-Cycle ≤p Longest-Path(哈密尔顿圈 ≤p 最长路径)
Longest-Path:给定一个有向图 G = (V,E),是否存在至少由 k 条边组成的简单路径?
⑪子集和≤p分区问题
Subset-Sum ≤p Partition(子集和问题 ≤p 分区问题)
Subset-Sum:给定 n 个数 w1 , … , wn 和整数 W,是否存在一个子集,其中所有元素的和等于 W。
Partition:给定元素个数为 m 的集合 V ={v1 , v2 , … , vm} ,是否可以将集合 V 分割成两个子集,使每个子集各元素之和为 1/2∑vi 。即集合 A 能划分成元素之和相等的两部分。
(子集和问题 ≤p 分区问题)问题描述:给定一个集合 S = {w1 , w2 , … , wn},子集和为 W,需构造集合 S’,使得集合 S 存在一个子集之和为 W,当且仅当集合 S’ 存在一个 Partition
证明:
构图思路:构造分区问题集合 S’ = {v1 , v2 , … , vn, vn+1, vn+2},其中:
v1 = w1,v2 = w2, … , vn = wn,vn+1 = 2∑wi - W,vn+2 = ∑wi + W
由于分割问题总和为 4∑wi ,所以 vn+1 和 vn+2 不能在同一子集,不然该子集和为3∑wi,最终不能均分。要使每部分和为 2∑wi ,只能是如下情况:
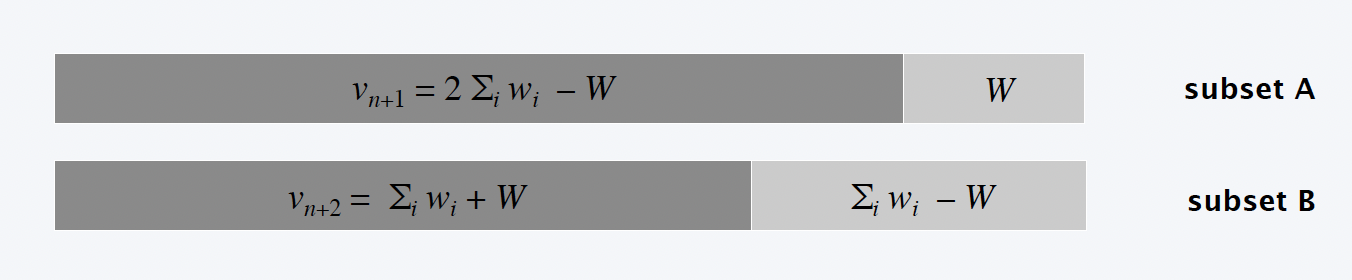
⇒
S 存在一个子集 A = {a1 , a2 , … , ak},其中 ak ∈ S,k≤n 且 ∑ai = W
那么集合 S’ 中,有 ∑i∈A ai + vn+1 = ∑i∈S-A ai + vn+2 = 2∑wi
所以集合 S’ 存在一个划分 A ∪ {vn+1} 和 S-A ∪ {vn+2}
⇐
集合 S’ 能被划分为两个和相等的集合,可知 vn+1 和 vn+2 不在一个划分子集里
那么,存在一个集合 A,设其元素之和为 Y,有 Y + vn+1 = ∑i∈S wi - Y + vn+2
解出 Y = W。
∴ Subset-Sum ≤p Partition
⑩子集和≤p背包问题
Subset-Sum ≤p Knapsack(子集和问题 ≤p 背包问题)
Knapsack:给定一个物品集合 X ,重量为 ui ≥ 0 ,价值 vi ≥ 0 ,背包能承受的总重量不超过 U,给定一个目标价值 V,是否存在一个子集 S ⊆ X 使得 ∑i∈S ui≤U,∑i∈S vi≥V
(子集和问题 ≤p 背包问题)问题描述:给定一个集合 S = {w1 , w2 , … , wn},子集和为 W,需构造集合 S’,使得集合 S 存在一个子集之和为 W,当且仅当集合 S’ 存在一个背包实例
证明:
构图思路:对于任意一个子集和实例,我们构造一个背包实例:ui = vi = wi,U = V = W
⇒
S 存在一个子集 A = {a1 , a2 , … , ak},其中 ai ∈ S,k≤n 且 ∑ai = W
那么集合 S’ 中,有 ∑ai = ∑ui = ∑vi = W,∴ ∑ui = U,∑vi = V
所以集合 S’ 存在一个背包实例
⇐
集合 S’ 中存在一个背包实例,可知 ∑i∈S ui≤U,∑i∈S vi≥V
那么,存在一个集合 A,设其元素之和为 Y,有 Y = W
∴ Subset-Sum ≤p Knapsack
⑫分区问题 ≤p k负载均衡
Partition ≤p k-Load-Balance(分区问题≤p k负载均衡)
❺自归身约
掌握同一个问题的最优化问题如何多项时间归约到该问题的判断问题(自身归约),例如顶点覆盖问题,Hamilton Cycle问题,3-Color问题
➀基础概念
自身规约:将求解(最优化)问题多项时间归约到该问题的判断问题。
如果判断问题能够解决,那么就可以利用判断问题来解决求解问题。
自归约步骤
- 设该判断算法为 A ,利用算法 A 判断出图中存在…(大小为k的…);
- 删除一条边或点(看具体是边集还是点集的问题),对删除边/点后的图运行判断算法 A ;
- 若图中还存在…(大小为k的…),则从图中彻底删除该边/点;若不存在,则把该边/点加入集合 S 中;
- 对所有的边/点调用算法 A 执行上述操作,最终得到的集合 S 就是求解问题的解。
看完以上解题步骤,小简觉得你应该还是有点点懵懵的,但别担心,看完下面的具体案例你再回来研读解题步骤,我相信你对自身规约会有不一样的认知,加油!
➁Vertex-Cover问题
假如我们能判断一个图中是否存在点数为 k 的最小点覆盖。请你设计构造最小点覆盖问题的多项式时间算法。
- 设该判断算法为 A ,利用算法 A 判断图 G 是否存在点数为 k 的最小点覆盖
- 若不存在,则结束;
- 若存在,则在图中删除一个点 v;
- 再用算法 A 判断图 G = (V-v, E) 中是否存在点数为 k 的最小点覆盖
- 若存在,则将点 v 从图中彻底删除;
- 若不存在,则把点 v 加入到集合 S 中;
- 不断重复上述操作,最终 S 中的所有点就是最小点覆盖。
➂Hamilton Cycle问题
(2020)如果存在判断任意简单无向图是否存在哈密尔顿圈的多项式时间算法,请你设计构造任意简单无向图的哈密尔顿圈(如果存在的话)的多项式时间算法。
算法:
//设该判断算法为A
S 初始化为空集;
首先算法 A 判断图 G 中是否存在哈密尔顿圈,如果不存在则算法结束,如果存在则继续寻找哈密尔顿圈;
For every edge e in G {
如果 G – {e} 中不存在哈密尔顿圈,则将 e 添加到集合 S 中;
否则 G = G – {e};
}
最终所得集合 S 中的所有边构成图 G 的哈密尔顿圈。
➃3-Color问题
3-Color问题:对一个图的顶点进行三种颜色着色使得相邻两个点的颜色不一样
(2018/2019)对于三着色问题,若存在一个多项式时间算法判断一个图是否可以三着色,则存在一个多项式时间算法对可以进行三着色的图找到一个可行的三着色。
解法一:不断加边进去然后进行判断,直到不能加边为止。这样三种颜色的点就是图中三个独立集。
解法二:不断将两个不相邻的点合并成一个点然后进行判断,直到不能再合并为止。最后剩下三个点。
➄Longest-Path
如果存在一个多项式时间算法判断一个图是否存在一个长度为 k 的路径,则存在一个多项式时间算法要么找到图中一个长度为 k 的路径要么证明此图不存在长度为 k 的路径。
假设存在判断一个图 G 是否存在一个长度为 k 的路径的多项式时间算法 A
首先用算法 A 判断图 G 是否存在一个长度为 k 的路径
- 若不存在,则结束;
- 若存在,则在图中删除一条边 e ;
再用 A 判断图 G = (V, E-e) 中是否存在长度为 k 的一条路径
- 若存在,则将边 e 从图中彻底删除;
- 若不存在,则把边 e 加入到集合 S 中;
重复上述操作,最终 S 中的所有边构成的边就是长度为 k 的一条路径。
➅Subset-Sum问题
如果存在一个多项式时间算法判断一个集合 V 存在一个子集且其中元素的和等于 W,则存在一个多项式时间算法要么找到图中一个和为 W 的子集要么证明此集合不存在和为W的子集。
假设存在判断一个集合 V 是否存在一个和为 W 的子集的多项式时间算法 A
首先用算法 A 判断该集合 V 是否存在和为 W 的子集
- 若不存在,则结束;
- 若存在,则在集合中删除一个元素 v ;
再用 A 判断 V - v 中是否存在和为 W 的子集
- 若存在,则将元素 v 从集合中彻底删除;
- 若不存在,则把元素 v 加入到集合 S 中;
重复上述操作,最终 S 构成的集合就是和为 W 的子集。
❻真题练习
➀题目1
证明问题属于NPC的基本步骤
Step 1. 证明该问题是NP问题.
