布隆过滤器
原理
论文名称:《Space/time trade-offs in hash coding with allowable errors》(在允许错误的哈希编码中,空间/时间的权衡) ——该篇论文是布隆过滤器的开山之作
作者:Burton H.Bloom
单位:Computer Usage Company, Newton Upper Falls, MA
时间:1970年07月
主要内容:给定一个 set,查找某个 key 是否存在于该 set,通常考虑三点:
- time: 查找时间
- space: 空间成本(例如 hash 目标区域大小)
- 允许一定概率的误判,来获取空间成本的显著降低。
本质上布隆过滤器是一种比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
BF的组成:
- n 个 待插入的 key
- m bits 的空间 v,全部初始化为0
- k 个无关的 hash 函数:
h1, h2, ..., hk,hash 结果为{0, 1, ..., m-1}
具体的,对于 key=a,经过 k 个 hash 函数后结果为 h1(a), h2(a), ..., hk(a)
那么就将 v 对应的 bit 置为 1,假定 k 为 4,对应的 bloom filter 为:
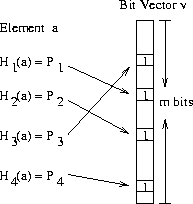
插入
布隆过滤器上面说了,就是一个二进制数据的集合。当一个数据加入这个集合时,经历如下洗礼:【动态演示】
- 通过 K 个哈希函数计算该数据,返回 K 个计算出的 hash 值
- 这 K 个 hash 值映射到对应的 K 个二进制的数组下标
- 将 K 个下标对应的二进制数据改成 1 。
例如,将“你好”存入布隆过滤器,第一个哈希函数返回 3,第二个第三个哈希函数返回 5 与 7 ,那么布隆过滤器对应的下标3,5,7的位置改成1。
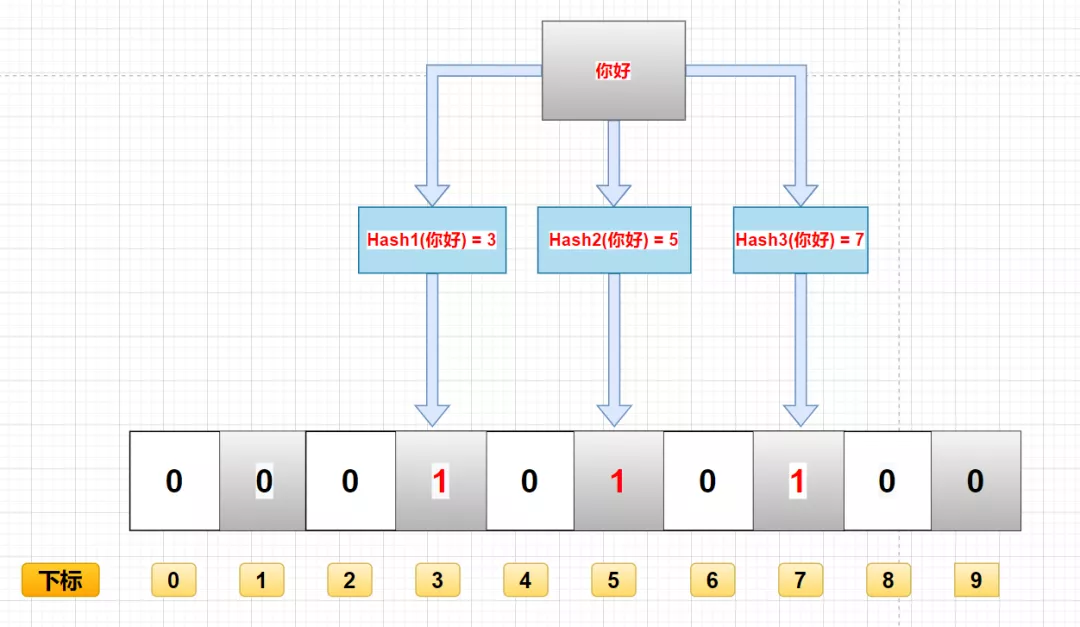
查找
布隆过滤器主要作用就是查询一个数据,在不在这个二进制的集合中,查询过程如下:
- 通过 K 个哈希函数计算该数据,对应计算出的 K 个 hash 值
- 通过 hash 值找到对应的二进制的数组下标
- 判断:如果存在一处位置的二进制数据是 0,那么该数据不存在。如果都是1,该数据存在集合中。
我们假设 BF 是一个 12bit 的二进制向量,{h1,h2}是两个哈希函数,{x,y,z}是一个集合。 用户想查询关键字 w,查询结果显示 w 在集合中不存在。

假阳性
宁可错杀三千,绝不放过一个
当 key 越来越多,v 里置为 1 的 bits 越来越多,前面被置 1 的位置可能就会被覆盖,此时就有概率发生误判,更专业的术语称为 **false positive(假阳性)**,也就是说当我们在 bloom filter 查找 key 时,有返回两种情况:
- key 不存在,那么 key 一定不存在。
- key 存在,那么 key 可能存在。
也就是说 bloom filter 具有一定的误判率。
m 越大,k 越大, n 越小,那么 false positive越小,更进一步,bloom filter 是关于空间和 false positive 的 tradeoff,bloom filter 的算法其实并不复杂,其真正的艺术在于这种平衡。
误报率和哈希个数
布隆过滤器需相关参数如下:
- n:插入元素的个数
- ρ:插入n 个元素的情况下的误报率
- m:布隆过滤器位数
- k:每插入一个元素进行的哈希轮数
构造时会提供 n 和 ρ 根据这两个参数会计算出布隆过滤器的大小 m,哈希函数的个数 k
它们之间的关系比较简单:
- 误报率越低,布隆过滤器就需要越长,但是控件占用较大
- 误报率越低,或者 hash 函数越多,但是计算耗时较长
如何选择合适的哈希函数个数 k 和布隆过滤器长度 m,有人推导出了如下公式
- n:插入元素的个数
- ρ:插入n 个元素的情况下的误报率
- m:布隆过滤器位数
- k:每插入一个元素进行的哈希轮数
1、根据 ρ 和 n 可以计算出 m 和 k
| 布隆过滤器位数 | 最优哈希函数个数 |
|---|---|
 |
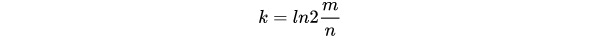 |
2、根据 m、 n、k 可以计算出 ρ

哈希选取
2008年5月哈佛大学的一篇论文指出可以使用 2 个哈希函数来模拟多个哈希函数
