ZK简介
Zookeeper 是 Apache Hadoop 项目下的一个子项目,是一个树形目录服务。Zookeeper 是一个分布式的、开源的分布式应用程序的协调服务。
Zookeeper 提供的主要功能包括:配置管理、分布式锁、集群管理
ZK安装
下载
Index of /dist/zookeeper (apache.org)
配置
配置zoo.cfg,进入到conf目录拷贝一个zoo_sample.cfg并完成配置
#进入到conf目录
cd apache-zooKeeper-3.5.6-bin/conf/
#拷贝
cp zoo_sample.cfg zoo.cfg
修改zoo.cfg
vim apache-zooKeeper-3.5.6-bin/conf/zoo.cfg
修改存储目录:dataDir=你自己的目录
启动ZooKeeper
./zkServer.sh start
查看ZooKeeper状态
./zkServer.sh status
standalone代表zk没有搭建集群,现在是单节点
数据结构
ZooKeeper 是一个树形目录服务,其数据模型和Unix的文件系统目录树很类似,拥有一个层次化结构。
这里面的每一个节点都被称为: ZNode,每个节点上都会保存自己的数据和节点信息。
节点可以拥有子节点,同时也允许少量(1MB)数据存储在该节点之下。
节点可以分为四大类:
PERSISTENT 持久化节点
EPHEMERAL 临时节点 :-e
PERSISTENT_SEQUENTIAL 持久化顺序节点 :-s
EPHEMERAL_SEQUENTIAL 临时顺序节点 :-es
命令操作
服务端常用命令
启动 ZooKeeper 服务:
./zkServer.sh start查看 ZooKeeper 服务状态:
./zkServer.sh status停止 ZooKeeper 服务:
./zkServer.sh stop重启 ZooKeeper 服务:
./zkServer.sh restart
客户端常用命令
Zookeeper 可视化客户端推荐:ZooKeeper Assistant (收费)、PrettyZoo(免费)
连接ZooKeeper服务端
./zkCli.sh –server 服务端ip:port断开连接
quit显示指定目录下节点
ls 目录创建节点
create /节点path value- 创建临时节点
create -e /节点path value - 创建顺序节点
create -s /节点path value
- 创建临时节点
获取节点值
get /节点path设置节点值
set /节点path value删除单个节点
delete /节点path删除带有子节点的节点
deleteall /节点path查询节点详细信息
ls –s /节点path
czxid:节点被创建的事务ID
ctime: 创建时间
mzxid: 最后一次被更新的事务ID
mtime: 修改时间
pzxid:子节点列表最后一次被更新的事务ID
cversion:子节点的版本号
dataversion:数据版本号
aclversion:权限版本号
ephemeralOwner:用于临时节点,代表临时节点的事务ID,如果为持久节点则为0
dataLength:节点存储的数据的长度
numChildren:当前节点的子节点个数
JavaAPI操作
引入 Curator
Apache Curator 是 ZooKeeper(分布式协调服务)的 Java/JVM 客户端库。它包括一个高级API框架和实用程序,使使用Apache ZooKeeper变得更加容易和可靠。
Curator 项目的目标是简化 ZooKeeper 客户端的使用。
Curator 最初是 Netfix 研发的,后来捐献了 Apache 基金会,目前是 Apache 的顶级项目。
使用时引入依赖
<dependencies>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>5.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
测试环境
public class CuratorTest {
private CuratorFramework client;
/**
* 建立连接
*/
@Before //在所有 @test方法之前执行
public void testConnect() {
//重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.namespace("jwt")
.build();
//开启连接
client.start();
}
// 此处写测试代码
@Test
public void testXXX() {
//。。。。
// 建立连接、添加节点、删除节点、修改节点、查询节点
}
@After //在所有 @test方法之后执行
public void close() {
if (client != null) {
client.close();
}
}
}
建立连接
//1.第一种方式
@Test
public void testConnect() {
/*
*
* @param connectString 连接字符串。zk server 地址和端口 "127.0.0.1:2181,"
* @param sessionTimeoutMs 会话超时时间 单位ms
* @param connectionTimeoutMs 连接超时时间 单位ms
* @param retryPolicy 重试策略
*/
//重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000,10);
CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181",
60 * 1000, 15 * 1000, retryPolicy);
//开启连接
client.start();
}
//2.第二种方式
@Test
public void testConnect_02() {
//重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.namespace("jwt")
.build();
//开启连接
client.start();
}
namespace 命名空间,每次操作都在该空间目录下
添加节点
创建节点:create 持久 临时 顺序 数据
- 基本创建 :create().forPath(“”)
- 创建节点 带有数据:create().forPath(“”,data)
- 设置节点的类型:create().withMode().forPath(“”,data)
- 创建多级节点 /app1/p1 :create().creatingParentsIfNeeded().forPath(“”,data)
@Test
public void testCreate() throws Exception {
