前言
哈喽!大家好,我是小简。今天开始学习《Java-集合》,此系列是我做的一个 “Java 从 0 到 1 ” 实验,给自己一年左右时间,按照我自己总结的 Java-学习路线,从 0 开始学 Java 知识,并不定期更新所学笔记,期待一年后的蜕变吧!<有同样想法的小伙伴,可以联系我一起交流学习哦!>
- 🚩时间安排:预计7天更新完
- 🎯开始时间:03-20
- 🎉结束时间:03-28
- 🍀总结:超时啦!这周花了一半时间看论文,耽搁啦!集合这章节是难点也是重点,算是勉勉强强算学完了,还不是很熟,后续再加强吧。
零、集合简介
集合的好处
以往我们保存多个数据使用的是数组,但是数组有不足的地方,我们分析一下
- 数组
- 1)长度开始时必须指定,而且一旦指定,不能更改
- 2)保存的必须为同一类型的元素
- 3)使用数组进行增加/删除元素比较麻烦
- 集合
- 1)可以动态保存任意多个对象,使用比较方便!
- 2)提供了一系列方便的操作对象的方法: add、remove、set、get等
- 3)使用集合添加,删除新元素简洁了
集合的框架体系
Java 的集合类很多,主要分为两大类(单列集合和双列集合)
| 单列集合 | 双列集合 |
|---|---|
 |
 |
List, Set, Queue, Map 的区别
List(对付顺序的好帮手): 存储的元素是有序的、可重复的。Set(注重独一无二的性质): 存储的元素是无序的、不可重复的。Queue(实现排队功能的叫号机): 存储的元素是有序的、可重复的。Map(用 key 来搜索的专家): 使用键值对存储,key 是无序的、不可重复的,value 是无序的、可重复的。
集合框架底层数据结构
List
ArrayList:Object[]数组Vector:Object[]数组LinkedList: 双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
Set
HashSet(无序,唯一): 基于HashMap实现的,底层采用HashMap来保存元素LinkedHashSet:LinkedHashSet是HashSet的子类,内部是通过LinkedHashMap来实现的。TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树)
Queue
PriorityQueue:Object[]数组来实现二叉堆ArrayQueue:Object[]数组 + 双指针
Map
HashMap:- JDK1.8 之前
HashMap由数组+链表组成,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。 - JDK1.8 以后
HashMap由数组+链表+红黑树,在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间
- JDK1.8 之前
LinkedHashMap:LinkedHashMap继承自HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。Hashtable: 数组+链表组成的,数组是Hashtable的主体,链表则是主要为了解决哈希冲突而存在的TreeMap: 红黑树(自平衡的排序二叉树)
一、Collection 接口
⓪Collection用法
⓿特点
public interface Collection<E> extends Iterable< E>
Collection 实现子类可以存放多个元素,每个元素可以是 Object
Collection 的实现类,有些可以存放重复的元素,有些不可以
Collection 的实现类,有些是有序的(List),有些不是有序(Set)
Collection 接口没有直接的实现子类,是通过它的子接口 List 和 Set 来实现的
❶常用方法
- add() 添加单个元素
- remove() 删除指定元素
- remove(index) //删除指定索引元素
- remove(Object) //删除指定某个元素
- contains() 查找元素是否存在
- size() 获取元素个数
- isEmpty() 判断是否为空
- clear() 清空
- addAll(Collection) 添加多个元素
- containsAll(Collection) 查找多个元素是否都存在
- removeAll(Collection) 删除多个元素
public class CollectionMethod {
public static void main(String[] args) {
// 说明:以ArrayList 实现类来演示
Collection col = new ArrayList();
// add:添加单个元素
col.add("jack");
col.add(10); //col.add(new Integer(10))
col.add(true);
System.out.println("col=" + col);
// remove:删除指定元素
col.remove(0);//删除第一个元素
System.out.println("col=" + col);
col.remove(true);//指定删除某个元素
System.out.println("col=" + col);
// contains:查找元素是否存在
System.out.println(col.contains("jack"));//F
// size:获取元素个数
System.out.println(col.size());//1
// isEmpty:判断是否为空
System.out.println(col.isEmpty());//F
// clear:清空
col.clear();
System.out.println("col=" + col);
// addAll:添加多个元素
Collection col2 = new ArrayList();
col2.add("红楼梦");
col2.add("三国演义");
col.addAll(col2);
System.out.println("col2=" + col2);
System.out.println("col=" + col);
// containsAll:查找多个元素是否都存在
System.out.println(col.containsAll(col2));//T
// removeAll:删除多个元素
col.add("聊斋");
col.removeAll(col2);
System.out.println("col=" + col);//[聊斋]
}
}
❷遍历
Iterator遍历
简介
- Iterator 对象称为迭代器, 主要仅用于遍历 Collection 集合中的元素,Iterator 本身并不存放对象。
- 所有实现了Collection 接口的集合类都有一个 iterator() 方法,用以返回一个实现了Iterator 接口的对象, 即可以返回一个迭代器。
Iterator 接口方法
- literator() 得到一个集合的迭代器
- hasNext() 判断是否还有下一个元素
- next() 下移并将下移以后集合位置上的元素返回
- remove() 移除集合元素
在调用 iterator.next() 方法之前必须要调用 iterator.hasNext() 进行检测。若不调用,如果下一条记录无效,直接调用 it.next() 会抛出NoSuchElementException异常。
public class CollectionIterator {
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book_("三国演义", "罗贯中", 10.1));
col.add(new Book_("小李飞刀", "古龙", 5.1));
col.add(new Book_("红楼梦", "曹雪芹", 34.6));
System.out.println("col=" + col);
//1. 先得到col 对应的迭代器
Iterator iterator = col.iterator();
//2. 使用while 循环遍历 快捷键:itit
while (iterator.hasNext()) {//判断是否还有数据
Object obj = iterator.next();//读取当前集合数据元素
System.out.println("col=" + obj);
}
//3. 当退出while 循环后, 这时iterator 迭代器,指向最后的元素
// iterator.next();//NoSuchElementException
//4. 如果希望再次遍历,需要重置我们的迭代器
iterator = col.iterator();
System.out.println("===第二次遍历===");
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("col=" + obj);
}
//5.移除集合元素
iterator = col.iterator();
System.out.println("===移除集合元素===");
while(iterator.hasNext()){
Object obj = iterator.next();
iterator.remove();
System.out.println("col=" + col);
}
}
}
class Book_ {
private String name;
private String author;
private double price;
public Book_(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
@Override
public String toString() {
return "Book_{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
}
增强for遍历
增强 for 循环, 可以代替 iterator 迭代器, 增强 for 底层就是迭代器
增强 for 就是简化版的 iterator,本质一样。只能用于遍历集合或数组。
基本语法:
for(元素类型 元素名:集合名或数组名) {}
public class CollectionFor {
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book_("三国演义", "罗贯中", 10.1));
col.add(new Book_("小李飞刀", "古龙", 5.1));
col.add(new Book_("红楼梦", "曹雪芹", 34.6));
System.out.println("col=" + col);
//增强for 快捷键:I
for (Object o :col) {
System.out.println("col=" + o);
}
}
}
class Book_ {
private String name;
private String author;
private double price;
public Book_(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
@Override
public String toString() {
return "Book_{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
}
①Collection子接口-List
⓿List用法
特点
List 接口是 Collection 接口的子接口
- List 集合类中元素有序(即添加顺序和取出顺序一致)、且可重复
List list = new ArrayList();
list.add("tom");
list.add("tom");//可以重复
list.add("mary");
list.add("jwt");
- List 集合中的每个元素都有其对应的顺序索引,即支持索引。
System.out.println(list.get(3));//jwt
- List 接口实现类常用的有:ArrayList、LinkedList、Vector
常用方法
- add() 添加单个元素
- add(int index, Object ele) 在 index 位置插入 ele 元素
- addAll(int index, Collection eles) 从 index 位置开始将 eles 中的所有元素添加进来
- get(int index) 获取指定 index 位置的元素
- indexOf(Object obj) 返回 obj 在集合中首次出现的位置
- lastIndexOf(Object obj) 返回 obj 在当前集合中末次出现的位置
- remove(int index) 移除指定 index 位置的元素,并返回此元素
- set(int index, Object ele) 设置指定 index 位置的元素为 ele , 相当于是替换
- subList(int fromIndex, int toIndex) 返回从 [fromIndex,toIndex) 位置的子集合
public class ListMethod {
public static void main(String[] args) {
List list = new ArrayList();
list.add("张三丰");
list.add("贾宝玉");
// void add(int index, Object ele):在index 位置插入ele 元素
//在index = 1 的位置插入一个对象
list.add(1, "简简");
System.out.println("list=" + list);
// boolean addAll(int index, Collection eles):从index 位置开始将eles 中的所有元素添加进来
List list2 = new ArrayList();
list2.add("jack");
list2.add("tom");
list.addAll(1, list2);
System.out.println("list2=" + list2);
System.out.println("list=" + list);
// Object get(int index):获取指定index 位置的元素
System.out.println(list.get(3));
// int indexOf(Object obj):返回obj 在集合中首次出现的位置
System.out.println(list.indexOf("tom"));//2
// int lastIndexOf(Object obj):返回obj 在当前集合中末次出现的位置
list.add("简简");
System.out.println("list=" + list);
System.out.println(list.lastIndexOf("简简"));
// Object remove(int index):移除指定index 位置的元素,并返回此元素
Object remove = list.remove(0);
System.out.println("remove = " + remove);
System.out.println("list=" + list);
// Object set(int index, Object ele):设置指定index 位置的元素为ele , 相当于是替换.