论文名称:《Less hashing, same performance: Building a better Bloom filter》(更少的散列,相同的性能:构建更好的布隆过滤器)
- 作者:Adam Kirsch
- 单位:哈佛大学
- 刊物:ESA’06: Proceedings of the 14th conference on Annual European Symposium【CCF B】
- 时间:2008年05月
- 主要内容:散列文献中的一种标准技术是使用两个哈希函数 h1(x) 和 h2(x) 来模拟 gi(x) = h1(x) + ih2(x) 的附加哈希函数。我们证明了这种技术可以有效地应用于 Bloom 过滤器和相关的数据结构。具体地说,只需两个哈希函数就可以有效地实现一个Bloom过滤器,而不会在渐近假阳性概率上有任何损失。这将导致更少的计算,并且在实践中可能更不需要随机性。
这篇论文涉及大量的数学推导,一共 32 页,🥹🥶😭,我当然是没有看完的,感兴趣的大佬可以仔细阅读,可以把我上面主要思想中的叙述作为一个结论在工程实践中使用。
另一个重点:由于使用布隆过滤器的唯一目的是为了更快地搜索,我们不能使用慢散列函数,Sha-1、MD5 等加密哈希函数对于布隆过滤器来说不是很好的选择,因为它们有点慢。因此,更快的散列函数实现的更好,最好选择 murmur、fnv系列散列、Jenkins 散列和HashMix散列
优缺点
优点:
- 集合元素可以增加
- 判断的时间复杂度为O(n),空间复杂度为O(1)
缺点:
- 集合中的元素只能增加不可以删除
- 存在一定的假阳率,也就是说,存在一定的可能性,该元素不在集合中,但是判断的结果却表明在集合中
使用场景
场景列表
大集合中重复元素的判断
使用布隆过滤器减少对不存在的资源或不被允许的请求进行耗费性能的网络查找
防止用户更改产品id进行重新请求而导致的缓存击穿
利用布隆过滤器减少磁盘IO或者网络请求
爬虫系统中,对URL进行去重
URL黑名单、白名单,比如Chrome浏览器就是使用了一个布隆过滤器识别恶意链接。
Redis防雪崩(缓存穿透)
邮箱系统的垃圾邮件过滤
谷歌Bigtable、Apache HBase、Apache Cassandra和PostgreSQL使用布隆过滤器来减少对不存在的行或列的磁盘查找(加快数据库查询过程)。
解决缓存穿透问题,缓存穿透指查询一个不存在的数据,这时候缓存中不存在,就会不断的查询数据库,造成不必要的IO,而且有人如果恶意使用不存在的key也可以对数据库进行攻击。
高并发秒杀系统中抢红包系统中判断用户是否今天已领取红包
LevelDB增加查询效率
- LevelDB利用布隆过滤器判断指定的key是否存在于sstable中,若过滤器表示不存在,则该key一定不存在。
视频网站,使用布隆过滤器来检查推荐的视频内容是否已经被推荐过。
一些交友软件,每次抓取一批推荐给用户前端,利用一个布隆过滤器来完成记录,每次检查是否已被推荐过
具体场景1
你接到一个新的开发需求,需要你为用户注册服务设计一个用户名检查的 API 接口, 这个接口会根据用户输入的用户名与系统中所有账号的用户名进行匹配检查,如果用户名已经存在,则会提示用户该名称已被使用,无法进行注册,如果名称未被占用,则返回允许注册。
这个需求是不是听上去很简单,实现上我们有以下的几种方案:
方案一:每次注册验证的时候直接去数据库执行SQL, 检查是否存在相同用户名。
- 最简单,除了原数据库存储外,不需要外部的数据存储服务,但是每次查询进行全表扫描,特别是涉及到注册用户较多,分库分表设的情况下,资源开销可不是一般的大,查询效率肯定也不会太好。
方案二:导出一份用户名列表到缓存(定期或者使用消息队列),每次单独的查询缓存完成检查
内存数据查询效率比第一种要好一些,但是需要额外维护一套缓存服务,运维成本也不小,另外数据存储服务在数据量较大的情况下占用的内存开销也会较大。
方案二:通过一个布隆过滤器来完成校验,这种方式具有维护简单,占用资源少,查询效率高的优势
具体场景2
假如需要过滤某些不安全网页,现有 100 亿个黑名单页面,每个网页的URL最多占用 64 字节。现要设计一种网页过滤系统,可以根据网页的URL判断该网页是否在黑名单上。
- 方案一:最直观的想法必然是使用一个集合或者说数据结构来存放黑名单 URL,比如查找树、Set、map
- 但是无论上方哪种,不可避免的是我们需要存储原始的 URL 值,但是 URL 并不是一个很短的字符串,动辄十几/几十字节,假设一个 URL 有30 字节那么 100 亿 URL 所占内存就是十几 G,所以每次判断是否存在于黑名单中,就要占用很大的内存开销。
