SE 论文阅读
论文清单
| 序号 | 论文名称 | 作者 年份 |
单位 | 来源 | 等级CCF |
|---|---|---|---|---|---|
| 1 | Practical Techniques for Searches on Encrypted Data | D.Song 2000 | 加州大学伯克利分校 | IEEE S&P | A |
| 2 | Multi-Keyword Fuzzy Search over Encrypted Data | 王恺璇 2017 | 东北大学 | 计算机研究与发展 | —— |
| 3 | Toward Efficient Multi-Keyword Fuzzy Search Over Encrypted Outsourced Data With Accuracy Improvement | 傅张杰2016 | 南京信息工程大学 | IEEE TIFS | A |
| 4 | Efficient dynamic multi-keyword fuzzy search over encrypted cloud data | 洪忠 2020 | 安徽大学 | ELSEVIER JNCA | C |
| 5 | VRFMS: Verifiable Ranked Fuzzy Multi-keyword Search over Encrypted Data | 李兴华 2022 | 西安电子科技大学 | IEEE TSC | B |
| 6 | EliMFS: Achieving Efficient, Leakage-Resilient, and Multi-Keyword Fuzzy Search on Encrypted Cloud Data | 陈静 2017 | 武汉大学 | IEEE TSC | B |
论文简介
如下是对上方清单中论文内容做一个简单的概述,以方便你快速了解论文所研究内容
[1] Practical Techniques for Searches on Encrypted Data(搜索加密数据的实用技术)
| 多关键字 | 模糊搜索 | 可验证搜索 |
|---|---|---|
| ❌ | ❌ | ❌ |
- 简要内容:本文首次提出了
一种搜索加密数据的实用技术(SWP),该方案通过将明文数据划分成一个个的单词,分别加密每个单词,然后将一个哈希值(具有特殊格式)嵌入密文中,服务器可以提取该哈希值,并检查该值是否具有这种特殊格式,确认是否匹配搜索。
[2] Multi-Keyword Fuzzy Search over Encrypted Data(MKFS:面向多关键字的模糊密文搜索方法)
| 多关键字 | 模糊搜索 | 可验证搜索 |
|---|---|---|
| ✅ | ✅LSH+BF | ❌ |
- 简要内容:本文提出了
一种面向多关键字的模糊密文搜索方案(MKFS),该方案以布隆过滤器为基础,使用对偶编码函数和局部敏感哈希函数来对文件索引进行构建,并使用距离可恢复加密算法对该索引进行加密,实现了对多关键字的密文模糊搜索。同时方案不需要提前设置索引存储空间,从而大大降低了搜索的复杂度。除此之外,该方案与已有方案相比不需要预定义字典库,降低了存储开销。实验分析和安全分析表明,该方案不仅能够实现面向多关键字的密文模糊搜索,而且保证了方案的机密性和隐私性。
[3] Toward Efficient Multi-Keyword Fuzzy Search Over Encrypted Outsourced Data With Accuracy Improvement(TEMKFS:通过提高准确性,在加密的外包数据上实现高效的多关键字模糊搜索)
| 多关键字 | 模糊搜索 | 可验证搜索 |
|---|---|---|
| ✅ | ✅LSH+BF | ❌ |
- 简要内容:本文提出了
一种高效多关键词模糊排名搜索方案,使用局部敏感哈希和布隆过滤器来实现模糊关键字搜索,首先开发了一种基于 uni-gram 关键字转换新方法,它将同时提高准确性并创建处理其他拼写错误的能力。此外,可以使用词干分析算法查询具有相同根的关键字。此外,在选择适当的匹配文件集时,该方案会考虑关键字权重。使用真实数据进行的实验表明,我们的方案实际上效率高,精度高。
[4] Efficient dynamic multi-keyword fuzzy search over encrypted cloud data(EDMKFS:对加密的云数据进行高效的动态多关键字模糊搜索)
| 多关键字 | 模糊搜索 | 可验证搜索 | 动态更新 |
|---|---|---|---|
| ✅ | ✅LSH+BF | ❌ | ✅ |
- 简要内容:本文提出
一种支持动态文件更新的加密云数据动态多关键字模糊搜索方案。局部性敏感散列和布隆过滤器用于生成索引向量和查询向量。基于生成的向量,构建平衡二叉树作为整个文件集的索引,并开发Top-k 搜索算法,借助索引树搜索与给定查询最相关的 k 个文件。在真实数据集上进行的广泛实验表明,我们的方案比现有的类似方案更有效。
[5] VRFMS: Verifiable Ranked Fuzzy Multi-keyword Search over Encrypted Data(VRFMS:可验证排序模糊多关键字密文搜索)
| 多关键字 | 模糊搜索 | 可验证搜索 | 动态更新 |
|---|---|---|---|
| ✅ | ✅LSH+BF | ✅ | ✅ |
- 简要内容:本文提出了