list.set(1, "玛丽");
System.out.println("list=" + list);
// List subList(int fromIndex, int toIndex):返回从[fromIndex,toIndex) 位置的子集合
List returnlist = list.subList(0, 2);
System.out.println("returnlist=" + returnlist);
}
}
遍历方式
public class ListFor {
public static void main(String[] args) {
//List 接口的实现子类ArrayList、Vector、LinkedList
//List list = new ArrayList();
//List list = new Vector();
List list = new LinkedList();
list.add("jack");
list.add("tom");
list.add("鱼香肉丝");
list.add("北京烤鸭子");
//遍历
//1. 迭代器 快捷代码itit
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println(obj);
}
//2. 增强for 快捷代码I
System.out.println("=====增强for=====");
for (Object o : list) {
System.out.println("o=" + o);
}
//3. 使用普通for
System.out.println("=====普通for====");
for (int i = 0; i < list.size(); i++) {
System.out.println("对象=" + list.get(i));
}
}
}
练习
题1
添加10个以上的元素,在2号位插入一个元素”简简”,获得第5个元素,删除第6个元素,修改第7个元素,在使用迭代器遍历集合,要求:使用 List 的实现类 ArrayList 完成。
package com.jwt.list_;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListExercise {
public static void main(String[] args) {
List list = new ArrayList();
for (int i = 0; i < 10; i++) {
list.add(i);
}
System.out.println(list);
//在2号位插入一个元素
list.add(1,"简简");
System.out.println(list);
//获得第5个元素
System.out.println(list.get(4));
//删除第6个元素
list.remove(5);
System.out.println(list);
//修改第7个元素
list.set(6,"简简");
System.out.println(list);
//迭代器遍历
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
}
题2
使用 List 的实现类添加三本图书,并遍历,打印如下效果
名称: xx 价格: xx 作者: xx
名称: xx 价格: xx 作者: xx
名称: xx 价格: xx 作者: xx
1)按价格排序,从低到高(使用冒泡法)
2)要求使用ArrayList、LinkedList 和Vector三种集合实现
package com.jwt.list_;
import java.util.List;
import java.util.Vector;
public class ListExercise02 {
public static void main(String[] args) {
//List<Book2> books = new ArrayList<Book2>();
//LinkedList<Book2> books = new LinkedList<Book2>();
Vector<Book2> books = new Vector<>();
books.add(new Book2("红楼梦", "曹雪芹", 90));
books.add(new Book2("西游记", "吴承恩", 100));
books.add(new Book2("水浒传", "施耐庵", 80));
System.out.println("==排序前==");
for (Object o : books) {
System.out.println(o);
}
System.out.println("==排序后==");
bubblesort(books);
for (Object o : books) {
System.out.println(o);
}
}
//冒泡排序
public static void bubblesort(List list) {
int listSize = list.size();
for (int i = 0; i < listSize - 1; i++) {
for (int j = 0; j < listSize - 1 - i; j++) {
//取出对象Book
Book2 book1 = (Book2) list.get(j);
Book2 book2 = (Book2) list.get(j + 1);
if (book1.getPrice() > book2.getPrice()) {//交换
list.set(j, book2);
list.set(j + 1, book1);
}
}
}
}
}
class Book2{
private String name;
private String author;
private double price;
public Book2(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "名称:" + name + "\t价格:" + price + "\t作者" + author ;
}
}
❶ArrayList
简介
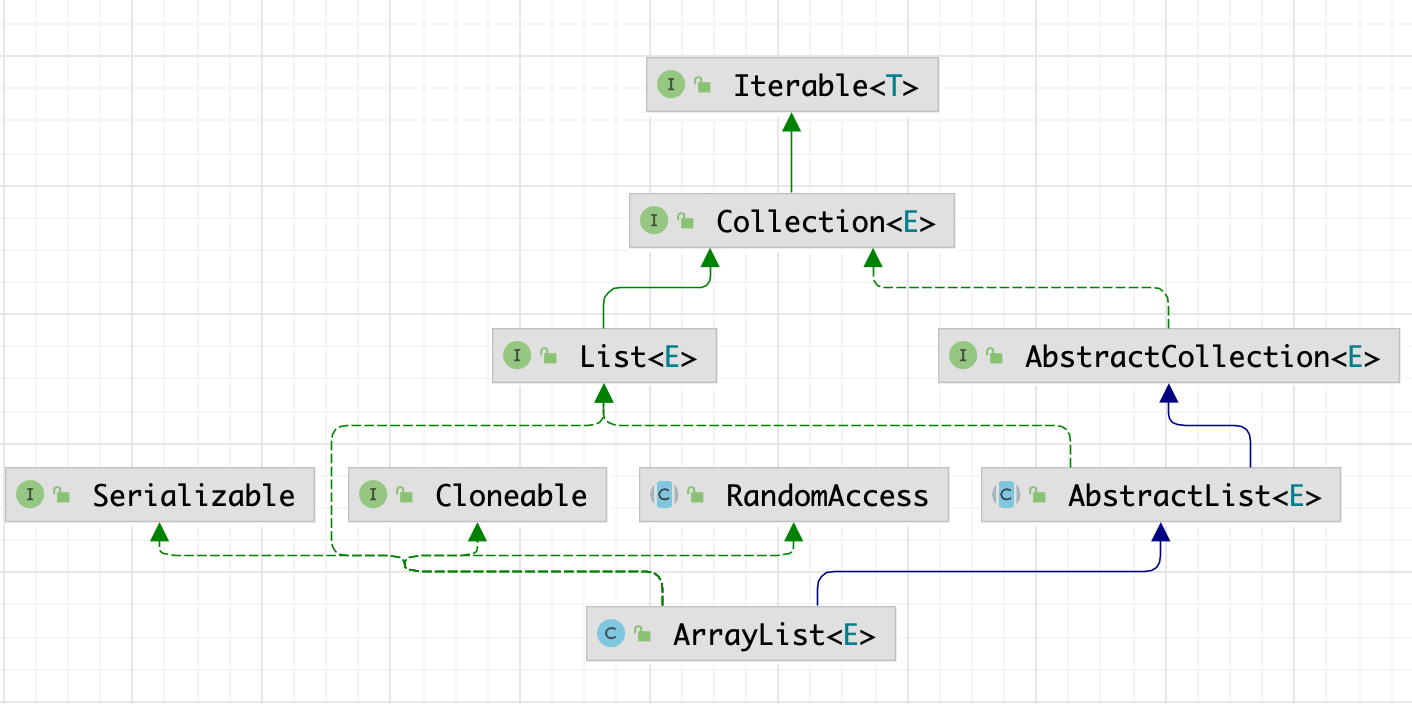
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{}
ArrayList 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。
ArrayList 继承于
AbstractList,实现了List,RandomAccess,Cloneable,java.io.Serializable这些接口。RandomAccess是一个标志接口,表明实现这个这个接口的 List 集合是支持快速随机访问的。在 ArrayList 中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。ArrayList实现了Cloneable接口 ,即覆盖了函数clone(),能被克隆。ArrayList实现了java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
特点
ArrayList 底层实现是一个
Object数组transient Object[] elementData;
ArrayList 只能存储对象引用类型,也就是说当我们需要装载的数据是诸如
int、float等基本数据类型的时候,必须把它们转换成对应的包装类ArrayList 可以加入 null,并且可以多个 null
list.add(null); list.add("jianjian"); list.add(null);ArrayList 基本等同于 Vector,除了 ArrayList 是线程不安全(执行效率高),在多线程情况下,不建议使用 ArrayList
//ArrayList 是线程不安全,没有 synchronized //add源码 public boolean add(E e) { ensureCapacityInternal(size + 1); elementData[size++] = e; return true; }
核心源码
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
* 默认初始容量大小
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 空数组(用于空实例)。
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
//用于默认大小空实例的共享空数组实例。
//我们把它从EMPTY_ELEMENTDATA数组中区分出来,以知道在添加第一个元素时容量需要增加多少。
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 保存ArrayList数据的数组
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* ArrayList 所包含的元素个数
*/
private int size;
/**
* 带初始容量参数的构造函数(用户可以在创建ArrayList对象时自己指定集合的初始大小)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//如果传入的参数大于0,创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//如果传入的参数等于0,创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
//其他情况,抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
*默认无参构造函数
*DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组 当添加第一个元素的时候数组容量才变成10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
*/
public ArrayList(Collection<? extends E> c) {
//将指定集合转换为数组
elementData = c.toArray();
//如果elementData数组的长度不为0
if ((size = elementData.length) != 0) {
// 如果elementData不是Object类型数据(c.toArray可能返回的不是Object类型的数组所以加上下面的语句用于判断)
if (elementData.getClass() != Object[].class)
//将原来不是Object类型的elementData数组的内容,赋值给新的Object类型的elementData数组
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 其他情况,用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}
}
/**
* 修改这个ArrayList实例的容量是列表的当前大小。 应用程序可以使用此操作来最小化ArrayList实例的存储。
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
//下面是ArrayList的扩容机制
//ArrayList的扩容机制提高了性能,如果每次只扩充一个,
//那么频繁的插入会导致频繁的拷贝,降低性能,而ArrayList的扩容机制避免了这种情况。
/**
* 如有必要,增加此ArrayList实例的容量,以确保它至少能容纳元素的数量
* @param minCapacity 所需的最小容量
*/
public void ensureCapacity(int minCapacity) {
//如果是true,minExpand的值为0,如果是false,minExpand的值为10
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
//如果最小容量大于已有的最大容量
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 获取“默认的容量”和“传入参数”两者之间的最大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//再检查新容量是否超出了ArrayList所定义的最大容量,
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
//比较minCapacity和 MAX_ARRAY_SIZE
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
/**
*返回此列表中的元素数。
*/
public int size() {
return size;
}
/**
* 如果此列表不包含元素,则返回 true 。
*/
public boolean isEmpty() {
//注意=和==的区别
return size == 0;
}
/**
* 如果此列表包含指定的元素,则返回true 。
*/
public boolean contains(Object o) {
//indexOf()方法:返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
return indexOf(o) >= 0;
}
/**
*返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
*/
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
//equals()方法比较
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。.
*/
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 返回此ArrayList实例的浅拷贝。 (元素本身不被复制。)
*/
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
//Arrays.copyOf功能是实现数组的复制,返回复制后的数组。参数是被复制的数组和复制的长度
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// 这不应该发生,因为我们是可以克隆的
throw new InternalError(e);
}
}
/**
*以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
*返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
*因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
*/
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
/**
* 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素);
*返回的数组的运行时类型是指定数组的运行时类型。 如果列表适合指定的数组,则返回其中。
*否则,将为指定数组的运行时类型和此列表的大小分配一个新数组。
*如果列表适用于指定的数组,其余空间(即数组的列表数量多于此元素),则紧跟在集合结束后的数组中的元素设置为null 。
*(这仅在调用者知道列表不包含任何空元素的情况下才能确定列表的长度。)
*/
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size)
// 新建一个运行时类型的数组,但是ArrayList数组的内容
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
//调用System提供的arraycopy()方法实现数组之间的复制
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
// Positional Access Operations
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
/**
* 返回此列表中指定位置的元素。
*/
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
/**
* 用指定的元素替换此列表中指定位置的元素。
*/
public E set(int index, E element) {
//对index进行界限检查
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
//返回原来在这个位置的元素
return oldValue;
}
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
//这里看到ArrayList添加元素的实质就相当于为数组赋值
elementData[size++] = e;
return true;
}
/**
* 在此列表中的指定位置插入指定的元素。
*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
*/
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//arraycopy()这个实现数组之间复制的方法一定要看一下,下面就用到了arraycopy()方法实现数组自己复制自己
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
/**
* 删除该列表中指定位置的元素。 将任何后续元素移动到左侧(从其索引中减去一个元素)。
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
//从列表中删除的元素
return oldValue;
}
/**
* 从列表中删除指定元素的第一个出现(如果存在)。 如果列表不包含该元素,则它不会更改。
*返回true,如果此列表包含指定的元素
*/
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/*
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
/**
* 从列表中删除所有元素。
*/
public void clear() {
modCount++;
// 把数组中所有的元素的值设为null
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
/**
* 按指定集合的Iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾。
*/
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
/**
* 将指定集合中的所有元素插入到此列表中,从指定的位置开始。
*/
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
/**
* 从此列表中删除所有索引为fromIndex (含)和toIndex之间的元素。
*将任何后续元素移动到左侧(减少其索引)。
*/
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// clear to let GC do its work
int newSize = size - (toIndex-fromIndex);
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}
/**
* 检查给定的索引是否在范围内。
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* add和addAll使用的rangeCheck的一个版本
*/
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 返回IndexOutOfBoundsException细节信息
*/
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
/**
* 从此列表中删除指定集合中包含的所有元素。
*/
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
//如果此列表被修改则返回true
return batchRemove(c, false);
}
/**
* 仅保留此列表中包含在指定集合中的元素。
*换句话说,从此列表中删除其中不包含在指定集合中的所有元素。
*/
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}
/**
* 从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。
*指定的索引表示初始调用将返回的第一个元素为next 。 初始调用previous将返回指定索引减1的元素。
*返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
/**
*返回列表中的列表迭代器(按适当的顺序)。
*返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator() {
return new ListItr(0);
}
/**
*以正确的顺序返回该列表中的元素的迭代器。
*返回的迭代器是fail-fast 。
*/
public Iterator<E> iterator() {
return new Itr();
}
扩容机制
为了方便复习先给出扩容源码分析的结论,然后再进行详细分析,分析流程是先把创建和扩容用到的属性和方法单独讲解,然后模拟一个场景来一步一步来 debug
结论
1.ArrayList 中维护了一个 Object 类型的数组 elementData
- transient Object[] elementData; //transient表示瞬间,短暂的,表示该属性不会被序
列化
- transient Object[] elementData; //transient表示瞬间,短暂的,表示该属性不会被序
2.创建 ArrayList 对象时,如果使用的是无参构造器,则初始 elementData 容量为 0
- 第 1 次添加,则扩容 elementData 为 10
- 如需再次扩容,则扩容 elementData 为 1.5 倍
3.创建 ArrayList 对象时,如果使用的是指定大小的构造器,则初始 elementData 容量为指定大小
- 如果需要扩容,则直接扩容 elementData 为 1.5 倍
属性&方法
如下是 ArrayList 创建和扩容用到的主要属性和方法,这里先列出来,后面再详细讲解
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
// 默认初始的容量
private static final int DEFAULT_CAPACITY = 10;
// 一个空数组
private static final Object[] EMPTY_ELEMENTDATA = {};
// 一个空数组,如果使用无参构造函数创建,则使用该值
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 当前数据对象存放地方,当前对象不参与序列化
transient Object[] elementData;
// 当前数组所包含的元素个数
private int size;
// 数组最大长度
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//protected transient int modCount = 0;
// modCount属性从AbstractList继承过来的,代表ArrayList集合的修改次数。
//如下是ArrayList创建和扩容主要方法,省略了方法体
public ArrayList(int initialCapacity) {}
public ArrayList() {}
public ArrayList(Collection<? extends E> c) {}
public boolean add(E e) {}
public void ensureCapacity(int minCapacity) {}
private static int calculateCapacity(Object[] elementData, int minCapacity) {}
private void ensureCapacityInternal(int minCapacity) {}
private void ensureExplicitCapacity(int minCapacity) {}
private void grow(int minCapacity) {}
private static int hugeCapacity(int minCapacity) {}
}
构造函数
无参构造函数
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
带int类型构造函数
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {//初始容量大于0
//创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {//初始容量等于0
//创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {//初始容量小于0,抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
带Collection对象构造函数
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
扩容方法
add
//将指定的元素追加到此列表的末尾
public boolean add(E e) {
//添加元素之前,先调用ensureCapacityInternal方法
ensureCapacityInternal(size + 1); // Increments modCount!!