Step 2. 找到一个已知的NP完全问题X.
Step 3. 证明问题X可以多项式归约到该问题.
➁题目2
(2018)给出一个图和一个整数k,问是否可以在这个图上删除k个点使得剩余图上没有三角形(含有3个顶点的圈)。证明这个问题是NP完全的。 (10分)
答:从点覆盖问题规约过来(2分)。
对于一个点覆盖实例 G,构造一个该问题实例 G’;(1分)
对 G 中每一条边 ab,都添加一个新的顶点 c 然后连成三角形 abc。(4分)
说明 G 存在大小为 k 的点覆盖当且仅当 G’ 存在一个大小为 k 的解。(3分)
➂题目3
(2019)证明独立集问题(给定一个图,问图中是否存在k个顶点的子集,使得这个子集中任意两个顶点之间在原图中都不存在边)是NP完全的。
答:从点覆盖问题规约过来
⇒
S 是图 G 的任一独立集
则任意边 (u,v)∈E,有u ∉ S 或 v ∉ S;那么 u∈V-S 或 v∈V-S
所以图的任意边至少有一个端点在集合 V-S 中,集合 V-S 是一个点覆盖
⇐
V-S 是图 G 的任一点覆盖
则任意边 (u,v) ∈ E,有 u ∈ V-S 或 v ∈ V-S ;那么 u ∉ S 或 v ∉ S
所以图的任意边至少有一个端点不在集合 S 中,集合 S 是一个独立集
∴ Vertex-Cover ≡p Independent Set,即独立集问题NP完全的
➃题目4
最长路径问题:给定简单无向图中是否存在长度大于等于k的简单路径?请证明这个问题是NP完全问题。
⑧近似算法
本章重点:
- 理解为什么会有近似算法,什么是近似算法,如何评价近似算法的优劣。
- 掌握负载均衡问题的近似算法及其近似比证明。
- 掌握带权重的顶点覆盖问题的定价算法,证明该方法能得到一个2倍近似解。
- 理解带权重的顶点覆盖问题的整数规划模型如何建立的,理解松弛求解方法。
- 能够对一个图问题建立整数规划模型(如:带权重的顶点覆盖问题,广义负载均衡问题)。
- 理解求解0-1背包问题的基于取整法的近似算法。
- 能够设计简单的近似算法,并证明该算法是几倍近似算法。
❶基础知识
➀概念
近似的想法很简单,要解决一个问题,我们希望能够做到
- ①求解结果是最优的
- ②在多项式时间内解决
- ③对于任意的实例都能够通过该算法解决。
现在对于部分问题,无法完全满足以上要求,所以就牺牲了①,但是我们希望结果不是盲目的,所以就引入了近似的概念。近似算法其实是针对NP难问题的一种退让,对于许多 P 不等于 NP 的最优化问题,无法在多项式时间内找到最优解。因此,如果可以只求一个我们可以接受的解,而不是非要最优解,那么可能存在一个多项式时间的算法。
➁思想
放弃求解最优解,用近似最优解代替最优解,以此换取:
- 算法设计上的简化
- 时间复杂性的降低
➂性能
近似算法通常采用两个标准来衡量性能:
- 算法的时间复杂度(必须为多项式级的)
- 解的近似程度(可能与算法设计、问题规模、输入实例等有关)
❷负载均衡问题
掌握负载均衡问题的近似算法及其近似比证明
问题描述:有 m 台相同机器,n 个任务,任务 j 的处理时间为 tj,每个任务只能在一台机器上连续工作,一台机器同一时间只能处理一个任务。我们认为完成最后一个任务所需的时间为负载时间,希望能够让这个负载时间最短。
机器 i 的负载(机器 i 处理任务的时间之和):L[i] = ∑j∈S[i] tj ,S[i] 为分配给机器 i 的任务集合
最优工期(完成所有工作的最短时间跨度[makespan]):L∗ = maxiL[i]
优化问题:寻找一个分配方案最优工期
决策问题:是否存在一个分配方案使工期为 L∗
两个引理:
- 引理1:L∗ ≥ max(tj)(最优工期大于等于完成最长的工作所需时间)
- 引理2:L∗ ≥ (1/m)∑jtj (最优工期大于等于所有任务的平均时间)
负载均衡问题是 NPH 问题,因为分割问题 ≤p 负载均衡问题
➀2倍近似算法-List Scheduling
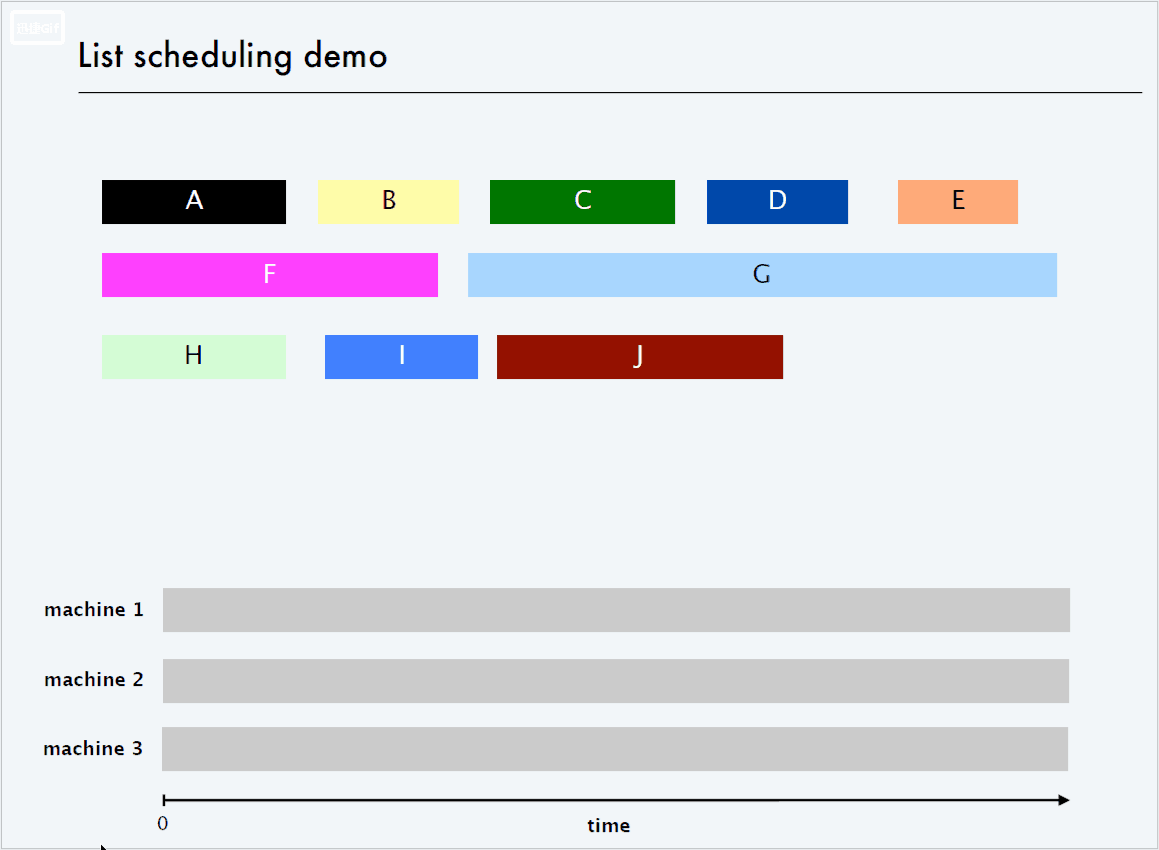
List Scheduling 是一种贪心策略,它的核心思想是将各个工作依次安排到累计工作时长最短的机器中,下面的动图显示了这一过程。可以发现,这种贪心的初衷只考虑了眼前的最小值,而局部最优解并不一定是最终的最优解。
2倍近似度证明:
设机器 i 是瓶颈机器(则 L[i] 为贪心解),任务 j 是最后一个在机器 i 上调度的任务(在调度前,机器 i 的工期是最小的)我们在考虑放入最后一个任务前,根据我们放置的规则,该机器 i 是所有机器中耗时最短的(L[i] − tj ≤ L[k]),该机器此时的用时(L[i] - tj)是低于除掉最后一个任务 j 后的平均时长(1/m)∑k L[k],更低于所有任务的平均时长(1/m)∑jtj(引理2);再根据引理1,最后一个任务应该是小于最优解的。
L[i] − tj ≤ L[k],对任意 1 ≤ k ≤ m
L[i] − tj ≤ (1/m) ∑kL[k]
≤ (1/m)∑jtj
≤ L∗
L∗ = L[i] = (L[i] − tj) + tj ≤ 2L∗
L[i] − tj ≤ L∗ ,tj ≤ L∗
∴ L[i] ≤ 2L∗
➁3/2倍近似算法-LPT Rule
上述贪心策略存在一个很明显的漏洞,当最后加入的工作所花时间最长时,效果很差。因此我们希望先安排长工作,将所有工作按花费时间降序排列,再执行上述贪心算法,这就是 Longest Processing Time Rule 的核心思想。
3/2倍近似度证明:
当 n ≤ m 时,则每台机器最多安排一个工作,容易找到最优解。 当 n ≥ m 时,先将 m 个任务安排到 m 台机器,那么对第 m+1 个工作,有 2tm+1 ≤ L∗ (瓶颈机器至少要做两个任务,两个任务的时间总和 ≥ 2tm+1)
由上面证明可得:L[i] − tj ≤ L∗
又∵ 2tm+1 ≤ L∗ ⇒ tj ≤ (1/2)L∗
L∗ = L[i] = (L[i] − tj) + tj ≤ (3/2)L∗
∴ L[i] ≤ (3/2)L∗
但其实 2/3 倍近似并不是紧密的,Graham 在1969年,计算出 LPT Rule 是负载均衡问题的一个 4/3 近似算法。因此 4/3 倍近似才是紧密的。
❸带权顶点覆盖问题
掌握带权重的顶点覆盖问题的定价算法(Pricing method),证明该方法能得到一个2倍近似解;
理解带权重的顶点覆盖问题的整数线性规划(Integer linear programming)模型如何建立的,理解松弛求解方法;
要求会对一个图问题建立整数线性规划模型(以点覆盖问题为例)
问题描述:对于顶点覆盖问题(一个点的集合使得图中所有边至少有一个端点在集合内),带权点覆盖问题中,需要满足这个集合中所有点的权值之和最小。
如下图左边就是一个带权的最小顶点覆盖

➀2倍近似算法-Pricing method
