1.局部敏感哈希(LSH)
Locality Sensitive Hashing:主要用于高效处理海量高维数据的最近邻问题 ,使得 2 个相似度很高的数据以较高的概率映射成同一个hash 值,而令 2 个相似度很低的数据以极低的概率映射成同一个 hash 值。
LSH详细内容请看:LSH原理与实现、LSH(局部敏感哈希)、深入浅出LSH
Locality Sensitive Hashing (LSH) Home Page (mit.edu)
2.布隆过滤器(BF)
Bloom filter:主要用于检索一个元素是否在一个集合中,1970年由布隆提出,它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。存储的数据是 0 或 1 ,默认是0,0代表不存在某个数据,1代表存在某个数据。
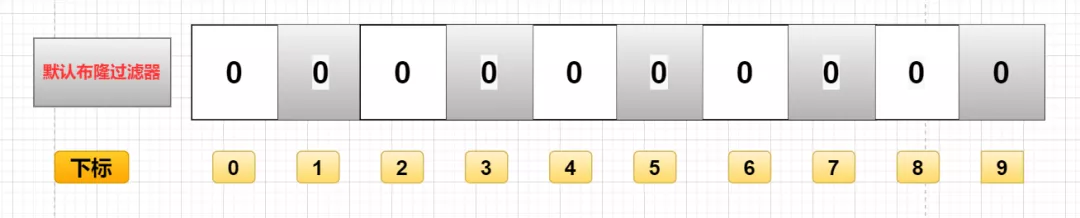
存入过程
布隆过滤器上面说了,就是一个二进制数据的集合。当一个数据加入这个集合时,经历如下洗礼:
- 通过 K 个哈希函数计算该数据,返回 K 个计算出的 hash 值
- 这 K 个 hash 值映射到对应的 K 个二进制的数组下标
- 将 K 个下标对应的二进制数据改成 1 。
例如,将“你好”存入布隆过滤器,第一个哈希函数返回 3,第二个第三个哈希函数返回 5 与 7 ,那么布隆过滤器对应的下标3,5,7的位置改成1。
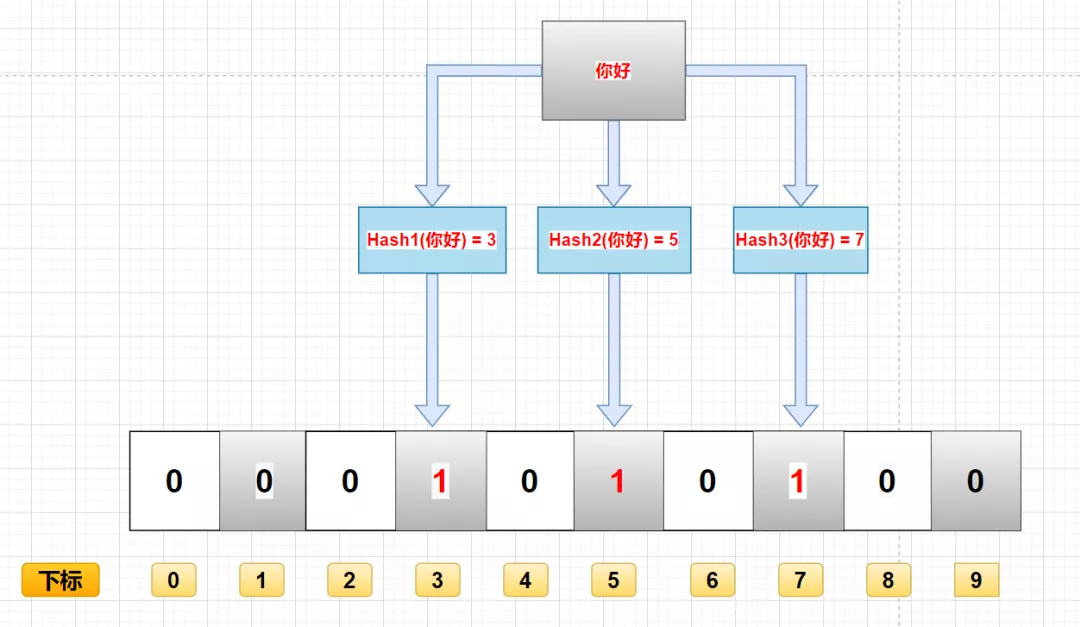
查询过程
布隆过滤器主要作用就是查询一个数据,在不在这个二进制的集合中,查询过程如下:
- 通过 K 个哈希函数计算该数据,对应计算出的 K 个 hash 值
- 通过 hash 值找到对应的二进制的数组下标
- 判断:如果存在一处位置的二进制数据是 0,那么该数据不存在。如果都是1,该数据存在集合中。
我们假设 BF 是一个 12bit 的二进制向量,{h1,h2}是两个哈希函数,{x,y,z}是一个集合。 用户想查询关键字 w,查询结果显示 w 在集合中不存在。

优缺点
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
添加数据是通过计算数据的 hash 值,那么很有可能存在这种情况:两个不同的数据计算得到相同的 hash值。这样查询的时候就会造成错误识别,同样如果已经存在有两个相同 hash 值的数据,删除时就会同时删除两个。
BF详细内容请看:最牛一篇布隆过滤器详解
Bloom filter 假阳性
Bloom filter 存在假阳性(false positive)的可能