一种高效且可验证排序模糊多关键字密文搜索方案(VRFMS),使用局部敏感哈希和布隆过滤器来实现模糊关键字搜索,并采用词频-逆文档频度(TF-IDF) 对查询结果进行排序。为了进一步提高搜索准确性,还设计了一种改进的bi-gram 关键字转换方法。此外,利用同态MAC技术和随机质询技术分别验证了返回结果的正确性和完整性。形式安全分析和实证实验表明,VRFMS在实际应用中分别具有安全性和有效性。
[6] EliMFS: Achieving Efficient, Leakage-Resilient, and Multi-Keyword Fuzzy Search on Encrypted Cloud Data(EliMFS:在加密的云数据上实现高效、防泄漏和多关键字模糊搜索)
| 多关键字 | 模糊搜索 | 可验证搜索 |
|---|---|---|
| ✅ | ✅LSH+BF | ❌ |
- 简要内容:本文提出了
一种基于加密云数据的高效泄漏弹性多关键字模糊搜索 (EliMFS) 框架。在这个框架中,利用了一种新颖的两阶段索引结构(由正向索引和倒排索引组成)来确保搜索时间与文件集大小无关。多关键字模糊搜索通过基于 Gram Counting Order、布隆过滤器和局部敏感散列的精细设计实现的。此外,考虑到由两阶段索引结构引起的泄漏,我们提出了两种具体的方案来抵抗不同威胁模型中的这些潜在攻击。广泛的分析和实验表明,我们的方案是高效和抗泄漏的。
①SWP方案
论文名称:《Practical Techniques for Searches on Encrypted Data》
该篇论文是 SE 的开山之作,这是首次研究出支持对数据加密后进行搜索的密码技术,提出了第一个实用的可搜索加密方案 SWP,由此开辟了密码学中的全新研究方向——可搜索加密(Searchable Encryption)。
- 作者:Dawn Xiaoding Song、D. Wagner, and A. Perrig.S
- 单位:University of California, Berkeley
- 刊物:Proceedings of the 2000 IEEE Symposium on Security and Privacy【CCF A】
- 时间:2000年5月
- 被引次数:5010(截至2024年5月20日,来源Google Scholar)
1、总体思路
该方案通过将明文数据划分成一个个的单词,分别加密每个单词,然后将一个哈希值(具有特殊格式)嵌入密文中,服务器可以提取该哈希值,并检查该值是否具有这种特殊格式,确认是否匹配搜索。
2、方案实现
加密过程

将明文数据拆分为固定大小的单词 Wi
并使用确定性加密算法 E 进行加密 E(Wi) = Xi
然后将加密的单词 Xi 划分为左右两部分 Xi = <Li,Ri>。
使用带密钥的 Hash 函数 f 对 Li 进行哈希运算,k’ 为固定密钥,计算得到新密钥 ki = fk’(Li)
借助流密码产生伪随机值 Si,用于带密钥的 Hash 函数 F 来对值 Si 做哈希运算,以 ki 为密钥,得到Fki(Si)
将 Si 与 ,Fki (Si) 拼接得到 Yi = <Si,Fki(Si)>
最终将 Yi 与 Xi 异或得到最后的密文 Ci = Xi ⊕ Yi,上传至不可信服务器
检索过程
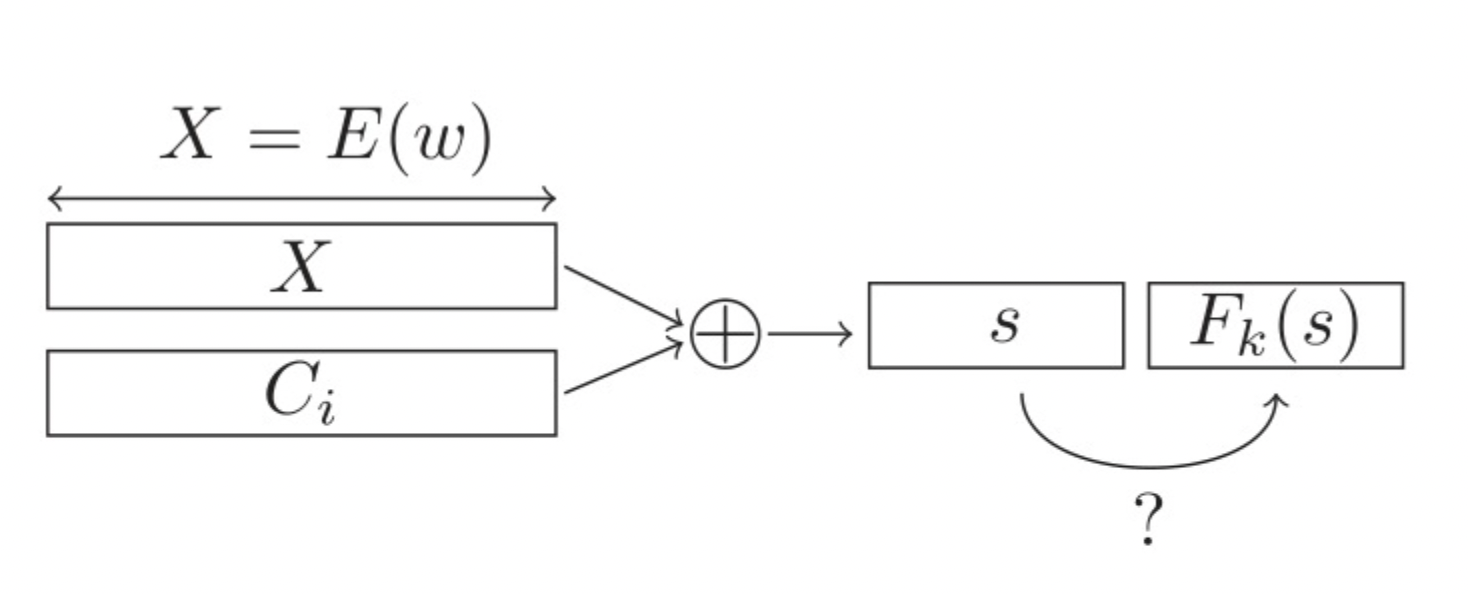
- 把要查询的关键词对应的 Xi 和 ki 告知服务器来进行检索,生成方式与加密过程相同。
- 服务器得到 Xi 和 ki 后,先计算 Yi = Ci ⊕ Xi
- 将 Yi 划分为 YiL 和 YiR ,即 Yi = <YiL,YiR >
- 使用带密钥的 Hash 函数 F 对 YiL 进行加密,以 ki 为密钥,将结果与 YiR 比较,相同则检索成功。
解密过程
将 Si 划分为 SiL 和 SiR,Ci 划分为 CiL 和 CiR,即 Si = < SiL,SiR>,Ci = <CiL,CiR>
SiL 和 CiL 异或得到 Li,即 Li = SiL ⊕ CiL
使用带密钥的 Hash 函数 f 对 Li 进行运算,以 k’ 为密钥,得到新的密钥 ki
使用带密钥的 Hash 函数 F 对进行加密,以为 ki 密钥,得到 Fki(Si)
Fki(Si) 和 CiR 异或得到 Ri,即 Ri = Fki(Si) ⊕ CiR
拼接 Li 和 Ri 得到 Xi,使用加密算法 E 的解密算法解密即可
3、总结
本文给出的可搜索加密方案,还有很大的可扩展空间:
- ①支持高级的查询:本文涉及的查询都是简单的单个关键字的查询,但是传统的数据库高级语言(SQL语言)却支持更为高级的布尔查询等查询模式,设计一种实现支持析取、合取范式的查询模式也很有必要;另外,模糊查询也可以和可搜索加密技术结合起来。
- ②支持变长关键字查询:i> 使用固定长度的、足够长的块,从而能够容纳所有的查询关键字;ii>使用变长的关键字,但是在关键字中要包含关键字的字长信息;
- ③基于索引的查询,基于索引的方案在查询效率上是一般方案的数倍,但是在索引更新上却有很大的提升空间。
看完文章两篇综述和这篇论文后,导师给我的建议是把看论文的重心放在对称可搜索加密(SSE)方向上,SSE方案具有计算开销小、算法简单、速度快的特点,导师着重让我看关于基于索引的多关键字查询、模糊查询、可验证的查询这三个方向。
②MKFS方案
论文名称:《Multi-Keyword Fuzzy Search over Encrypted Data》
- 作者:王恺璇、李宇溪、周福才、王权琦
- 单位:东北大学
- 刊物:计算机研究与发展
- 时间:2017年5月