//2. 创建节点 带有数据
//如果创建节点,没有指定数据,则默认将当前客户端的ip作为数据存储
String path = client.create().forPath("/app2", "hehe".getBytes());
System.out.println(path);
}
@Test
public void testCreate2() throws Exception {
//1. 基本创建
//如果创建节点,没有指定数据,则默认将当前客户端的ip作为数据存储
String path = client.create().forPath("/app1");
System.out.println(path);
}
@Test
public void testCreate3() throws Exception {
//3. 设置节点的类型
//默认类型:持久化
String path = client.create().withMode(CreateMode.EPHEMERAL).forPath("/app3");
System.out.println(path);
}
@Test
public void testCreate4() throws Exception {
//4. 创建多级节点 /app1/p1
//creatingParentsIfNeeded():如果父节点不存在,则创建父节点
String path = client.create().creatingParentsIfNeeded().forPath("/app4/p1");
System.out.println(path);
}
查询节点
- 查询数据:get: getData().forPath()
- 查询子节点: ls: getChildren().forPath()
- 查询节点状态信息:ls -s:getData().storingStatIn(状态对象).forPath()
@Test
public void testGet1() throws Exception {
//1. 查询数据:get
byte[] data = client.getData().forPath("/app1");
System.out.println(new String(data));
}
@Test
public void testGet2() throws Exception {
// 2. 查询子节点: ls
List<String> path = client.getChildren().forPath("/");
System.out.println(path);
}
@Test
public void testGet3() throws Exception {
Stat status = new Stat();
System.out.println(status);
//3. 查询节点状态信息:ls -s
client.getData().storingStatIn(status).forPath("/app1");
System.out.println(status);
}
修改节点
- 1.基本修改数据:setData().forPath()
- 2.根据版本修改: setData().withVersion().forPath()
version 是通过查询出来的。目的就是为了让其他客户端或者线程不干扰我。
@Test
public void testSet() throws Exception {
client.setData().forPath("/app1", "hello".getBytes());
}
@Test
public void testSetForVersion() throws Exception {
Stat status = new Stat();
//3. 查询节点状态信息:ls -s
client.getData().storingStatIn(status).forPath("/app1");
int version = status.getVersion();//查询出来的
System.out.println(version);
client.setData().withVersion(version).forPath("/app1", "hehe".getBytes());
}
删除节点
删除节点: delete deleteall
- 删除单个节点:delete().forPath(“/app1”);
- 2 . 删除带有子节点的节点:delete().deletingChildrenIfNeeded().forPath(“/app1”);
- 必须成功的删除:为了防止网络抖动。本质就是重试。 client.delete().guaranteed().forPath(“/app2”);
- 4.回调:inBackground
@Test
public void testDelete() throws Exception {
// 1. 删除单个节点
client.delete().forPath("/app1");
}
@Test
public void testDelete2() throws Exception {
//2. 删除带有子节点的节点
client.delete().deletingChildrenIfNeeded().forPath("/app4");
}
@Test
public void testDelete3() throws Exception {
//3. 必须成功的删除
client.delete().guaranteed().forPath("/app2");
}
@Test
public void testDelete4() throws Exception {
//4. 回调
client.delete().guaranteed().inBackground(new BackgroundCallback(){
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("我被删除了~");
System.out.println(event);
}
}).forPath("/app1");
}
Watch事件监听
ZooKeeper 允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
ZooKeeper 中引入了Watcher机制来实现了发布/订阅功能能,能够让多个订阅者同时监听某一个对象,当一个对象自身状态变化时,会通知所有订阅者。
ZooKeeper 原生支持通过注册Watcher来进行事件监听,但是其使用并不是特别方便,需要开发人员自己反复注册Watcher,比较繁琐。Curator 引入了 Cache 来实现对 ZooKeeper 服务端事件的监听。
ZooKeeper提供了三种Watcher:
NodeCache : 只是监听某一个特定的节点
PathChildrenCache : 监控一个ZNode的子节点.