- 方案二:但是,我们需要的仅仅是知道是否存在这一需求,可以不需要具体的URL,所以仅仅对Ture or False 这个问题,可以使用位图(BitMap)算法,位图顾名思义就是,每个map 值都使用 1bit,这样大大降低了内存开销,具体做法是,我们使用一个Hash函数将URL 映射到大小为 n 的 bit 数组中,并置相应位置为 True 这样我们可以在尽可能低的内存开销下,实现 O(1) 时间的判断 URL 是否存在黑名单中。但不得不面对的一个问题就是,即使采取再好的哈希函数,都会出现哈希冲突的情况,在查询阶段出现哈希冲突意味着查询错误,会返回一个错误的结果,而想尽可能的降低哈希冲突,我们需要位图大小比黑名单中 URL 数量大的多,我们考虑随机哈希的情况下,查询碰撞的概率是:黑名单 URL 数量 /位图大小。所以要想查询准确率高,又带来了更高的内存开销,而可以有效改善这种情况的一种数据结构叫做布隆过滤器(Bloom Filter)
具体场景3
海量数据下的去重和查重:10亿个正整数,给定一个数值,如何快速判定该数值是否在 10 亿个正整数当中?假如机器只有 1G 内存?
我们来估计一下上面所需要用到的内存,1G 约等于 109 个字节,上面的数字都是 int 型,一个 int 占用 4 字节,所以问题一可能需要占用 4G 内存,显然需要的内存太大了,传统的方法显然是不能用了,就可以使用布隆过滤器
- 首先初始化一个 int 数组,每个元素对应 32 位比特(int 占用 4 字节,1字节 8 个比特位)
- 将 10 亿个元素分别读入内存,对 int 数组中的元素比特位进行标记。如果存在,标记为 1 即可
- 原先一个 int 类型只能表示一个整数,现在一个 int 能表示 32 个整数,相当于是节省了 32 倍的内存
- 标记完之后,即可快速判定某个元素是否在 10 亿个正整数当中,时间复杂度为 O(1)

参考文章
- Bloom Filters - the math (wisc.edu)
- 布隆(Bloom Filter)过滤器—redis集成布隆过滤器—Java使用布隆过滤器
- 论文:[papers of bloom filter - Ying’s Blog (izualzhy.cn)](https://izualzhy.cn/bloom-filter-paper#:~:text=Space%2FTime Trade-offs in Hash Coding with Allowable Errors,在1970年发表的文章,布隆过滤器的开山之作。 给定一个 set,查找某个 key 是否存在于该 set,通常考虑两点: time%3A 查找时间)
- leveldb笔记之9:bloom filter - Ying’s Blog (izualzhy.cn)
- 误报率:布隆过滤器在一个测试场景中的应用
- 误报率:布隆过滤器假阳率公式推导
- 误报率:Probabilistic Data structures: Bloom filter | HackerNoon
- 白话布隆过滤器BloomFilter (bbsmax.com)
- 【分布式】Bloom Filter 与 Cuckoo Filter - 知乎 (zhihu.com)
- 初探布隆过滤器 - 掘金 (juejin.cn)
- 【大数据算法】Counting Bloom Filter 的原理和实现 - 掘金 (juejin.cn)
- 详解布隆过滤器的原理,使用场景和注意事项 - 知乎 (zhihu.com)
- 结合Guava源码解读布隆过滤器 - 知乎 (zhihu.com)
- 使用Bloom Filter模拟器,带你一分钟了解布隆过滤器原理
- 场景1来源:一篇文章读懂布隆过滤器
- 场景2来源:布隆过滤器(Bloom Filter)详解及应用
- 误报率计算器:Bloom filter calculator (hur.st)
- 动态交互:Bloom Filters by Example (llimllib.github.io)
- 动态交互:Bloom Filters (jasondavies.com)
- 误报率计算器:Bloom Filter Calculator (krisives.github.io)
- 海量数据下的去重和查重(一):BitMap位图法
- 为什么抖音从来没有重复内容?
