本篇文章以小简看过的文献以及查阅的资料为基础,归纳和总结了可搜索加密(Searchable Encryption,SE)的相关知识点。
SE介绍
以下内容是小简阅读可搜索加密的两篇综述论文所总结,论文介绍如下
| 序号 | 论文名称 | 作者 年份 |
单位 | 来源 | 链接 |
|---|---|---|---|---|---|
| 1 | Survey on the Searchable Encryption | 李经纬 2015 | 南开大学 | Journal of Software | 原文 |
| 2 | Research Advances on Secure Searchable Encryption | 董晓蕾 2017 | 华东师范大学 | Journal of Computer Research and Development | 原文 |
可搜索加密(SE):旨在将数据文件进行加密后存储到云端,然后对密文进行检索的一种技术。
例如:用户为节约自身的资源开销,将文件外包给云服务器,但又不想云服务知道存储的文件内容,因此需要对文件采用某种加密方式加密后存储。此外,用户若想从云服务器中查询文件中的特定数据,只有合法的用户基于关键词检索对应的密文数据。
可搜索加密解决两类基本问题:
① 不可信赖服务器的存储问题
② 不可信赖服务器的路由问题
SE过程
①加密过程。用户使用密钥在本地对明文文件进行加密,并将其上传至服务器。
②陷门生成过程。具备检索能力的用户,使用密钥生成待查询关键词的陷门,要求陷门不能泄露关键词的任何信息。
③检索过程。服务器以关键词陷门为输入,执行检索算法,返回所有包含该陷门对应关键词的密文文件,要求服务器除了能知道密文文件是否包含某个特定关键词外,无法获得更多信息。
④解密过程。用户使用密钥解密服务器返回的密文文件,获得查询结果。

SE分类
按照应用模型分类
- ①一对一模式
- 用户加密个人文件并将其存储到不可信的服务器。只有该用户具备基于关键词检索的能力,服务器无法获取明文文件和待检索关键词的信息。

- ②多对一模式
- 多个发送者加密文件后,将其上传至不可信的服务器,以达到与单个接收者传送数据的目的。只有接收者具备基于关键词检索的能力,服务器无法获取明文文件信息,不同于单用户模型,多对一模式要求发送者和接收者不能是同一用户。

- ③一对多模式
- 单个发送者将加密文件上传至不可信服务器,然后多个接收者共享数据。
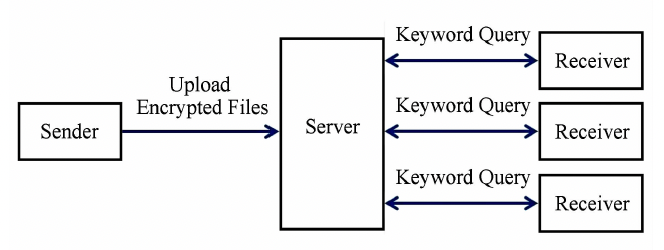
- ④多对多模式
- 在多对一模式的基础上,任意用户都可成为接受者,通过访问控制和认证策略后,具备关键词的密文检索方式提取共享文件的能力。只有合法的用户具备基于关键词检索的能力,服务器无法获取明文文件信息,具备广阔的应用前景。