给每条边 e = (i,j) 赋予一个价格 pe ≥ 0 ,任意顶点 i 的权重大于等于与其邻接的所有边价格总和:∑e=(i,j) pe ≤ wi
公平引理:对于任意顶点覆盖集合 S 和任意公平价格 pe ,有∑e pe ≤ w(S)

算法:任选一条边 (i, j) 加上代价,这个代价从零开始,且这个代价的最大值小于 i 和 j 节点的权值。显然,这个边权值的最大值取决于两个端点权值的最小值,我们认为当边权值与点权值相等时,对应的那个点是紧的。把所有紧的点找出来即为顶点覆盖。
定价法求解点覆盖问题,举例如下:
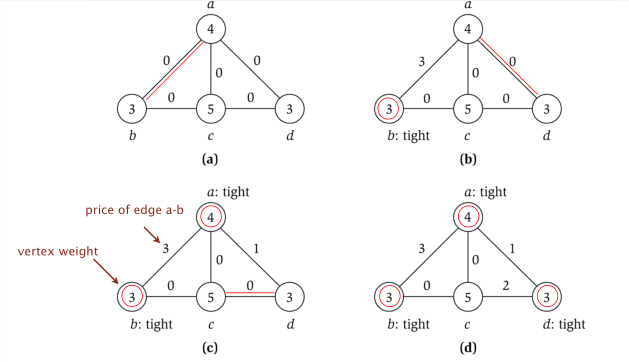
上图中,最后 tight 的点 {a, b, d},即为最小的带权点覆盖,权为 10
2倍近似度证明:
设 S 为算法终止时所有紧节点的集合。易得 S 是顶点覆盖(反证:如果某条边没有被覆盖到,则其两个端点都没有覆盖很紧,算法不会终止)
w(S) 等于所选的节点的权值之和,等于所选节点所对应的边权之和,可以把它放大到所有节点对应边权之和,这样因为一条边 (u, v) 在 u 上算过一次后还要在 v 上算一次,所以等于边权和的两倍。再由上面公平引理可得。

∴ 定价算法是2倍近似算法
➁2倍近似算法-ILP
对每一个点 i ,用 bool 变量 xi 表示其是否在点覆盖集合中。
- xi=0,表示点 i 不在点覆盖中;
- xi=1,表示点 i 在点覆盖中。
因此,整数规划带权点覆盖问题转换为:

如果 x* 是 ILP 的最优解,那么 S= { i∈V|xi*=1 }是最小权重顶点覆盖。
点覆盖的整数规划是一个NP难问题,因此我们希望能找到它的近似算法,牺牲准确度以快速求解。很容易想到把它转化为线性规划问题(LP),并找到它的近似程度。建立如下线性规划,与整数线性规划区别在于第三式。

线性规划的约束条件不如整数规划苛刻,所以线性规划(LP)的最优解 ≤ 整数规划(ILP)的最优解。
但会带来一个问题,加入点覆盖集合中的点 i 其 xi 极有可能是分数,会呈现如下形式
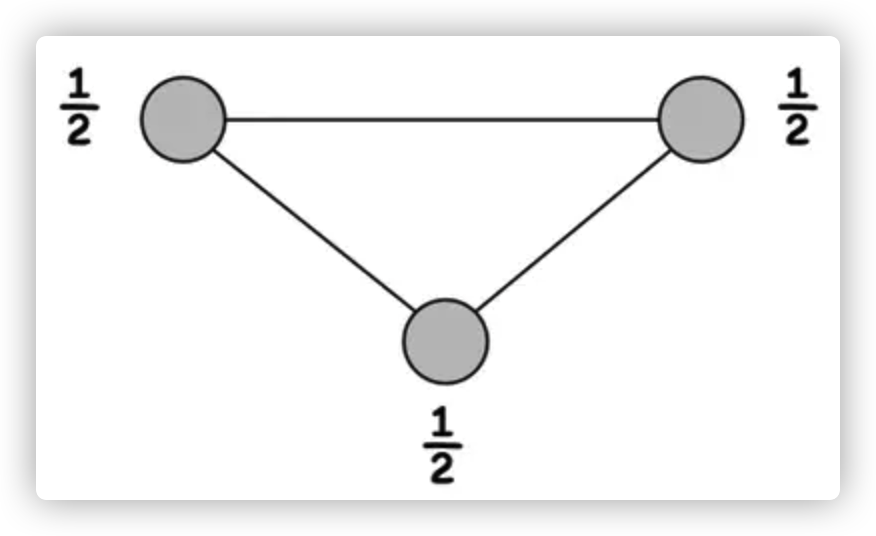
定理: 如果 x* 是 LP 的最优解,那么点覆盖S={i∈V|xi* ≥ 1/2},且是准确解的2倍近似。
2倍近似度证明:
对于边 (i,j) ∈ E,点覆盖中有 xi* + xj* ≥ 1,则 xi* ≥ 1/2 或 xj* ≥ 1/2 ⇒ 边 (i,j) 被覆盖
设ILP点覆盖的最优顶点覆盖为 S* ,有
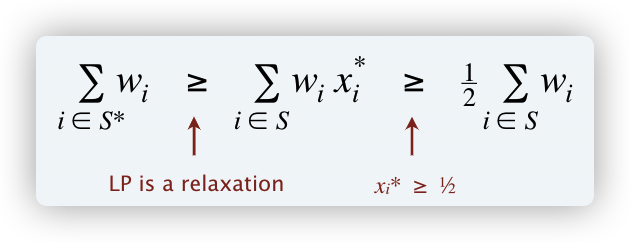
第一个不等式:根据整数规划的最优解不小于线性规划这一性质放缩;
第二个不等式:xi* ≥ 1/2
⇒∑i∈S Wi ≤ 2∑i∈S* Wi
∴ 整数规划是2倍近似算法
❹01背包问题
。。。
❺真题练习
➀题目1
(2020)给定正整数集合 A = {a1,a2,a3,…,an} 和正整数 b,b ≥ max {a1,a2,a3,…,an}。当集合 A 的子集 S∈A 中的元素之和小于等于 b 时,即 ∑ai∈S[i] ai≤b,我们称 S 为可行集。请寻找元素之和最大的可行集 S 。例如,A = {8,2,4},b= 11,则最优的可行集为 S = {8,2},最优解为 8+2=10 (10分)
(1)下面是求解这个问题的算法。集合 S 初始为空集;按照下标 i 从小到大的顺序依次考察集合 A 中的每个整数 ai,如果 αi + ∑ak∈S ak<b ,则将 ai 添加集合 S 中,即 S = S U {ai}。证明这个算法不是1/2倍近似算法。(3分)
设集合 A = {1,4},b = 4
根据该算法求得可行集 S = {1} ,解为 ∑S = 1
而最优可行解 S* = {4},最优解 ∑S* = 4
⇒ ∑S = (1/4)∑S* < (1/2)∑S*
∴该算法不是1/2倍近似算法
(2)为该问题设计O(nlogn)时间复杂度的近似算法,并证明该算法是1/2倍近似算法(7分)
在 (1) 中 所给算法基础上对集合 A 进行降序归并排序[O(nlogn)]
即: a1>a2>a3>…>ak>ak+1>…>an
证明:设 ak 为可行集最后一个元素
ak ≥ ak+1 ⇒ ∑S ≥ ak+1 ——①
ak 为可行集最后一个元素 ⇒ ∑S ≥ b - ak+1 ——②
①+② : ∑S ≥ (1/2)b ,再又 b ≥ ∑S*
⇒∑S ≥ (1/2)∑S*
∴ 该算法是 1/2 倍近似算法
➁题目2
(2018)叙述带权重的点覆盖问题的竞价法(Pricing method)的步骤。
答:任选一条边 (i, j) 加上代价,这个代价从零开始,且这个代价的最大值小于 i 和 j 节点的权值。显然,这个边权值的最大值取决于两个端点权值的最小值,我们认为当边权值与点权值相等时,对应的那个点是紧的。把所有紧的点找出来即为顶点覆盖。
➂题目3
(2019)简单证明定价算法(Pricing method)求解带权重的点覆盖(Weighted Vertex Cover)问题是2倍近似的。
答: S 为算法终止时所有紧节点的集合。易得 S 是顶点覆盖(反证:如果某条边没有被覆盖到,则其两个端点都没有覆盖很紧,算法不会终止)
w(S) 等于所选的节点的权值之和,等于所选节点所对应的边权之和,可以把它放大到所有节点对应边权之和,这样因为一条边 (u, v) 在 u 上算过一次后还要在 v 上算一次,所以等于边权和的两倍。再由上面公平引理可得。
∴ 定价算法是2倍近似算法
➃题目4
为最大独立集问题建立一个整数规划模型。 (5分)
参考答案:
目标函数: max ∑ xi (2分)
条件:对每一条边(i,j), xi + xj ≤ 1 (2分)
对每个顶点i, xi = 0,1 (1分)
⑨历年期末真题
题目来源于课堂,由小简拍下来,手工整理,因此或多或少存在一些错误,望谅解!
❶选择题
样题
一、判断下列陈述的对错(共20分,共 10题,每题2分)
- 一个计算问题的输入是n个数字a1,a2,…,an。如果这个问题存在一个运行时间为O(ann10)的算法,则这个问题可以在多项时间内被计算机求解。
(F) - 如果存在一个从问题A到问题B的多项式时间归约(Polynomial reduction),且问题A是NP难的,则可知问题B也是NP难的。
(T) - 一个2倍的近似算法一定会有在一个问题上得到正好是最优解的两倍的解。
(F) - 如果存在一个NP问题有多项式时间算法,则P=NP。
(F) - 一个图上的最大网络流是唯一的。
(F) - 当图中的顶点个数是常数时,最大独立集问题(Maximum Independent Set Problem)是多项式时间可解的.
(T) - 这里有两个解决排序问题的分而治之算法:算法A递归将需要排列的数字均分成2份,分别排序后再合并。算法B递归将需要排列的数字均分成3份,分别排序后再合并。从渐进分析的角度来看,算法B比算法A要快。