布隆过滤器变体
布隆过滤器的变体十分多,主要是为了解决布隆过滤器算法中的一些缺陷或者劣势。常见的变体如下:
| 序号 | 变体名称 | 简称 | 变体描述 | 来源 | 等级(CCF) |
|---|---|---|---|---|---|
| 1 | Counting Bloom Filter | CBF | 加入Counter,实现删除操作 | ACM Transactions on Networking | A |
| 2 | Accurate Counting Bloom Filter | ACBF | 将 Counter 数组划分成多个层级,来降低误判率 | Mathematical Problems in Engineering | —— |
| 3 | Dynamic Count Filter | DCF | 使用两个数组来存储所有的counter,改进CBF | SIGMOD Record | —— |
| 4 | Spectral Bloom Filters | SBF | CBF的扩展,提供查询集合元素的出现频率功能 | ACM SIGMOD’03 | A |
| 5 | Compressed Bloom Filter | 对位数组进行压缩 | ACM Transactions on Networking | A | |
| 6 | d-Left Counting Bloom Filter | dlCBF | 解决哈希表的负载平衡问题 | ESA’06 | B |
| 7 | Hierarchical Bloom Filters | HBF | 分层,由多层布隆过滤器组成 | CCS ‘04 | A |
| 8 | Time-Decaying Bloom Filters | TDBF | 计数器数组替换位向量,优化每个计数器存储其值所需的最小空间 | EDBT ‘13 | B |
| 9 | Bloomier Filters | 存储函数值,不仅仅是做位映射 | ACM SODA ‘04 | A | |
| 10 | Dynamic Bloom Filter | DBF | 改进SBF | IEEE Transactions on Knowledge and Data Engineering | A |
| 11 | Dynamic Bloom Filter Array | DBA | DBA在可扩展性、误判率控制和内存空间效率等方面均优于现有的DBF方法。 | IEEE Transactions on Parallel and Distributed Systems | A |
Counting Bloom Filter(CBF)
论文名称:《Summary cache: a scalable wide-area Web cache sharing protocol》(摘要缓存:可扩展的广域 Web 缓存共享协议)
- 作者:Li Fan; Pei Cao; J. Almeida; A.Z. Broder
- 单位:Cisco Systems
- 刊物:ACM Transactions on Networking
- 时间:2000年06月
引出

假如有这么一个情景
- 放入数据包 1 时,将 bitmap 的 1,3,6 位设置为了 1
- 放入数据包 2 时,将 bitmap 的 3,6,7 位设置为了 1
- 此时一个并没有存过的数据包请求 3,做三次哈希之后,对应的 bitmap 位点分别是 1,6,7
- 这个数据之前并没有存进去过,但是由于数据包 1 和 2 存入时将对应的点设置为了1,所以也会认为数据包 3 存入了 bitmap
- 随着存入的数据增加,前面的现象就会越来越严重
布隆过滤器没法删除数据,删除数据存在以下两种困境:
1、由于有误判的可能,并不确定数据是否存在数据库里,例如数据包3
2、当你删除某一个数据包对应位图上的标志后,可能影响其他的数据包,例如上面例子中,如果删除数据包1,也就意味着会将 1,3,6 位设置为0,此时数据包 2 来请求时,会显示不存在,因为 3,6 两位已经被设置为 0
原理
为了解决上面布隆过滤器的问题,出现了一个增强版的布隆过滤器(Counting Bloom Filter),这个过滤器的思路是将布隆过滤器的 bitmap 更换成数组,数组的每一位扩展为一个小的计数器(Counter),当数组某位置被映射一次时就 +1,当删除时就 -1,这样就避免了普通布隆过滤器删除数据后需要重新计算其余数据包 Hash 的问题,但是依旧没法避免误判。
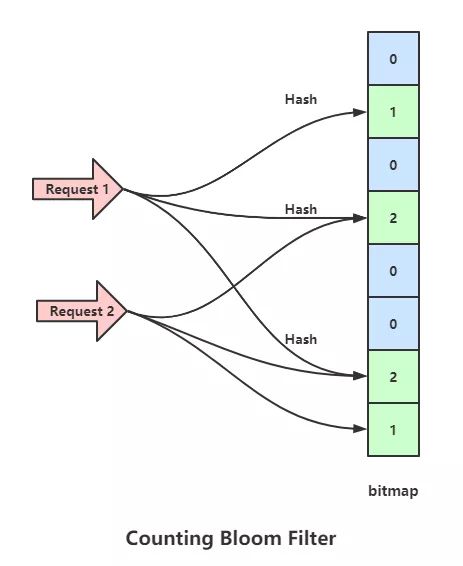
Counting Bloom Filter 通过多占用几倍的存储空间的代价,给 Bloom Filter 增加了删除操作。下一个问题自然就是,到底要多占用几倍呢?