//这里看到ArrayList添加元素的实质就相当于为数组赋值
elementData[size++] = e;
return true;
}
ensureCapacityInternal
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 获取默认的容量和传入参数的较大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
当 要 add 进第 1 个元素时,minCapacity 为 1,在 Math.max()方法比较后,minCapacity 为 10。
ensureExplicitCapacity
如果调用 ensureCapacityInternal() 方法就一定会进入(执行)这个方法
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
- 当我们要 add 进第 1 个元素到 ArrayList 时,elementData.length 为 0 (因为还是一个空的 list),因为执行了
ensureCapacityInternal()方法 ,所以 minCapacity 此时为 10。此时,minCapacity - elementData.length > 0成立,所以会进入grow(minCapacity)方法。 - 当 add 第 2 个元素时,minCapacity 为 2,此时 e lementData.length(容量)在添加第一个元素后扩容成 10 了。此时,
minCapacity - elementData.length > 0不成立,所以不会进入 (执行)grow(minCapacity)方法。 - 添加第 3、4···到第 10 个元素时,依然不会执行 grow 方法,数组容量都为 10。
grow
//要分配的最大数组大小
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//ArrayList扩容的核心方法。
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,
//如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);//扩容
}
ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity 为偶数就是 1.5 倍,否则是 1.5 倍左右)! 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
“>>”(移位运算符):>>1 右移一位相当于除 2,右移 n 位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了 1 位所以相当于 oldCapacity /2。对于大数据的 2 进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
hugeCapacity
如果新容量大于 MAX_ARRAY_SIZE,进入(执行) hugeCapacity() 方法来比较 minCapacity 和 MAX_ARRAY_SIZE
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
//对minCapacity和MAX_ARRAY_SIZE进行比较
//若minCapacity大,将Integer.MAX_VALUE作为新数组的大小
//若MAX_ARRAY_SIZE大,将MAX_ARRAY_SIZE作为新数组的大小
//MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
return (minCapacity > MAX_ARRAY_SIZE) ?Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
如果 minCapacity 大于最大容量,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 Integer.MAX_VALUE - 8

扩容场景模拟
案例1:无参构造函数
//模拟代码
import java.util.ArrayList;
public class ArrayListSource {
public static void main(String[] args) {
//使用无参构造器创建ArrayList 对象
ArrayList list = new ArrayList();
//使用for 给list 集合添加1-10 数据
for (int i = 1; i <= 10; i++) {
list.add(i);
}
//使用for 给list 集合添加11-15 数据
for (int i = 11; i <= 15; i++) {
list.add(i);
}
}
}
Step1
执行ArrayList list = new ArrayList();
//该步骤底层代码
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
执行时会调用无参数构造方法创建 ArrayList ,实际上创建了一个名为elementData 的Object[] 空数组,也就是说该数组可以放任何对象
Step2
执行 for (int i = 1; i <= 10; i++) {list.add(i);}
//该步骤底层代码
private int size;// 当前数组所包含的元素个数
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
添加元素之前,先调用 ensureCapacityInternal 方法
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
//计算最小扩容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// 如果元素数组为默认的空
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 获取“默认的容量”和“传入参数 minCapacity ”两者之间的最大值
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
当要 add 进第 1 个元素时,minCapacity 为 1,DEFAULT_CAPACITY 为 10,在 Math.max() 方法比较后,minCapacity 为 10,然后调用 ensureExplicitCapacity 方法
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;//记录修改次数
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
当要 add 进第 1 个元素时,elementData.length = 0 (因为还是一个空的 list),因为上步骤执行了 ensureCapacityInternal() 方法 ,所以 minCapacity = 10。此时,minCapacity - elementData.length > 0成立,所以会执行 grow() 方法。
//扩容方法
private void grow(int minCapacity) {
// 取到旧数组的长度
int oldCapacity = elementData.length;
//计算新数组的长度
//>>是移位运算符,相当于int newCapacity = oldCapacity + (oldCapacity/2),但性能会好一些
int newCapacity = oldCapacity + (oldCapacity >> 1);
//保证长度在正常范围内
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 用计算出来的数组长度,往下传继续处理
elementData = Arrays.copyOf(elementData, newCapacity);
}
此时 oldCapacity 为 0,经比较后第一个 if 判断成立,newCapacity = 10。但是第二个 if 判断不会成立,即 newCapacity 不比 MAX_ARRAY_SIZE 大,则不会执行 hugeCapacity 方法。然后调用 Arrays.copyOf() 方法进行扩容,数组扩容为 10,add 方法中 return true,size 增为 1。
当 add 第 2 个元素时,minCapacity 为 2,此时 elementData.length 在添加第一个元素后扩容成 10 了。此时,
minCapacity - elementData.length > 0不成立,所以不会执行 grow()方法。添加第 3、4···到第 10 个元素时,依然
不会执行 grow()方法,数组容量都为 10。直到添加第 11 个元素,minCapacity(为 11)比 elementData.length(为 10)要大。进入 grow () 方法进行扩容
Step3
执行 for (int i = 11; i <= 15; i++) {list.add(i);}
当 add 第 11 个元素进入 grow() 方法时,newCapacity 为 15,比 minCapacity 为 11大,第一个 if 判断不成立。新容量没有大于数组最大 size,不会进入 hugeCapacity 方法。扩容 elementData 为 1.5 倍,数组容量扩为 15,add 方法中 return true,size 增为 11。
以此类推······
案例2:有参构造函数
package com.jwt.list_;
import java.util.ArrayList;
public class ArrayListSource {
public static void main(String[] args) {
//使用有参构造器创建ArrayList 对象
ArrayList list = new ArrayList(8);
//使用for 给list 集合添加1-10 数据
for (int i = 1; i <= 10; i++) {
list.add(i);
}
//使用for 给list 集合添加11-15 数据
for (int i = 11; i <= 15; i++) {
list.add(i);
}
list.add(100);
list.add(200);
list.add(null);
}
}
有参构造与上面无参构造类似,区别在于第一步,有参构造是以传入的参数创建了一个名为elementData 的Object[指定大小] 空数组 ,如果需要扩容,也是调用无参构造相同的方法来进行扩容,第一次扩容就按照 elementData 的 1.5 倍扩容
❷Vector
特点
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{}
Vector 底层也是一个对象数组
protected Object[] elementData;
Vector是线程同步的,即线程安全,Vector 类的操作方法带有 synchronized
public synchronized boolean add(E e) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = e; return true; }需要线程同步安全是,考虑使用
扩容机制
结论
- 1、创建 Vector 对象时,如果使用的是无参构造器,则初始 elementData 容量为 0
- 第 1 次添加,则扩容 elementData 为 10
- 如需再次扩容,则扩容 elementData 为 2 倍
- 2、创建 Vector 对象时,如果使用的是指定大小的构造器,则初始 elementData 容量为指定大小
- 如果需要扩容,则直接扩容 elementData 为 2倍
- 3、创建 Vector 对象时,如果使用的是指定大小和增量的构造器(自定义扩容),则初始 elementData 容量为指定大小
- 如果需要扩容,则直接扩容原容量+容量增量
构造函数
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);//0代表容量增量
}
public Vector() {
this(10);
}
public Vector(Collection<? extends E> c) {
Object[] a = c.toArray();
elementCount = a.length;
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, elementCount, Object[].class);
}
}
扩容方法
add
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
ensureCapacityHelper
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
判断最小容量是否超出 elementData 数组的长度,如果超出就调用 grow() 进行扩容
grow
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
- capacityIncrement 未指定的话,新容量就为原容量的 2 倍
- capacityIncrement 指定的话,新容量就为原容量+容量增量
Vector和ArrayList对比
| 底层结构 | 版本 | 线程安全/效率 | 扩容倍数 | |
|---|---|---|---|---|
| ArrayList | 可变数组 | Jdk1.2 | 不安全、效率高 | 如果无参构造第一次10,第二次1.5倍;如果有参数构造按1.5倍扩 |
| Vector | 可变数组 | Jdk1.0 | 安全、效率不高 | 如果无参构造默认10,第二次2倍;如果有参数构造按2倍扩;如果指定增量按增量扩 |
❸LinkedList
特点

public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
- LinkedList底层实现了双向链表和双端队列特点,和 Deque 接口
- 可以添加任意元素(元素可以重复),包括 null
- 线程不安全,没有实现同步
模拟一个简单的双向链表
//定义一个Node 类,Node 对象表示双向链表的一个结点
class Node {
public Object item; //真正存放数据
public Node next; //指向后一个结点
public Node pre; //指向前一个结点
public Node(Object name) {
this.item = name;
}
public String toString() {
return "Node name=" + item;
}
}
使用双向链表
public class LinkedList01 {
public static void main(String[] args) {
//模拟一个简单的双向链表
Node jack = new Node("jack");
Node tom = new Node("tom");
Node jwt = new Node("jwt");
//连接三个结点,形成双向链表
//jack -> tom -> jwt
jack.next = tom;
tom.next = jwt;
//jwt -> tom -> jack
jwt.pre = tom;
tom.pre = jack;
Node first = jack; //让first 引用指向jack,就是双向链表的头结点
Node last = jwt; //让last 引用指向jwt,就是双向链表的尾结点
//从头到尾进行遍历
System.out.println("===从头到尾进行遍历===");
while (true) {
if (first == null) {
break;
}
//输出first 信息
System.out.println(first);
first = first.next;
}
//从尾到头的遍历
System.out.println("===从尾到头的遍历===");
while (true) {
if (last == null) {
break;
}
//输出last 信息
System.out.println(last);
last = last.pre;
}
//链表的添加对象/数据,是多么的方便
//要求,是在tom--jwt之间,插入一个对象smith
//1. 先创建一个Node 结点,name 就是smith
Node smith = new Node("smith");
//下面就把smith 加入到双向链表了
smith.next = jwt;
smith.pre = tom;
jwt.pre = smith;
tom.next = smith;
//让first 再次指向jack
first = jack;//让first 引用指向jack,就是双向链表的头结点
System.out.println("===从头到尾进行遍历===");
while (true) {
if (first == null) {
break;
}
//输出first 信息
System.out.println(first);
first = first.next;
}
last = jwt; //让last 重新指向最后一个结点
//从尾到头的遍历
System.out.println("===从尾到头的遍历===");
while (true) {
if (last == null) {
break;
}
//输出last 信息
System.out.println(last);
last = last.pre;
}
}
}
增删改查使用
public class LinkedListCRUD {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.add(1);
linkedList.add(2);
linkedList.add(3);
linkedList.add(4);
linkedList.add(4,5);
System.out.println("linkedList=" + linkedList);
//演示一个删除结点的
linkedList.remove(); //默认删除的是第一个结点
linkedList.remove(2);//删除索引为2的结点
System.out.println("linkedList=" + linkedList);
//修改某个结点对象
linkedList.set(1, 999);
System.out.println("linkedList=" + linkedList);
//得到某个结点对象
Object o = linkedList.get(1);//得到双向链表的第二个对象
System.out.println(o);//999
//因为LinkedList 是实现了List 接口, 遍历方式
System.out.println("===LinkeList 遍历迭代器====");
Iterator iterator = linkedList.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("next=" + next);
}