(F) - 在并行计算中,一个计算问题能在CREW PRAM模型下O(n)处理器O(n3)时间被解决,则也可以在EREW PRAM模型下O(n)处理器O(n3)时间被解决.
(T) - 对于任意一个动态规划算法,其使用的空间一定不比它使用的时间要大。
(T) - 求一个图中两个点间最长路径的问题是属于NP的,但是求一个图中两个点间最短路径的问题则不是属于NP的。
(F)
2018
一、判断下列陈述的对错(共30分,共 15题,每题2分)
- 任何一个NP问题能被多项式时间算法解决则所有NP问题都能在多项式时间内被解决。
(F) - 可以用如下方法来证明某结论X成立:先假设X不成立,在此假设基础上推导出X成立,则可以证明X成立。
(T) - 一个2倍近似算法得到的解总比一个4倍近似算法得到的解更好。
(F) - 问一个图是否存在一个大小为k的点覆盖,很容易证明该问题是属于NP的;但是,问一个图是否不存在一个大小为k的点覆盖,却是很难证明这个问题是否属于NP。
(T) - 一个问题A可以多项式时间规约到一个NP完全问题B,那么问题A可能属于P也可能属于NP完全。
(T) - 一个3倍近似算法如果对任何问题实例找到的解都在最优解的1.5倍以内,则这不是一个3倍近似率的算法。
(F) - 对某个问题以前最好的算法运行时间为O(n3),新给出的算法运行时间为O(n2)。那么在该问题上运行时间改进了O(n)。
(F) - 对于判断一个整数w是不是素数的问题,一个运行时间为O(w2)的算法是多项式时间算法,而一个运行时间为O(2w)的算法是指数时间算法。
(F) - 证明一个算法不是2倍近似算法只需要构造一个例子使得在该例子上返回的解超过2倍最优解即可。
(T) - 如果一个图上两点间的最大流是唯一的,则可以确定这两点间的最小割也唯一。
(F) - 证明把问题A规约到了问题B,只需要证明对于任意问题A的实例 I 都可以构造一个问题B的实例 I’ 使得实例 I’ 的任意解可以构造出实例 I 的一个解。
(F) - 动态规划算法有可能是多项式时间的也有可能是指数时间的。
(T) - 一个二分图如果包含奇数个顶点,则这个图一定不存在一个哈密尔顿圈。
(T) - 不属于NP中的问题一定不存在多项式时间算法。
(F) - 对于每秒可以处理100万条基本指令的计算机,一个运行时间为 1.5n 的算法在 n=100 的例子上可以1年内计算完。
(F)
2019
一、判断下列陈述的对错(共20分,共 10题,每题2分)
- 在背包问题中,如果规定所有输入的数值(包括背包的大小和各个物品的价值和体积)都是长整型数据,则动态规划算法可以在多项式内求解。
(T) - NP问题是目前没有找到多项式时间求解算法的判定问题集合。
(F)- NP问题是所有可用多项式时间算法验证其猜测准确性的问题的集合。
- 线性规划问题可以多项式求解,但是整数规划问题是NP-hard问题。
(T)- 整数规划是NPC,NPC ⊆ NP-hard
- 找出一个图的哈密尔顿圈和判定该图是否存在哈密尔顿圈,这两个问题在不考虑多项式时间的差异基础上计算难度是相当的。
(T) - 一个网络的最大流的值一定不大于任意一个割集的容量。
(T)- 网络的最大流应等于最小割集容量。
- 如果我们不能在一个流网络中找到一条从S到T的路径,使得路径上所有边的流量都小于该边的容量,则我们得到了该网络上S到T的最大流。
(F) - 证明一个算法不能达到2倍近似解只需要找到一个例子在该例子上得到的解要差于2倍最优解即可。反之,无论给出多少个例子在这些例子上都能得到优于2倍最优解的解也不能说明这个算法拥有2倍近似率。
(T) - 如果一个问题A存在多项式算法可以推导出所有NP里的问题都存在多项式算法,那么可知问题A是NP完全的
(T) - 问一个数是不是个合数,很容易证明该问题是属于NP的:但是问一个数是不是素数,这个问题却是很难证明是否属于NP的。
(F)- 都是 NP
- 因为判断一个图是否存在哈密尔顿圈问题是属于NP的,所以判断一个图是否不存在哈密尔顿圈问题也是属于NP的。
(F)- 不存在是 Co-NP
2020
一、命题正确填T,命题错误填F(2分题x10题=20分)
- 如果f(n) = O(g(n)),则有log2f(n) = O(log2g(n))。
(T) - 一个P类问题可以多项式时间归约到任意一个NP完全问题。
(T) - 斐波那契数列定义f(1)=f(2)=1,当n≥3时,f(n)=f(n-1)+f(n-2)。求解该数列第n个数f(n)的自顶向下的分治递归算法是指数时间算法,求解该数列第n个数f(n)的自底向上的动态规划算法也是指数时间算法。
(T)- 考虑输入规模
- 给定边上容量均为正整数的流网络,网络流 f 的 ∆ 剩余网络 Gf(∆) 中不存在从源点 s 到终点 t 的有向路径,如果 ∆ = 1 则 f 是该网络的最大流。
(T) - 给定求解负载均衡问题的 2 倍近似算法 A 和 3/2 倍近似算法 B,对于该问题的任意实例,算法 B 得到的近似解都比算法 A 得到的近似解更接近最优解。
(F) - 给定带权重的顶点覆盖问题,利用整数规划模型求得的顶点覆盖的最小权重之和为 x ,利用松驰化的线性规划模型求得的顶点覆盖的最小权重之和为 y,则总有x≤y。
(F) - 判断给定简单无向图中是否不存在哈密尔顿圈是 NP 完全问题。
(F)- co-NP
- 给定两个判定问题 A 和 B ,如果 A ≤p B,B ≤p A,并且 A ∈ NPC,那么 B ∈ NPC。
(F)- A 是否是 NP
- 如果判断问题 A 存在多项式时间的求解算法,那么问题 A 是 P 问題,不是NP问题。
(F)- 是 P 肯定是 NP
- 给定两个判定问题 A 和 B,A ≤p B 的意思是说,可以通过多项式次的调用求解问题 B 的方法来求解问题 A,也就是说,如果问题 B 可以多项式时间求解,则问题 A 可以多项式时间求解。
(T)
❷计算题&简单题
样题
二、计算题(共9分,共3题,每题3分)
求如下有向图中的一个最长路径,要求给出路径和路径长度的值。
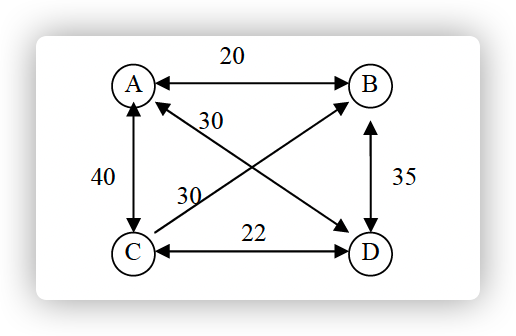
参考答案: CADB,长度:40+30+35=105
- 如下可满足问题(SAT)是否有解,若有解该如何给变量赋值:
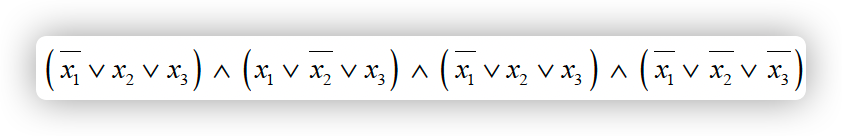 参考答案:x1=1,x2=1,x3=0或者x1=0,x2=0,x3=0,答案正确即可给分。(说明:本题存在多种解,如x3=1, x1和x2中有一个0,这种情况还是有解。只要任给出一种解就给分)
参考答案:x1=1,x2=1,x3=0或者x1=0,x2=0,x3=0,答案正确即可给分。(说明:本题存在多种解,如x3=1, x1和x2中有一个0,这种情况还是有解。只要任给出一种解就给分)