直接给结论吧:每个 Counter 分配 4 位,对于大多数应用程序来说就足够了。详细证明过程可以去看论文
参考
- Counting Bloom Filter | Programming.Guide
- Bloom Filter和Counting Bloom Filter
- Counting Bloom Filter
- Counting Bloom Filter 的原理和实现
- 布隆过滤器之Counting Bloom Filter
- Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol
- 冷饭新炒:理解布隆过滤器算法的实现原理 | Throwable (throwx.cn)
Accurate Counting Bloom Filter(ACBF)
通过 offset indexing 的方式将 Counter 数组划分成多个层级,来降低误判率。
Accurate Counting Bloom Filters for Large-Scale Data Processing
Dynamic Count Filter(DCF)
为改进SBF的缺点,人们又发明了DCF(Dynamic Count Filter),其使用两个数组来存储所有的counter,它们的长度都为m(即bloom filter的位数组长度)。第一个数组是一个基本的CBF(即下图中的CBFV,counting bloom filter vector),counter的长度固定,为x = log(M/n),其中M是集合中所有元素的个数,n为集合中不同元素的个数。第二个数组用来处理counter的溢出(即下图中的OFV,overflow vector),数组每一项的长度并不固定,根据counter的溢出情况动态调整。
Dynamic count filters | ACM SIGMOD Record
Compressed Bloom Filter
Compressed bloom filters - Networking, IEEE/ACM Transactions on (harvard.edu)
Spectral Bloom Filter(SBF)
Saar Cohen, Yossi Matias 2003.6
SIGMOD ‘03: Proceedings of the 2003 ACM SIGMOD international conference on Management of data
在 CBF 的基础上提出了元素出现频率查询的概念,将CBF的应用扩展到了 multi-set 的领域;
sbf-sigmod-03.pdf (stanford.edu)
d-Left Counting Bloom Filter(dlCBF)
利用 d-left hashing 的方法存储 fingerprint,解决哈希表的负载平衡问题;
布谷鸟哈希
引出
哈希的本质是从一个较大空间映射到一个较小的空间,因此在插入数据足够多之后,根据鸽巢原理,一定会存在位置冲突。常见的哈希表(Hash Table 或者 dictionary)会通过链表、开放地址探测等方式来处理冲突。
单桶多函数的布谷鸟哈希,便是开放地址法处理冲突的一种哈希表,只不过有冲突后,不是通过线性寻找新的位置,而是通过额外哈希函数来寻找。Cuckoo Hashing 是一种鸠占鹊巢的策略。
原理
论文名称:《Cuckoo Hashing》——该篇论文是布谷鸟哈希的开山之作
- 作者:Rasmus Pagha,Flemming Friche Rodlerb
