论文名称:《Dynamic Searchable Symmetric Encryption》
- 作者:Seny Kamara、Charalampos Papamanthou、Tom Roeder
- 单位:微软研究院、加州大学伯克利分校
- 会议:CCS ‘12: Proceedings of the 2012 ACM conference on Computer and communications【CCF A】
- 时间:2012年10月
| 多关键字 | 模糊搜索 | 可验证 |
|---|---|---|
| ✅ | ❌ | ❌ |
| 动态更新 | 安全性 | 复杂度 |
| ✅ | IND-CKA2 | 亚线性 $O(#f_w)$ |
1、方案简介
任何实用的SSE方案都应该(至少)满足以下属性:亚线性搜索时间、抵御自适应选择关键字攻击的安全性、
紧凑的索引以及有效地添加和删除文件的能力。本文提出了第一个SSE方案来满足上述所有属性。我们方案扩展了
倒排索引方法,并为SSE的设计引入了新技术。
我们的贡献:
- 我们提出了动态SSE的形式化安全定义。
- 我们构造了第一个SSE方案,它是动态的,CKA2-secure 的,并且实现了最优的搜索时间。
- 我们描述了基于可搜索的对称加密:改进的定义和高效的结构的倒排索引方法的SSE方案的第一个实现和评估。我们的实现表明,这种类型的SSE方案非常有效。
2、安全性
服务器可以了解到一些客户端查询的有限信息。例如它知道正在搜索的关键字都包含在加密为$c_{w}$ 的文件中。
SSE安全性
(1)加密的索引 $\gamma$ 和密文 $c$ 除了文件的数量 $n$ 和它们的长度之外,不泄露关于 $f$ 的任何信息;
(2)加密的索引 $\gamma$ 和令牌 $T_{w}$ 至多揭示了搜索 $I_{w}$ 的结果。
CKA1——抵抗选择关键字攻击的安全性
- 只有当客户的查询独立于索引和先前的结果时,才能保证安全性。
CKA2——抵抗自适应选择关键字攻击的安全性
- 即使客户端的查询是基于加密的索引和先前查询的结果,也能保证安全性。
- 即使存在可以在协议进行时破坏参与者的对手的情况下也能保持其安全性,则称其自适应安全。
动态SSE方案必须允许添加和删除文件。这两种操作都是使用令牌来处理的。
为了添加文件 $f$,客户端生成添加令牌 $\tau_{a}$,给定 $\tau_{a}$ 和 $\gamma$,服务器可以更新加密的索引 $\gamma$。
为了删除文件 $f$,客户端生成删除令牌 $\tau_{d}$,服务器用它来更新 $\gamma$。
动态SSE方案要求的安全保证:
(1)给定加密的索引 $\gamma$ 和密文序列 $c$,任何对手都无法获知关于文件 $f$ 的任何信息;
(2)给定了 token 序列 $\tau=(\tau_{1},…,\tau_{n})$。对于自适应生成的查询序列 $q=(q_{1},…,q_{n})$(它可以用于搜索、添加或删除操作),任何对手都无法获知关于 $f$ 或 $q$ 的任何信息。
3、方案概述
| 符号 | 含义 |
|---|---|
| $f$ | 明文序列 $f=(f_{1},…,f_{n})$ |
| $f_{w}$ | 包含$w$的明文 |
| $c$ | 密文序列 $c=(c_{1},…,c_{n})$ |
| $c_{w}$ | 包含$w$的密文 |
| $I_{w}$ | 包含$w$的文件标识符 $I_w∈c$ |
| $δ$ | 索引 |
| $\gamma$ | 加密的索引 |
| $\tau_{s}$ | 搜索令牌 |
| $\tau_{a}$ | 添加令牌 |
| $\tau_{d}$ | 删除令牌 |
| $#f$ | $f$ 中文件的数量 |
| $#f_w$ | 是包含关键字$w$的文件数量 |
| $#W$ | 关键字空间的大小 |
我们的方案是基于倒排索引SSE-1结构的扩展。尽管 SSE-1 是实用的(它对于小常数是渐近最优的),但它确实有一些限制,使得它不适合直接用于加密云存储系统中:
(1)它只能抵抗非自适应选择关键字攻击(CKA1),这意味着它只能为批量执行搜索的客户端提供安全性;
(2)它不是显式动态的,它只能支持使用通用和低效技术的动态操作。
SSE-1 construction