按照解决策略分类
- ①对称可搜索加密(Symmetric searchable encryption, SSE)
- 旨在加解密过程中采用相同的密钥之外,陷门生成也需要密钥的参与,通常适用于单用户模型,具有计算开销小、算法简单、速度快的特点。
- ②非对称可搜索加密(Asymmetric searchable encryption, ASE)
- 旨在加解密过程中采用公钥对明文信息加密和目标密文的检索,私钥用于解密密文信息和生成关键词陷门。非对称可搜索加密算法通常较为复杂,加解密速度较慢,其公私钥相互分离的特点,非常适用于私钥生成待检索关键词陷门,通常适用于多对一模型。
- ③对称+非对称可搜索加密
- 由于非对称SE本身支持最基本形式的隐私数据共享,可通过共享密钥拓展到多对多的应用场景。对称SE虽然使用单用户模型,但计算开销小、速度快,更适用于大型文件数据的加密和共享。通过混合加密与基于属性加密技术相结合,或与代理重加密结合,也可构造共享方案。
- ④属性基加密(Attribute-based encryption, ABE)
- 它是指通过对用户私钥设置属性集(或访问结构)为数据密文设置访问结构(或属性集),由属性集和访问结构之间的匹配关系确定其解密能力。特别是密文策略的属性基加密(CP-ABE),其密文上的访问策略本身就是一种搜索策略,访问策略的表达能力从一定程度上反映了可搜索能力。
按照关键词数分类
- ①单关键词搜索:旨在用户在检索的过程中使用单关键词进行检索。
- ②多关键词搜索:旨在用户在检索的过程中使用多个关键词进行检索。
按照检索精度分类
- ①精确搜索:旨在搜索的过程中,只有当输入的关键词完全等于文件的索引值时才能检索出结果。
- ②模糊搜索:旨在搜索的过程中,用户输入的关键词与数据或索引中存在的关键词之间存在某种模糊的关系,并以这种模糊关系进行关键词匹配。模糊搜索分为以下两种架构:
- 使用编辑距离(edit distance):利用通配符和编辑距离构造一组与原始关键字相似的模糊关键字。
不支持多关键字排序搜索、搜索效率低 - 使用局部敏感哈希(LSH)和布隆过滤器(BF):通过LSH为每个文件生成Bloom过滤器。
搜索精度最多87%
- 使用编辑距离(edit distance):利用通配符和编辑距离构造一组与原始关键字相似的模糊关键字。
SE用途
- ①外包数据库字段加密
- ②云计算中隐私数据的保护和共享
- ③密文直接操作的相关应用
SE构造
- 基于索引:对于每一个关键字 W,建立一个索引,索引中包含所有含有该关键字的文件的指针。由于这种方案在更新数据的时候会对索引进行大量的修改,因此适合大量只读模式。
Z-IDX方案
SSE-1方案
- 基于存储结构:这种情况下没有索引,每次查询都是对文件进行一次扫描来寻找符合查询条件的文件。无疑,这种模式的查询效率会低很多,但是却更适合经常更新的存储系统。
- SWP方案
SE历史
- 2000年——D.Song等人首次提出了SE,有效地解决了对加密数据的搜索问题,保证了数据
的隐私不被泄露。论文链接 - 2010年——Jin Li等人提出了第一个支持模糊关键词搜索的解决方案。该方案使用编辑距离来表示关键字的相关性,并利用通配符*来构造模糊关键字集。论文链接
- 2012年——Qi Chai等人首次提出了采用基于树的索引和哈希链技术实现了可验证的SE方案。论文链接
- 2014年——Bing Wang等人提出了利用LSH和BF的体系结构提出了MFSE(加密数据上的多关键字模糊搜索)方案。该方案可以在不预先定义模糊关键字集的情况下对返回的结果进行排序。论文链接
- 。。。。。。
SE未来
未来的工作还应该关注如何应用SE的基本思想来处理其他类型的数据。
例如:
- 如何搜索包含图像数据或视频数据的加密媒体数据;
- 如何搜索包含关系数据库或非关系数据库的加密数据库;
- 如何搜索结构化的社交网络数据(空间数据)。
SSE安全性
当SSE方案是安全的:
(1)仅密文不揭示关于数据的任何信息;
(2)密文与搜索令牌一起最多揭示了搜索的结果;
(3)只能使用密钥生成搜索令牌。
服务器可以了解到一些关于客户端查询的有限信息。例如它知道正在搜索的关键字都包含在加密为$c_{w}$ 的文件中。
KPA < IND-SCKA < IND-CKA1 < IND-CKA2
KPA
Known Plaintext Attack
知道部分的明文和密文对,推出密钥和加密算法
SCKA
selectivelychosen-keyword attack
选择性关键字攻击
它不能保证谓词的私密性,因为攻击者可以通过生成任意的明文-密文索引对 从陷门中推断出查询关键字。
IND-CKA1
- indistinguishability against chosen keyword attack
- 针对选择关键字攻击的不可区分性
- 保证文档内容不会被建立在其上的索引以及其他文档的索引泄漏
- 然而,在可搜索的对称加密:改进的定义和高效的结构中提出到,只有当搜索查询独立于 $(\gamma, c)$ 和先前的搜索结果时,CKA1 才提供安全性。为了解决这个问题,提出了更强的CKA2。
- 只有当客户的查询独立于索引和先前的结果时,CKA1才能保证安全性。
IND-CKA2
adaptively chosen-keyword attack
自适应选择关键字攻击
自适应攻击模型下满足抵抗选择性明文攻击的安全为CKA2
对手根据先前选择的查询及其陷门和搜索结果自适应地选择未来的每个查询。如果没有概率多项式时间(PPT)对手能够以不可忽略的优势区分真实项目和模拟项目,则该方案是自适应安全的,这是迄今为止基于SSE的关键字搜索最强大的安全模型。
即使客户端的查询是基于加密的索引和先前查询的结果,CKA2也能保证安全性。
UC-Secure
- 最近,Kurosawa和Ohtaki提出了更强的通用可组合How to Construct UC-Secure Searchable Symmetric Encryption Scheme(UC-Secure)SSE概念。粗略地说,即使在任意环境中使用该方案时,也能保证安全性。
参考:在 可搜索的对称加密:改进的定义和有效的构造 中,Curtmola 等人。为可搜索的加密方案提出非自适应和自适应(不可区分性和基于模拟器)的安全定义,通常称为IND-CKA1 和IND-CKA2。
今年来关于对称可搜搜加密的研究主要集中于对于动态可搜索加密中的前向安全和后向安全。
前向安全指的是:在插入新的文件后,之前的搜索不能匹配到新添加的文件。
后向安全指的是:插入在删除文件后,搜索不会暴漏该文件的标识。
前向隐私(Forward privacy)和后向隐私(Backward privacy)是DSSE(Dynamic Searchable Symmetric Encryption)的两个基本属性,旨在控制动态方案中更新操作造成的信息泄露。
前向隐私:服务器无法将当前添加的关键字与之前搜索的结果相关联。即服务器不知道当前添加的关键字是否之前搜索过。(先搜索后更新)。
后向隐私:服务器无法将当前搜索的关键字与之前的更新相关联。即服务器不知道更新(添加或删除)历史(先更新后搜索)。
Sponsor❤️
您的支持是我不断前进的动力,如果你觉得本文对你有帮助,你可以请我喝一杯冰可乐!嘻嘻🤭
| 支付宝支付 | 微信支付 |
 |
 |