- 单位:Aarhus University
- 刊物:ACM Journal of Algorithms
- 时间:2004年05月
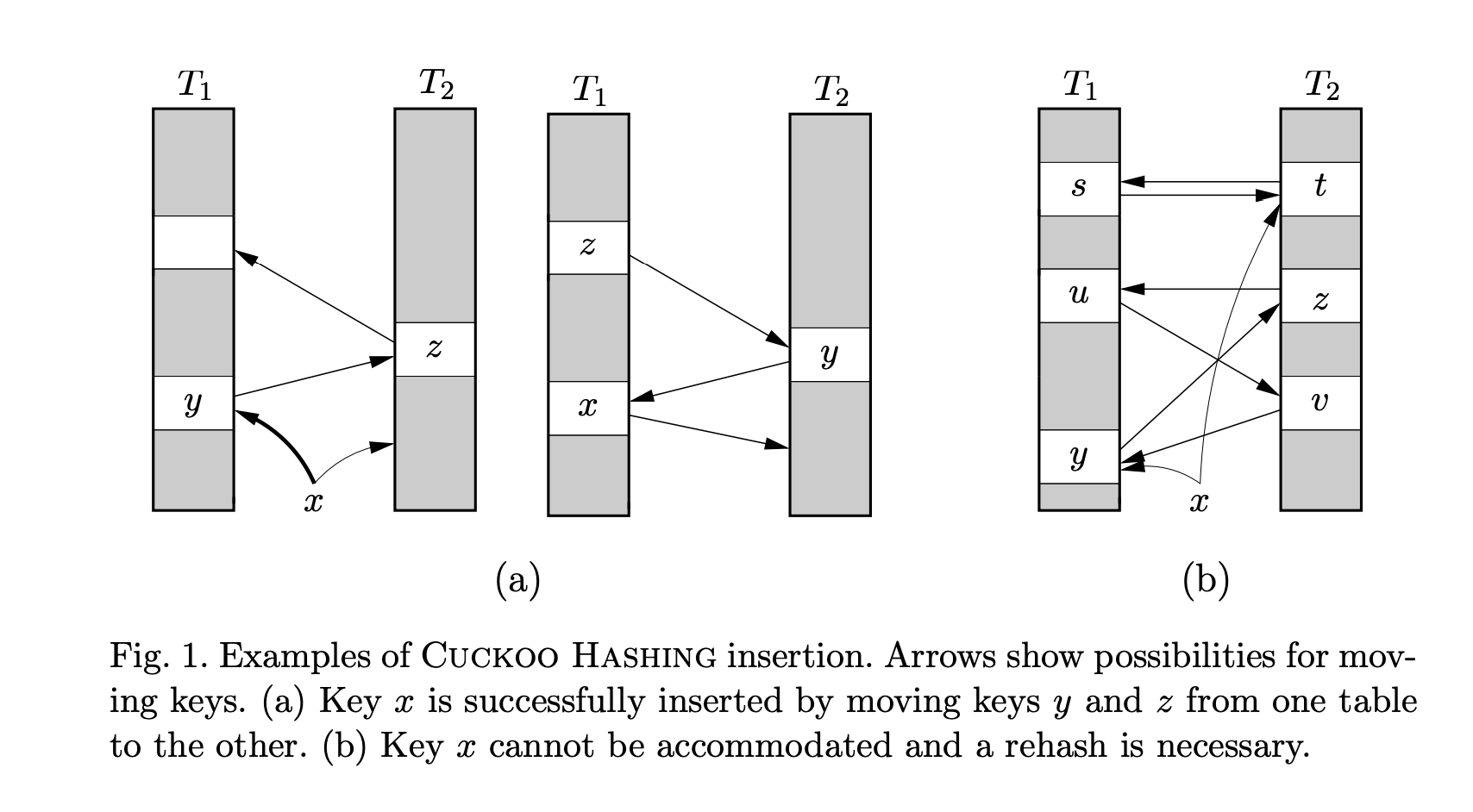
基本思想:使用两个哈希函数 h1、h2 和两个哈希桶 T1、T2, 对一个 key 进行哈希,得到桶中的两个位置
- 如果两个位置都为空,随便选一个插入 key
- 如果只有一个位置为空,则存入为空的位置
- 如果都不为空,则随机踢出一个元素
- 踢出的元素,重复上述过程,插入元素
当然假如存在绝对的空间不足,那老是踢出也不是办法,所以一般会设置一个踢出阈值,如果在某次插入行为过程中连续踢出,则说明哈希桶满了,超过阈值,则进行扩容。
- p1 = hash1(x) % L
- p2 = hash2(x) % L
变种
布谷鸟哈希可以有很多变种,比如:
- 使用两个哈希函数和一个哈希桶。
- 使用两个哈希函数和四路哈希桶。
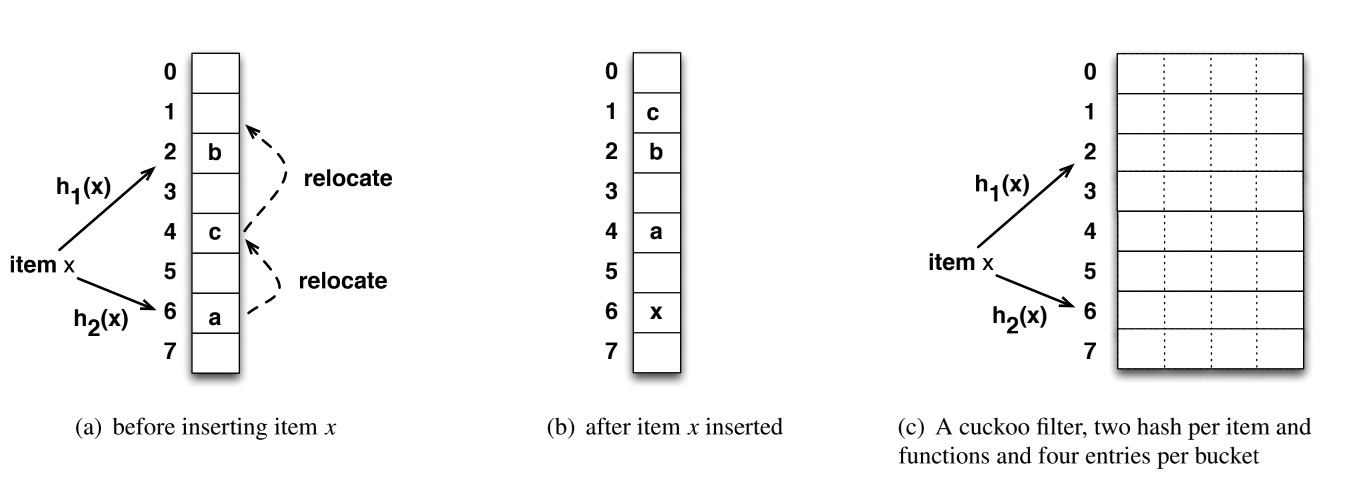
可以证明,后者的桶的利用率会更高,后面讲布谷鸟过滤器会细说原因
布谷鸟过滤器
论文名称:《Cuckoo Filter: Practically Better Than Bloom》(布谷鸟过滤器:实际上比布隆过滤器更好) ——该篇论文是布谷鸟隆过滤器的开山之作
- 作者:Bin Fan, Dave G. Andersen, Michael Kaminsky, Michael D. Mitzenmacher
- 单位:卡内基梅隆大学
- 刊物:CoNEXT ‘14【CCF B】
- 时间:2014年12月
- 主要内容:我们
提出了一种称为布谷鸟滤波器的新数据结构,它可以取代 Bloom 过滤器进行近似集合查询测试。布谷鸟过滤器支持动态添加和删除元素,同时实现比 Bloom 过滤器更高的性能。对于存储许多项目并针对中等低误报率的应用程序,布谷鸟过滤器的空间开销低于空间优化的 Bloom 过滤器。
论文直接说到布隆过滤器的缺点:
- Bloom过滤器的一个限制是:在不重新构建整个过滤器的情况下,不能删除现有项。
论文中也提到了布谷鸟过滤器 4 大优点:
- 1、支持动态的新增和删除元素;
- 2、提供了比传统布隆过滤器更高的查找性能,即使在接近满的情况下(比如空间利用率达到 95% 的时候);
- 3、相比其他支持删除的 Filter 更容易实现;
- 4、如果要求误判率小于3%,那么在许多实际应用中,它比布隆过滤器占用的空间更小。
为了达到以上效果,Cuckoo Filter 对原 Cuckoo Hash 做了如下改变:
- 为了提高桶的利用率,使用多路哈希桶。
- 为了减少内存的使用,只存储 key 指纹。
原理
布谷鸟过滤器的布谷鸟哈希表的基本单位称为条目(entry),每个条目存储一个指纹(fingerprint)
指纹:对插入的 key 使用一个哈希函数生成的 n 位比特位,n 的具体大小由所能接受的误判率来设置,论文中的例子使用的是 8 bits 的指纹大小。牺牲了一定精度,但是换取了空间。
与布谷鸟哈希不同,布谷鸟过滤器采取了两个并不独立的哈希函数,具体的布谷鸟过滤器位置计算公式:
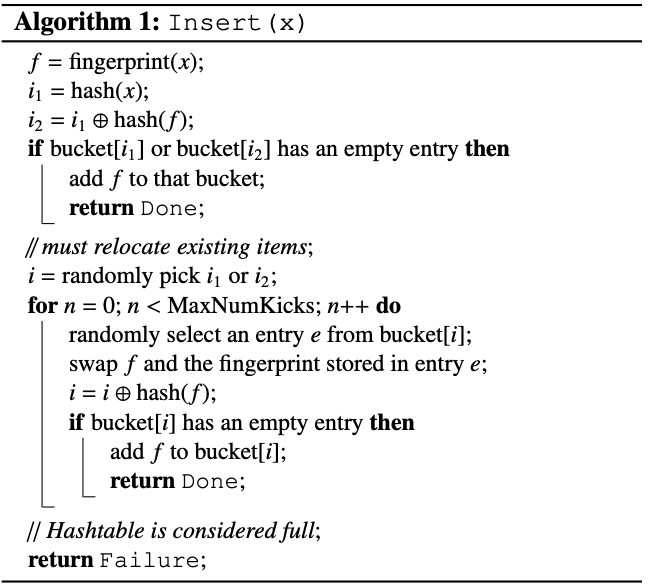
f = fingerprint(x)
i1 = hash(x)
i2 = i1 ⊕ hash(f)
# i1 和 i2 即为计算出来两个桶的索引
为什么采用并不独立的哈希函数?又为什么需要用到异或呢?