System.out.println("===LinkeList 遍历增强for====");
for (Object o1 : linkedList) {
System.out.println("o1=" + o1);
}
System.out.println("===LinkeList 遍历普通for====");
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
}
}
源码阅读
LinkedList 底层维护了一个双向链表
LinkedList 中维护了两个属性 first 和 last 分别指向首节点和尾节点
每个结点(Node对象),里面又维护了 prev、 next、 item 三个属性,其中通过 prev 指向前一个,通过 next 指向后一个节点,最终实现双向链表。
LinkedList 的元素的添加和删除,不是通过数组完成的,相对来说效率较高。
数据结构
// 元素个数
transient int size = 0;
// 链表头节点
transient Node<E> first;
// 链表尾节点
transient Node<E> last;
//链表节点结构
private static class Node<E> {
//数据
E item;
// 前驱,后继指针
Node<E> next;
Node<E> prev;
// 构造函数
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
构造函数
//无参构造
public LinkedList() {
}
//带Collection对象构造函数
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
增加结点
增加单个结点
//默认增加
public boolean add(E e) {
linkLast(e);//调用增加尾结点方法
return true;
}
//根据索引增加
public void add(int index, E element) {
//判断下标是否越界,越界就抛出异常
checkPositionIndex(index);
//如果增加位置是尾部index,和上面调用的同一个方法
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
增加尾结点
void linkLast(E e) {
//得到当前的最后一个元素节点
final Node<E> l = last;
//构造新节点,并设置当前上一个节点是l,元素为e,下一个节点为null
final Node<E> newNode = new Node<>(l, e, null);
//现在最新的last节点为新插入的节点
last = newNode;
//判断l节点是否为空,为空的话则代表当前插入的是第一个元素,则需要设置首节点也为当前的新节点,反之则设置原先的最后一个节点的next节点是当前新的节点
if (l == null)
first = newNode;
else
l.next = newNode;
//元素数量+1
size++;
//链表改动次数+1
modCount++;
}
增加头结点
private void linkFirst(E e) {
final Node<E> f = first;
// 创建新节点,后继为原头节点
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
// 若之前链表为空,设置 last
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
增加中间结点
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
//得到index下标节点的前一个
final Node<E> pred = succ.prev;
//构造新节点,新节点的前一个节点为原先这个index位置的前一个节点,设置新节点的下一个节点为原先index节点
final Node<E> newNode = new Node<>(pred, e, succ);
//设置原先index位置的节点的前一个为新节点
succ.prev = newNode;
//如果pred节点为null,则代表succ是头节点,现在设置头节点为新节点
if (pred == null)
first = newNode;
else
//如果pred节点不为null,则修改pred的下一个节点为新节点
pred.next = newNode;
//元素数量+1
size++;
//链表修改次数+1
modCount++;
}
批量增加
public boolean addAll(int index, Collection<? extends E> c) {
//先判断下标是否越界,越界就抛出异常
checkPositionIndex(index);
//将拆入的元素集合转换为数组
Object[] a = c.toArray();
//得到数组的大小
int numNew = a.length;
if (numNew == 0)
return false;
//定义前一个节点,当前节点
Node<E> pred, succ;
//拆入位置是size,即接着尾部拆入
if (index == size) {
//当前节点没有,前一个节点就是当前最后一个节点
succ = null;
pred = last;
} else {
//当前节点就是index位置的节点,前一个节点直接拿prev获取
succ = node(index);
pred = succ.prev;
}
//快速for处理待拆入元素的数组
for (Object o : a) {
//元素转换
@SuppressWarnings("unchecked") E e = (E) o;
//构建新节点的前一个是pred,元素为e,下一个节点为null
Node<E> newNode = new Node<>(pred, e, null);
//如果pred节点为null,则代表原先index位置的节点为头节点,则需要重新设置头节点
if (pred == null)
first = newNode;
else
//如果pred节点不为null,则设置原先index位置的节点的下一个节点为当前新节点
pred.next = newNode;
//一个新节点完成后,设置上一个为当前新节点,直到把所有元素拆入完成
pred = newNode;
}
//index位置的原先节点为null,则代表index原先的前一个节点就是最后一个节点,则设置最后一个节点就是最新最后的那个节点
if (succ == null) {
last = pred;
} else {
//index位置的原先节点不为null,则设置拆入数组的最后一个元素的最后一个节点的next是succ,succ的前一个是当前这个
pred.next = succ;
succ.prev = pred;
}
//得到新链表元素的数量
size += numNew;
//链表改动次数+1
modCount++;
return true;
}
扩展的方法
如下方法都是基于上面方法扩展出来的
public void addFirst(E e) {
linkFirst(e);
}
public void addLast(E e) {
linkLast(e);
}
public boolean offer(E e) {
return add(e);
}
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
public boolean offerLast(E e) {
addLast(e);
return true;
}
public void push(E e) {
addFirst(e);
}
删除结点
删除单个结点
//默认删除
public E remove() {
return removeFirst();//调用删除头结点的方法
}
//根据索引删除
public E remove(int index) {
//下标都先判断下标是否越界,越界就抛出异常
checkElementIndex(index);
return unlink(node(index));//调用删除中间结点的方法
}
//找到需要删除的节点
Node<E> node(int index) {
// assert isElementIndex(index);
//二分查找的思想,判断一下是在链表的前半部分还是后半部分
if (index < (size >> 1)) {
//从头节点一直找到index位置拿到节点
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//从尾节点一直找到index位置拿到节点
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
删除头节点
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
// 相应数据设为 null,从而之后GC清理
f.item = null;
f.next = null; // help GC
first = next;
// 就一个节点,删完了
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
删除尾节点
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
// 相应数据设为 null,从而之后GC清理
l.item = null;
l.prev = null; // help GC
last = prev;
// 就一个节点,删完了
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
删除中间节点
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
// 为头节点,则设置新头节点
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
// 为尾节点,则设置新尾节点
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
扩展的方法
和增加一样,删除也有很多扩展版本,不过基础还是上面三个方法。
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
public E pop() {
return removeFirst();
}
更新结点
public E set(int index, E element) {
// 下标合法性检查
checkElementIndex(index);
// 获取index下标节点
Node<E> x = node(index);
// 获取旧值
E oldVal = x.item;
// 设置新值
x.item = element;
// 返回旧值
return oldVal;
}
// 采用二分法遍历每个Node节点,直到找到index位置的节点
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
查找结点
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// 采用二分法遍历每个Node节点,直到找到index位置的节点
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
ArrayList和LinkedList比较
| 底层结构 | 增删效率 | 改查效率 | |
|---|---|---|---|
| ArrayList | 可变数组 | 较低,数组扩容 | 较高 |
| LinkedList | 双向链表 | 较高,链表追加 | 较低 |
- 如果我们改查的操作多,选择 ArrayList
- 如果我们增删的操作多,选择 LinkedList
- 一般来说,在程序中,80%-90% 都是查询,因此大部分情况下会选择 ArrayList
- 在一个项目中,根据业务灵活选择,也可能这样,一个模块使用的是 ArrayList,另外一个模块是 LinkedList,要根据业务来进行选择
②Collection子接口-Set
⓿Set用法
特点
Set 接口是 Collection 接口的子接口
- 无序性:无序(添加和取出顺序不一致),取出的顺序的顺序虽然不是添加的顺序,但是每次取出顺序是固定的
- 不重复性:不允许重复元素,因此最多只包含一个 null
Set set = new HashSet();
set.add("jack");
set.add("lucy");
set.add("jack");//重复,添加不成功
set.add("jwt");
set.add(null);
set.add(null);//再次添加null,添加不成功
for(int i = 0; i <3;i ++) {
System.out.println("set=" + set);
}
/*
set=[null, jwt, lucy, jack]
set=[null, jwt, lucy, jack]
set=[null, jwt, lucy, jack]
*/
不能使用索引的方式来获取
Set 接口实现类常用的有:HashSet、LinkedHashSet、TreeSet
遍历方式
同 Collection 的遍历方式一样,因为 Set 接口是 Collection 接口的子接口。
- 1.可以使用迭代器
- 2.增强 for
public class SetMethod {
public static void main(String[] args) {
Set set = new HashSet();
set.add("jack");
set.add("lucy");
set.add("jwt");
set.add(null);
System.out.println("=====使用迭代器====");
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
set.remove(null);
//方式2: 增强for
System.out.println("=====增强for====");
for (Object o : set) {
System.out.println("o=" + o);
}
}
}
❶HashSet
特点
- HashSet 实现了 Set 接口
- HashSet 底层实际上是 HashMap,HashMap 底层是数组 + 链表 + 红黑树
public HashSet() {
map = new HashMap<>();
}
- 不重复性:HashSet 可以存放 null 值,但是只能有一个 null,不能有重复元素/对象,下面会详细分析
HashSet hashSet = new HashSet();
hashSet.add(null);
hashSet.add(null);//添加失败
- 无序性:HashSet 不保证元素是有序的(即,不保证存放元素的插入顺序和取出顺序一致)
HashSet<String> hashSet = new HashSet<>();
hashSet.add("深圳");
hashSet.add("北京");
hashSet.add("西安");
// 循环打印 HashSet 中的所有元素
hashSet.forEach(m -> System.out.println(m));
/*
西安
北京
深圳
*/
//HashSet 插入的顺序是:深圳 -> 北京 -> 西安,而循环打印的顺序却是:西安 -> 深圳 -> 北京,所以 HashSet 是无序的,不能保证插入和迭代的顺序一致。
添加元素机制
结论
- HashSet 底层是 HashMap,HashMap 底层是数组 + 链表 + 红黑树
- 添加一个元素时,先计算 hash 值,得出索引值,找到存储数据表 table,看这个索引位置是否已经存放元素,如果没有,直接加入;如果有,调用 equals 比较
- 如果相同,就放弃添加;
- 如果不相同,则添加到最后,形成链表
- 在 Java 8 中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是8),并且 table 的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
源码分析
//debug如下代码
import java.util.HashSet;
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");//第一次
hashSet.add("java");//第二次
System.out.println("set=" + hashSet);
}
}
Step1
执行 HashSet hashSet = new HashSet();
//该步骤底层代码
public HashSet() {
map = new HashMap<>();
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
//其他构造方法
//指定集合转化为HashSet, 完成map的创建
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//指定初始化大小,和负载因子
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
//指定初始化大小
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
//指定初始化大小和负载因子,dummy 无实际意义
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
Step2
执行hashSet.add("java");
//1、执行add(),调用put()
public boolean add(E e) {
return map.put(e, PRESENT)==null;// hashmap 中 put() 返回 null 时,表示操作成功
}
// 虚拟对象
private static final Object PRESENT = new Object();
//HashSet是通过HashMap来保存元素,由于只需要在key中保存,所以采用虚拟对象PRESENT对应map中插入key-value的value值的引用。每次向map中添加元素时,键值对对应的value都是PRESENT。
//2、执行put(),调用hash()和putVal()
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//3、执行hash(),调用hashCode()
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);//并不是直接返回hash值,做了处理,为了避免hash碰撞
}//先计算key的hash值,再计算该hash值无符号右移16位的值,再将两者进行^按位异或
//4、执行hashCode(),计算key的hash值
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
//5.执行putVal()
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;//定义了辅助变量
//table是HashMap的一个属性,存放结点的,类型是Node[]
//这里就是第一次扩容,到16个空间.