- 假阳性表示实际是假但误辨为真的情况
Bloom filter 不存在假阴性(false negatives)的可能
- 假阴性表示实际是真但误辨为假的情况
也就是说,一次查询返回的结果是可能在集合里或者绝对不在集合里。
3.对偶编码函数
给定字符串 S1 = C1C2 … Cn 和二进制向量 S2 = b0b1 … bm-1 , S2 中每位元素的初始值为 0,其中 n < m .通过 Hash 函数 H,把 S1 中相邻 2 个字符散列映射为 0~(m -1) 之间的数,当且仅当 H ( Cj , Cj +1 ) = i 时,bi = 1。把 S1 → S2 的函数称为对偶编码函数。
在面向密文的多关键字模糊搜索方案中,构建索引、构建陷门和关键字查询的过程都是基于向量的操作过程。数据拥有者输入的关键字都由字符组成,由于字符的不可计算性,需要将其转换成向量的形式。
4.倒排索引
正排索引(forward index)
正排索引是指以文档 ID 为 Key,文档内容为 Value
倒排索引(inverted index)
倒排索引是指以文档内容为 Key,文档 ID 为 Value
举个例子🌰
例如,有 3 个文档及其对应关键词
| ID | 文档 | 关键词 |
|---|---|---|
| id1 | 《手机》 | 苹果、小米 |
| id2 | 《水果》 | 香蕉、苹果 |
| id3 | 《粮食》 | 小米、玉米 |
正排索引:
{id1,苹果,小米}、{id2,香蕉,苹果}、{id3,小米,玉米}
倒排索引:
{苹果,id1,id2}、{小米,id1,id3}、{香蕉,id2}、{玉米,id3}
两种索引优缺点
| 索引 | 优点 | 缺点 |
|---|---|---|
| 正排索引 | 易维护、构建方便 | 搜索耗时长 |
| 倒排索引 | 搜索耗时短 | 构建耗时、维护成本较高 |
5.安全最近邻算法(kNN)
KNN(k-nearest neighbour):就是 K 个最近的邻居的意思,说的是每个样本都可以用它最接近的 K 个邻近值来代表
安全K最近邻计算是 Wong 等人在2009年论文 Secure kNN computation on encrypted databases 提出的,用于计算两个加密数据库记录之间的距离。在一个安全的 KNN 计算中,所有的数据库记录都被扩展到 m 维的向量,并由 m位的向量 S 和两个 m × m 可逆矩阵 M1 和 M2 加密。
举个🌰
下图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?