TreeCache : 可以监控整个节点自己和所有的子节点,类似于PathChildrenCache和NodeCache的组合
测试环境
public class CuratorWatcherTest {
private CuratorFramework client;
/**
* 建立连接
*/
@Before
public void testConnect() {
//重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
//2.第二种方式
client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.namespace("jwt")
.build();
//开启连接
client.start();
}
// 测试代码写此处。。。。
/**
* 关闭连接
*/
@After
public void close() {
if (client != null) {
client.close();
}
}
}
NodeCache
只是监听某一个特定的节点
/**
* 演示 NodeCache:给指定一个节点注册监听器(监听节点/jwt/app1)
*/
@Test
public void testNodeCache() throws Exception {
//1. 创建NodeCache对象
final NodeCache nodeCache = new NodeCache(client,"/app1");
//2. 注册监听
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("节点变化了~");
//获取修改节点后的数据
byte[] data = nodeCache.getCurrentData().getData();
System.out.println(new String(data));
}
});
//3. 开启监听.如果设置为true,则开启监听是,加载缓冲数据
nodeCache.start(true);
while (true){
// 测试需要,保证监听器一直运行
}
}
PathChildrenCache
监控一个ZNode的子节点
/**
* 演示 PathChildrenCache:监听某个节点的所有子节点们(监听/jwt/app2的子节点)
*/
@Test
public void testPathChildrenCache() throws Exception {
//1.创建监听对象
PathChildrenCache pathChildrenCache = new PathChildrenCache(client,"/app2",true);
//2. 绑定监听器
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
System.out.println("子节点变化了~");
System.out.println(event);
//监听子节点的数据变更,并且拿到变更后的数据
//1.获取类型
PathChildrenCacheEvent.Type type = event.getType();
//2.判断类型是否是update
if(type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)){
System.out.println("数据变了!!!");
byte[] data = event.getData().getData();
System.out.println(new String(data));
}
}
});
//3. 开启
pathChildrenCache.start();
while (true){
}
}
TreeCache
可以监控整个节点自己和所有的子节点,类似于PathChildrenCache和NodeCache的组合
/**
* 演示 TreeCache:监听某个节点自己和所有子节点们(监听/jwt/app2 和其子节点)
*/
@Test
public void testTreeCache() throws Exception {
//1. 创建监听器
TreeCache treeCache = new TreeCache(client,"/app2");
//2. 注册监听
treeCache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
System.out.println("节点变化了");
System.out.println(event);
}
});
//3. 开启
treeCache.start();
while (true){
}
}
分布式锁
ZK 分布式锁原理
在我们进行单机应用开发,涉及并发同步的时候,我们往往采用synchronized或者Lock的方式来解决多线程间的代码同步问题,这时多线程的运行都是在同一个JVM之下,没有任何问题。但当我们的应用是分布式集群工作的情况下,属于多JVM下的工作环境,跨JVM之间已经无法通过多线程的锁解决同步问题。
那么就需要一种更加高级的锁机制,来处理种跨机器的进程之间的数据同步问题——这就是分布式锁。