if ((tab = table) == null || (n = tab.length) == 0)
//如果哈希表为空,调用resize(),创建一个哈希表,并用变量n记录哈希表长度
n = (tab = resize()).length;//执行完resize(),tab大小为16
//(1)根据key,得到hash 去计算该key 应该存放到table 表的哪个索引位置
//并把这个位置的对象,赋给p
//(2)判断p是否为null
//(2.1) 如果p为null, 表示还没有存放元素, 就创建一个Node (key="java",value=PRESENT)
//(2.2) 就放在该位置tab[i] = newNode(hash, key, value, null)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
/*第一次add都不执行
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//第一次add不进入
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}*/
++modCount;
if (++size > threshold)//每加入一个结点Node(k,v,h,next), size++
resize();
afterNodeInsertion(evict);//空方法,HashMap留给子类去实现
return null;
}
//创建一个哈希表或者扩容哈希表
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;//默认容量
//static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //默认值16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//临界值
//static final float DEFAULT_LOAD_FACTOR = 0.75f;//加载因子0.75
//临界值=加载因子(0.75)*默认容量
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;//临界值
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//新建容量为16的节点数组
table = newTab;//把建好的数组赋给table
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
Step3
执行hashSet.add("java");//第二次
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
/*第二次add不执行
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
*/
else {
Node<K,V> e; K k;
//如果当前索引位置对应的链表的第一个元素和准备添加的key的hash值一样
//并且满足下面两个条件之一
//1.准备加入的key和p指向的Node结点的key是同一个对象
//2.p指向的Node结点的key的equals()和准备加入的key比较后相同
//就不能加入
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//再判断p是不是一颗红黑树
//如果是一颗红黑树,就调用putTreeVal,来进行添加
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//如果table对应索引位置,已经是一个链表,就用for循环比较
else {
for (int binCount = 0; ; ++binCount) {
//依次和该链表的每一个元素比较后,都不相同,则加入到该链表最后
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//注意在把元素添加到链表后,立即判断该链表是否已经达到8个结点
if (binCount >= TREEIFY_THRESHOLD - 1) // 8-1
//就调用treeifyBin(),对当前这个链表进行树化(转成红黑树)
treeifyBin(tab, hash);
//注意,转成红黑树时,要进行判断,如果该table数组的大小>64,小于到话先扩容再转成红黑树
break;
}
//依次和该链表的每个元素比较过程中,如果有相同情况,就直接break
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;//p往后移
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
扩容机制
结论
HashSet 底层是 HashMap,第一次添加时,table 数组扩容到 16,临界值 threshold = 16 * loadFactor(加载因子:0.75) = 12
- 如果 table 数组使用到了临界值 12,就会扩容到 16 * 2 = 32,新的临界值就是32*0.75 = 24,依次类推
在 Java 8 中,如果一条链表的元素个数到达 TREEIFY_TH RESHOLD(默认是8),
并且 table 的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树),否则仍然采用数组扩容机制
扩容源码
int threshold;//临界值,该数值决定什么时候开始下一次扩容
static final int MAXIMUM_CAPACITY = 1 << 30;//很大的数,基本不会碰上
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //16
static final float DEFAULT_LOAD_FACTOR = 0.75f;//负载因子,决定临界值大小
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;//获得table大小
int oldThr = threshold;//获得临界值,新数组则为0
int newCap, newThr = 0;//新数组容量和临界值
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//原数组大小大于16时,临界值设置为原来的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0)//意味着老数组没有元素
//初始容量设置为临界值
newCap = oldThr;
else {
//说明是调用无参构造器创建的旧数组,并且第一次添加元素
newCap = DEFAULT_INITIAL_CAPACITY;//16
//新临界值 = 负载因子 * 默认容量
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//0.75 * 16
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//将新临界值赋值给 threshold
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//new 一个新的 Node 数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//原数组不为空,说明是扩容操作,则涉及到元素转移操作
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//如果当前位置元素不为空,那么需要转移该元素到新数组
if ((e = oldTab[j]) != null) {
//置空 oldTab[j],便于虚拟机回收
oldTab[j] = null;
//如果 e 的后结点为空,则计算 e 在 newTab 中的位置并置入
if (e.next == null)
//如果这个oldTab[j]就一个元素,那么就直接放到newTab里面
// 把元素存储到新的数组中,存储到数组的哪个位置需要根据hash值和数组长度来进行取模
// 【hash值 % 数组长度】 = 【 hash值 & (数组长度-1)】
// 数组扩容后,所有元素都需要重新计算在新数组中的位置。
newTab[e.hash & (newCap - 1)] = e;
//如果此时 e 已经转为红黑树结点
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // e 有后结点
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//重点难点!!!
//与运算 & 是 两个位都为1时,结果才为1
//(e.hash & oldCap) 得到的是 元素在数组中的位置是否需要移动
// 示例1:
// e.hash=10 0000 1010
// oldCap=16 0001 0000
// & =0 0000 0000 比较高位的第一位 0
//结论:元素位置在扩容后数组中的位置没有发生改变
// 示例2:
// e.hash=17 0001 0001
// oldCap=16 0001 0000
// & =1 0001 0000
//结论:元素位置在扩容后数组中的位置发生了改变,新的下标位置是原下标位置+原数组长度
if ((e.hash & oldCap) == 0) {//扩容后不需要移动的链表
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {//扩容后需要移动的链表
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashSet 检查重复
我们只要了解了 HashSet 执行添加元素的流程,就能知道为什么 HashSet 能保证元素不重复了?
HashSet 添加元素的执行流程是:当把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现,会将对象插入到相应的位置中。但是如果发现有相同 hashcode 值的对象,这时会调用对象的 equals() 方法来检查对象是否真的相同,如果相同,则 HashSet 就不会让重复的对象加入到 HashSet 中,这样就保证了元素的不重复。
总结
HashSet 底层是由 HashMap 实现的,它可以实现重复元素的去重功能,如果存储的是自定义对象必须重写 hashCode 和 equals 方法。HashSet 保证元素不重复是利用 HashMap 的 put 方法实现的,在存储之前先根据 key 的 hashCode 和 equals 判断是否已存在,如果存在就不在重复插入了,这样就保证了元素的不重复。
练习
判断题
package com.jwt.set_;
import java.util.HashSet;
public class HashSet01 {
public static void main(String[] args) {
HashSet set = new HashSet();
//1. 在执行add 方法后,会返回一个boolean 值
//2. 如果添加成功,返回true, 否则返回false
System.out.println(set.add("john"));//T
System.out.println(set.add("lucy"));//T
System.out.println(set.add("john"));//F
System.out.println(set.add("jack"));//T
System.out.println(set.add("Rose"));//T
//3. 可以通过remove 指定删除哪个对象
set.remove("john");
System.out.println("set=" + set);//3 个
//4. Hashset 不能添加相同的元素/数据
set.add("lucy");//添加成功
set.add("lucy");//加入不了
set.add(new Dog("tom"));//OK
set.add(new Dog("tom"));//Ok
System.out.println("set=" + set);
set.add(new String("jwt"));//ok
set.add(new String("jwt"));//加入不了
System.out.println("set=" + set);
}
}
class Dog { //定义了Dog 类
private String name;
public Dog(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}
编程题1
定义一个 Employee 类,该类包含: private成员属性name,age 要求:
- 创建 3 个 Employee 对象放入 HashSet 中
- 当 name 和 age 的值相同时,认为是相同员工,不能添加到 HashSet 集合中
package com.jwt.set_;
import java.util.HashSet;
import java.util.Objects;
public class HashSetExercise {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add(new Employee("milan", 18));//ok
hashSet.add(new Employee("smith", 28));//ok
hashSet.add(new Employee("milan", 18));//加入不成功.
System.out.println("hashSet=" + hashSet);
}
}
class Employee{
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "\nEmployee{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
//如果name 和age 值相同,则返回相同的hash 值
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age && Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
编程题2
定义一个Employee02类,该类包含: private 成员属性name,sal,birthday(MyDate) 类
型),其中 birthday 为 MyDate 类型(属性包括: year,month,day) 要求:
- 创建 3 个 Employee02 对象放入 HashSet 中
- 当 name 和 birthday 的值相同时,认为是相同员工,不能添加到 HashSet 集合中
要点:Employee02 类和 MyDate 类都要重写 equals 和 hashCode 方法,因为都是创建了新对象
package com.jwt.set_;
import java.util.HashSet;
import java.util.Objects;
public class HashSetExercise02 {
public static void main(String[] args) {
HashSet<Employee02> hashSet = new HashSet<>();
hashSet.add(new Employee02("tom",new MyDate(2000,7,1)));
hashSet.add(new Employee02("jack",new MyDate(2001,9,1)));
hashSet.add(new Employee02("tom",new MyDate(2000,7,1)));
System.out.println("hashSet = " + hashSet);
}
}
class Employee02{
private String name;
private MyDate birthday;
public Employee02(String name, MyDate birthday) {
this.name = name;
this.birthday = birthday;
}
@Override
public String toString() {
return "\nEmployee02{" +
"name='" + name + '\'' +
", birthday=" + birthday +
'}';
}
//如果name 和birthday 值相同,则返回相同的hash 值
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee02 that = (Employee02) o;
return Objects.equals(name, that.name) && Objects.equals(birthday, that.birthday);
}
@Override
public int hashCode() {
return Objects.hash(name, birthday);
}
}
class MyDate{
private int year;
private int month;
private int day;
public MyDate(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
@Override
public String toString() {
return "MyDate{" +
"year=" + year +
", month=" + month +
", day=" + day +
'}';
}
//birthday 的year、month、day相同,则返回相同的hash 值
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyDate myDate = (MyDate) o;
return year == myDate.year && month == myDate.month && day == myDate.day;
}
@Override
public int hashCode() {
return Objects.hash(year, month, day);
}
}
❷LinkedHashSet
特点
- LinkedHashSet 是 HashSet 的子类
- LinkedHashSet 底层是一个 LinkedHashMap,底层维护了一个数组+双
向链表 - 有序性:LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的
- 不重复性:LinkedHashSet 不允许添重复元素

栗子🌰:Car类(属性:name,price),如果 name 和 price 一样,则认为是相同元素,就不能添加。
package com.jwt.set_;
import java.util.LinkedHashSet;
import java.util.Objects;
public class LinkedHashSetExercise {
public static void main(String[] args) {
LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add(new Car("奥拓", 1000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//OK
linkedHashSet.add(new Car("法拉利", 10000000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//加入不了
linkedHashSet.add(new Car("保时捷", 70000000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//加入不了
System.out.println("linkedHashSet = " + linkedHashSet);
}
}
class Car{
private String name;
private double price;
public Car(String name, double price) {
this.name = name;
this.price = price;
}
@Override
public String toString() {
return "\nCar{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
//重写equals方法和hashCode
//当name 和price 相同时, 就返回相同的hashCode 值, equals 返回t