1、总体思路
该方案利用布隆过滤器和局部敏感哈希函数技术,来实现多关键字的密文模糊搜索。主要研究内容包括:将上传文件利用对偶编码函数将其关键字转换成向量,再利用局部敏感哈希函数将其映射到布隆过滤器中;服务器在执行密文搜索时,需要先对输入的查询关键字进行上述转换,再通过计算安全索引参数和陷门的内积来搜索到符合条件的密文文件。
2、使用技术
- 局部敏感哈希函数
- 布隆过滤器
- 安全近邻算法
- 对偶编码函数
3、方案实现
本方案主要由 4 个主要算法组成:密钥生成算法、索引生成算法、陷门生成算法、搜索算法
sk ← KeyGen(1k ):密钥生成算法
- 运行于数据拥有者端,用于生成加密索引和查询关键字的密钥。
- 输入安全参数 1k,输出密钥 sk 。
I ← BuildIndex(sk , F , W):索引生成算法
- 运行于数据拥有者端,用于生成文件对应的安全索引。
- 输入密钥 sk 、文件标记序号 F、文件 F 对应的关键词集合 W ,输出安全索引 I 。
t ← Trapdoor(sk , Q):陷门生成算法
- 运行于用户端,用于加密查询关键字集合生成安全陷门。
- 输入密钥 sk 、查询关键词集合 Q ,输出安全陷门 t 。
FR ← Search(I , t):搜索算法
- 运行于第三方服务器端。用于安全索引与安全陷门的匹配。
- 输入安全索引I 和安全陷门 t ,输出文件序列集合 FR。
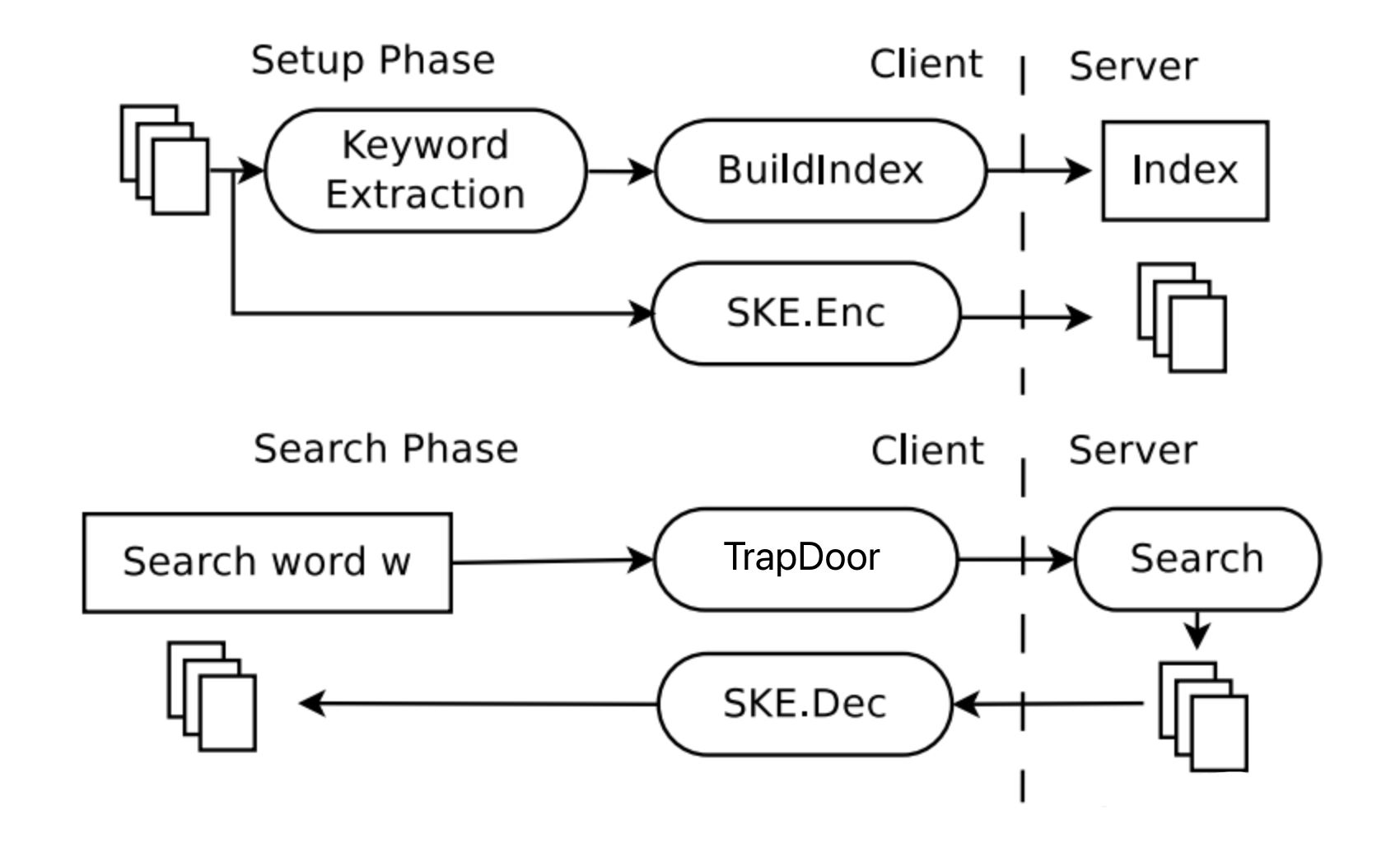
密钥生成算法
sk ← KeyGen(1k ) 生成密钥,具体步骤如下(k≥128):
(1)随机构建 2 个 k × k 维的矩阵 M1 , M2 ∈ Rk × k
(2)随机构建一个 k 维的向量 S ∈ { 0 , 1 }k ,且 S 中 0 和 1 的数量需要大致相同
(3)输出 sk =( M1 , M2 , S )作为生成加密索引和生成陷门的密钥
索引生成算法
I ← BuildIndex(sk , F , W)生成安全索引,具体步骤如下:
(1)数据预处理
- 对于文件集合 F = { f1 , f2 ,…, fn }中的每一个文件 fi 所对应的关键字集合 Wi = { w1 , w2 ,…, wt },使用对偶编码函数将其转换成向量集合 V = { v1 , v2 ,…, vt },其中每个向量 vi ∈ {0,1}676 ;
(2)构建索引
- ① 为文件 fi 构建一个 k bit 的布隆过滤器 Bi,初始化为0
- ②对于向量集合 V = { v1 , v2 ,…, vt } 中的每个向量 vi,使用局部敏感哈希函数 { H1 , H2 ,…, Hl } 进行计算(H1(vi) , H2(vi) ,…, Hl(vi) ),并将结果插入到布隆过滤器 Bi 。
(3)索引加密
将密钥 sk 中的 S 表示为 S = (s1 , s2 ,…, sk)。对于每一个文件 fi 所得到的布隆过滤器 Bi
- ① 随机选择参数 r ∈ R
- ② 将 Bi 表示为 Bi = ( b1 , b2 ,…, bk)。 Bi 与 S 具有同样的结构,均为由 {0,1} 组成的 k 位向量。对于 Bi 中的每一个 bj ,
- 若在 S 中对应的 sj = 1 ,则令 b’j = b’’j = bj
- 若在 S 中对应的 sj =0,则令 b’j = 1/2bj + r 、b’’j = 1/2bj - r
- ③ 令 B’i = ( b’1 , b’2 ,…, b’k),B”i = ( b”1 , b”2 ,…, b”k)
- ④ 计算 I’i = M1T • B’i , I”i = M2T • B”i
- ⑤ 令 Ii = (I’i ,I”i )
- ⑥输出索引 I = ( F , I1 , I2 ,…, In )
陷门生成算法
t ← Trapdoor(sk , Q) 根据查询关键词集合生成安全陷门,具体步骤如下:
(1)构建一个 k 位的布隆过滤器 B 。
(2)对于查询关键字集合 Q = { q1 , q2 ,…, qt },使用对偶编码将其转换成向量集合 V = { v1 , v2 ,…, vt } 中每个向量 vi ∈ {0,1}676 ,使用局部敏感哈希函数 { H1 , H2 ,…, Hl } 进行计算(H1(vi) , H2(vi) ,…, Hl(vi) ),并将结果插入到布隆过滤器 B 。
(3)将密钥 sk 中的 S 表示为 S = (s1 , s2 ,…, sk)。对于布隆过滤器 B
- ① 随机选择参数 r’ ∈ R
- ② 将 Bi 表示为 Bi = ( b1 , b2 ,…, bk)。 Bi 与 S 具有同样的结构,均为由 {0,1} 组成的 k 位向量。对于 B 中的每一个 bj ,
- 若在 S 中对应的 sj = 0 ,则令 b’j = b’’j = bj ,
- 若在 S 中对应的 sj = 1,则令 b’j = 1/2bj + r’ 、b’’j = 1/2bj - r’
- ③ 令 B’ = ( b’1 , b’2 ,…, b’k),B” = ( b”1 , b”2 ,…, b”k)
- ④ 计算 t’ = M1-1 • B’ , t” = M2-1 • B”
- ⑤ 令 t = (t’,t” )
(4)输出陷门 t 。
搜索算法
FR ← Search(I , t)服务器根据陷门和加密索引执行搜索,具体步骤如下:
- (1)令 FR 为一个初始为空的文件集合
- (2)将索引 I 表示为 I = ( F , I1 , I2 ,…, In ) 对于每一个 Ii