为了加密文件集合 $f$,该方案为每个关键字 $w∈W$ 构造一个列表 $L_{w}$,每个列表 $L_{w}$ 由 $#\rm f_{w}$ 个节点$(N_{1},…,N_{f_{w}})$,它们被存储在搜索数组 $A_s$ 中的随机位置。节点 $N_{i}$ 被定义为$N_{i}=⟨id,addr_{s}(N_{i+1})⟩$,其中 $id$ 是包含 $w$ 的文件的唯一文件标识符,$addr_{s}(N)$ 表示在范围 $A_{s}$ 中的节点 $N$ 的位置。
为了防止$A_{s}$的大小泄露有关 $f$ 的统计信息,建议$A_{s}$的大小至少为$|c|/8$,和 使用长度适当的随机字符串填充未使用的单元格。
对于每个关键字 $w$,将指向 $L_{w}$ 头部的指针插入到搜索表 $T_{s}$ 下的搜索键 $F_{K_{1}}(w)$中 ,然后在生成的密钥 $G_{K_{2}}(w)$ 下使用 SKE= (Gen,Enc,Dec) 对每个列表进行加密。
如果要搜索关键字 w,客户端发送 $F_{K_{1}}(w)$ 和 $G_{K_{2}}(w)$ 就足够了。然后,服务器可以使用 $F_{K_{1}}(w)$ 和 $T_{s}$ 来恢复指向 $L_{w}$ 头部的指针,并使用 $G_{K_{2}}(w)$ 来解密列表并恢复包含 $w$ 的文件的标识符。只要 T 支持 O(1) 时间复杂度查找(可以使用哈希表实现),服务器的总搜索时间在 $#f_{w}$ 中是线性的,这是最优的。
使用SSE-1动态。如上所述,SSE-1的限制有两方面:
(1)它只是CKA1-secure的
(2)它不是显式动态的。
第一个限制可以通过要求 SKE 是非承诺的就可以相对容易地解决(事实上,该工作中提出的 CKA2 安全 SSE 结构使用了一个简单的基于 PRF 的非承诺加密方案)。
- 非承诺性(non-committin):即方案的密文和安全参数与随机数是不可区分的!
然而,第二个限制就不那么容易克服了。难点在于文件的添加、删除或修改需要服务器在存储在$A_{s}$中的加密列
表中添加、删除或修改节点。 这对于服务器来说很难做到,因为:
(1)当删除文件 $f$ 时,它不知道(在A中)与 $f$ 对应的节点存储在哪里;
(2)当从列表中插入或删除一个节点时,它不能修改前一个节点的指针,因为它是加密的;
(3)添加一个节点后,它不知道 $A_{s}$ 中哪些位置是空闲的。
在高层次上,我们处理这些限制如下:
(文件删除)我们添加了一个额外的(加密的)数据结构$A_{d}$,称为删除数组,服务器可以查询(通过客户端提供的令牌),以恢复指向被删除文件对应节点的指针。更准确地说,删除数组为每个文件存储一个指向 $A_{s}$ 中的节点的节点列表,如果文件 $f$ 被删除,这些节点应该被删除。所以搜索数组中的每个节点在删除数组中都有一个对应的节点,删除数组中的每个节点都指向搜索数组中的一个节点。在整个过程中,我们将把这样的节点称为对偶,并编写$N^*$ 来指代节点$N$的对偶。
(指针修改)我们使用同态加密方案对存储在节点中的指针进行加密。这类似于[23]中van Liesdonk等人用来修改他们构造的加密搜索结构的方法。通过向服务器提供适当值的加密,它就可以修改指针,而不需要解密节点。我们使用“标准”对称加密方案,该方案包括将消息与PRF的输出进行异或运算。这个简单的构造还有一个优点,即不提交(在私有密钥设置中),我们可以利用这个优点来实现CKA2安全性。
(内存管理)为了跟踪$A_{s}$中的哪些位置是空闲的,我们添加并管理额外的空间,包括服务器用来添加新节点的free列表。
4、具体实现
Prepare
$$
DSSE=(Gen,Enc,SrchToken,AddToken,DelToken,Search,Add,Del,Dec)
$$
| 序号 | 算法 | 描述 |
|---|---|---|
| ① | $K\leftarrow Gen(1^{k})$ | 密钥生成算法 |
| ② | $(\gamma,c)\leftarrow Enc(K,f)$ | 索引生成算法 |
| ③ | $\tau_{s}\leftarrow SrchToken(K,w)$ | 陷门生成算法 |
| ④ | $(\tau_{a},c_{f})\leftarrow AddToken(K,f)$ | 添加令牌生成算法 |
| ⑤ | $\tau_{d} \leftarrow DelToken(K,f)$ | 删除令牌生成算法 |