有一些区间段 (0,3), (2,4), (3,6), (5,7), (1,4), (3,5), (6,8),(7,9),找出其中个数最多的一组相容的区间段(两个区间相容当且仅当两个区间的交集为空)。
参考答案:(0,3),(3,5),(5,7),(7,9)
2018
二、计算题和简答题,计算题可以只写答案不写过程(共16分,共4题,每题4分)
一个数的序列中排在前面的数比排在后面的数要大的话则称为一对逆序。问下面这个序列中存在多少对逆序:5,10,7,9,13,1,8,4,12,2,6,3,11,14。(4分)
答:4+8+5+6+8+0+4+2+4+0+1+0+0=42
负载均衡(Load Balancing)问题要求将一些工作放到一些机械上进行处理,每个工作有一个固定的需要处理的时间。算法的思想如下:将任务按任意一个次序进行排序,再依次将任务分配到负载最轻的机器上。简单证明该算法是2倍近似的。(4分)
答:设机器 i 是瓶颈机器(则 L[i] 为贪心解),任务 j 是最后一个在机器 i 上调度的任务(在调度前,机器 i 的工期是最小的)我们在考虑放入最后一个任务前,根据我们放置的规则,该机器 i 是所有机器中耗时最短的(L[i] − tj ≤ L[k]),该机器此时的用时(L[i] - tj)是低于除掉最后一个任务 j 后的平均时长(1/m)∑kL[k],更低于所有任务的平均时长(1/m)∑jtj(引理2);再根据引理1,最后一个任务应该是小于最优解的。
L[i] − tj ≤ L[k],对任意 1 ≤ k ≤ m
L[i] − tj ≤ (1/m) ∑kL[k] ≤ (1/m)∑jtj ≤ L∗
L[i] = (L[i] − tj) + tj
L[i] − tj ≤ L∗ ,tj ≤ L∗
∴ L[i] ≤ 2L∗
叙述带权重的点覆盖问题的竞价法(Pricing method)的步骤。(4分)
答:任选一条边 (i, j) 加上代价,这个代价从零开始,且这个代价的最大值小于 i 和 j 节点的权值。显然,这个边权值的最大值取决于两个端点权值的最小值,我们认为当边权值与点权值相等时,对应的那个点是紧的。把所有紧的点找出来即为顶点覆盖。
在一个无向图中给出两个顶点对(s1,t1)和(s2,t2),需要求出同时从 s1 流向 t1 的流加上从 s2 流向 t2 的流的和达到最大。有一个算法是:添加一个新的顶点 s 仅连接 s1 和 s2 ,边的容量无穷大;再添加一个新的顶点 t 仅连接 t1 和 t2 ,边的容量无穷大;然后求 s 到 t 的最大流。请分析这个算法的正确性(认为它是错的就给出理由,认为它是对的则也给出说明并分析其时间复杂性)。(4分)
答:错误。(2分)
因为这样做将会包含从 s1 到 t2 的流和从 s2 到 t1 的流。(2分)
2019
(2019)计算题和简答题,计算题可以只写答案不写过程(共24分,共6题,每题4分)
证明一个有奇数个顶点的二分图一定不存在哈密尔顿圈。(4分)
设G=(V,E)是无向图,如果 V 可以划分为子集 X 和 Y,使得对所有的e=(u,v)∈E, 都有 u 和 v 分属于 X 和 Y,则称 G 是二分图,下图便是一个二分图。

(数学归纳法)
当n = 3个顶点时候,明显不存在哈密尔顿圈
假设当 n = k ,k为奇数时,不存在哈密尔顿圈
当n = k + 2 时,假设存在哈密尔顿圈
由于是二分图,圈中相邻顶点属于不同子集,假设ABCD是圈中四个相邻的顶点,则AC在二分图的一个子集 X 中,BD 在子集 Y 中,那么 AD 有边相连,取掉BC两点,链接AD,仍然存在哈密尔顿圈,而剩下点仍然是二分图,与假设矛盾,因此一个有奇数个顶点的二分图一定不存在哈密尔顿圈
在一个图中给出 x 对顶点 (s1,t1),(s2,t2),…,(sx,tx) 求 (si,ti) 这 x 对顶点之间同时能达到的最大流(si 只能流向 ti)。分析如下算法的正确性:添加一个顶点 s 连接所有 si ,且 s 到 si 的容量无穷大;添加另一个顶点 t 连接所有 ti,且 t 到 ti 的容量无穷大;则只需求 s 到 t 之间的最大流。(4分)
答:正确
如下可满足问题(SAT)存在几组使得其值为真的赋值?给出具体的赋值方案。(4分)

答:x1=1,x2=1,x3=0,x4=0
- 求如下有向图中一条从 A 到 D 的最长路径。要求给出路经和路经长度的值。(4分)
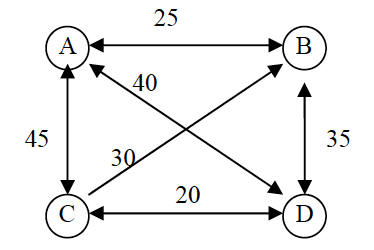
参考答案: CADB,长度:45+40+35=120
给出如下一个带权重的图,图中每个顶点上的数字为该项点的权重,找出图中一个独立集(一组顶点之间没有任何边称为一个独立集)使得该独立集中顶点的权重之和达到最大。(4分)
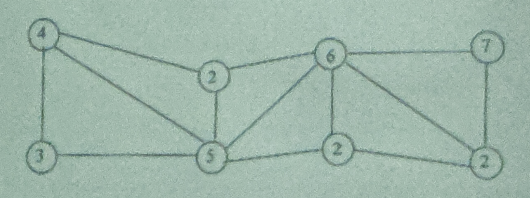
答:3 + 2 + 2 + 7 = 14
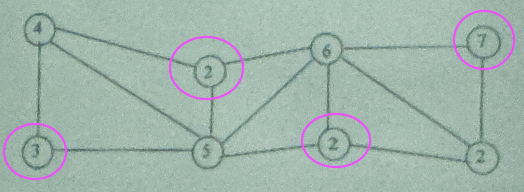
求解下面两个递归关系式(4分)
(1)f(n) = 9f(n/3) + O(n2)
答:利用主定理求解
a = 9,b = 3,f(n) = n2,nlogba = nlog39 = n2 = f(n)
所以T(n) = Θ(nlogbalogn) = Θ(n2logn)
(2)f(n) = 3f(n-3) + O(1)
答:利用直接展开法求解
详细解题步骤请参考前面分治算法-真题练习-题目一-第2问,这里不再赘述。
2020
(2020)简答和计算题,无需计算过程,直接给出答案即可(5分题 x 6题 = 30分)
如果 P ≠ NP 时,请给出 P,NP,NPC 这3个集合两两之间的关系。
答:如果 P ≠ NP 时,P ⊆ NP,NPC ⊆ NP,P ≠ NPC
请用下图右侧所示的4种不同形状的L型骨牌,覆盖下图左侧给定棋盘上除阴影方格以外的所有方格,且任何2个L型骨牌不得重叠覆盖,4种L型骨牌数量均不设限制。

答:

给定整数序列{a1,a2,a3,…,an},如果 i < j 但是 ai > aj逆序。则(ai, aj)称为一对逆序,请计算整数序列{32,15,48,17,21,24,57,12,36}中有多少对逆序。
答:5+1+5+1+1+1+2+0+0=16
给出下列2个递归关系式的渐近界。
(1)T(n) = 4T(n/2) + n1.9(logn)5答:a = 4,b = 2 ,f(n) = n1.9(logn)5,nlogba = nlog24 = n2 > f(n)
因此 T(n) = Θ(nlogba) = Θ(n2)
(2)T(n) = T(2n/3) + 1
答:a =1,b = 3/2 ,f(n) = 1,nlogba = n0 = 1 = f(n)
所以T(n) = Θ(nlogbalogn) = Θ(logn)