- ① 将 Ii 表示为 Ii = (I’i ,I”i ) ,将 t 表示为 t = (t’,t” )
- ② 计算向量的数量积: RI = I’i • t’ + I”i • t”
- ③ 按排序算法将计算的向量内积作排序,将排序序列中的前 λ 条记录加入到结果集合 FR 中
- (3)输出 FR 作为最终搜索结果
4、总结
与已有方案相比,本方案不需要提前设置索引存储空间,从而大大降低了搜索的复杂度;同时,该方案不需要预定义字典库,降低了存储开销。
MKFS 没有显示关键字和文件之间的相关性。对于不同文件中相同的关键字,其关键字权重应该不同,在排序时要考虑这种差异。因此,与查询关键字更相关的文件可能不会包含在返回结果中。
③TEMKFS方案
论文名称:《Efficient dynamic multi-keyword fuzzy search over encrypted cloud data》
- 作者:傅张杰; 吴心乐; 关朝文; 孙兴明; 任奎
- 单位:安徽大学
- 来源:IEEE Transactions on Information Forensics and Security 【CCF A】
- 时间:2016年7月
1、总体思路
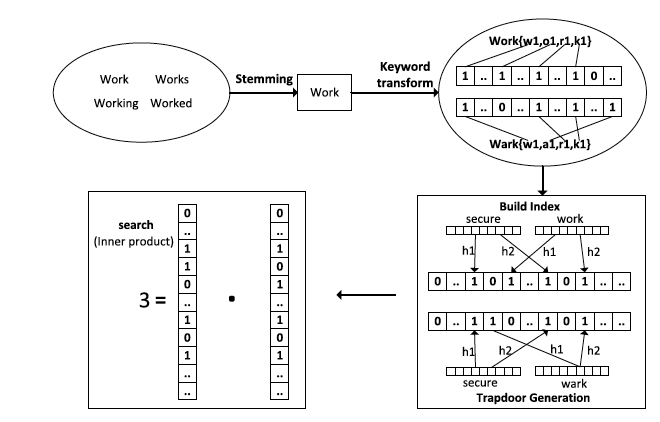
该方案利用局部敏感哈希和布隆过滤器来实现模糊关键字搜索,开发了一种基于 uni-gram 关键字转换新方法。此外,使用词干分析算法查询具有相同根的关键字。在选择适当的匹配文件集时,该方案会考虑关键字权重。
本文的主要贡献归纳如下:
- 1.开发了一种基于 uni-gram 的关键词转换新方法。对于一个字母的拼错,该方法减小了拼错关键字与正确关键字之间的欧几里德距离。此外,我们引入词干提取算法来获取单词的词根。
- 2.在构建结果的排名列表时考虑关键字权重。与关键字更相关的文件将有更大的机会出现在列表的首位。
- 3.使用真实数据集来实施和评估我们提出的方案。实验结果表明,本文提出的算法具有较高的精度。
2、使用技术
- 局部敏感哈希函数
- 布隆过滤器
- 安全近邻算法
- uni-gram 关键字变换
- 波特词干算法
- 词频-逆文档频度(TF-IDF)
3、方案实现
4、总结
引入了基于uni-gram 模型的 porter 词干提取算法和关键字转换算法,极大地提高了模糊搜索精度。然而,仅使用术语频率对结果进行排序,这会导致排序结果不准确和高计算开销。
④EDMKFS方案
论文名称:《Efficient dynamic multi-keyword fuzzy search over encrypted cloud data》
- 作者:洪忠,詹飞利,杰翠,岳孙,陆流
- 单位:安徽大学
- 来源:Journal of Network and Computer Applications【CCF C】
- 时间:2020年1月
- 方案效率
- 精确搜索100%
- 模糊搜索85%
1、总体思路
该方案利用局部性敏感散列和布隆过滤器用于生成索引向量和查询向量。基于生成的向量,构建平衡二叉树作为整个文件集的索引,并开发 Top-k 搜索算法,借助索引树搜索与给定查询最相关的 k 个文件。
本文的主要贡献归纳如下:
- 1.开发了一种动态多关键字模糊搜索方案,实现了容错的多关键字模糊搜索,并支持
文件的高效动态更新。 - 2.引入一种平衡二叉树来组装所有布隆索引向量。基于此树,一个搜索请求的搜索时间为O(rlogn),优于以往类似的模糊搜索方案。
- 3.通过综合实验,验证了该方案的有效性。
2、使用技术
- 局部敏感哈希函数
- 布隆过滤器
- 安全近邻算法
- uni-gram 关键字变换
- 平衡二叉树
- 词频-逆文档频度(TF-IDF)
- Top-k 搜索算法
3、方案实现
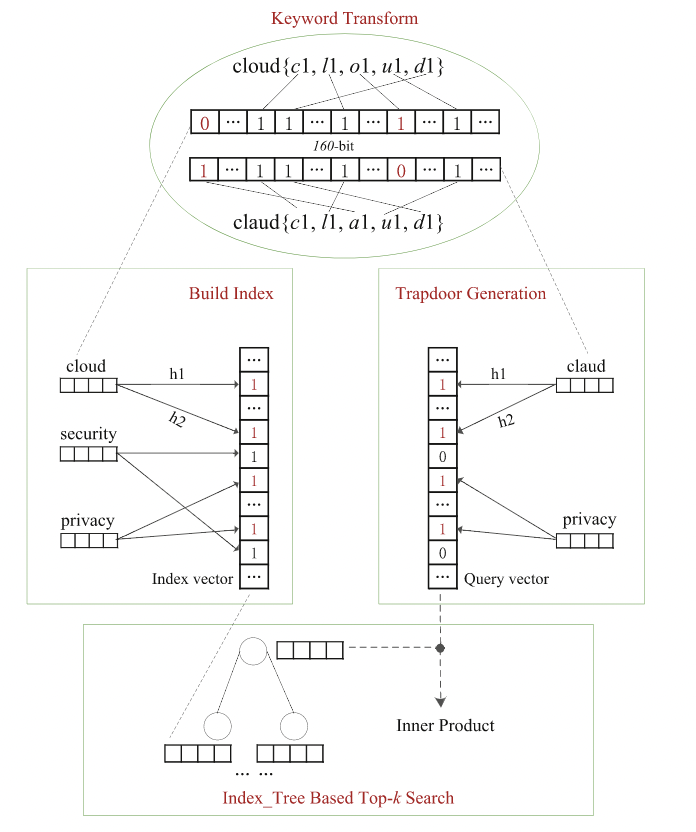
基于 uni-gram 的关键字转换
从文件集合中提取的关键字首先转换为 uni-gram 向量表示,以便使用 LSH 函数进行映射
- 首先,每个关键字被分割成一个 uni-gram 集合。
- 例如,关键字 “secure” 被转换为{s1,e1,c1,u1,r1,e2},其中 “e1” 是 “secure” 中的第一个 “e”,而“e2” 是第二个 “e”。
- uni-gram 集合用一个 160 位的向量表示,向量组成为 26∗5+30 bits,其中 26∗5 bits 代表 26∗5 个字母,30 bits 表示常用的符号和数字。如果给定的位表示相应的 uni-gram,则将其设为 1。
通过这种方式,不同的关键字被转换为 160 位长度的向量表示。拼写错误的关键字仍然可以转化为与其对应的正确关键字高度相似的向量。
基于BF的索引/查询向量
将原始关键字转换为向量后,使用 LSH 函数将向量映射到 Bloom filter。为每个文件生成一个 m 位 Bloom 过滤器,并将其所有关键字向量散列到 Bloom 过滤器上。每个关键字向量都用 l 个不同的 LSH 函数散列在不同的位置上,它们对应的位置设置为 1。在实现过程中,数字 “1” 被替换为关键字权重 TF,以反映关键字和文件的相关性。
- TFi,j = 1 + |wj| / |fj|
- |wj| 是在 fi 中关键字 wj 的数量
- |fj| 是在 fi 中所有关键字的数量
查询向量和索引向量的内积(即 Score)反映了查询和文件的相关性
通常,Score > 0 表示文件包含查询关键字。但由于布隆过滤器的假阳性,上述情况并非如此。在所提出的方案中,该阈值被设置为TH = l,这意味着根据查询只会选择 Score ≥ TH 的文件