KNN的算法过程是是这样的:

- 最小的圈K=3,第二个圈K=5
- 如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
- 如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
6.词频-逆文档频度(TF-IDF)
词频-逆文档频度(Term Frequency - Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用加权技术,用来评估一个词对于一个文档集或语料库中某个文档的重要程度,主要用在自动提取关键词算法中。
词频 (TF)
指的是某一个给定的词语在该文件中出现的次数。

逆文档频率(IDF)
以统计一篇文档的关键词为例,最简单的方法就是计算每个词的词频,出现频率最高的词就是这篇文档的关键词,但是一篇文章中出现频率最高的词肯定是“的”、“是”、“在”……这样的词,这些词显然不能反应文章的意思,此时就需要对每个词加一个权重,最常见的词(”的”、”是”、”在”)给予最小的权重,较少见的但能反应这篇文章意思的词给予较大的权重,这个权重叫做逆文档频率。
IDF 是一个词语普遍重要性的度量。如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。
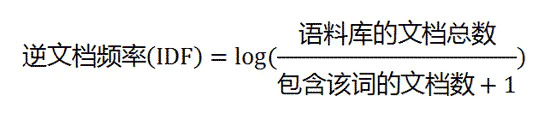
TF-IDF
知道了 TF 和 IDF 以后,将这两个值相乘,就得到了一个词的 TF-IDF 值。某个词对文章的重要性越高,它的 TF-IDF 值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。

可以看到,TF-IDF 与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的 TF-IDF 值,然后按降序排列,取排在最前面的几个词。
总结
字词的重要性随着它在文件中出现的次数成正比增加 ,但同时会随着它在语料库中出现的频率成反比下降 。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
TF-IDF详细内容请看:TF-IDF(词频-逆文档频率)介绍
7.波特词干算法(Porter stem)
从数据集中提取出的关键字集合进行“词根” 过滤,例如“walks”、“walking”、“walked”等近似的关键字,词根均为“walk”。后续的检索操作基于词根进行,大幅减少了计算量,且由于该操作只是在索引生成时执行一次,对整个系统的运行效率不会产生过大的影响。
8.分词算法(N-gram)
N-gram 模型是一种语言模型(Language Model,LM),N-gram 的基本思想是将文本里面的内容按照字节进行大小为 N 的滑动窗口操作,形成了长度是 N 的字节片段序列。每个字节片段即为 gram 。
- 当N=1 时称为
uni-gram - 当N=2 时称为
bi-gram- P(我帮你) = P(我) * P(帮|我) * P(你|帮)
- {“我帮”:1, “帮你”:2, “你帮”:3, “帮我”:4}
- 我帮你→[1,1,0,0]
- 你帮我→[0,0,1,1]
- 当N=3 时称为
tri-gram
例如输入为西安交通大学
uni-gram 形式为:西/安/交/通/大/学
big-ram形式为: 西安/安交/交通/通大/大学
tri-gram形式为:西安交/安交通/交通大/通大学
中文文本处理大多采用 bi-gram 进行分解,因为双字词出现概率比较大,即以大小为2的滑动窗口进行操作,切成长度为 2 的字节片段。
9.Top-k检索
旨在获取相似度后,将其作为打分结果,根据匹配到的文件的分数,按照顺序返回给用户分数排名最高的K份数据,是搜索引擎中最常见的模式。简而言之,就是使用户快速找到最相关的 k 个结果。
10.向量内积(点乘)
- a = [a1,a2,…,an]
- b = [b1,b2,…bn]
a 和 b 的内积公式为:a∙b = a1b1 + a2b2 + … + anbn
内积的几何意义
内积的几何意义是可以用来表征或计算两个向量之间的夹角,以及在 b 向量在 a 向量方向上的投影。
11.PRF&PRP
伪随机函数(PRF)和置换(PRP),它们是多项式时间可计算的函数,不能被任何可能的多项式时间对手从随机函数中区分出来。