| ⑥ | $I_{w}:=Search(\gamma,c,\tau_{s})$ | 搜索算法 |
| ⑦ | $(\gamma’,c’):=Add(\gamma,c,\tau_{a},c_{new})$ | 添加文件算法 |
| ⑧ | $(\gamma’,c’):=Del(\gamma,c,\tau_{d})$ | 删除文件算法 |
| ⑨ | $f:=Dec(K,c)$ | 解密算法 |
| 伪随机函数 |
|---|
| $F:{0,1}^k×{0,1}^∗→{0,1}^k$ |
| $G:{0,1}^k×{0,1}^∗→{0,1}^∗$ |
| $P:{0,1}^k× {0,1}^∗→ {0,1}^k$ |
| 随机预言机 |
| $H_1:{0,1}^∗→ {0,1}^∗$ |
| $H_2:{0,1}^∗→{0,1}^∗$ |
| 符号 | 描述 |
|---|---|
| $A_s$ | 搜索数组 |
| $A_{d}$ | 删除数组 |
| $T_s$ | 搜索表 |
| $T_{d}$ | 删除表 |
$Gen(1^k)$
$$
K = (K_1,K_2,K_3,K_4)←{0, 1}^k
$$
$Enc(K,f)$
- 设 $A_s$ 和 $A_d$ 为大小为 $|c|/8 +z$ 的数组,设 $T_s$ 和 $T_d$ 分别为大小为 $#W$ 和 $#f$ 的字典。我们假设 0 是一个长度为$(log#A_s)$的 0 字符串,free 是一个不在 $W$ 中的单词
- 设 $z∈N$ 为 $free \ list$ 的初始大小
- for $w∈W$
创建一个列表 $L_w$ 包含 $#f_w$ 个节点 $(N_1,…,N_#f_w)$ 存储在搜索数组 $A_s$ 的随机位置,并定义为
$$
N_i:= (〈id_i,addr_s(N_{i+1})〉⊕H_1(K_w, r_i),r_i)
$$
- 其中 $id_i$ 是 $f_w$ 中第 i 个文件的 ID,$r_i$ 是随机生成的 $k-bit$ 串,$K_w:=P_{K_3}(w)$ , $addr_s(N_#f_{w+1}) =0$
通过设置 $T_s[F_{K_1}(w)] :=〈addr_s(N_1),addr_d(N^⋆1)〉⊕G{K_2}(w)$ 存储一个指向搜索表中 $L_w$ 的第一个节点的指针
- 其中 $N^*$ 是 N 的对偶,即$A_d$ 中的节点,其第四个入口指向$A_s$中的 $N_1$。
- for $f∈\rm f$
创建一个列表 $L_f$ 包含 $#f$ 个节点$(D_1,…,D_#f_w)$ 存储在搜索数组 $A_d$ 的随机位置,并定义为
$D_i:= (〈addr_d(D_{i+1}),addr_d(N^⋆_{−1}),addr_d(N^⋆_{+1}),addr_s(N),addr_s(N_{−1}),addr_s(N_{+1}),F_{K_1}(w)〉⊕ H_2(K_f, r^′_i), r^′_i)$
- 其中 $r’i$ 是随机生成的 k-bit 串,$K_f:=P{K_3}(f)$ , $addr_d(D_#f_{w+1}) =0$
- 每个条目$D_i$都与一个单词 $w$ 相关,因此$L_w$中节点$N$。设$N_{+1}$为$L_w$中$N$之后的节点,$N_{-1}$为$L_w$中$N$之前的节点
通过设置 $T_d[F_{K_1}(f)] :=addr_d(D_1)⊕G_{K_2}(f)$,在删除表中存储一个指向 $L_f$ 的第一个节点的指针
- 通过在 $A_s$ 和 $A_d$ 中随机选择 $z$ 个未使用的单元格,创建一个未加密的空闲列表 $L_{free}$,让$(F_1,…,F_z)$和$(F’_1,…,F’_z)$分别为 $A_s$ 和 $A_d$ 中的空闲节点。设置 $T_s[free] :=〈addr_s(F_z),0^{log}#A〉$
for $z≤i≤1$, 设置 $A_s[addr_s(F_i)] :=0^{log}#f,addr_s(F_{i−1}),addr_d(F^′_i)$ 其中 $addr_s(F_0) =0^{log}#A$
用随机字符串填充$A_S$ 和 $A_d$ 的其余条目
对于 $1≤i≤#f$,令 $c_i←SKE.Enc_{K4}(f_i)$
输出 $(γ,c)$ , 其中 $γ:= (A_s,T_s,A_d,T_d)$ 和 $c= (c_1, . . . , c_#f)$.