索引树的构造
为了提高模糊搜索的效率,该方案引入了一个平衡的二叉树来组装所有的布隆索引向量。因此,将只检索最需要的文件,从而避免遍历树中的所有索引向量。
索引树的结构:
如果(n = 2k),(k = 1,2,3,···):每对叶节点 D2k−1 和 D2k 都会生成一个父节点 Du,每个父节点 Du 存储一个满足 Du[i] = max{D2k−1[i],D2k[i]}的 m 位向量;n为文件个数
如果(n = 2k+1),(k = 1,2,3,···):前 D2k 叶节点以上方同样的方式进行整合。此外,第 2k+1 个叶节点 D2k+1 与第 D2k 个节点的父节点进行整合。
每个叶节点与一个文件相关联,存储相应文件的标识符和布隆索引向量。
内部节点基于叶节点生成。
父节点索引向量中的值是子节点索引向量中相应位的较大值。
- 例如,r21[3] = max{f1[3],f2[3]} = max{1.5,1} = 1.5。
这样子节点就被它们的父节点覆盖,这意味着一旦父节点中的索引向量不满足搜索条件,它们的子节点就会被忽略。
基于索引树的 top-k 搜索
方案中使用的搜索算法是由 Xia 等人(2016)提出的 GDFS(贪婪深度优先搜索)
为在平衡二进制树(KBB)上搜索顶级相关文件而设计的算法与基于 Bloom 索引向量的树非常兼容。
如图所示(GDFS),构造了一个搜索结果列表,即 RList,它由 k 条记录组成,每条记录定义为 <RScore,FID>。
- RScore 表示 fFID 文件与给定查询的关联分数。它是索引向量与查询向量(陷门向量)的内积的值。
- RList 中的这 k 条记录对应于搜索的文件,因此这个列表根据它们与给定查询的相关性,以及它们的 RScore,按照降序排序。我们将 RList 中最小的 RScore 表示为第 k 个分数,初始化为阈值 TH,在搜索过程中可以修改。
由于子节点被其父节点覆盖,搜索算法可以更快,这是因为进程只需要搜索索引树的一小部分,而不是整个树。例如,对于文件集合 f = {f1,f2,…,f7},k = 2,阈值 TH = 2,查询向量将为 q =(0,1,1,0,0),搜索过程如图所示

在这个例子中,在文件集合 f = {f1,f2,…,f7},我们搜索最相关的 2 个文件(k=2)到查询 q = (0,1,1,0,0)。这里,相关阈值 TH = 2。搜索过程从根节点开始。相关性得分Sr = 2.7 > TH = 2(因为查询向量第2,3位为1,所以计算Score是计算2,3位数字之和),搜索 r11,因为Sr11 = 2.7 > Sr12= 2.2 > TH。在下一跳中,r21 在搜索中被选中,后面跟着 f1。Sf1 = 2.7 > TH,将 f1 添加到结果列表中,返回到 r21,当搜索到达 f2 时,添加 f2。注意,Sr22 = 1 < TH,因此进程将停止搜索其子节点,然后搜索 f7,Sf7 = 2.2 > Sf2 = 2.1 > TH,因此 f2 被删除,f7 被添加到结果列表中。最后,我们得到搜索结果 f1,f7
⑤VRFMS方案
论文名称:《VRFMS: Verifiable Ranked Fuzzy Multi-keyword Search over Encrypted Data》
- 作者:李兴华; 童秋云; 赵金伟; 苗银斌; 马思琪; 翁健; 马剑峰; Kim-Kwang Raymond
- 单位:西安电子科技大学
- 刊物:IEEE TRANSACTIONS ON SERVICES COMPUTING【CCF B】
- 时间:2022年1月
- 方案精度
- 精确搜索100%
- 模糊搜索91%
1、总体思路
该方案首先对现有的 LSH 和 BF 体系结构进行了改进,以实现高精度的模糊关键字搜索。随后分别引入同态 MAC 和随机挑战技术来验证返回结果的正确性和完整性。
本文的主要贡献归纳如下:
- (1)使用 LSH、BF 和 TF-IDF 支持模糊多关键字搜索
- (2)设计了一种改进的 bi-gram 关键字变换方法,考虑到相同 bi-gram 的出现,进一步提高了模糊关键字搜索的准确性,最高准确率可达 91%
- (3)利用同态 MAC 和随机挑战技术来保证搜索结果的正确性和完整性。
2、使用技术
- 局部敏感哈希函数
- 布隆过滤器
- 安全近邻算法
- bi-gram 关键字变换
- 波特词干算法
- 词频-逆文档频度(TF-IDF)
3、方案实现

密钥生成算法
KeyGen(1λ, m)→SK具体步骤如下:(λ:随机安全参数,m:索引长度)
(1)根据安全参数 λ,数据所有者调用 RealHomMac,生成密钥(K,α)
(2)随机构建 2 个(m+2) × (m+2) 维的矩阵 M1 , M2 ∈ R(m+2) × (m+2)
(3)随机构建一个 m+2 维的向量 S ∈ { 0 , 1 }m+2 ,且 S 中 0 和 1 的数量需要大致相同
(4)输出 SK = (K, α,M1,M2,S) 作为生成加密索引和生成陷门的密钥
索引生成算法
BuildIndex(F, SK)→Encsk(I)生成安全索引,具体步骤如下:(F:文件集合,SK:密钥)
- (1)数据预处理
- 对于文件集合 F = { f1 , f2 ,…, fn }中的每一个文件 fi 所对应的关键字集合 Wi = { w1 , w2 ,…, wt },使用 波特词干算法 将获得词干关键词集合 ST = { st1 , st2 ,…, stt },根据 ST 计算 TF 和 IDF 值