布谷鸟过滤器插入元素时会有频繁的踢出操作,当某个值 x 被踢出时,需要找到另外一个位置。 Cuckoo Hash 是通过额外哈希函数作用于 x 计算而出:i2。
但在 Cuckoo Filter 中为了节省内存,保存的是定长的指纹 finger(x) 而非原值 x。当 x 被踢出时,如何找到其另外一个位置?直观的,我有两种想法:
方法一:通过
h2(finger(x))计算出另外一个位置。但这样在计算第二个位置时,相当于将原数据空间强行压缩到了指纹空间,会损失很多信息,加大碰撞概率。方法二:在值中记下另外一个位置
(finger,other position),但这样空间占用会大大增加。
Cuckoo Filter 用了一个巧妙地做法,将位置 i1和该位置里面存储的“指纹”信息的 Hash值 hash(f) 进行异或得到另外一个位置。
因为异或的自反性:
A ⊕ B ⊕ B = A这样就不需要知道当前的位置是 i1 还是 i2,只需要将当前的位置和该位置里面存储的“指纹”信息的Hash值进行异或计算就可以得到另一个位置。
而且只需要确保 hash(f) != 0 就可以确保 i1 != i2,如此就不会出现自己踢自己导致死循环的问题。
为什么 i1 不直接和指纹 f 进行异或 来计算 i2 ?
- 如果直接进行异或处理(i2 = i1 ⊕ f),那么很可能 i1 和 i2 的位置相隔很近
- 因为指纹 f 一般位数比较少,比如 8 bit。如果按照这种方法,即是在原位置 ±2^8 = 256 的范围内找到另一个位置,异或只会改变低 8 bit 的值。这个范围太小了,不利于均衡散列。尤其是在比较小的 hash 表中,这样无形之中增加了碰撞的概率。
插入
假设布谷鸟过滤器里面有两个 hash 表 T1、T2,两个 hash 表,对应一个 hash 函数 H1
具体的插入步骤如下:布谷鸟过滤器动态演示
- 当一个不存在的元素插入的时候,会先根据 H1 计算出其在 T1 表的位置 i1,如果该位置为空则可以放进去。
- 如果该位置不为空,则根据公式计算出其在 T2 表的位置 i2,如果该位置为空则可以放进去。
- 如果 T1 表和 T2 表的位置元素都不为空,那么就随机的选择一个 hash 表将其元素踢出。
- 被踢出的元素会去找自己的另一个位置,如果被占了也会随机选择一个将其踢出,被踢出的元素又会去找自己的另一个位置
- 如果出现循环踢出导致放不进元素的情况,那么会设置一个阈值,超出了某个阈值,就认为这个 hash 表已经几乎满了,这时候就需要对它进行扩容,重新放置所有元素。

如果想要插入一个元素 Z 到过滤器里:
- 首先会将 Z 进行 hash 计算,发现 T1 和 T2 对应的槽位1和槽位2都已经被占了;
- 随机将 T1 中的槽位1中的元素 X 踢出,X 的 T2 对应的槽位4已经被元素 3 占了;
- 将 T2 中的槽位4中的元素 3 踢出,元素 3 在 hash 计算之后发现 T1 的槽位6是空的,那么将元素3放入到 T1 的槽位6中。
实际上布谷鸟过滤器中只会存储元素的几个 bit ,称作指纹信息。这里是牺牲了数据的精确性换取了空间效率。
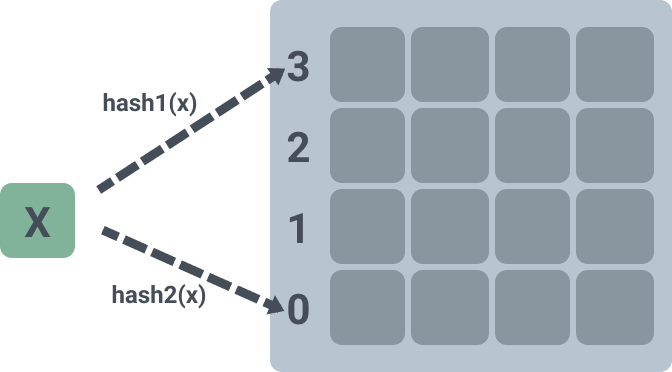
上面的实现方案中,hash 表中每个槽位只能存放一个元素,空间利用率只有 50%