给定整数序列(23,4,-2,30,- 63,47,26,-53,58,97,-93,-23,84,-15,6),求这个序列的最大连续子序列之和,并给出相应的子序列。例如序列(-20,11,-4,13,-5,-2)的最大连续子序列之和为 20 = sum(11, 4,13)。
答:175 = sum(47,26,-53,58,97)
将下列6个函数按渐近增长率由低至高进行排序。
f1(n) = log100n + logn100,f2(n) = 2019n3 +3n,f3(n) = 2nlogn +lognnf4(n) = 2019√n2019 ,f5(n) = n! + 100nn + n100,f6(n) = log(3nlogn)
答:
f1(n) = log100n + 100logn = Θ(log100n),f2(n) = 2019n3 +3n= Θ(3n)
f3(n) = nn +lognn = Θ(nn),f4(n) = Θ(n1009.5)
f5(n) = Θ(nn),f6(n) =nlog3 + loglogn = Θ(n)
显然 f6(n) <f4(n) < f2(n) < f3(n) = f5(n)
f1(n) ,f6(n)同时取对数 ,因此 f1(n)< f6(n)
综上所述:f1(n)< f6(n)< f4(n) < f2(n) < f3(n) = f5(n)
❸解答题
辅以每个章节的真题练习部分食用,效果更佳,又狂肝了一波,睡觉睡觉,狗命要紧。。。
2018
三、将下列6个函数按渐近增长率由低至高进行排序,要求写出判断依据(8分)

f1(n) = √n + log100n = O(√n)
f2(n) = 2logn * 2loglogn = nlogn
f3(n) = 100logn + nlog3 = O(n)
f4(n) = O(3n)、f5(n) = 100log2n、f6(n) = O(n!)
(1)显然 f3(n) < f2(n) < f4(n)<f6(n)
(2)f5(n) 是对数的幂,f1(n) 是幂函数,因此 f5(n)< f1(n)
综上所述: f5(n) < f1(n)< f3(n) < f2(n) < f4(n)<f6(n)
四、求如下有向图中s和t间的最小割,其中边上的数字表示边的容量。要求给出最少两个中间计算步骤(8分)。
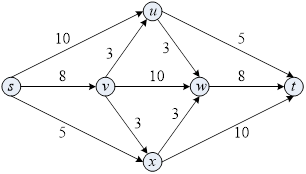
将最小割问题转化为最大流问题
1增广路径:(s, u, t),流量值+5
2增广路径:(s, x, t),流量值+5
3增广路径:(s, v, w, t),流量值+8
4增广路径:(s, u, w, v, x, t),流量值+3

最小割为**[ {s, u},{w, v, x, t} ]** 容量为 21
五、对某个输入大小为n的问题有如下三个分而治之算法:
(1)算法1将该问题分成5个子问题,子问题大小为n/5,将子问题的解合并得到上一级问题的解需要O(n2)时间;
(2)算法2将该问题分成4个子问题,子问题大小为n/2,将子问题的解合并得到上一级问题的解需要O(n)时间;
(3)算法3将该问题分成2个子问题,第一个子问题大小为n/3,第二个子问题大小为2n/3,将子问题的解合并得到上一级问题的解需要O(n)时间。
请分析以上3个算法的运行时间。(6分)
答:
(1) T(n) = 5T(n/5) + n2
a = 5,b = 5 ,f(n) = n2,nlogba = nlog55 = n < f(n)
再判断是否满足不等式:af(n/b) ≤ cf(n),代入f(n) = n2
n2/5和cn2,当 c ≥ 1/5 即可满足 af(n/b) ≤ cf(n) 的关系
因此 T(n) = Θ(f(n)) = Θ(n2)
(2) T(n) = 4T(n/2) + n
a = 4,b = 2 ,f(n) = n,nlogba = nlog24 = n2 > f(n)
存在 f(n) = O(nlogba-ε) = O(nlog24-2),ε = 2
因此 T(n) = Θ(nlogba) = Θ(n2)
(3) T(n) = T(n/3) + T(2n/3) + n
T(n) = 3T(n/3) + n
a = 3,b = 3 ,f(n) = n,nlogba = nlog33 = n = f(n)
因此 T(n) = Θ(nlogbalogn) = Θ(nlogn)
六、对于三着色问题(对一个图的顶点进行三种颜色着色使得相邻两个点的颜色不一样),若存在一个多项式时间算法判断一个图是否可以三着色,则存在一个多项式时间算法对可以进行三着色的图找到一个可行的三着色。 (8分)
答:
解法一:不断加边进去然后进行判断,直到不能加边为止。这样三种颜色的点就是图中三个独立集。
解法二:不断将两个不相邻的点合并成一个点然后进行判断,直到不能再合并为止。最后剩下三个点。
七、给出一个图和一个整数k,问是否可以在这个图上删除k个点使得剩余图上没有三角形(含有3个顶点的圈)。证明这个问题是NP完全的。 (10分)
答:从点覆盖问题规约过来(2分)。
对于一个点覆盖实例 G,构造一个该问题实例 G’;(1分)
对 G 中每一条边 ab,都添加一个新的顶点 c 然后连成三角形 abc。(4分)
说明 G 存在大小为 k 的点覆盖当且仅当 G’ 存在一个大小为 k 的解。(3分)

(1)令计算**A1 x A2 x A3 x … x An*所需要的最少乘法次数为m*[i, j]
则递归关系式为
(2)
| m(i, j) | j = 1 | j = 2 | j = 3 | j = 4 | j = 5 |
|---|---|---|---|---|---|
| i = 1 | 0 | 1440 | 3360 | 4000 | 5856 |
| i = 2 | / | 0 | 2400 | 2800 | 4800 |
| i = 3 | / | / | 0 | 1600 | 2880 |
| i = 4 | / | / | / | 0 | 3200 |
| i = 5 | / | / | / | / | 0 |
将对应m(i,j)的断开位置k记为s(i,j)
| s(i, j) | j = 1 | j = 2 | j = 3 | j = 4 | j = 5 |
|---|---|---|---|---|---|
| i = 1 | / | 1 | 2 | 2 | 2 |
| i = 2 | / | / | 2 | 2 | 2 |
| i = 3 | / | / | / | 3 | 4 |
| i = 4 | / | / | / | / | 4 |
| i = 5 | / | / | / | / | / |
s(1,5) = 2 因此矩阵链在A2和A3之间断开,则加括号方式为 (A1A2)(A3A4A5)
s(3,5) = 4 因此矩阵链在A4和A5之间断开,则加括号方式为 (A1A2)((A3A4)A5)