- (2)关键词转换
- 使用改进的关键字转换方法 bi-gram,将每个关键字转换为集合 BS,考虑了相同 bi-gram 的出现,然后将 BS 转换为固定长度的二进制向量 BV
- 例如,关键字 “represent” 表示 BS = {re1,ep1,pr1,re2,es1,se1,en1,nt1}
- (3)构建索引
- ① 为文件 fi 构建一个 m bit 的布隆过滤器 Bi,初始化为 0
- ②对于向量集合 BV = { bv1 , bv2 ,…, bvt } 中的每个向量 bvi,使用 l 个局部敏感哈希函数 { H1 , H2 ,…, Hl } 进行计算(H1(bvi) , H2(bvi) ,…, Hl(bvi) ),计算在 Bi 中相应的位置 ,并将每个位置设置为 TFi,j / l
- TFi,j = 1 + |wj| / |fj|, |wj| 是在 fi 中关键字 wj 的数量,|fj| 是在 fi 中所有关键字的数量
- 如果将不同的关键字散列到同一位置,我们将使用它们的平均值作为插入
- ③ 将 Bi 扩展为 (m+2) 位,扩展值为 ε1 和 1
- (4)索引加密
- ①将密钥 SK 中的 S 表示为 S = (s1 , s2 ,…, sm+2)。对于每一个文件 fi 所得到的布隆过滤器 Bi
- 随机选择参数 r ∈ R
- ② 将 Bi 表示为 Bi = ( b1 , b2 ,…, bm+2)。 Bi 与 S 具有同样的结构,均为由 {0,1} 组成的 m+2 位向量。对于 Bi 中的每一个 bj ,
- 若在 S 中对应的 sj = 1 ,则令 b’j = b’’j = bj ;
- 若在 S 中对应的 sj = 0,则令 b’j = 1/2bj + r 、b’’j = 1/2bj - r
- ③ 令 B’i = ( b’1 , b’2 ,…, b’m+2),B”i = ( b”1 , b”2 ,…, b”m+2)
- ④ 计算 I’i = M1T • B’i , I”i = M2T • B”i
- ⑤ 令 Ii = (I’i ,I”i )
- ⑥输出加密索引 Encsk(I)= ( I1 , I2 ,…, In ),n 是文件集合中的文件数
索引生成实例
我们通过一个实例展示了索引的建立过程。为了简单起见,我们假设某个文件有两个关键字“ranked”和“searched”
- W = {ranked,searched},设 m = 10,S = [1,0,0,1,0,0,1,1,0,0,1,1] ,并假设(M1,M2)都是可逆矩阵。
- 首先 对 W 用波特词干算法转换为 ST = {rank,search}
- 关键字 “rank” 使用 bi-gram 转换为 BS1= {ra1,an1,nk1},再转换为 BV1
- BS2 和 BV2 是用同样的方法为关键字 “search” 生成的
- 分别使用 BV1 和 BV2 作为 LSH 函数的两个输入,并在其计算结果的位置设置 TF 值 0.5
- Bi = [0.5,0,0,0,0,0,0,0.5,0,0.5],它被扩展为[0.5,0,0,0,0,0,0,0,0,0,0,0.5,0.5,0.5,1],使用值 0.5 和 1 。
- B’i = [0.5, 0.1, 0.1, 0,0.1, 0.35, 0, 0.5, 0.1, 0.35, 0.5, 1],B”i = [0.5, -0.1, -0.1, 0,-0.1, 0.15, 0, 0.5, -0.1, 0.15, 0.5, 1]
- 最后, B’i 和 B”i 用矩阵(M1 , M2)加密,最后的结果是Encsk(Ii) = { I’i = M1T • B’i , I”i = M2T • B”i } =[0.5,0.1,0.1,0.1,0,0.1,0.35,0.5,0.1,0.35,0.5,0.5,-0.1,-0.1,-0.1,0.15,0.5,-0.1]
陷门生成算法
Trapdoor(Wk, SK)→Encsk(Q)根据查询关键词集合生成安全陷门,具体步骤如下:
(1)前两步与索引建立生成 BV 的前两个步骤完全相同
(2)构建一个 m 位的布隆过滤器 Q 。
(3)使用 LSH 函数将每个关键字的 bi-gram 向量映射到布隆过滤器 Q 中,将 Q 的对应位置设置为其 IDF 值,将陷门向量 Q 乘以 ε2,并将其扩展为(m+2)位向量,其值为 ε2 和 t
(4)将密钥 sk 中的 S 表示为 S = (s1 , s2 ,…, sm+2)。对于布隆过滤器 Q,
- ① 随机选择参数 r’ ∈ R
- ② 将 Qi 表示为 Qi = (q1 , q2 ,…, qm+2)。 Qi 与 S 具有同样的结构,均为由 {0,1} 组成的 m+2 位向量。对于 Q 中的每一个 qj ,
- 若在 S 中对应的 sj = 0 ,则令 q’j = q’’j = qj ,
- 若在 S 中对应的 sj = 1,则令 q’j = 1/2qj + r’ 、q’’j = 1/2qj - r’
- ③ 令 Q’ = ( q’1 , q’2 ,…, q’m+2),Q” = ( q”1 , q”2 ,…, q”m+2)
(5)输出陷门 Encsk(Q) = {M1-1 • Q’ , M2-1 • Q”}。
陷门生成实例
我们通过一个实例展示了陷门的建立过程。为了简单起见,我们假设查询关键字为 “ranked” 和 “searched”
- BS1 , BV1,BS2 , BV2 是用索引的建立过程同样方法生成的