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Car car = (Car) o;
return Double.compare(car.price, price) == 0 && Objects.equals(name, car.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
}
❸TreeSet
可以按照添加对象指定属性进行排序
向TreeSet中添加的数据,要求是相同类的对象
TreeSet set = new TreeSet();
set.add(456);
set.add(123);
set.add("AA");//报错,此处向TreeSet中添加的必须是同一类的对象
两种排序方式:
- 自然排序(实现Comparable接口)
- 自然排序中,比较两个对象是否相等的标准为:compareTo()返回0,不再是equals()
- 定制排序(comparator)
- 定制排序中,比较两个对象是否相同的标准为:compare() 返回0,而不是equals()
TreeSet 中是通过红黑二叉树来实现对添加的数据进行去重排序,其中排序需要两种比较方式的重写来规定进行排序的类的属性。
public class TreeSet_ {
public static void main(String[] args) {
//默认从小到大排序
TreeSet set = new TreeSet();
set.add(34);
set.add(-34);
set.add(43);
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
自然排序
public class TreeSet_ {
public static void main(String[] args) {
TreeSet set = new TreeSet();
set.add(new Person("Tom", 12));
set.add(new Person("Jerry", 32));
set.add(new Person("Jim", 2));
set.add(new Person("Mike", 65));
set.add(new Person("Jack", 33));
set.add(new Person("Jack", 56));
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
class Person implements Comparable{
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Object o) {
if (o instanceof Person) {
Person p1 = (Person) o;
// return Integer.compare(this.getAge(), p1.getAge());//按年龄从小到大
return this.name.compareTo(p1.name);//按姓名从大到小
} else {
throw new RuntimeException("输入类型不一致");
}
}
}
定制排序
public class TreeSet_ {
public static void main(String[] args) {
TreeSet set = new TreeSet();
//通过定制排序实现年龄从小到大的顺序
Comparator com=new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof Person && o2 instanceof Person) {
Person p1 = (Person) o1;
Person p2 = (Person) o2;
return Integer.compare(p1.getAge(), p2.getAge());
} else {
throw new RuntimeException("输入类型不一致");
}
}
};
TreeSet set2 = new TreeSet(com);
set2.add(new Person("Tom", 12));
set2.add(new Person("Jerry", 32));
set2.add(new Person("Jim", 2));
set2.add(new Person("Mike", 65));
set2.add(new Person("Jack", 33));
Iterator iterator = set2.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
class Person{
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
二、Map 接口
⓪Map用法
特点
- Map 用于保存具有映射关系的数据:Key-Value(双列元素)
- Map 中的 key 和 value 可以是任何引用类型的数据,会封装到HashMap$Node 对象中
- Map 中的 key 不允许重复,原因和 HashSet 一样,前面分析过源码,当当有相同的k,后添加的 value 会覆盖之前的,相当于替换
Map map = new HashMap();
map.put("no1", "小明");//k-v
map.put("no1", "小红");//当有相同的k,就等价于替换
//输出:{no1=小红}
- Map 中的 value 可以重复
map.put("no1", "小明");
map.put("no2", "小明");
//输出:{no2=小明, no1=小明}
- Map 的 key 可以为 null, value 也可以为null
- 但是 key 为 null,只能有一个
- value 为 null 可以有多个
- 常用 String 类作为 Map 的 key
map.put(null, "abc"); //ok
map.put("no4", null); //ok
map.put(null, "abcd"); //会覆盖abc
map.put("no5", null);//ok
//输出:{null=abcd,, no4=null, no5=null}
- key 和 value 之间存在单向对一关系,即通过指定的 key 总能找到对应的 value
System.out.println(map.get("no1"));//小明
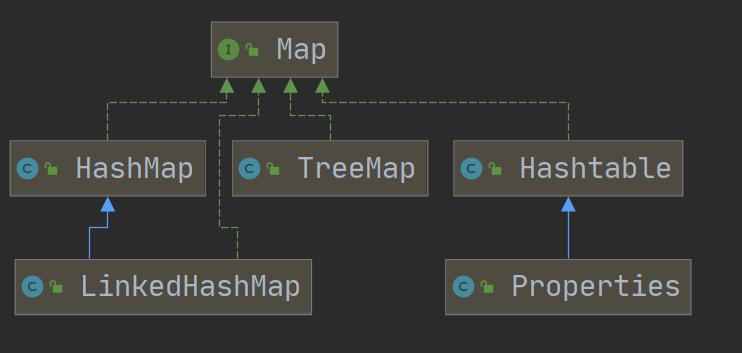
- Map 接口的常用实现类:HashMap、Hashtable、TreeMap、LinkedHashMap、Properties
常用方法
- put() 添加映射关系
- remove() 根据键删除映射关系
- get() 根据键获取值
- size() 获取元素个数
- isEmpty() 判断个数是否为0
- containsKey() 查找键是否存在
- clear() 清除映射关系
- getOrDefault(key, defaultValue) 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值。
public class MapMethod {
public static void main(String[] args) {
Map map = new HashMap();
//put:添加映射关系
map.put("no1", "小明");//OK
map.put("no2", "小红");//OK
System.out.println("map=" + map);
// remove:根据键删除映射关系
map.remove("no2");
System.out.println("map=" + map);
// get:根据键获取值
Object val = map.get("no1");
System.out.println("val=" + val);
// size:获取元素个数
System.out.println("k-v=" + map.size());
// isEmpty:判断个数是否为0
System.out.println(map.isEmpty());//F
// containsKey:查找键是否存在
System.out.println("结果=" + map.containsKey("no1"));//T
// clear:清除k-v
map.clear();
System.out.println("map = " + map);
}
}
/*
map={no2=小红, no1=小明}
map={no1=小明}
val=小明
k-v=1
false
结果=true
map = {}
*/
遍历
keySet:获取所有的键
public class MapFor {
public static void main(String[] args) {
Map map = new HashMap();
map.put("邓超", "孙俪");
map.put("王宝强", "马蓉");
map.put("宋喆", "马蓉");
map.put("刘令博", null);
map.put(null, "刘亦菲");
map.put("鹿晗", "关晓彤");
//方法1: 先取出所有的Key , 通过Key 取出对应的Value
Set keyset = map.keySet();
//(1) 增强for
System.out.println("-----第一种方式-------");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
//(2) 迭代器
System.out.println("----第二种方式--------");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
}
}
values:获取所有的值
public class MapFor {
public static void main(String[] args) {
Map map = new HashMap();
map.put("邓超", "孙俪");
map.put("王宝强", "马蓉");
map.put("宋喆", "马蓉");
map.put("刘令博", null);
map.put(null, "刘亦菲");
map.put("鹿晗", "关晓彤");
//方法2: 把所有的values 取出
Collection values = map.values();
//这里可以使用所有的Collections 使用的遍历方法
//(1) 增强for
System.out.println("---取出所有的value 增强for----");
for (Object value : values) {
System.out.println(value);
}
//(2) 迭代器
System.out.println("---取出所有的value 迭代器----");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object value = iterator2.next();
System.out.println(value);
}
}
}
entrySet:获取所有关系k-V
public class MapFor {
public static void main(String[] args) {
Map map = new HashMap();
map.put("邓超", "孙俪");
map.put("王宝强", "马蓉");
map.put("宋喆", "马蓉");
map.put("刘令博", null);
map.put(null, "刘亦菲");
map.put("鹿晗", "关晓彤");
//方法3: 通过EntrySet 来获取k-v
Set entrySet = map.entrySet();// EntrySet<Map.Entry<K,V>>
//(1) 增强for
System.out.println("----使用EntrySet 的for 增强----");
for (Object entry : entrySet) {
//将entry 转成Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
//(2) 迭代器
System.out.println("----使用EntrySet 的迭代器----");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
}
}
练习
使用 HashMap 添加 3 个员工对象,要求 键:员工id、值:员工对象,并遍历显示工资 > 18000的员工(遍历方式最少两种),员工类:姓名、工资、员工id
public class MapExercise {
public static void main(String[] args) {
Map map = new HashMap();
map.put("1",new Employee("小明",20000,1));
map.put("2",new Employee("小红",30000,2));
map.put("3",new Employee("小刚",10000,3));
//方法1 使用keySet -> 增强for
Set set = map.keySet();
for (Object key :set) {
//先获取value
Employee emp = (Employee) map.get(key);
if (emp.getSal() > 18000){
System.out.println("emp = " + emp);
}
}
//方法2 使用EntrySet -> 迭代器
Set set1 = map.entrySet();
Iterator iterator = set1.iterator();
while (iterator.hasNext()) {
Map.Entry entry = (Map.Entry) iterator.next();
Employee emp = (Employee) entry.getValue();
if (emp.getSal() > 18000){
System.out.println("emp = " + emp);
}
}
}
}
class Employee{
private String name;
private double sal;
private int id;
public Employee(String name, double sal, int id) {
this.name = name;
this.sal = sal;
this.id = id;
}
public String getName() {
return name;
}
public double getSal() {
return sal;
}
public int getId() {
return id;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", sal=" + sal +
", id=" + id +
'}';
}
}
①HashMap
特点
- HashMap 是 Map 接口使用频率最高的实现类。
- HashMap 是以 key-val 的方式来存储数据(HashMap$Node类型)
- key不能重复,但是值可以重复,允许使用 null 键和 null 值。
- 如果添加相同的 key,则会覆盖原来的 key-val ,等同于修改(key不会替换,val 会替换)
- 与 HashSet 一样,不保证映射的顺序,因为底层是以 hash 表的方式来存储的(hashMap底层 数组+链表+红黑树)
- HashMap 没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有 synchronized
底层机制及源码剖析
- HashMap 底层维护了 Node 类型的数组 table,默认为 null
- 当创建对象时,将加载因子(loadfactor)初始化为 0.75
- 当添加 key-val 时通过 key 的哈希值得到在 table 的索引,然后判断该索引处是否有元素
- 如果没有元素直接添加
- 如果该索引处有元素,判断该元素的 key 和准备加入的 key 是否相等
- 如果相等,则直接替换 val
- 如果不相等需要判断是树结构还是链表结构,做出相应处理
- 如果添加时发现容量不够,则需要扩容。
- 第1次添加,则需要扩容 table 容量为 16,临界值(threshold)为12 (16*0.75)
- 以后再扩容,则需要扩容 table 容量为原来的 2 倍(32),临界值为原来的 2倍,即24,依次类推
- 在 Java8 中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是8),并且 table 的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
package com.jwt.map_;
import java.util.HashMap;
public class HashMapSource1 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("java", 10);//ok
map.put("php", 10);//ok
map.put("java", 20);//替换value
System.out.println("map=" + map);
}
}
- 执行构造器new HashMap()
初始化加载因子loadfactor = 0.75
HashMap$Node[] table = null
- 执行put 调用 hash 方法
//计算key 的hash 值(h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) {//K = "java" value = 10
return putVal(hash(key), key, value, false, true);
}
- 执行putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K, V>[] tab;Node<K, V> p;int n, i;//辅助变量
//如果底层的table 数组为null, 或者length =0 , 就扩容到16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//取出hash值对应table的索引位置的Node, 如果为null, 就直接加入k-v
if ((p = tab[i = (n - 1) & hash]) == null)
//创建成一个Node ,加入该位置即可
tab[i] = newNode(hash, key, value, null);
else {
Node<K, V> e;K k;//辅助变量
// 如果table的索引位置的key的hash和新的key的hash值相同,
// 并满足(table现有的结点的key和准备添加的key是同一个对象||equals 返回真)
// 就认为不能加入新的k-v
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果当前的table已有的Node是红黑树,就按照红黑树的方式处理
else if (p instanceof TreeNode)
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
else {
//如果找到的结点,后面是链表,就循环比较
for (int binCount = 0; ; ++binCount) {//死循环
if ((e = p.next) == null) {//如果整个链表,没有和他相同,就加到该链表的最后
p.next = newNode(hash, key, value, null);
//加入后,判断当前链表的个数,是否已经到8个,到8个后
//就调用treeifyBin 方法进行红黑树的转换
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && //如果在循环比较过程中,发现有相同,就break,就只是替换value
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; //替换,key 对应value
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//每增加一个Node ,就size++
if (++size > threshold)//如size > 临界值,就扩容
resize();
afterNodeInsertion(evict);
return null;
}
- 关于树化(转成红黑树)
//如果table为null ,或者大小还没有到64,暂时不树化,而是进行扩容.