核心思想:当客户端要获取锁,则创建节点,使用完锁,则删除该节点。
1.客户端获取锁时,在某节点(lock)下创建
临时顺序节点。- 使用临时节点的原因:防止客户端宕机,而无法释放锁,如果使用临时节点,即使宕机,节点也会自动删除(临时节点特性,客户端断开连接,临时节点自动删除)
- 使用顺序节点的原因:因为需要找最小节点,需要排顺序
2.然后获取该节点(lock)下面的所有子节点(/lock/1,/lock/2,/lock/3),客户端获取到所有的子节点之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。使用完锁后,将该节点删除。
3.如果发现自己创建的节点并非该节点所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。
4.如果发现比自己小的那个节点被删除,则客户端的监听器Watcher会收到相应通知,此时再次判断自己创建的节点是否是lock子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点,并注册监听。

总结:多个客户端在一个节点下创建临时顺序节点,然后去找序号最小的节点就是锁,用完之后删除就可以了。
在Curator中有五种锁方案:
InterProcessSemaphoreMutex:分布式排它锁(非可重入锁)
InterProcessMutex:分布式可重入排它锁
InterProcessReadWriteLock:分布式读写锁
InterProcessMultiLock:将多个锁作为单个实体管理的容器
InterProcessSemaphoreV2:共享信号量
分布式锁案例
模拟12306售票
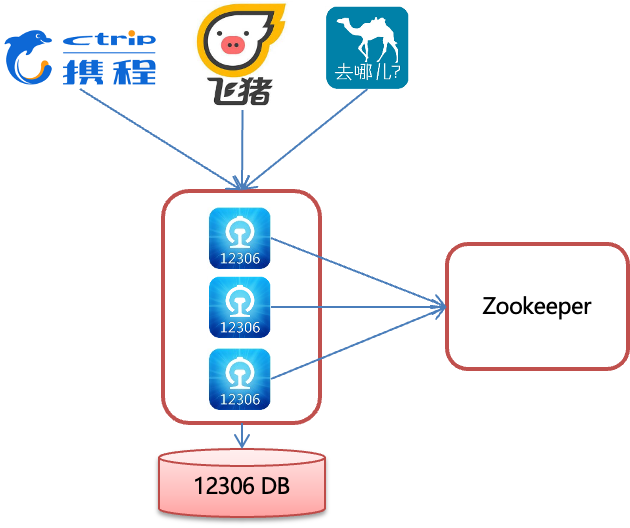
public class LockTest {
public static void main(String[] args) {
Ticket12306 ticket12306 = new Ticket12306();
//创建客户端
Thread t1 = new Thread(ticket12306,"携程");
Thread t2 = new Thread(ticket12306,"飞猪");
Thread t3 = new Thread(ticket12306,"去哪儿");
t1.start();
t2.start();
t3.start();
}
}
public class Ticket12306 implements Runnable{
private int tickets = 10;//数据库的票数
private InterProcessMutex lock ;
// 构造函数
public Ticket12306(){
// 连接 ZK
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10); //重试策略
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.build();
client.start(); //开启连接
// 创建锁
lock = new InterProcessMutex(client,"/lock");
}
@Override
public void run() {
while(true){
//获取锁
try {
lock.acquire(3, TimeUnit.SECONDS);
if(tickets > 0){
System.out.println(Thread.currentThread()+":"+tickets);
Thread.sleep(100);
tickets--;
}
} catch (Exception e) {
e.printStackTrace();
}finally {
//释放锁
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
集群
集群搭建
1.1 搭建要求
真实的集群是需要部署在不同的服务器上的,但是在我们测试时同时启动很多个虚拟机内存会吃不消,所以我们通常会搭建伪集群,也就是把所有的服务都搭建在一台虚拟机上,用端口进行区分。
我们这里要求搭建一个三个节点的Zookeeper集群(伪集群)。
1.2 准备工作
重新部署一台虚拟机作为我们搭建集群的测试服务器。
(1)安装JDK 【此步骤省略】。
(2)Zookeeper压缩包上传到服务器
(3)将Zookeeper解压 ,建立/usr/local/zookeeper-cluster目录,将解压后的Zookeeper复制到以下三个目录
- /usr/local/zookeeper-cluster/zookeeper-1
- /usr/local/zookeeper-cluster/zookeeper-2
- /usr/local/zookeeper-cluster/zookeeper-3
[root@localhost ~]# mkdir /usr/local/zookeeper-cluster
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-1