- 分别使用 BV1 和 BV2 作为 LSH 函数的两个输入,并在其计算结果的位置设置 IDF 值 log(0.5) = -0.3
- Q = [0, -0.3, 0, 0, 0, -0.3, 0, -0.3, 0, -0.3],它被扩展为 [0, -0.3, 0, 0, 0, -0.3, 0, -0.3, 0, -0.3, 1, -0.1] ,使用值 1 和 -0.1
- Q’ = [0.1,-0.3, 0, 0.1, 0, -0.3, 0.1, -0.05, 0, -0.3, 0.6, 0.05] ,Q” = [-0.1, -0.3, 0, -0.1, 0, -0.3, -0.1, -0.25, 0, -0.3, -0.6, -0.15]
- 最后, Q’ 和 Q” 用矩阵(M1 , M2)加密,最后的结果是Encsk(Ii) = { I’i = M1-1 • Q’ , I”i = M2-1 • Q” } = [0.1, -0.3, 0, 0.1, 0, -0.3, 0.1, -0.05, 0, -0.3, 0.6, 0.05, -0.1, -0.3, 0, -0.1, 0, -0.3,-0.1, -0.25, 0, -0.3, -0.6, -0.15]
认证算法
Auth(SK, L, Encsk(I) or Encsk(Q))→σI or σQ 身份验证标记生成算法,该算法为每个加密的索引或加密的陷门生成认证标签。
- 代理服务器首先对 Encsk(Ii) 或 Encsk(Q) 的每一项进行标记
- Encsk(Ii)[j] 被标记为 LEncsk(Ii),j 表示在 i 位置的 索引 Ii 中的第 j 项
- Encsk(Q)[j] 被标记为 LEncsk(Q),j 表示陷门 Q 中的第 j 项
- 然后,对于加密索引 Encsk(Ii) 中的每一项 Encsk(Ii)[j],代理服务器调用 Real-HomMAC
- Auth(SK,LEncsk(Ii),j,Encsk(Ii)[j]) 输出 (y0(j), y1(j)) = (Encsk(Ii)[j],(ri,j − Encsk(Ii)[j])/α
- 式中 r = FK(LEncsk(Ii),j)。这样,代理为加密索引 Encsk(Ii) 生成认证标签 σIi
- 代理服务器为加密的陷门 Encsk(Q) 生成认证标签 σQ 。
搜索算法
Search(f, σI , σQ)→σ 模糊关键词搜索算法,模糊关键词搜索函数f、索引标记 σI 和陷门标记 σQ 作为输入,并输出结果 σ =(σ0,···,σk)具体步骤如下:
加密陷门获得相关分数 scoi = f(Encsk(I) , Encsk(Q)),选择相关度最高的 k 个搜索结果,最后,对于 k 个搜索结果,比如 fi,调用 RealHomMac,Eval(f,{σI , σQ})以输出其证明 σi = (y0, y1, y2)
(1)将索引 I 表示为 I = ( I1 , I2 ,…, In ) 对于每一个 Ii
- ① 将 Ii 表示为 Ii = (I’i ,I”i ) ,将 t 表示为 t = (t’,t”)
- ② 计算向量的数量积: RI = I’i • t’ + I”i • t”
- ③ 按排序算法将计算的向量内积(数量积)作排序
验证算法
Verify(SK, P, scoi, σi)
- 设 P= (f, LEncsk(Ii),LEncsk(Q)) 代理服务器调用 Real-HomMAC。
- Verify(SK, P, scoi, σi),根据如下公式验证 scoi 的正确性。
- 如果公式成立,代理服务器接受 fi 作为搜索结果
- 否则拒绝 fi
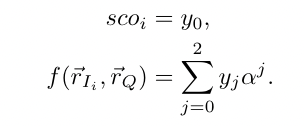
更新算法
Update(Ftemp, SK)
该算法包括添加文件、删除文件和修改文件三个操作。在添加文件时,代理服务器对文件进行加密,调用 Auth 为其生成身份验证标记,最后将其外包给云服务器。当删除文件时,代理服务器需要与云服务器进行交互,删除对应的密文和索引。对于文件修改,相当于删除原始文件,然后添加一个新文件
⑥EliMFS方案
论文名称:《EliMFS: Achieving Efficient, Leakage-Resilient, and Multi-Keyword Fuzzy Search on Encrypted Cloud Data》
- 作者:陈静; 何坤; 邓兰; 泉源; 杜瑞英; 杨翔; 吴杰
- 单位:武汉大学
- 刊物:IEEE Transactions on Services Computing【CCF B】
- 时间:2017年10月
1、总体思路
该方案利用了一种新颖的两阶段索引结构来确保搜索时间与文件集大小无关。多关键字模糊搜索通过基于 bi-gram ** 布隆过滤器和局部敏感散列**的精细设计实现的。此外,考虑到由两阶段索引结构引起的泄漏,我们提出了两种具体的方案来抵抗不同威胁模型中的这些潜在攻击。
本文的主要贡献归纳如下:
- (1)这是第一个针对加密云数据的多关键字模糊搜索方案,其搜索复杂性与文件大小无关;
- (2)与现有的多关键字模糊搜索解决方案相比,我们设计了一种新颖的两阶段索引结构和相应的搜索算法,以提高对加密云数据的搜索效率;
- (3)为了保护数据隐私,我们分析了不同威胁模型中框架可能存在的泄漏,并提出了两种实现泄漏弹性的具体方案;
- (4)对隐私和效率进行了全面分析,对真实世界数据集的实验进一步表明,我们的设计在搜索过程中具有较低的开销。
2、使用技术
- 局部敏感哈希函数
- 布隆过滤器
- 安全近邻算法