布谷鸟过滤器中每个槽位可以存放多个元素,从一维变成了二维。当每个槽位可以存放 2,4,8 个元素的时候,空间利用率就会飙升到 84%,95%,98%
如下图,表示的是一个二维数组,每个槽位可以存放 4 个元素,和上面的实现有所不同的是,没有采用两个数组来存放,而是只用了一个
查找
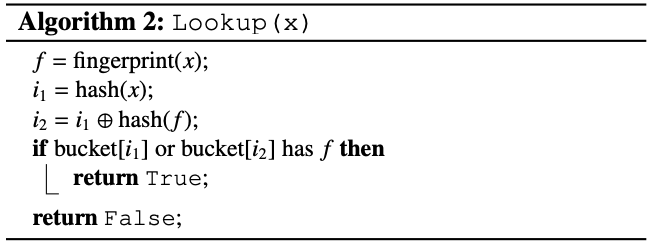
布谷鸟过滤器的查找过程很简单
- 给定一个项 x,算法首先根据插入公式,计算 x 的指纹和两个候选桶 i1 和 i2
- 然后读取这两个桶:如果任意桶与现有指纹匹配,则布谷鸟过滤器返回 true,否则过滤器返回 false。
- 只要不发生桶溢出,就可以确保没有假阴性。
删除

- 标准布隆过滤器不能删除,因此删除单个项需要重建整个过滤器
- 而计数布隆过滤器需要更多的空间
- 布谷鸟过滤器就像计数布隆过滤器,可以通过从哈希表删除相应的指纹,其他具有类似删除过程的过滤器比布谷鸟过滤器更复杂。
具体删除的过程也很简单
- 检查给定项的两个候选桶;如果任何桶中的指纹匹配,则从该桶中删除匹配指纹的一份副本。
对重复数据进行限制:如果需要布谷鸟过滤器支持删除,它必须知道一个数据插入过多少次。不能让同一个数据插入 kb+1 次。其中 k 是 hash 函数的个数,b 是一个下标的位置能放几个元素。
比如 2 个 hash 函数,一个二维数组,它的每个下标最多可以插入 4 个元素。那么对于同一个元素,最多支持插入 8 次。
缺点
- 删除不完美,存在误删的概率。删除的时候只是删除了一份指纹副本,并不能确定此指纹副本是要删除的 key 的指纹。同时这个问题也导致了假阳性的情况。
- 插入复杂度比较高。随着插入元素的增多,复杂度会越来越高,因为存在桶满,踢出的操作,所以需要重新计算,但综合来讲复杂度还是常数级别。
- 存储空间的大小必须为2的指数的限制让空间效率打了折扣。
- 同一个元素最多插入kb次,(k指哈希函数的个数,b指的桶中能装指纹的个数也可以说是桶的尺寸大小)如果布谷鸟过滤器支持删除,则必须存储同一项的多个副本。 插入同一项kb+1次将导致插入失败。 这类似于计数布隆过滤器,其中重复插入会导致计数器溢出。
参考
- 布谷鸟过滤器(Cuckoo Filter)
- 基于原论文,我实现了一个更全面的布谷鸟过滤器
- Go语言实现布谷鸟过滤器
- 【分布式】Bloom Filter 与 Cuckoo Filter
- 论文:布谷鸟过滤器:实际上优于布隆过滤器 (linvon.cn)
- CPP实现布谷鸟过滤器:https://github.com/efficient/cuckoofilter
- Cuckoo Hashing Visualization :: Laszlo Kozma (lkozma.net)
- 布隆,牛逼!布谷鸟,牛逼!
- 布谷鸟哈希和布谷鸟过滤器 | 木鸟杂记
两种过滤器比较
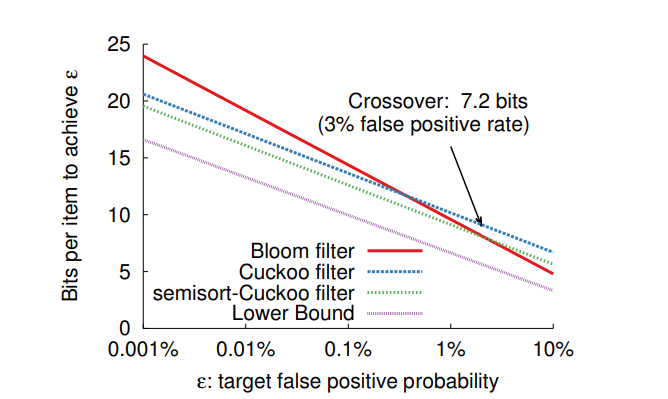
上图是布谷鸟过滤器其他过滤器比较,假阳性率与每个元素的空间成本。
对于低假阳性率(低于3%),布谷鸟过滤器比空间优化的布隆过滤器每个元素需要更少的存储空间。
❤️Sponsor
您的支持是我不断前进的动力,如果您恰巧财力雄厚,又感觉本文对您有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用,拒绝白嫖,从你我做起!🥰🥰🥰
| 支付宝支付 | 微信支付 |
 |
 |