最优加括号方式为**(A1A2)((A3A4)A5)**
2019
四、简单证明定价算法(Pricing method)求解带权重的点覆盖(Weighted Vertex Cover)问题是2倍近似的。
答: S 为算法终止时所有紧节点的集合。易得 S 是顶点覆盖(反证:如果某条边没有被覆盖到,则其两个端点都没有覆盖很紧,算法不会终止)
w(S) 等于所选的节点的权值之和,等于所选节点所对应的边权之和,可以把它放大到所有节点对应边权之和,这样因为一条边 (u, v) 在 u 上算过一次后还要在 v 上算一次,所以等于边权和的两倍。再由上面公平引理可得。
∴ 定价算法是2倍近似算法
五、证明独立集问题(给定一个图,问图中是否存在k个顶点的子集,使得这个子集中任意两个顶点之间在原图中都不存在边)是NP完全的。
答:从点覆盖问题规约过来
⇒
S 是图 G 的任一独立集
则任意边 (u,v) ∈ E,有u ∉ S 或 v ∉ S 或 u,v 都 ∉ S;那么 u∈V-S 或 v∈V-S 或 u,v 都 ∈ S
所以图的任意边 (u,v) 至少有一个顶点在集合 V-S 中,即集合 V-S 是一个顶点覆盖
⇐
V-S 是图 G 的任一顶点覆盖
则任意边 (u,v) ∈ E,有 u ∈ V-S 或 v ∈ V-S 或 u,v 都 ∈ V-S ;那么 u ∉ S 或 v ∉ S 或 u,v 都 ∉ V-S
所以图的任意边至少有一个端点不在集合 S 中,集合 S 是一个独立集
∴ Vertex-Cover ≤p Independent Set,即独立集问题NP完全的
六、求如下有向图中s和t间的最小割,其中边上的数字表示边的容量,要求给出最少两个中间计算步骤(8分)。

将最小割问题转化为最大流问题
1增广路径:(s, u, v, t),流量值+10
2增广路径:(s, y, z, t),流量值+10
3增广路径:(s, w, x, t),流量值+18
4增广路径:(s, y, x, w, v, t),流量值+4
最小割为**[ {s,y,z},{w,x,u,v,t} ]** 容量为 10+10+18+4=42
七、证明图二着色问题(是否能给一个图的顶点进行两种颜色着色使得任意两个相邻顶点都有不同的颜色)是属于P的。(8分)
如果只用2种颜色,那么确定一个顶点的颜色之后,和它相邻的顶点的颜色也就确定了。因此,选择任意一个顶点出发,依次确定相邻顶点的颜色,就可以判断是否可以被2种颜色着色了。这个问题如果用深度优先搜索的话,能够简单地实现。
设 p(j) 为与工作 j 相容的最大的工作 i 且 i < j 。OPT(j)表示前 j 个工作 ( 1,2,3,…,j )的最大的工作权重。则递归关系式为:
依据递推公式,计算出 p(j)、OPT(j)
因为 OPT(17) = 50 ,因此最大权重之和为 50
OPT(17) = OPT(16) = OPT(15) = 50 ,选择活动 15,p(15) =13;
OPT(13) = OPT(12) = 45 ,选择活动 12,p(12) = 7;
OPT(7) = OPT(6) = 25 ,选择活动 6,p(6) = 3;
OPT(3) = 18 ,p(3) = 0,选择活动 3,且选择完毕。
因此最优活动子集为 3、6、12、15
九、对于三着色问题,若存在一个多项式时间算法判断一个图是否可以三着色,则存在一个多项式时间算法对可以进行三着色的图找到一个可行的三着色。
解法一:不断加边进去然后进行判断,直到不能加边为止。这样三种颜色的点就是图中三个独立集。
解法二:不断将两个不相邻的点合并成一个点然后进行判断,直到不能再合并为止。最后剩下三个点。
2020
三、给定任意连通的无向有权图G,每条边上的权重c(e)都是不同的整数。G的最小生成树是G的一个连通的、无圈的、边的权重之和最小的包含图中所有顶点的子图。如果e*是图G上权重最小的边,那么一定有一棵图G的最小生成树T包含边e*。请问这个命题是否正确,如果正确,请给出证明。如果不正确,请给出反例。(8分)
答:正确
四、工厂s生产的商品通过下图表示的运输网络运送到市场t,网络中边上的数值表示单位时间可以通过该边的商品数量的上限,求单位时间内从工厂s到市场t能运送的最大商品总量。要求给出求解过程(给出每条增广路径及其增加的流量值)。(8分)
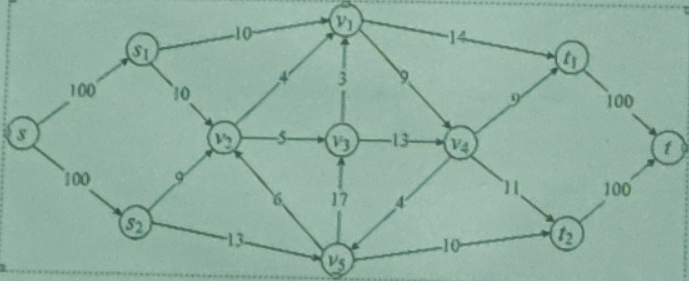
1增广路径:(s, s1, t, v1, t1, t),流量值+10
2增广路径:(s, s2, v5, t2, t),流量值+10
3增广路径:(s, s1, v2, v3, v4, t1, t),流量值+5
4增广路径:(s, s2, v2, v1, t1, t),流量值+4
5增广路径:(s, s2, v5, v3, v4, t2, t),流量值+3
最大流 10 + 10 + 5 + 4 + 3 = 32
五、若给定两个序列 X = (x1,x2,x3,…,xn) 和 Y = (y1,y2,y3,…,ym) 、如果对于所有 j = 1,2,3,.,m-1 有 yj < yj+1 并且存在一个严格递增下标序列 (i1,i2,i3,…,ik) 使得对于所有 j = 1,2,3,…,m 有 yj = xi ,则称 Y 是 X 的单调递增子序列。(8分)
(1)给出动态规划算法求给定序列最长单调递增子序列长度的递归关系式。
对于数组序列 Yi ( 1 ≤ i ≤ m ) ,令 dp[i] 表示以第 i 个数 Yi 结尾的最长递增子序列的长度。那么,我们考虑以第 i 个数 Yi 结尾的最长递增子序列,它在这个序列中的前一个数 Yj ( 1 ≤ j < i ),所以,如果我们已经知道了 dp[j],那么就有 dp[i] = dp[j] + 1 。显然,我们还需要满足 Yj < Yi,这个递增的限制条件。
递归关系式:dp[i] = maxj=1( dp[j] ∣ Yj < Yi ) + 1
(2)求解序列(a,l,g,o,r,i,t,h,m)的最长单调递增子序列,画出求解过程表格。

最长单调递增子序列:a,l,o,r,t 或 a,g,o,r,t
六、判定问题A:给定包含奇数个结点的简单无向图,判断其是否包含哈密尔顿圈;判定问题B:给定包含偶数个结点的简单无向图,判断其是否包含哈密尔顿圈;证明问题A可多项式归约到问题B。
设奇数个节点的简单无向图为 G。
构造方法为:随机在 G 中选择一个点 u,假设这个点 u 存在 k 条边,我们断开一条边添加一个点 w,将 w 连接到断开边的两个顶点,这样便构造了一个偶数个顶点的图 G’,依次断开这 k 条边加点,这样我们可以构造 k 个 G’ ,则在这 k 个 G’ 中肯定能找到一个 G’ 存在一条边 (u,v) 是在哈密尔顿圈中,则这个图 G’ 肯定满足奇数结点的简单无向图包含哈密尔顿当且仅当偶数结点的简单无向图包含哈密尔顿。
大家可以在评论区留下你想法,一起交流!