//否则才会真正的树化-> 剪枝
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
}
②Hashtable
特点
- 存放的元素是键值对:即 K-V
- Hashtable 的键和值都不能为 null,否则会抛出 NullPointerException
Hashtable table = new Hashtable();//ok
table.put( "john", 100); //ok
table.put(null, 100); //异常
table.put("john", null);//异常
table.put("john", 200);//替换
- Hashtable 使用方法基本上和 HashMap 一样
- Hashtable 是线程安全的 (synchronized), HashMap 是线程不安全的
Hashtable和HashMap对比
| 版本 | 线程安全(同步) | 效率 | 允许null键null值 | |
|---|---|---|---|---|
| HashMap | 1.2 | 不安全 | 高 | 可以 |
| Hashtable | 1.0 | 安全 | 较低 | 不可以 |
③Properties
特点
Properties 类继承自 Hashtable 类并且实现了 Map 接口,也是使用一种键值对的形式来保存数据。
Properties 使用特点和 Hashtable 类似,key 和 value 不能为 null
Properties 还可以用于从 xxx.properties 文件中,加载数据到 Properties 类对象,并进行读取和修改
xxx.properties 文件通常作为配置文件,这个知识点在 IO 流会讲解
基本使用
package com.jwt.set_;
import java.util.Properties;
public class Properties_ {
public static void main(String[] args) {
//创建
Properties properties = new Properties();
//properties.put(null, "abc");//抛出空指针异常
//properties.put("abc", null); //抛出空指针异常
//增加
properties.put("john", 100);//k-v
properties.put("lucy", 100);
properties.put("lic", 100);
properties.put("lic", 88);//如果有相同的key,value被替换
System.out.println("properties=" + properties);
//通过k 获取对应值
System.out.println(properties.get("lic"));//88
//删除
properties.remove("lic");
System.out.println("properties=" + properties);
//修改
properties.put("john", "约翰");
System.out.println("properties=" + properties);
}
}
④TreeMap
TreeMap 保证按照添加的 key-value 对进行排序,实现排序遍历。此时使用 key 的自然排序或定制排序。底层使用红黑树
自然排序
class Student implements Comparable{
....
@Override
public int compareTo(Object o) {
if (o instanceof Student) {
Student s = (Student) o;
int com = -this.name.compareTo(s.name);
if (com != 0) {
return com;
} else {
return Integer.compare(this.age, s.age);
}
}else
throw new RuntimeException();
}
}
定制排序
TreeMap map1 = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if (o1 instanceof Student && o2 instanceof Student) {
Student s1 = (Student) o1;
Student s2 = (Student) o2;
return Integer.compare(s1.getAge(), s2.getAge());
} else {
throw new RuntimeException("类型不匹配");
}
}
});
⑤LinkedHashMap
LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。
另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
⑥ConcurrentHashMap
线程安全的HashMap
集合对比
三种集合:
- HashMap 是线程不安全的,性能好
- Hashtable 线程安全基于 synchronized,综合性能差,已经被淘汰
- ConcurrentHashMap 保证了线程安全,综合性能较好
集合对比:
- Hashtable 继承 Dictionary 类,HashMap、ConcurrentHashMap 继承 AbstractMap,均实现 Map 接口
- Hashtable 底层是数组 + 链表,JDK8 以后 HashMap 和 ConcurrentHashMap 底层是数组 + 链表 + 红黑树
- HashMap 线程不安全,Hashtable 线程安全,Hashtable 的方法都加了 synchronized 关来确保线程同步
- ConcurrentHashMap、Hashtable 不允许 null 值,HashMap 允许 null 值
- ConcurrentHashMap、HashMap 的初始容量为 16,Hashtable 初始容量为11,填充因子默认都是 0.75,两种 Map 扩容是当前容量翻倍:capacity * 2,Hashtable 扩容时是容量翻倍 + 1:capacity*2 + 1
工作步骤
初始化,使用 cas 来保证并发安全,懒惰初始化 table
树化,当 table.length < 64 时,先尝试扩容,超过 64 时,并且 链表节点数 > 8 时,会将链表树化,树化过程会用 synchronized 锁住链表头
说明:锁住某个槽位的对象头,是一种很好的细粒度的加锁方式,类似 MySQL 中的行锁
put,如果该 节点 尚未创建,只需要使用 cas 创建 节点;如果已经有了,锁住链表头进行后续 put 操作,元素添加至 节点 的尾部
get,无锁操作仅需要保证可见性,扩容过程中 get 操作拿到的是 ForwardingNode 会让 get 操作在新 table 进行搜索
扩容,扩容时以 bin节点 为单位进行,需要对 bin节点 进行 synchronized,但这时其它竞争线程也不是无事可做,它们会帮助把其它 bin节点 进行扩容
size,元素个数保存在 baseCount 中,并发时的个数变动保存在 CounterCell[] 当中,最后统计数量时累加
//需求:多个线程同时往HashMap容器中存入数据会出现安全问题
public class ConcurrentHashMapDemo{
public static Map<String,String> map = new ConcurrentHashMap();
public static void main(String[] args){
new AddMapDataThread().start();
new AddMapDataThread().start();
Thread.sleep(1000 * 5);//休息5秒,确保两个线程执行完毕
System.out.println("Map大小:" + map.size());//20万
}
}
public class AddMapDataThread extends Thread{
@Override
public void run() {
for(int i = 0 ; i < 1000000 ; i++ ){
ConcurrentHashMapDemo.map.put("键:"+i , "值"+i);
}
}
}
三、Collections 工具类
①简介
Collections 是一个操作 Set、List 和Map 等集合的工具类
Collections 中提供了一系列静态的方法对集合元索进行排序、查询和修改等操作
②常用方法
- reverse(List): 反转 List 中元素的顺序
- shuffle(List): 对List 集合元索进行随机排序
- sort(List): 根据元素的自然顺序对指定 List 集合元素按升序排序
- sort(List, Comparator): 根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
- swap(List, int, int): 将指定 List 集合中的 i 处元素和 j 处元素进行交换
- Object max(Collection): 根据元素的自然顺序,返回给定集合中的最大元素
- Object max(Collection, Comparator): 根据Comparator 指定的顺序,返回给定集合中的最大元素
- Object min(Collection)
- Object min(Collection, Comparator)
- int frequency(Collection, Object): 返回指定集合中指定元素的出现次数
- void copy(List dest,List src): 将 src 中的内容复制到 dest 中
- boolean replaceAll(List list, Object oldVal, Object newVal): 使用新值替换List对象的所有旧值
package com.jwt.map_;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class Collections_ {
public static void main(String[] args) {
//创建ArrayList 集合,用于测试.
List list = new ArrayList();
list.add("tom");
list.add("smith");
list.add("king");
list.add("milan");
list.add("tom");
System.out.println("自然顺序list=" + list);
// reverse(List):反转List 中元素的顺序
Collections.reverse(list);
System.out.println("反转list=" + list);
// shuffle(List):对List 集合元素进行随机排序
for (int i = 0; i < 3; i++) {
Collections.shuffle(list);
System.out.println("随机排序list=" + list);
}
// sort(List):根据元素的自然顺序对指定List 集合元素按升序排序
Collections.sort(list);
System.out.println("自然排序后list=" + list);
// sort(List,Comparator):根据指定的Comparator 产生的顺序对List 集合元素进行排序
//我们希望按照字符串的长度大小排序
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String) o2).length() - ((String) o1).length();
}
});
System.out.println("字符串长度大小排序=" + list);
// swap(List,int, int):将指定list 集合中的i 处元素和j 处元素进行交换
Collections.swap(list, 0, 1);
System.out.println("交换后的情况");
System.out.println("list=" + list);
//Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
System.out.println("自然顺序最大元素=" + Collections.max(list));
//Object max(Collection,Comparator):根据Comparator 指定的顺序,返回给定集合中的最大元素
//比如,我们要返回长度最大的元素
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
System.out.println("长度最大的元素=" + maxObject);
//int frequency(Collection,Object):返回指定集合中指定元素的出现次数
System.out.println("tom 出现的次数=" + Collections.frequency(list, "tom"));
//void copy(List dest,List src):将src 中的内容复制到dest 中
ArrayList dest = new ArrayList();
//为了完成一个完整拷贝,我们需要先给dest 赋值,大小和list.size()一样
for(int i = 0; i < list.size(); i++) {
dest.add("");
}
//拷贝
Collections.copy(dest, list);
System.out.println("dest=" + dest);
//boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换List 对象的所有旧值
//如果list 中,有tom 就替换成汤姆
Collections.replaceAll(list, "tom", "汤姆");
System.out.println("list 替换后=" + list);
}
}
四、集合总结
①集合数据结构
List
| List | 结构 | 图 |
|---|---|---|
| ArrayList | Object数组 |  |
| LinkedList | 双向链表 |  |
| Vector | Object数组 | 同 ArrayList |
Map
| Map | 结构 | 图 |
|---|---|---|
| HashMap | 数组+链表+红黑树 |  |
| Hashtable | 数组+链表 | 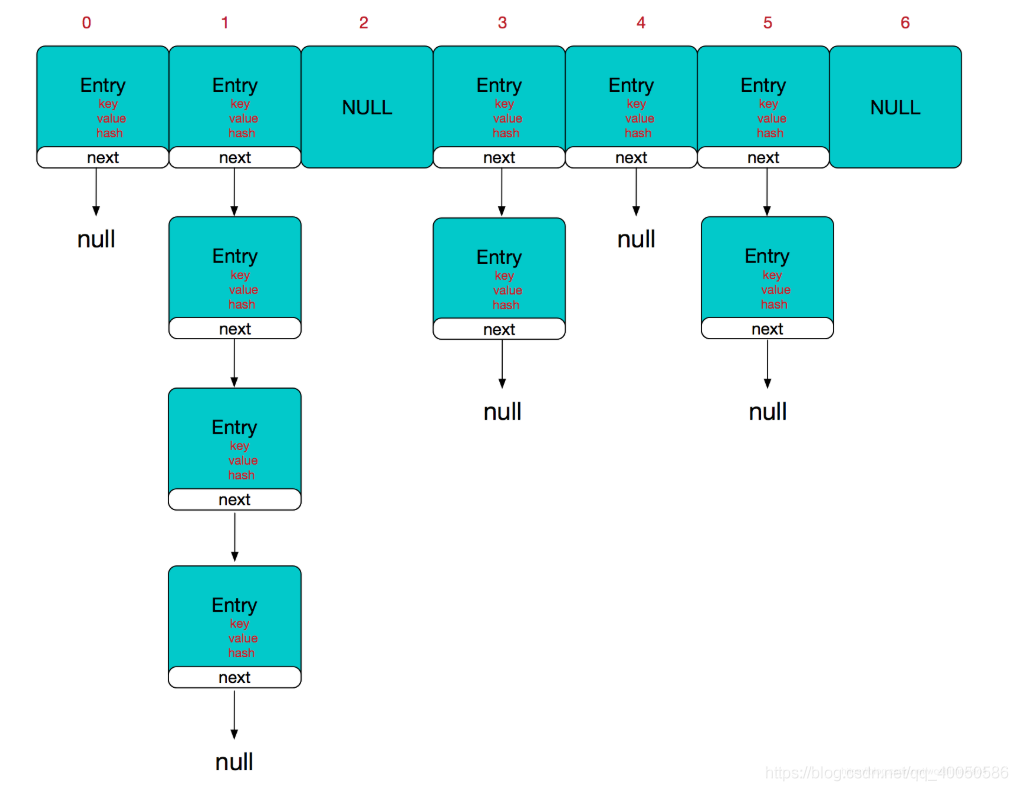 |
| LinkedHashMap | 数组+双向链表+红黑树 |  |
| TreeMap | 红黑树 |  |
Set
- HashSet:数组+链表+红黑树(同HashMap)