- bi-gram 关键字变换
- 倒排索引
3、方案实现

首先构建了一个包含各种文件标识符和关键字的两阶段安全索引。
搜索复杂性仅由查询中与一个关键字关联的文件数决定,而不是整个文件集大小
在第一阶段索引中,每个关键字都转换为一个标记,该标记指向包含此关键字的所有文件标识符。
第二个索引恰恰相反,它由所有文件标识符及其匹配的关键字生成。
考虑到隐私,当我们使用这个框架时,每个文件标识符都会被算法 Enc 加密。
对于模糊搜索函数,将关键字 wi 转换为中间值 Vi,
Vi 通过顺序计算 2-gram 序列的 26 x 26 位数组和 LSH 值。
在第一级索引中,由 tagi 被 vi 和 伪随机函数 F(x) 创建。
在第二阶段索引中,每个文件标识符都映射到一个 Bloom Filter,该过滤器由多关键字的所有中间值推导而成。
在这种两阶段索引结构中,第一阶段能够高效地执行单关键字搜索,并在多关键字搜索中缩小搜索范围。
第二阶段用于估计第一阶段的结果是否确实包含所有目标关键字
EliMFS-B
密钥和安全索引生成
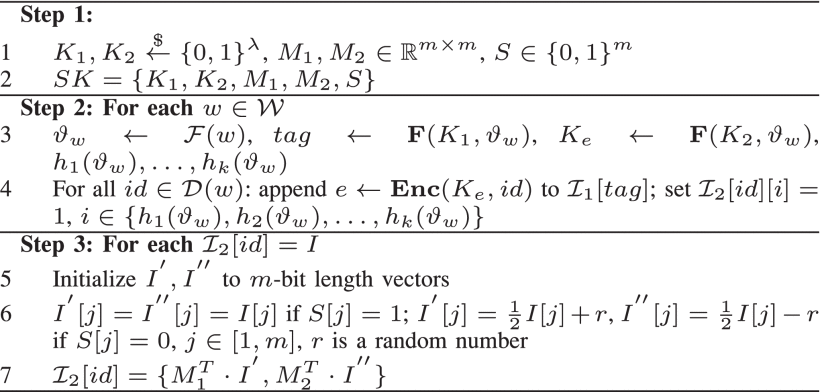
步骤一:生成密钥
- 两个随机序列(K1,K2)
- 两个可逆矩阵(M1,M2)
- 一个向量 S
步骤二:建立文件索引
- 通过 l hash 函数计算中间值 Vw 、通过伪随机函数 F 加密 Vw 计算标记 tag、
- 通过 K2 和 Vw 生成加密文件标识符的密钥 Ke
- 用 Ke 加密文件标识符 id 得到 e ,并附加到 I1[tag],得到 I1
- 设置布隆过滤器 h1(Vw),h2(Vw),…,hk(Vw) 位置的 I2[id][i] = 1
步骤三:使用KNN算法加密索引 I2
- 将 布隆过滤器 I 分裂成两个向量 {I’ ,I”}
- 根据 S 计算 I2[id] = {M1T • I’ ,M2T • I”}
- 得到 Index = {I1, I2}
陷门生成

步骤一:
- 假设在第一阶段搜索中选择的关键字是 w1
- 那么数据所有者首先计算中间值 Vw1、标记 tag、加密文件标识符的密钥 Ke
- 如果 n(关键字个数) = 1,则不执行下两个步骤,直接将标记tag发送到云服务器。
步骤二:
- 构建 m-bits 布隆过滤器 Bfq
- 每个关键字都用 l LSH 处理,并用 k hash 函数 插入到 Bfq 中
步骤三:
Bfq 使用 M1,M2,S 加密,方法与索引加密类似
数据所有者选择一个阈值 thr ≤ k|w|,thr 被用来比较内积,在第二个搜索阶段来判断是否应该返回文件 ID
发送 Token = {tag,M1-1 • Bfq‘ ,M2-1 • Bfq“,Ke,thr} 到云服务器
搜索算法
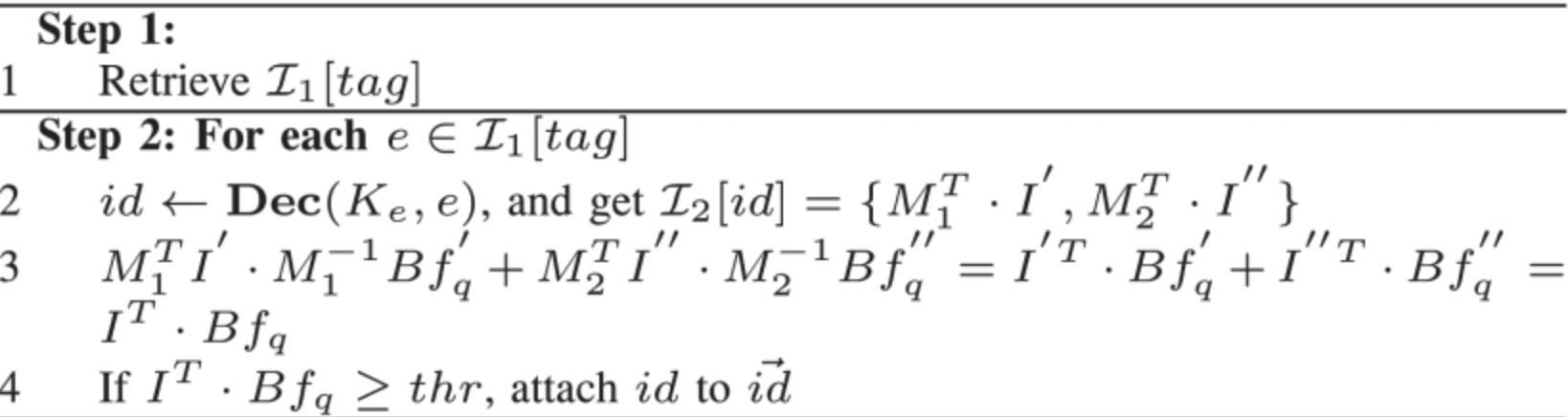
步骤一:
- 收到陷门后,读取所有 I1[tag]
- 如果 Token = {tag},云服务器返回这些标识符并完成算法
- 如果 Token = {tag,M1-1 • Bfq‘ ,M2-1 • Bfq“,thr},云服务器逐个检查 I1[tag] 的布隆过滤器
步骤二:
- 用 Ke 解密文件标识符 e 得到 id,从而得到 I2[id] = {M1T • I’ ,M2T • I”}
- {M1-1 • Bfq‘ ,M2-1 • Bfq“} 和 {M1T • I’ ,M2T • I”} 进行内积得到 IT • Bfq
- 如果 IT • Bfq ≥ thr 将文件标识符 id 添加到结果集中
EliMFS-E
密钥和安全索引生成
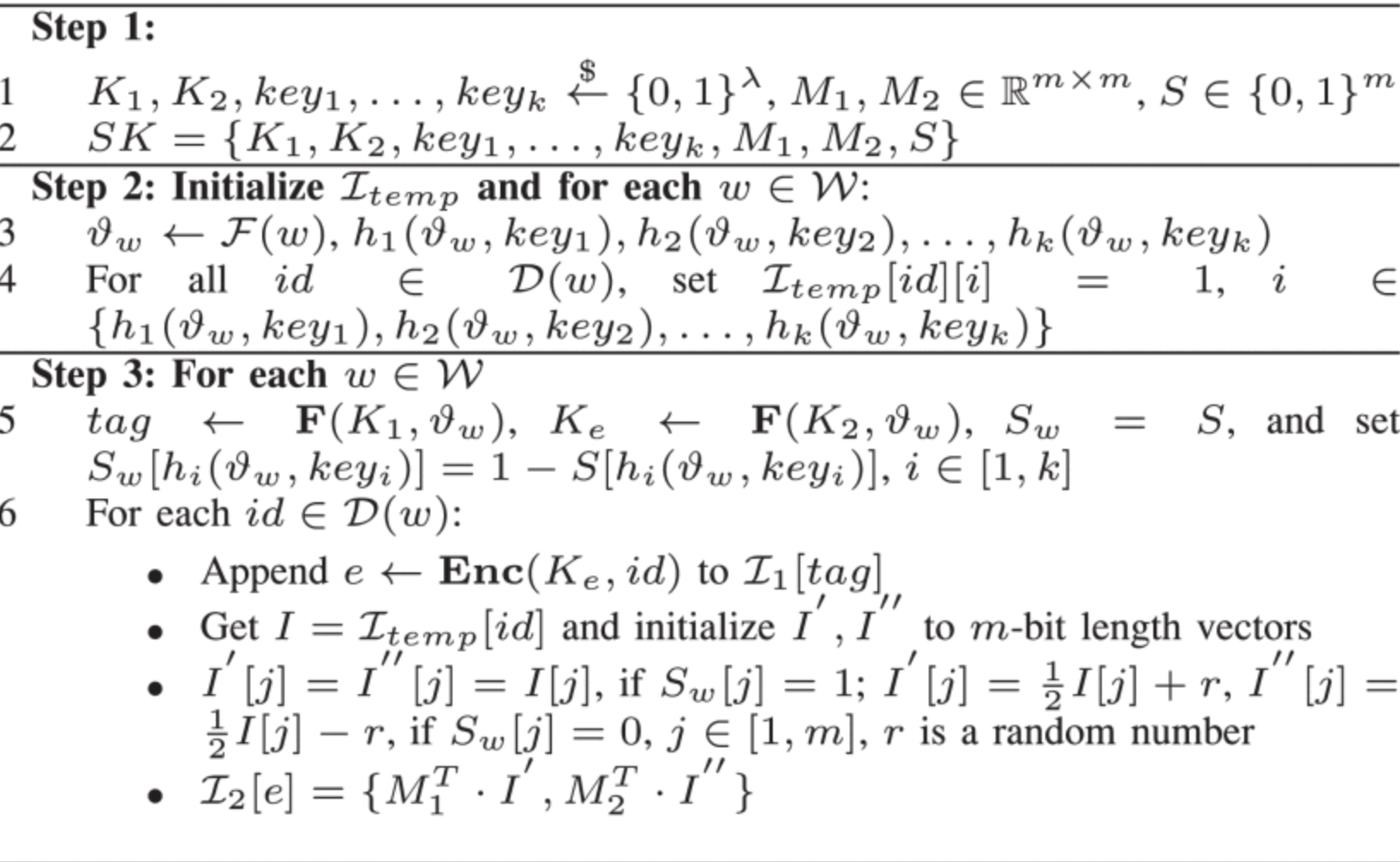
陷门生成

搜索算法

②~⑥方案总结
对比
| 编号 | 方案/技术 | LSH | BF | KNN | Gram | 索引建立 |
|---|---|---|---|---|---|---|
| 2 | MKFS | ✅ | ✅ | ✅ | —— | 对偶编码函数 |
| 3 | TEMKS | ✅ | ✅ | ✅ | uni-gram | Porter Stemming、TF-IDF |
| 4 | EDMKFS | ✅ | ✅ | ✅ | uni-gram | KBB、 Top-k、TF-IDF |
| 5 | VRFMS | ✅ | ✅ | ✅ | bi-gram | Porter Stemming、TF-IDF |
| 6 | EliMFS | ✅ | ✅ | ✅ | bi-gram | inverted index、forward index |
遗留问题
- 为什么模糊查询的 Inner Product 和 Socre 比较来确定文本相关性?
如果一个文档在查询中包含关键字,那么两个向量对应的位将为 1 ,因此内积将返回一个高值。因此,这个简单的内积结果是一个很好的衡量匹配关键字的数量。
通常,Score > 0 表示文件包含查询关键字。但由于布隆过滤器的假阳性,上述情况并非如此。在所提出的方案中,该阈值被设置为TH = l,这意味着根据查询只会选择 Score ≥ l 的文件
- 布隆过滤器中 局部敏感哈希函数个数如何确定?
请参考小简写的另外一篇文章:布隆过滤器VS布谷鸟过滤器 | 简简 (jwt1399.top)
Sponsor❤️
您的支持是我不断前进的动力,如果您感觉本文对您有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用,拒绝白嫖,从你我做起!🥰🥰🥰
| 支付宝 | 微信 |
 |
 |