七、如果存在判断任意简单无向图是否存在哈密尔顿圈的多项式时间算法,请你设计构造任意简单无向图的哈密尔顿圈(如果存在的话)的多项式时间算法。
算法:
//设该判断算法为A
S 初始化为空集;
首先算法 A 判断图 G 中是否存在哈密尔顿圈,如果不存在则算法结束,如果存在则继续寻找哈密尔顿圈;
For every edge e in G {
如果 G – {e}中不存在哈密尔顿圈,则将 e 添加到集合 S 中;
否则 G = G – {e};
}
最终所得集合 S 中的所有边构成图 G 的哈密尔顿圈。
八、给定正整数集合 A = {a1,a2,a3,…,an} 和正整数 b,b ≥ max {a1,a2,a3,…,an}。当集合 A 的子集 S∈A 中的元素之和小于等于 b 时,即 ∑ai∈S[i] ai≤b,我们称 S 为可行集。请寻找元素之和最大的可行集 S 。例如,A = {8,2,4},b= 11,则最优的可行集为 S = {8,2},最优解为 8+2=10 (10分)
(1)下面是求解这个问题的算法。集合 S 初始为空集;按照下标 i 从小到大的顺序依次考察集合 A 中的每个整数 ai,如果 αi + ∑ak∈S ak<b ,则将 ai 添加集合 S 中,即 S = S U {ai}。证明这个算法不是1/2倍近似算法。(3分)
设集合 A = {1,4},b = 4
根据该算法求得可行集 S = {1} ,解为 ∑S = 1
而最优可行解 S* = {4},最优解 ∑S* = 4
⇒ ∑S = (1/4)∑S* < (1/2)∑S*
∴该算法不是1/2倍近似算法
(2)为该问题设计O(nlogn)时间复杂度的近似算法,并证明该算法是1/2倍近似算法(7分)
在 (1) 中 所给算法基础上对集合 A 进行降序归并排序[O(nlogn)]
即: a1>a2>a3>…>ak>ak+1>…>an
证明:设 ak 为可行集最后一个元素
ak ≥ ak+1 ⇒ ∑S ≥ ak+1 ——①
ak 为可行集最后一个元素 ⇒ ∑S ≥ b - ak+1 ——②
①+② : ∑S ≥ (1/2)b ,再又 b ≥ ∑S*
⇒∑S ≥ (1/2)∑S*
∴ 该算法是 1/2 倍近似算法
2021
考试结束啦,考得一塌糊涂,以下是我的回忆
大题:
渐进增长率排序
矩阵连乘,求最小计算次数和最优加括号方式
贪心算法正确性证明(找零钱)
分治算法(类似2020年L型骨牌覆盖)
网络流(跟2020年的图相似)
归约(3着色归约到k着色)
自归约(支配集)
近似算法(给了一个算法,证明不是1/2倍算法)
最大连续子序列(给出递归关系并求解)
⑩总结&感谢
看到这里你已经看完了所有正文部分了,相信你对算法设计也有了大致的了解,还是希望此文或多或少对你产生了一些帮助吧,这也是小简写此文的初衷之一。后面的内容是本文的版本管理记录,记录了小简写此文的过程,然后是本文的参考书籍和参考文章,最后是读者对小简的赞助渠道。(赞助将用于本博客运营【CDN和OBS续费】)
首先感谢各位前辈所写文章,没有他们本文也无法完成,其次自从文章开放以来,收到很多读者对文章错误指正的消息以及收到部分读者的赞助,这里就不一一列出了,小简在此真诚的感谢大家!🙏🙏
最后还想送给读者一句话,慢慢来,比较快!
⑪版本管理
v 1.0(2021-10-17)
- 初步构建算法笔记
基本框架 - 完成
算法引论、算法复杂度、网络流全部章节撰写 - 完成
贪心算法、分治算法、动态规划部分章节撰写
v 1.1(2021-10-21)
- 修复若干
已知错误(感谢@tzj、@whh) - 优化若干
小细节 - 完善
渐近增长率比较习题解答 - 新增
动态规划真题练习 - 新增
任意流与任意割关系
v 1.2(2021-11-12)
- 新增
判断问题和优化问题概念 - 新增
NP完备性理论章节 - 新增
01背包问题 - 完善
动态规划分析 - 新增
近似算法部分章节
v 1.3(2021-11-27)
- 完善
分治算法章节 - 新增
历年期末真题章节 - 完善
近似算法章节 - 完善贪心算法
正确性证明 - 优化整体
文章结构 - 修改若干
已知错误(感谢@whh)
v 1.4(2021-12-07)
- 优化
NP完备性理论章节 - 完善
历年期末真题章节 - 修改若干
已知错误(感谢若干不知名读者)
To Do
- 完善NP完备性理论章节
- 完善近似算法章节
⑫Reference📖
书籍
- 《算法设计》 Kleinberg,J. ,Tardos,E. 著;张立昂,屈婉玲 译
- 《计算机算法设计与分析》王晓东 著
- 《算法图解》 Aditya Bhargava 著 ;袁国忠 译
- 《大话数据结构》程杰 著
贪心算法
- AI产品经理必修——揭开算法的面纱(贪心算法)
- 贪心算法刷完这些题目就够了 - SegmentFault 思否
- 五大经典算法|2.贪心算法 - 张浩在路上
- 活动安排问题-计算机算法_笨手笨脚°的博客-CSDN博客
- 贪心算法的正确性证明
- ACM–贪心算法–活动安排问题_戎码人生-CSDN博客
- 活动安排问题贪心证明_AKGWSB ‘s blog-CSDN博客
- USTC-算法基础-贪心算法
分治
动态规划
- 动态规划—>矩阵连乘问题
- 矩阵连乘问题-动态规划
- 算法之动态规划,问题二:带权重的任务安排问题_我爱加菲猫
- 动态规划算法 | 航行学园
- 动态规划算法_bajiaoyu517的博客
- 算法之动态规划,问题三:0 1 背包问题_我爱加菲猫
- 最长公共子序列问题和最长公共子串问题 - Excaliburer - 博客园
网络流
NP完备性理论
- 算法设计与分析-归约与复杂度的NP问题以及近似算法_lyly1995的博客
- 多项式时间归约 | | 清水寺修行生活记录
- 多项式规约_小菜菜forever的博客-CSDN博客
- 算法设计与分析笔记之独立集问题 - 简书
- 多项式规约——续_小菜菜forever的博客-CSDN博客
- 算法设计与分析笔记之整数规划
- 高级算法 | AdAlgo
近似算法
- 算法设计与分析之近似算法_猿归林的博客-CSDN博客
- 近似算法_小菜菜forever的博客-CSDN博客
- 算法基础 - 简书
- Yang的后花园
- ustc.edu.cn
- 算法设计与分析笔记之近似算法 - 简书
⑬Sponsor❤️
本文是 UESTC 研一 《高级算法设计与分析》课程总结,总结得不一定完善不一定完美,但是从查阅资料,到画图构思,再到文章编写前后也经历了大概一个多月的时间,在这个喧嚣浮躁的时代,个人博客越来越没有人看了,写博客感觉一直是用爱发电的状态。如果你恰巧财力雄厚,感觉本文对你有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用。
| 支付宝 | 微信 |
 |
 |