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-2
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-3
(4)创建data目录 ,并且将 conf下zoo_sample.cfg 文件改名为 zoo.cfg
mkdir /usr/local/zookeeper-cluster/zookeeper-1/data
mkdir /usr/local/zookeeper-cluster/zookeeper-2/data
mkdir /usr/local/zookeeper-cluster/zookeeper-3/data
mv /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
mv /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
mv /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
(5) 配置每一个Zookeeper 的dataDir 和 clientPort 分别为2181 2182 2183
修改/usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
clientPort=2181
dataDir=/usr/local/zookeeper-cluster/zookeeper-1/data
修改/usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
clientPort=2182
dataDir=/usr/local/zookeeper-cluster/zookeeper-2/data
修改/usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
clientPort=2183
dataDir=/usr/local/zookeeper-cluster/zookeeper-3/data
1.3 配置集群
(1)在每个zookeeper的 data 目录下创建一个 myid 文件,内容分别是1、2、3 。这个文件就是记录每个服务器的ID
echo 1 >/usr/local/zookeeper-cluster/zookeeper-1/data/myid
echo 2 >/usr/local/zookeeper-cluster/zookeeper-2/data/myid
echo 3 >/usr/local/zookeeper-cluster/zookeeper-3/data/myid
(2)在每一个zookeeper 的 zoo.cfg配置客户端访问端口(clientPort)和集群服务器IP列表。
集群服务器IP列表如下
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
server.1=127.0.0.1:2881:3881
server.2=127.0.0.1:2882:3882
server.3=127.0.0.1:2883:3883
解释:server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
1.4 启动集群
启动集群就是分别启动每个实例。
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh start
启动后我们查询一下每个实例的运行状态
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
先查询第一个服务
Mode为follower表示是跟随者(从)
再查询第二个服务Mod 为leader表示是领导者(主)
查询第三个为跟随者(从)
1.5 模拟集群异常
(1)首先我们先测试如果是从服务器挂掉,会怎么样
把3号服务器停掉,观察1号和2号,发现状态并没有变化
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh stop
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
由此得出结论,3个节点的集群,从服务器挂掉,集群正常
(2)我们再把1号服务器(从服务器)也停掉,查看2号(主服务器)的状态,发现已经停止运行了。
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh stop
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
由此得出结论,3个节点的集群,2个从服务器都挂掉,主服务器也无法运行。因为可运行的机器没有超过集群总数量的半数。
(3)我们再次把1号服务器启动起来,发现2号服务器又开始正常工作了。而且依然是领导者。
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
(4)我们把3号服务器也启动起来,把2号服务器停掉,停掉后观察1号和3号的状态。
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh stop