- LinkedHashSet: 数组+双向链表+红黑树(同LinkedHashMap)
- TreeSet:红黑树(同 TreeMap)
②集合选取
在开发中,选择什么集合实现类,主要取决于业务操作特点,然后根据集合实现类特性进行选择,分析如下:
先判断存储的类型(一组对象[单列]或一组键值对[双列])
- 一组对象[单列]: Collection 接口
- 允许重复: List
- 增删多: LinkedList-线程不安全
- 改查多: ArrayList-线程不安全、Vector-线程安全
- 不允许重复: Set
- 无序: HashSet
- 排序: TreeSet
- 插入和取出顺序一致: LinkedHashSet
- 一组键值对[双列]: Map 接口
- 键无序: HashMap-线程不安全 、Hashtable-线程安全
- 键排序: TreeMap
- 键插入和取出顺序一致: LinkedHashMap-线程不安全
- 读取文件: Properties
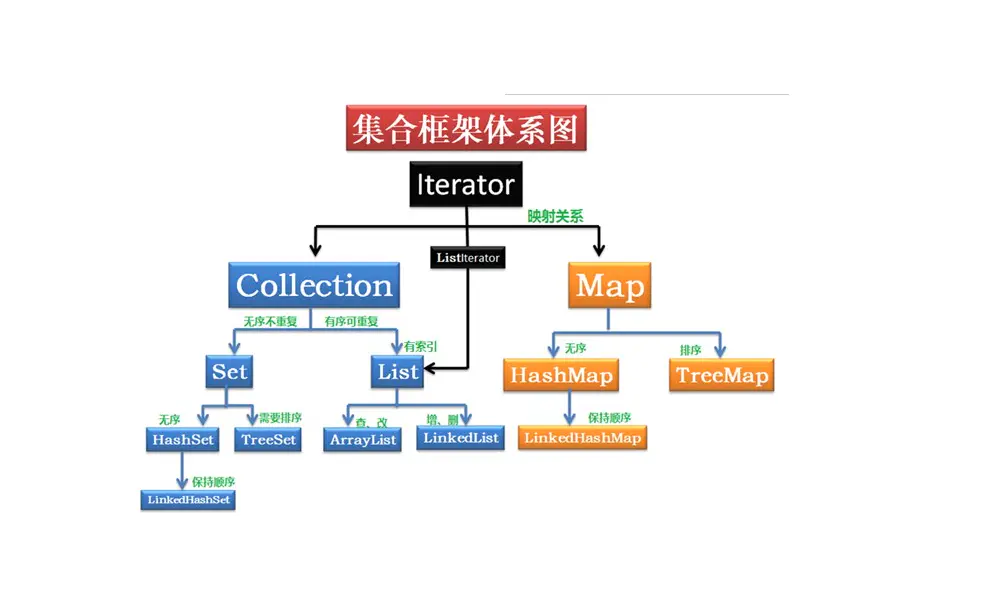
参考
[面经手册 · 第8篇《LinkedList插入速度比ArrayList快?你确定吗?》 | bugstack 虫洞栈](https://bugstack.cn/md/java/interview/2020-08-30-面经手册 · 第8篇《LinkedList插入速度比ArrayList快?你确定吗?》.html)
五、本章练习
1.编程题Homework01.java
按要求实现:
(1)封装一个新闻类,包含标题和内容属性,提供get、 set方法,重写toString方法,打印对象时只打印标题:
(2)只提供一个带参数的构造器,实例化对象时,只初始化标题;并且实例化两个对象:
- 新闻一:新冠确诊病例超千万,数百万印度教信徒赴恒河“圣浴”引民众担忧
- 新闻二:男子突然想起2个月前钓的鱼还在网兜里,捞起一看赶紧放生
(3)将新闻对象添加到ArrayList集合中,并且进行倒序遍历;
(4)在遍历集合过程中,对新闻标题进行处理,超过15字的只保留前15个,然后在后边加“…”
(5)在控制台打印遍历出经过处理的新闻标题;
package com.jwt.map_;
import java.util.ArrayList;
import java.util.Collections;
public class Homework01 {
public static void main(String[] args) {
News news1 = new News("新闻一:新冠确诊病例超千万,数百万印度教信徒赴恒河“圣浴”引民众担忧");
News news2 = new News("新闻二:男子突然想起2个月前钓的鱼还在网兜里,捞起一看赶紧放生");
ArrayList<News> arrayList = new ArrayList<>();
arrayList.add(news1);
arrayList.add(news2);
//方法一:使用for循环倒序 + 处理title函数
for (int i = arrayList.size()-1; i >= 0 ; i--) {
News news = arrayList.get(i);
System.out.println(processTitle(news.getTitle()));
}
//方法二:使用Collections工具类倒序 +if
Collections.reverse(arrayList);//反转List 中元素的顺序
for (News news :arrayList) {
if (news.getTitle().length() > 15){
char[] chars = news.getTitle().toCharArray();
for (int i = 0; i < 15; i++) {
System.out.print(chars[i]);
}
System.out.println("...");
}
}
}
public static String processTitle(String title) {
if (title.length() > 15) {
return title.substring(0, 15) + "...";
} else {
return title;
}
}
}
class News{
private String title;
private String content;
public News(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "News{" +
"title='" + title + '\'' +
'}';
}
}
2.编程题Homework02.java
使用 ArrayList 完成对对象 Car{name, price} 的各种操作
- 1.add:添加单个元素
- 2.remove:删除指定元素
- 3.contains:查找元素是否存在
- 4.size:获取元素个数
- 5.isEmpty:判断是否为空
- 6.clear:清空
- 7.addAlI:添加多个元素
- 8.containsAll:查找多个元素是否都存在
- 9.使用增强for和迭代器来遍历所有的car ,需要重写Car的toString方法
- 10.removeAll: 删除多个元素
package com.jwt.map_;
import java.util.ArrayList;
import java.util.Iterator;
public class Homework02 {
public static void main(String[] args) {
Car car = new Car("宝马",400000);
Car car2 = new Car("宾利", 5000000);
ArrayList<Car> arraylist = new ArrayList<>();
//1.add:添加单个元素
arraylist.add(car);
arraylist.add(car2);
System.out.println("arraylist = " + arraylist);
//2.remove:删除指定元素
arraylist.remove(car2);
System.out.println("arraylist = " + arraylist);
//3.contains:查找元素是否存在
System.out.println(arraylist.contains(car));
//4.size:获取元素个数
System.out.println(arraylist.size());
//5.isEmpty:判断是否为空
System.out.println(arraylist.isEmpty());
//6.clear:清空
arraylist.clear();
System.out.println("arraylist = " + arraylist);
//7.addAlI:添加多个元素
ArrayList<Car> arraylist2 = new ArrayList<>();
arraylist2.add(car);
arraylist2.add(car2);
arraylist.addAll(arraylist2);
System.out.println("arraylist = " + arraylist);
//8.containsAll:查找多个元素是否都存在
System.out.println(arraylist.containsAll(arraylist2));
//9.使用增强for和迭代器来遍历所有的car ,需要重写Car的toString方法
//增强for
for (Object o :arraylist) {
System.out.println("o = " + o);
}
//迭代器
Iterator<Car> iterator = arraylist.iterator();
while (iterator.hasNext()) {
Car next = iterator.next();
System.out.println("next = " + next);
}
//10.removeAll: 删除多个元素
arraylist.removeAll(arraylist2);
System.out.println("arraylist = " + arraylist);
}
}
class Car{
private String name;
private double price;
public Car(String name, double price) {
this.name = name;
this.price = price;
}
@Override
public String toString() {
return "Car{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
}
3.编程题Homework03.java
按要求完成下列任务
1)使用 HashMap 类实例化一个 Map 类型的对象 m,键(String) 和值(int) 分别用于存储员工的姓名和工资,存入数据如下: jack-650元; tom-1200元; smith-2900元;
2)将jack的工资更改为2600元
3)为所有员工工资加薪100元
4)遍历集合中所有的员工
5)遍历售合中所有的工资
package com.jwt.map_;
import java.util.*;
public class Homework03 {
public static void main(String[] args) {
Map map = new HashMap();
map.put("jack",650);
map.put("tom",1200);
map.put("smith",2900);
//将jack的工资更改为2600元
map.put("jack",2600);
System.out.println("map = " + map);
//为所有员工工资加薪100元
Set set = map.keySet();
for (Object key :set) {
map.put(key,(Integer)map.get(key)+100);
}
System.out.println("map = " + map);
//遍历集合中所有的员工
Set set1 = map.entrySet();
Iterator iterator = set1.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
Map.Entry m = (Map.Entry) next;
System.out.println(m.getKey() + "-" + m.getValue());
}
//遍历售合中所有的工资
Collection values = map.values();
for (Object o :values) {
System.out.println("工资 = " + o);
}
}
}
4.简答题
试分析 HashSet 和 TreeSet 分别如何实现去重的?
- (1) HashSet 的去重机制: hashCode() + equals() ,底层先通过存入对象,进行运算得到一个 hash 值,通过 hash 值得到对应的索引,如果发现 table索引所在的位置,没有数据,就直接存放如果有数据,就进行 equals 比较[遍历比较], 如果比较后,不相同,就加入,否则就不加入。
- (2) TreeSet的去重机制:如果你传入了一个 Comparator 匿名对象,就使用实现的 compare 去重,如果方法返回 0,就认为是相同的元素/数据,就不添加;如果你没有传入一个 Comparator 匿名对象,则以你添加的对象实现的 Compareable 接口的 compareTo 去重。
5.代码分析题
下面代码运行会不会抛出异常,并从源码层面说明原因[考察读源码+接口编程+动态绑定]
TreeSet treeSet = new TreeSet();
treeSet.add(new Person());
会报转换异常(ClassCastException),Person 类要实现 Compareable 才行
因为 TreeSet() 构造器没有传入 Comparator 接口的匿名内部类,所以在底层会执行 ComparabLe<? super K> k = (Comparable<? super K>) key; 即把 Perosn 转成 Comparable 类型,所以 Person 类要实现 Compareable 才不报错
class Person implements Comparable{
....
@Override
public int compareTo(Object o) {
return 0;
}
}
6.代码分析题
已知: Person 类按照 id 和 name 重写了 hashCode 和 equals 方法,问下面代码输出什么?
HashSet set = new HashSet();//ok
Person p1 = new Person(1001,"AA");//ok
Person p2 = new Person(1002,"BB");//ok
set.add(p1);//ok
set.add(p2);//ok
p1.name = "CC";
set.remove(p1);//此处计算“1001-CC”的hash值,p1还存在“1001-AA”的hash值的位置,所以删除不成功
System.out.println(set); //2个对象
set.add(new Person(1001,"CC"));//计算“1001-CC”的hash,此处为空,可以添加
System.out.println(set); //3个对象
set.add(new Person(1001," AA"));//计算“1001-AA”的hash,此处不为空,进行equals比较,p1已经变成“1001-CC”,不相同,会挂在p1后面,添加成功
System.out.println(set) //4个对象
参考
- 送分题,ArrayList 的扩容机制了解吗? - 云+社区 - 腾讯云 (tencent.com)
- ArrayList源码解析(基于Java8)扩容删除 - 云+社区 - 腾讯云 (tencent.com)
- ArrayList源码+扩容机制分析 - 云+社区 - 腾讯云 (tencent.com)
- ArrayList源码分析(基于JDK8)_Fighter168的博客-CSDN博客
- ArrayList 从源码角度剖析底层原理
- LinkedList 源码解析 - 掘金 (juejin.cn)
- LinkedList 源码解析
- IDEA调试debug时,stepinto 进不去方法和数据显示不完整的解决方法
- 在Intellij IDEA中使用Debug - bojiangzhou - 博客园 (cnblogs.com)
❤️Sponsor
您的支持是我不断前进的动力,如果您恰巧财力雄厚,又感觉本文对您有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用,拒绝白嫖,从你我做起!🥰🥰🥰
| 支付宝支付 | 微信支付 |
 |
 |