$SrchToken(K, w)$
$$
τ_s:=(F_{K_{1}}(w), G_{K_{2}}(w), P_{K_{3}}(w))
$$
$Search(γ,c, τ_s)$
将 $τ_s$ 解析为 $(τ_1, τ_2, τ_3)$,如果 $τ_1$ 在 $T_s$ 中不存在,则返回空列表。
通过计算 $(α_1, α’_1):=T_s[τ_1]⊕τ_2$ 恢复指向列表第一个节点的指针
查找 $N_1:=A[α_1]$ 并用 $τ_3$ 进行解密,
即将 $N_1$ 解析为 $(ν_1, r_1)$ 并计算$(id_1,0,addr_s(N_2)):=ν_1⊕H_1(τ_3, r_1)$
对于 $i≥2$,解密节点 $N_i$,直到 $α_{i+1}=0$
设 $I={id_1,…,id_m}$ 为前面步骤中显示的文件标识符,并输出${c_i}_{i∈I}$,即显示标识符的文件的加密
$AddToken(K, f)$
让 $(w_1,…,w_#f)$ 是 $f$ 中关键词。计算 $τ_a:=(F_{K_{1}}(f), G_{K_{2}}(f), λ_1,. . .,λ_#f)$,对于所有 $1≤i≤#f$
$λ_i:= (F_{K_{1}}(w_i), G_{K_{2}}(w_i),〈id(f),0〉 ⊕H_1(P_{K_3}(w_i), r_i), r_i,〈0,0,0,0,0,0, F_{K_{1}}(w_1〉 ⊕H_2(P_{K_3}(f), r^′_i), r^′_i)$
- $r_i$ 和 $r’i$ 是随机位字符串。令 $c_f←SKE.Enc{K_4}(f)$
- 输出 $(τ_a, c_f)$
$Add(γ,c, τ_a)$
将 $τ_a$ 解析为$(τ_1,τ_2, λ_1,. . .,λ_#f)$,如果 $τ_1$ 不在 $T_s$ 内,则是⊥(无法运算)
对于 $1≤i≤#f$
计算 $(φ,0) :=T_s[free], (φ_{−1}, φ^⋆) :=A_s[φ]$ 找到搜索数组中最后一个空闲位置 $φ$ 和删除数组中对应入口 $φ^*$
通过设置 $T_s[free]:= (φ_{−1},0)$,更新搜索表以指向倒数第二个空闲条目
通过计算 $(α_1,α^*_1):=T_s[λ_i[1]]⊕λ_i[2]$ 恢复指向列表第一个节点 $N_1$ 的指针
将新节点存储在位置 $φ$ 处,并通过设置$A_s[φ]:=(λ_i[3]⊕< 0,α_1 >, λ_i[4])$将其前向指针修改为$N_1$
更新搜索表 $T_s[λ_i[1]]:=(φ, φ^⋆)⊕λ_i[2]$
更新 $N_1$的对偶 $A_d[α^⋆_1] :=(D_1⊕〈0, φ^⋆,0,0,φ,0,0〉, r)$,其中 $(D_1,r) :=A_d[α^⋆_1]$
更新$A_s[φ]$的对偶 $A_d[φ^⋆]:=(λ_i[5]⊕〈φ^⋆_{−1},0, α^⋆_1,φ,0, α_1, λ_i[1]〉, λ_i[6])$
如果 i = 1,则更新删除表 $T_d[τ_1] :=〈φ^⋆,0〉⊕τ_2$
- 更新密文,将新密文 $c_{new}$ 加入 $c$
$DelToken(K, f)$
$$