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
发现新的leader产生了~
由此我们得出结论,当集群中的主服务器挂了,集群中的其他服务器会自动进行选举状态,然后产生新得leader
(5)我们再次测试,当我们把2号服务器重新启动起来启动后,会发生什么?2号服务器会再次成为新的领导吗?我们看结果
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
我们会发现,2号服务器启动后依然是跟随者(从服务器),3号服务器依然是领导者(主服务器),没有撼动3号服务器的领导地位。
由此我们得出结论,当领导者产生后,再次有新服务器加入集群,不会影响到现任领导者。
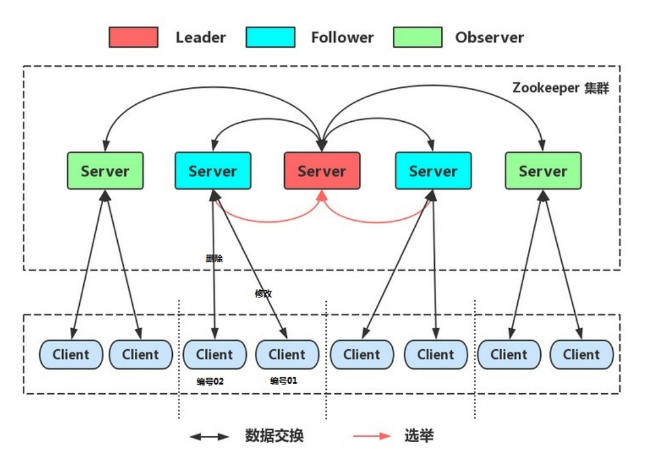
集群角色
ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了 Leader、Follower 和 Observer 三种角色。如下图所示
| 角色 | 说明 |
|---|---|
| Leader | 处理客户端事务请求(读写/增删改查),负责投票的发起和决议,更新系统状态。 |
| Follower | 处理客户端非事务请求(读/查),如果是写服务则转发给 Leader。参与Leader选举投票。 |
| Observer | 处理客户端非事务请求(读/查),如果是写服务则转发给 Leader。不参与Leader选举投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于 ZooKeeper3.3 系列新增的角色。 |
ZooKeeper 集群中的所有机器通过一个 Leader 选举过程 来选定一台称为 “Leader” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
Leader 选举
Leader选举规则:
Serverid:服务器ID
比如有三台服务器,编号分别是1,2,3。
编号越大在选择算法中的权重越大。
Zxid:数据ID
服务器中存放的最大数据ID。值越大说明数据越新,在选举算法中数据越新权重越大。
在Leader选举的过程中,如果某台 ZooKeeper 获得了超过半数的选票,则此ZooKeeper就可以成为Leader
当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,就会进入 Leader 选举过程,这个过程会选举产生新的 Leader 服务器。
Leader产生过程:
- Leader election(选举阶段):节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
- Discovery(发现阶段):在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
- Synchronization(同步阶段):同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
- Broadcast(广播阶段):到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
ZooKeeper 集群中的服务器状态有下面几种:
- LOOKING:寻找 Leader。
- LEADING:Leader 状态,对应的节点为 Leader。
- FOLLOWING:Follower 状态,对应的节点为 Follower。
- OBSERVING:Observer 状态,对应节点为 Observer,该节点不参与 Leader 选举。
ZAB 协议
Paxos算法:一种基于消息传递且具有高度容错特性的一致性算法。
Paxos算法解决的问题:快速正确的在一个分布式系统中对某个数据值达成一致,并且保证不论发生任何异常,都不会破坏整个系统的一致性。
Zab 借鉴了 Paxos 算法,特别为 Zookeeper 设计的支持崩溃恢复的原子广播协议。基于该协议,Zookeeper 设计为只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader 客户端将数据同步到其他 Follower 节点。即 Zookeeper 只有一个 Leader 可以发起提案。
ZAB 协议两种基本的模式:崩溃恢复和消息广播
崩溃恢复:当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致。
消息广播:当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了。 当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
📚参考资料
❤️Sponsor
您的支持是我不断前进的动力,如果您感觉本文对您有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用,拒绝白嫖,从你我做起!🥰🥰🥰
| 支付宝 | 微信 |
 |
 |