PRP(pseudo random permutation,伪随机置换)和PRF(pseudo random function,伪随机函数)之间的区别,可以从定义来看
PRF
- F:K × X → Y
取一个密钥和集合 X 中的元素作为输入,输出值在集合 Y 中,现在唯一要求的是存在一个有效的算法来实现这个函数。也就是说,要有一个有效的函数来实现 K × X → Y 的映射。
PRP
- E:K × X → X
- 存在求解 E(K,X) 的高效确定性算法
- 函数 E(k,·) 是一对一的
- 存在高效的“逆算法” D(K,X)
与 PRF 不同的是,多了一个条件,那就是要有一个算法 D 可以实现逆运算。
在PRP中,存在一个有效算法,能够实现 K × X → X 映射关系,也就是说该算法能够将随机密钥 K 与集合 X 中的元素作为输入,同时输出值也是集合 X 中的元素,那么就要求每个元素一一对应。从本质上来说,E(K,X) 是对元素 x 的置换,为了解密的需要,就要求 E 是可逆的。
12.Homomorphic MAC
同态MAC:任何消息 mi 被加密为一个 degree-1 多项式 y(x)
- 即 y(0) = mi 和 y(α) = γi,其中 α 和 γi 只有验证者知道
- 即 y(x) = mi + ( γi −mi)∙x/α 成立。
- 由于云服务器在计算函数 f 时需要进行一些基本的算术运算,因此需要引入同态加密,对加密后的数据进行直接计算。
- f(γ1,···, γn) = y(α) —①
- f(m1 ,···, mn) = y(0) —②
- 在方程①建立的条件下,验证器可以验证方程②。因此,该技术可以验证云服务器是否诚实地执行用户定义的搜索算法
由于传统同态 MAC 仅支持有限域的计算,论文 VRFMS 采用了 realhomm-MAC,realhomm-MAC 的改进是将所有消息作为实数来处理,其编码格式类似于 IEEE 754 标准中定义的双精度浮点格式。也就是说,新算法在保留原算法同态的前提下能够处理实数。
13.SSE安全性
KPA<IND-SCKA<IND-CKA<IND-CKA2
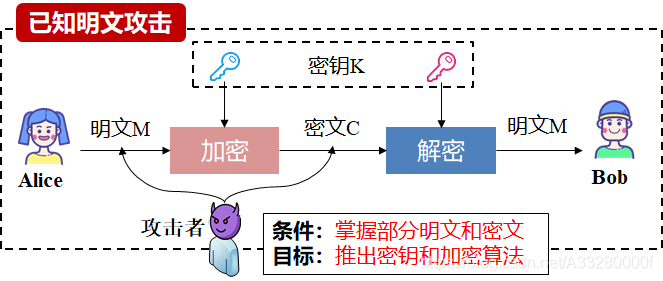
KPA
Known Plaintext Attack
知道部分的明文和密文对,推出密钥和加密算法
SCKA
selectivelychosen-keyword attack
选择性关键字攻击
它不能保证谓词的私密性,因为攻击者可以通过生成任意的明文-密文索引对 从陷门中推断出查询关键字。
IND-CKA1
- indistinguishability against chosen keyword attack
- 针对选择关键字攻击的不可区分性
- 保证文档内容不会被建立在其上的索引以及其他文档的索引泄漏
IND-CKA2
adaptively chosen-keyword attack
自适应选择关键字攻击
自适应攻击模型下满足抵抗选择性明文攻击的安全为CKA2
对手根据先前选择的查询及其陷门和搜索结果自适应地选择未来的每个查询。如果没有概率多项式时间(PPT)对手能够以不可忽略的优势区分真实项目和模拟项目,则该方案是自适应安全的,这是迄今为止基于SSE的关键字搜索最强大的安全模型。
参考:在 可搜索的对称加密:改进的定义和有效的构造 中,Curtmola 等人。为可搜索的加密方案提出非自适应和自适应(不可区分性和基于模拟器)的安全定义,通常称为IND-CKA1 和IND-CKA2。
14.双线性映射
1946年双线性对首先被法国数学家Weil提出并成为代数几何领域重要的概念和研究工具。
双线性映射可以用五元组 (p,G1,G2,GT,e) 来描述,G1,G2,GT 是三个素数阶乘法循环群,阶数皆为p,定义在这三个群上的一个映射关系e:G1*G2 —>GT,满足以下性质:
1、双线性性:对于任意a,b ∈ Zp 和 R,S ∈ G1,有e(Ra, Sb) = e(R, S)ab;
2、非退化性:存在R,S ∈ G1,使得 e(R, S) ≠ 1G2(1G2代表G2群的单位元);
3、可计算性:存在有效的算法对任意的 R,S ∈ G1,计算e(R, S)的值。
如果G1=G2则称上述双线性配对是对称的,否则是非对称的。
Sponsor❤️
您的支持是我不断前进的动力,如果您感觉本文对您有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用,拒绝白嫖,从你我做起!🥰🥰🥰
| 支付宝 | 微信 |
 |
 |