τ_d:= (F_{K_{1}}(f), G_{K_{2}}(f), P_{K_{3}}(f),id(f))
$$
$Del(γ,c, τ_d)$
将 $τ_d$ 解析为 $(τ_1,τ_2,τ_3,id)$,如果 $τ_1$ 不在 $T_d$ 内,则是⊥(终止)
找到 $L_f$ 的第一个节点 $α^′_1:=T_d[τ_1]⊕τ_2$
对于 $1≤i≤#f$
解密 $D_i$ , $(α_1, . . . , α_6, μ) :=D_i⊕H_2(τ_3, r)$, 其中 $(D_i, r) :=A_d[α^′_i]$
删除 $D_i$, $A_d[α^′_i]$ 为一个随机 ($6 log #(A+k)0$)-bit 字符串
找到最后一个空闲节点 $(φ,0^{log}#A) :=T_s[free]$
使搜索表中的 free 条目指向$D_i$的对偶 $T_s[free]:=〈α_4,0^{log}#A〉$
$D_i$ 对偶的 的自由位置 $As[α_4] := (φ, α^′_i)$
让$N_{-1}$成为 $D_i$ 对偶之前的节点,更新 $N_{-1}$ 的 next 指针 by setting:
$A_s[α_5] := (β_1, β_2⊕α_4⊕α_6, r_{−1})$,其中 $(β_1, β_2, r_{−1}) :=A_s[α_5]$
此外 更新 $N_{-1}$的对偶指针 by setting:
$A_d[α_2] := (β_1, β_2, β_3⊕α^′i⊕α_3, β_4, β_5, β_6⊕α_4⊕α_6, μ^∗, r^∗{-1})$,where $(β_1, . . . , β_6, μ^∗, r^∗_{-1}) :=A_d[α_2]$
让$N_{+1}$成为跟随 Di 的对偶的节点,更新 $N_{+1}$的对偶指针 by setting:
$A_d[α_3] := (β_1, β_2⊕α^′i⊕α_2, β_3, β_4, β_5⊕α_4⊕α_5, β_6, μ^∗, r^∗{+1})$,其中 $(β_1, . . . , β_6, μ^∗, r^∗_{+1}) :=A_d[α_3]$
set $α^′_{i+1}:=α_1$
4.从 $c$ 中删除 $id$ 对应的密文
5.从$T_d$中去除$τ_1$
$Dec(K, c)$
$$
m:=SKE.Dec_{K4}(c)
$$
说明性例子
图1演示了包含3个文件和3个单词的玩具索引上的动态SSE数据结构。
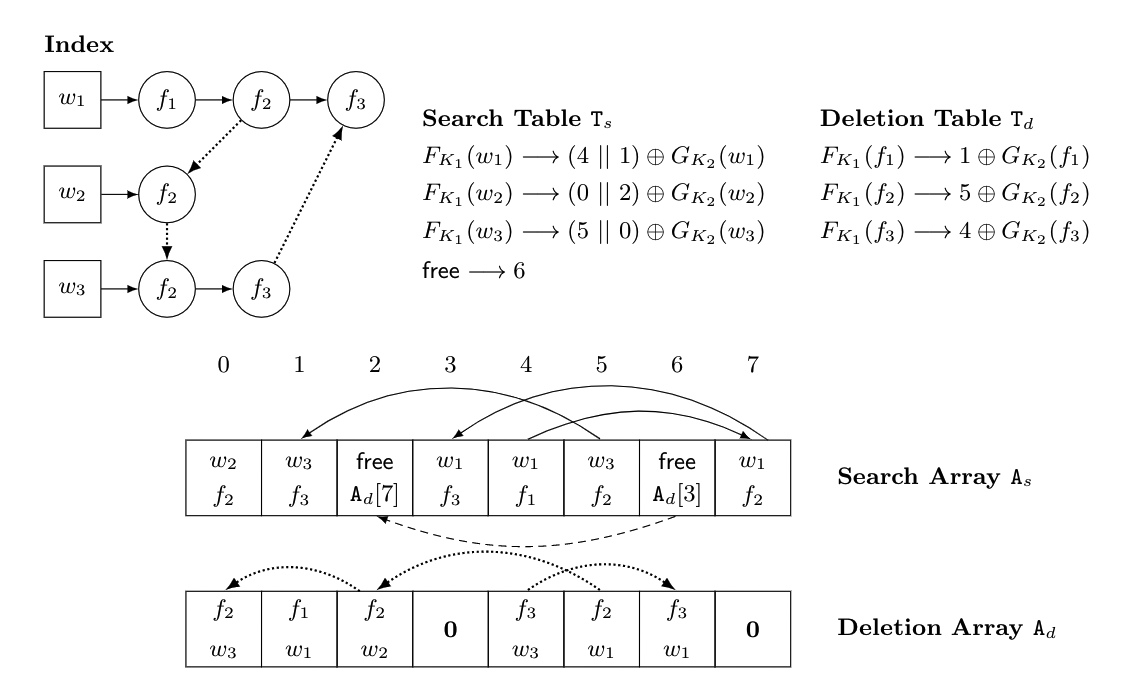
该索引基于三个文档,即$f_{1}$、$f_{2}$、$f_{3}$,基于三个关键词,即 $w_{1}$、$w_{2}$、$w_{3}$。所有文档都包含关键字 $w_{1}$,关键字$w_{2}$仅包含在文档 $f_{2}$ 中,而 $w_{3}$ 包含在文档 $f_{2}$ 和 $f_{3}$ 中。
图1中还示出了相应的搜索表$T_{s}$、删除表 $T_{d}$、搜索数组 $A_{s}$ 和删除数组 $A_{d}$。
注意,在真实的DSSE索引中,会有填充来隐藏文件单词对的数量;在这个例子中,为了简单起见,我们省略了这个填充。
搜索。搜索是我们方案中最简单的操作。
假设客户希望搜索包含关键字$w_{1}$的所有文档。他准备搜索令牌,其中包含 $F_{K_{1}}(w)$ 和$G_{K_{2}}(w)$。第一值 $F_{K_{1}}(w)$ 和将使服务器能够在搜索表$T_{s}$中定位对应于关键字$w_{1}$的条目。
在我们的例子中,这个值是$x=(4∣∣1)\oplus G_{K_{2}}(w)$。服务器现在使用第二个值 和$G_{K_{2}}(w)$来计算$x\oplus G_{K_{2}}(w)$。这将允许服务器在搜索数组中定位正确的条目(在我们的例子中是4个),并开始“暴露”存储指向包含$w_{1}$的文档的指针的位置。这种去屏蔽是通过搜索令牌中包含的第三个值来执行的。
添加文档。假设现在客户希望添加包含关键字$w_{1}$和$w_{2}$的文档$f_{4}$。请注意,搜索表根本没有改变,因为$f_{4}$正在进行成为关键字$w_{1}$和$w_{2}$列表中的最后一个条目,并且搜索表仅存储前几个条目。然而,所有其他数据结构必须以下列方式更新。首先,服务器使用无需快速检索搜索数组中“空闲”位置的索引,新条目将存储在这些位置。
在我们的例子中,这些位置是2和6。服务器在这些条目中存储新信息$(w_{1},f_{4})$和$(w_{2},f_{4})$。现在,服务器需要将这个新条目连接到相应的关键字列表:使用add令牌,它在搜索数组中检索元素x和y的索引$i = 0$和j = 3,使得x和y对应于关键字列表$w_{1}$和$w_{2}$的最后条目。这样,服务器同态地将$A_{s}\left[ 0 \right]$和$A_{s}\left[ 3 \right]$的“下一个”指针设置为指向新添加的节点,这些节点已经存储在搜索数组的位置2和6。
注意,访问搜索数组中的空闲条目也提供了对删除数组$A_d$的相应空闲位置的访问。在我们的例子中,删除数组中空闲位置的索引是3和7。服务器将在删除数组中的这些位置存储新的条目$(f_{4},w_{1})$和$(f_{4},w_{2})$,并将它们用指针连接起来。最后,服务器将通过将条目$F_{K_{1}}(f_{4})$设置为指向删除数组中的位置3来更新删除表,以便稍后可以容易地检索文件$f_4$进行删除。
删除文档。假设现在客户想要删除一个已经存储在我们的索引中的文档,比如说文档$f_{3}$,它包含关键字$w_{1}$和$w_{3}$。删除是添加的“双重操作”。首先,服务器使用删除令牌的值$F_{K_{1}}(f_{3})$在删除表中定位正确的值$4\oplus G_{K_{2}}(f_{3})$。这将允许服务器访问剩余数据结构中需要用add算法以类似方式更新的部分。即它将“释放”删除数组中的位置4和6以及搜索数组中的位置1和3。当“释放”搜索数组中的位置时,它还将同态更新指向新条目的关键字列表$w_{1}$和$w_{3}$(在我们的例子中,指向列表的末尾——通常在已删除条目的下一个指针中)。注意,删除数组不需要这样的指针更新。
5、参考文献
Sponsor❤️
您的支持是我不断前进的动力,如果您感觉本文对您有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用,拒绝白嫖,从你我做起!🥰🥰🥰
| 支付宝 | 微信 |
 |
 |



